不同策略的主题建模方法比较
本文将介绍利用 LSA、pLSA、LDA、NMF、BERTopic、Top2Vec 这六种策略进行主题建模之间的比较。
1.简介
在自然语言处理(NLP)中,主题建模一词包含了一系列的统计和深度学习技术,用于寻找文档集中的隐藏语义结构。
主题建模是一个无监督的机器学习问题。无监督的意思是,算法在没有标签的情况下学习模式。
我们作为人类产生和交换的大部分信息都具有文本性质。文件、对话、电话、信息、电子邮件、笔记、社交媒体帖子。在缺乏(或有限的)先验知识的情况下,从这些来源中自动提取价值的能力是数据科学中一个永恒的、无处不在的问题。
在这篇文章中,我们将讨论热门的主题建模方法,从传统的算法到最新的基于深度学习的技术。我们旨在分享对这些模型的通俗介绍,并比较它们在实际应用中的优势和劣势。
2.主题建模策略
2.1 简介
潜在语义分析(LSA,Latent Semantic Analysis)
(Deerwester¹ et al. 1990)
\text{(Deerwester¹ et al. 1990)}
(Deerwester¹ et al. 1990)、概率潜在语义分析(pLSA,probabilistic Latent Semantic Analysis)
(Hofmann²,1999)
\text{(Hofmann²,1999)}
(Hofmann²,1999)、隐含狄利克雷分布(LDA,Latent Dirichlet Allocation)
(Blei³ 等人,2003)
\text{(Blei³ 等人,2003)}
(Blei³ 等人,2003)和非负矩阵分解(NMF,Non-Negative Matrix Factorization)
( Lee³ 等人,1999)
\text{( Lee³ 等人,1999)}
( Lee³ 等人,1999)是传统且应用广泛的主题建模方法。
它们将文档表示为一个词包,并假定每个文档是潜在话题的混合物。
它们都是从将文本语料库转换为 文档-词 矩阵(Document-Term Matrix,DTM)开始的,DTM 是一个表格,每一行是一个文档,每一列是一个不同的词。

每个单元格
<
i
,
j
>
<i, j>
<i,j> 包含一个计数,即单词
j
j
j 在文档
i
i
i 中出现的次数。一个常见的替代单词计数的方法是
T
F
−
I
D
F
TF-IDF
TF−IDF 得分。它同时考虑了术语频率(TF)和反文档频率(IDF),以惩罚那些在语料库中经常出现的术语的权重,并增加更多稀有术语的权重。

潜在主题搜索的基本原则是将 DTM 分解为 文档-主题 和 主题-术语 矩阵。下面的方法在如何定义和达到这一目标方面有所不同。
2.2 潜在语义分析(Latent Semantic Analysis,LSA)
为了达到分解 DTM 和提取主题的目的,潜在语义分析(LSA)采用了一种叫做奇异值分解(SVD,Singular Value Decomposition)的矩阵分解技术。
SVD 将 DTM 分解为三个不同矩阵的乘积。
D
T
M
=
U
×
Σ
×
V
t
DTM = U×Σ×V^t
DTM=U×Σ×Vt,其中
- U U U 和 V V V 的大小分别为 m × m m×m m×m 和 n × n n×n n×n,即 m m m 为语料库中的文件数, n n n 为词数。
-
Σ
Σ
Σ 为
m
×
n
m×n
m×n,只有其主对角线被填充:它包含
DTM的奇异值。
LSA 选择 DTM 的第一个最大的奇异值,其中
t
<
=
m
i
n
(
m
,
n
)
t <= min(m, n)
t<=min(m,n) ,从而分别丢弃
U
U
U 和
V
V
V 的最后
m
−
t
m - t
m−t 和
n
−
t
n - t
n−t 列。这个过程被称为 truncated SVD。由此产生的 DTM 的近似值具有
t
t
t 阶,如下图所示。
t
t
t 阶的 DTM 近似值是最佳的,因为它是在
L
2
L_2
L2 规范方面最接近 DTM 的
t
t
t 阶矩阵。
U
U
U 和
V
V
V 的其余列可以解释为 文档-主题 和 词-主题 矩阵,
