导读:收集常见架构技术点,作为项目经理了解这些知识点以及解决具体场景是很有必要的。技术要服务业务,技术跟业务具体结合才能发挥技术的价值。
目录
1. 微服务
2. 服务发现
3. 流量削峰
4. 版本兼容
5. 过载保护
6. 服务熔断
7. 服务降级
8. 熔断VS降级
9. 服务限流
10. 故障屏蔽
1. 微服务
微服务架构是一种架构模式,它提倡将单一应用程序划分成一组小的服务,服务之间相互协调、互相配合,为用户提供最终价值。每个服务运行在其独立的进程中,服务和服务之间采用轻量级的通信机制相互沟通(通常是基于HTTP的Restful API).每个服务都围绕着具体的业务进行构建,并且能够被独立的部署到生产环境、类生产环境等。
- 单体应用:简单,脆弱(某个模块出问题,整个系统不可用),战斗力弱,维护成本低
- 微服务架构:复杂,健壮(某个模块出问题,不会影响系统整体的可用性),战斗力强,维护成本高
微服务架构的特点:
- 针对特定服务发布,影响小,风险小,成本低
- 频繁发布版本,快速交付需求
- 低成本扩容,弹性伸缩,适应云环境
Spring Cloud 为什么是国内最流行的微服务框架,它提供哪些开箱即用的组件 ?概览如下:
- Srping Boot 服务应用
- Spring Cloud Config 配置中心
- Spring Cloud Eureka 服务发现
- Spring Cloud Hystrix 熔断保护
- Spring Cloud Zuul 服务网关
- Spring Cloud OAuth 2 服务保护
- Spring Cloud Stream 消息驱动
- 分布式全链路跟踪
- 部署微服务
扩展参考:一文带你了解微服务架构和设计(多图) - 小二十七 - 博客园 (cnblogs.com)
2. 服务发现
服务发现是指使用一个注册中心来记录分布式系统中的全部服务的信息,以便其他服务能够快速的找到这些已注册的服务。服务发现是支撑大规模 SOA 和微服务架构的核心模块,它应该尽量做到高可用。
服务发现除了提供服务注册、目录和查找三大关键特性,还需要能够提供健康监控、多种查询、实时更新和高可用性等。
服务发现有三个角色,服务提供者、服务消费者和服务中介。服务中介是联系服务提供者和服务消费者的桥梁。服务提供者将自己提供的服务地址注册到服务中介,服务消费者从服务中介那里查找自己想要的服务的地址,然后享受这个服务。服务中介提供多个服务,每个服务对应多个服务提供者。
有三种典型的服务发现组件,分别是 ZooKeeper、Eureka 和 Nacos
3. 流量削峰
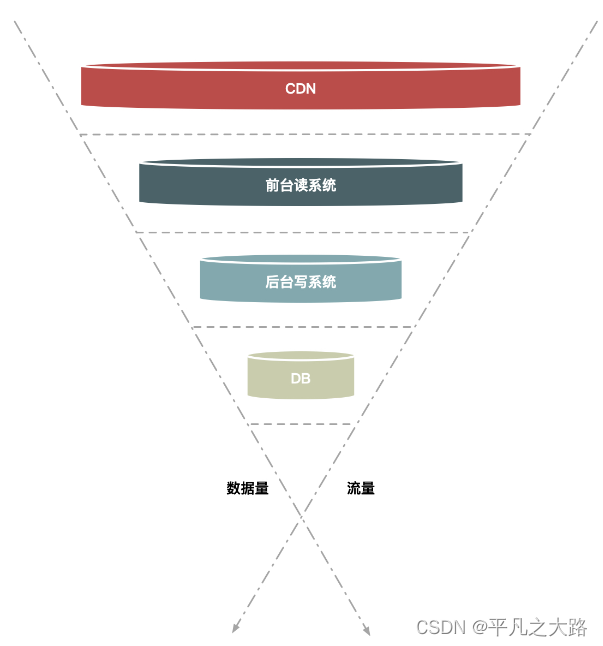
如果观看抽奖或秒杀系统的请求监控曲线,你就会发现这类系统在活动开放的时间段内会出现一个波峰,而在活动未开放时,系统的请求量、机器负载一般都是比较平稳的。为了节省机器资源,我们不可能时时都提供最大化的资源能力来支持短时间的高峰请求。所以需要使用一些技术手段,来削弱瞬时的请求高峰,让系统吞吐量在高峰请求下保持可控。削峰也可用于消除毛刺,使服务器资源利用更加均衡和充分。常见的削峰策略有队列,限频,分层过滤,多级缓存等。
流量削峰就好比因为存在早高峰和晚高峰的问题,所以有了错峰限行的解决方案。
一般采用以下方式:
- 排队 :流量削峰首先想到的就是队列,将同步的请求转换成异步请求,将流量峰值通过消息队列平缓推送过去。
- 答题:经过答题之后的请求具有了先后顺序,这样对于后续的业务逻辑来说就可以很容易的控制了
- 分层过滤:过滤无效请求,分层过滤是采用漏斗方式进行请求处理的。
4. 版本兼容