t
t
t 表示主题的数量。

LSA的优点
- 直观。
- 既可以适用于短文本,也可以适用于长文本。
- 通过 V V V 矩阵,主题是可解释的。
LSA的缺点
DTM不考虑语料库中单词的语义表示。类似的概念被当作不同的矩阵元素来处理。预处理技术可能有帮助,但只是在某种程度上。例如,词干化可能有助于将 I t a l y Italy Italy 和 I t a l i a n Italian Italian 作为类似的术语,但是像 m o n e y money money 和 c a s h cash cash 这样具有不同词干的近义词仍然会被认为是不同的。此外,词干化也可能导致较难解释的主题。LSA需要一个广泛的预处理阶段,以便从文本输入数据中获得一个重要的表示。- 在
truncated SVD中要保持的奇异值 t t t(主题)的数量必须事先知道。 - U U U 和 V V V 可能包含负值。这给可解释性带来了问题。
2.3 概率潜在语义分析(Probabilistic Latent Semantic Analysis,pLSA)
Hofmann² (1999)
\text{ Hofmann² (1999) }
Hofmann² (1999) 提出了 LSA 的一个变种,即使用 概率模型 而不是 SVD 来估计主题。因此被称为概率潜在语义分析(pLSA)。
特别是,pLSA 将一个词
w
w
w 和一个文档
d
d
d 的联合概率
P
(
d
,
w
)
P(d, w)
P(d,w) 建模为一个条件独立的多项式分布的混合物。
P
(
d
,
w
)
=
P
(
d
)
P
(
w
∣
d
)
P(d,w)=P(d)P(w|d)
P(d,w)=P(d)P(w∣d)
P
(
w
∣
d
)
=
∑
z
∈
Z
P
(
w
∣
z
)
P
(
z
∣
d
)
P(w|d)=\displaystyle \sum_{z\in Z} P(w|z)P(z|d)
P(w∣d)=z∈Z∑P(w∣z)P(z∣d)
其中:
- w w w 表示一个词。
- d d d 表示一个文档。
- z z z 表示一个主题。
- P ( z ∣ d ) P(z|d) P(z∣d) 是话题 z z z 出现在文档 d d d 中的概率。
- P ( w ∣ z ) P(w|z) P(w∣z) 是单词 w w w 出现在话题 z z z 中的概率。
- 我们假设 P ( w ∣ z , d ) = P ( w ∣ z ) P(w|z, d) = P(w|z) P(w∣z,d)=P(w∣z)。
前面的表达式可以重新写成:
P ( d , w ) = ∑ z ∈ Z P ( z ) P ( d ∣ z ) P ( w ∣ z ) P(d,w) = \displaystyle \sum_{z\in Z}P(z)P(d|z)P(w|z) P(d,w)=z∈Z∑P(z)P(d∣z)P(w∣z)
我们可以在这个表达式和之前的 DTM 分解的表述之间做一个类比,其中:
-
P
(
d
,
w
)
P(d,w)
P(d,w) 对应于
DTM。 - P ( z ) P(z) P(z) 类似于 ∑ \sum ∑ 的主对角线。
- P ( d ∣ z ) P(d|z) P(d∣z) 和 P ( w ∣ z ) P(w|z) P(w∣z) 分别对应于 U U U 和 V V V。
该模型可以使用期望最大算法(Expectation-Maximization Algorithm,EM)进行拟合。简而言之,EM 在存在潜在变量(在这种情况下是指主题)的情况下进行最大似然估计。
值得注意的是,DTM 的分解依赖于不同的目标函数。对于 LSA,它是
L
2
L_2
L2 准则,而对于 pLSA,它是似然函数。后者的目的是明确地将模型的预测能力最大化。
pLSA 与 LSA 模型有相同的优点和缺点,但有一些特殊的区别。
优点:与 LSA 相比,pLSA 显示出更好的性能
(Hofmann²,1999)
\text{(Hofmann²,1999)}
(Hofmann²,1999)。
缺点:pLSA 没有提供文档层面的概率模型。这意味着
- 参数的数量随着文档数量的增加而线性增长,导致了可扩展性和过拟合的问题。
- 它不能给新的文档分配概率。
2.4 潜在的狄利克雷分布(Latent Dirichlet Allocation,LDA)
LDA
(Blei³ et al., 2003)
\text{ (Blei³ et al., 2003)}
(Blei³ et al., 2003) 通过使用狄利克雷先验概率在贝叶斯方法中估计 文档-主题 和 术语-主题 分布来改进 pLSA。
狄利克雷分布 D i r ( α ) Dir(α) Dir(α) 是一个连续多变量概率分布系列,其参数为正实数的向量 α α α。
让我们设想一份报纸有三个部分:政治、体育和艺术,每个部分也代表一个主题。假设报纸各部分的主题混合分布是迪里切特分布的一个例子。
第1部分(政治),主题混合:政治 0.99,体育 0.005,艺术 0.005。
第2部分(体育),主题混合:政治 0.005,体育 0.99,艺术 0.005。
第3部分(艺术),主题混合:政治 0.005,体育 0.005,艺术 0.99。
让我们观察一下 LDA 的板块符号(一种在图形模型中表示变量的常规方法),以解释 狄利克雷先验概率 的使用。

LDA 的平面符号。摘自
(Barbieri⁵,2013)
\text{(Barbieri⁵,2013)}
(Barbieri⁵,2013)。灰色圆圈表示观察变量(语料库中的词),而白色圆圈表示潜在变量。
M M M 表示文档的数量, N N N 表示一个文档中的词的数量。从顶部,我们观察到 α α α,即每个文档主题分布的狄利克雷先验的参数。从 D i r i c h l e t Dirichlet Dirichlet 分布 D i r ( α ) Dir(α) Dir(α) 中,我们抽取一个随机样本,代表一个文档的主题分布 θ θ θ。就像在我们的报纸例子中,我们抽取一个混合物(0.99政治,0.05体育,0.05艺术)来描述一篇文章的主题分布。
从选定的混合物 θ θ θ 中,我们根据分布情况(在我们的例子中是政治)抽取一个主题 z z z。从底部,我们观察 β β β,即每个主题词分布的狄利克雷先验参数。从 D i r i c h l e t Dirichlet Dirichlet 分布 D i r ( β ) Dir(\beta) Dir(β) 中,我们选择一个样本,代表给定主题 z z z 的词分布 φ φ φ,然后从 φ φ φ 中,我们抽取一个词 w w w。
最后,我们感兴趣的是在给定文档 d d d 以及参数 α α α 和 β \beta β 的情况下估计话题 z z z 的概率,即 P ( z ∣ d , α , β ) P(z | d, α, \beta) P(z∣d,α,β)。该问题被表述为计算给定文档的隐藏变量的后验分布。
P ( θ , z ∣ d , α , β ) = p ( θ , z , d ∣ α , β ) p ( d ∣ α , β ) P(\theta, z|d, α, \beta)=\frac{p(\theta, z, d | \alpha, \beta)}{p(d | \alpha,\beta)} P(θ,z∣d,α,β)=p(d∣α,β)p(θ,z,d∣α,β)
由于这种分布难以计算,
(
B
l
e
i
3
等人,
2013
)
(Blei³ 等人,2013)
(Blei3等人,2013)建议使用一种近似推理算法(变异近似)。通过最小化近似分布和真实后验
P
(
θ
,
z
∣
d
,
α
,
β
)
P(θ, z|d, α, \beta)
P(θ,z∣d,α,β) 之间的
K
u
l
l
b
a
c
k
−
L
e
i
b
l
e
r
D
i
v
e
r
g
e
n
c
e
Kullback-Leibler Divergence
Kullback−LeiblerDivergence 来找到优化值。一旦我们得到了数据的最优参数,我们就可以再次计算
P
(
z
∣
d
,
α
,
β
)
P(z|d, α, \beta)
P(z∣d,α,β),从某种意义上说,它对应于 文档-主题 矩阵
U
U
U。
β
1
,
β
2
,
.
.
.