在升级版本的过程中,需要考虑升级版本后,新的数据结构是否能够理解和解析旧数据,新修改的协议是否能够理解旧的协议以及做出预期内合适的处理。这就需要在服务设计过程中做好版本兼容。
对于持续迭代产品,需要做好版本配置管理,版本兼容中要重点考虑低版本一些特殊情况。
5. 过载保护
过载是指当前负载已经超过了系统的最大处理能力,过载的出现,会导致部分服务不可用,如果处置不当,极有可能引起服务完全不可用,乃至雪崩(雪崩效应:是一种因服务提供者的不可用导致服务调用者的不可用,并将不可用逐渐放大的过程)。过载保护正是针对这种异常情况做的措施,防止出现服务完全不可用的现象。
应该使用该模式来:防止应用程序直接调用那些很可能会调用失败的远程服务或共享资源。
不适合的场景:对于应用程序中的直接访问本地私有资源,比如内存中的数据结构,如果使用熔断器模式只会增加系统额外开销。不适合作为应用程序中业务逻辑的异常处理替代品。
6. 服务熔断
服务熔断的作用类似于我们家用的保险丝,当某服务出现不可用或响应超时的情况时,为了防止整个系统出现雪崩,暂时停止对该服务的调用。
场景:某一服务出现异常,拖垮整个服务链路,消耗整个线程队列,造成服务不可用,资源耗尽:
1)服务提供者不可用
- 硬件故障:硬件损坏造成的服务器主机宕机, 网络硬件故障造成的服务提供者的不可访问
- 程序Bug:
- 缓存击穿:缓存击穿一般发生在缓存应用重启, 所有缓存被清空时,以及短时间内大量缓存失效时. 大量的缓存不命中, 使请求直击后端,造成服务提供者超负荷运行,引起服务不可用
- 用户大量请求:在秒杀和大促开始前,如果准备不充分,用户发起大量请求也会造成服务提供者的不可用
2)重试加大流量
- 用户重试:在服务提供者不可用后, 用户由于忍受不了界面上长时间的等待,而不断刷新页面甚至提交表单
- 代码逻辑重试: 服务调用端的会存在大量服务异常后的重试逻辑
3)服务调用者不可用:同步等待造成的资源耗尽:当服务调用者使用同步调用 时, 会产生大量的等待线程占用系统资源. 一旦线程资源被耗尽,服务调用者提供的服务也将处于不可用状态, 于是服务雪崩效应产生了。
7. 服务降级
服务降级是当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略的降级,以此释放服务器资源以保证核心任务的正常运行。降级往往会指定不同的级别,面临不同的异常等级执行不同的处理。
根据服务方式:可以拒接服务,可以延迟服务,也有时候可以随机服务。
根据服务范围:可以砍掉某个功能,也可以砍掉某些模块。
总之服务降级需要根据不同的业务需求采用不同的降级策略。主要的目的就是服务虽然有损但是总比没有好。
8. 熔断VS降级
相同点:目标一致,都是从可用性和可靠性出发,为了防止系统崩溃;用户体验类似,最终都让用户体验到的是某些功能暂时不可用;
不同点:触发原因不同,服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑;
9. 服务限流
限流可以认为服务降级的一种,限流就是限制系统的输入和输出流量已达到保护系统的目的。一般来说系统的吞吐量是可以被测算的,为了保证系统的稳定运行,一旦达到的需要限制的阈值,就需要限制流量并采取一些措施以完成限制流量的目的。比如:延迟处理,拒绝处理,或者部分拒绝处理等等。
10. 故障屏蔽
将故障机器从集群剔除,以保证新的请求不会分发到故障机器。










![[MAUI]模仿Chrome下拉标签页的交互实现](https://img-blog.csdnimg.cn/fc17be3ae466459b960abd1aa0e31680.gif)