,
β
t
\beta_1, \beta_2, ..., \beta_t
β1,β2,...,βt 的每个条目都是
p
(
w
∣
z
)
p(w|z)
p(w∣z),对应于 术语-主题 矩阵
V
V
V。主要区别在于,和 pLSA 一样,矩阵系数有统计学解释。
优点
- 它提供了比
LSA和pLSA更好的性能。 - 与
pLSA不同的是,LDA可以为一个新的文档分配一个概率,这要归功于 文档-主题 D i r i c h l e t Dirichlet Dirichlet 分布。 - 它既可以应用于短文档,也可以应用于长文档。
- 主题对人的解释是开放的。
- 作为一个概率模块,
LDA可以被嵌入到更复杂的模型中或进行扩展。在 B l e i 3 等人( 2013 ) {\text Blei³ 等人(2013)} Blei3等人(2013)的原始工作之后的研究扩展了LDA并解决了一些原始的限制。
缺点
- 主题的数量必须事先知道。
- 字袋法忽略了语料库中词的语义表示,与
LSA和pLSA类似。 - 贝叶斯参数 α α α 和 β β β 的估计是以文档的可交换性为前提的。
- 它需要一个广泛的预处理阶段来从文本输入数据中获得一个重要的表示。
- 研究报告称,
LDA可能会产生过于笼统( R i z v i 6 等人, 2019 {\text Rizvi⁶ 等人,2019} Rizvi6等人,2019)或不相关 ( A l n u s y a n 7 等人, 2020 ) {\text(Alnusyan⁷等人,2020)} (Alnusyan7等人,2020)的主题。不同的执行结果也可能是不一致的 ( E g g e r 8 等人, 2021 ) {\text(Egger⁸等人,2021)} (Egger8等人,2021)。
LDA的实际例子
流行的 LDA 实现是在 Gensim 和 sklearn 包(Python)以及 Mallet(Java)中。
在下面的例子中,我们使用 Gensim 库和 pyLDAvis 来进行可视化主题探索。
'''
Topic Modeling with LDA: Minimum Viable Example
References:
[1] LDA with Gensim: https://radimrehurek.com/gensim/models/ldamodel.html
[2] Visualization with pyLDAvis: https://pypi.org/project/pyLDAvis/
'''
# Import dependencies
import gensim
import gensim.corpora as corpora
from gensim.utils import simple_preprocess
import spacy
import pyLDAvis
import pyLDAvis.gensim_models
from sklearn.datasets import fetch_20newsgroups
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
def lemmatize(docs, allowed_postags = ["NOUN", "ADJ", "VERB", "ADV"]):
'''
Performs lemmization of input documents.
Args:
- docs: list of strings with input documents
- allowed_postags: list of accepted Part of Speech (POS) types
Output:
- list of strings with lemmatized input
'''
nlp = spacy.load("en_core_web_sm", disable = ["parser", "ner"])
lemmatized_docs = []
for doc in docs:
doc = nlp(doc)
tokens = []
for token in doc:
if token.pos_ in allowed_postags:
tokens.append(token.lemma_)
lemmatized_docs.append(" ".join(tokens))
return (lemmatized_docs)
def tokenize(docs):
'''
Performs tokenization of input documents.
Args:
- docs: list of strings with input documents
Output:
- list of strings with tokenized input
'''
tokenized_docs = []
for doc in docs:
tokens = gensim.utils.simple_preprocess(doc, deacc=True)
tokenized_docs.append(tokens)
return (tokenized_docs)
# Fetch 20newsgropus dataset
docs = fetch_20newsgroups(subset = 'all', remove = ('headers', 'footers', 'quotes'))['data']
# Pre-process input: lemmatization and tokenization
lemmatized_docs = lemmatize(docs)
tokenized_docs = tokenize(lemmatized_docs)
# Mapping from word IDs to words
id2word = corpora.Dictionary(tokenized_docs)
# Prepare Document-Term Matrix
corpus = []
for doc in tokenized_docs:
corpus.append(id2word.doc2bow(doc))
# Fit LDA model: See [1] for more details
topic_model = gensim.models.ldamodel.LdaModel(
corpus = corpus, # Document-Term Matrix
id2word = id2word, # Map word IDs to words
num_topics = 30, # Number of latent topics to extract
random_state = 100,
passes = 100, # N° of passes through the corpus during training
)
# Visualize with pyLDAvis: See [2] for more details
pyLDAvis.enable_notebook()
visualization = pyLDAvis.gensim_models.prepare(
topic_model,
corpus,
id2word,
mds = "mmds",
R = 30)
visualization

2.5 非负矩阵分解(Non-negative Matrix Factorization,NMF)
Lee⁴ 等人(1999)
\text{ Lee⁴ 等人(1999)}
Lee⁴ 等人(1999)提出的非负矩阵分解(NMF)是 LSA 的一个变体。
LSA 利用 SVD 来分解 文档-术语 矩阵并提取潜在的信息(主题)。SVD 的一个特性是基向量是相互正交的,迫使基向量中的一些元素为负数。
简而言之,矩阵系数为负数的因式分解(如 SVD)给可解释性带来了问题。减法组合不允许理解一个组成部分对整体的贡献。NMF 将 文档-术语 矩阵分解为 话题-文档 矩阵
U
U
U 和 话题-术语 矩阵
V
t
V^t
Vt,与 SVD 非常相似,但有一个额外的约束条件,即
U
U
U 和
V
t
V^t
Vt 只能包含非负的元素。
此外,虽然我们利用了 U × Σ × V t U×Σ×V^t U×Σ×Vt形式的分解,但在非负矩阵因式分解的情况下,这变成了 U × V t U×V^t U×Vt。
DTM 的分解可以被设定为一个优化问题,目的是使 DTM 和它的近似值之间的差异最小。经常采用的距离测量方法是
Frobenius Norm
\text{Frobenius Norm}
Frobenius Norm 和
Kullback-Leibler Divergence
\text{Kullback-Leibler Divergence}
Kullback-Leibler Divergence。
NMF 具有与其他经典模型相同的主要优点和缺点(词包方法,需要预处理,…),但也有一些特殊的特征。
优点
文献认为,与 SVD(因此是 LSA)相比,NMF 在产生更多可解释和连贯的主题方面具有优势
(Lee⁴ 等人,1999;Xu⁹ 等人,2003;Casalino¹⁰ 等人,2016)
\text{(Lee⁴ 等人,1999;Xu⁹ 等人,2003;Casalino¹⁰ 等人,2016)}
(Lee⁴ 等人,1999;Xu⁹ 等人,2003;Casalino¹⁰ 等人,2016)。
缺点
- 非负性约束使分解更加困难,可能导致不准确的主题。
NMF是一个非凸的问题。不同的 U U U 和 V t V^t Vt 可能近似于DTM,导致不同的运行结果可能不一致。
'''
Topic Modeling with NMF: Minimum Viable Example
References:
[1] https://radimrehurek.com/gensim/models/nmf.html
'''
# Import dependencies
import gensim
import gensim.corpora as corpora
from gensim.utils import simple_preprocess
import spacy
import pyLDAvis
import pyLDAvis.gensim_models
from sklearn.datasets import fetch_20newsgroups
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
def lemmatize(docs, allowed_postags = ["NOUN", "ADJ", "VERB", "ADV"]):
'''
Performs lemmization of input documents.
Args:
- docs: list of strings with input documents
- allowed_postags: list of accepted Part of Speech (POS) types
Output:
- list of strings with lemmatized input
'''
nlp = spacy.load("en_core_web_sm", disable = ["parser", "ner"])
lemmatized_docs = []
for doc in docs:
doc = nlp(doc)
tokens = []
for token in doc:
if token.pos_ in allowed_postags:
tokens.append(token.lemma_)
lemmatized_docs.append(" ".join(tokens))
return (lemmatized_docs)
def tokenize(docs):
'''
Performs tokenization of input documents.
Args:
- docs: list of strings with input documents
Output:
- list of strings with tokenized input
'''
tokenized_docs = []
for doc in docs:
tokens = gensim.utils.simple_preprocess(doc, deacc=True)
tokenized_docs.append(tokens)
return (tokenized_docs)
# Fetch 20newsgropus dataset
docs = fetch_20newsgroups(subset = 'all', remove = ('headers', 'footers', 'quotes'))['data']
# Pre-process input: lemmatization and tokenization
lemmatized_docs = lemmatize(docs)
tokenized_docs = tokenize(lemmatized_docs)
# Mapping from word IDs to words
id2word = corpora.Dictionary(tokenized_docs)
# Prepare Document-Term Matrix
corpus = []
for doc in tokenized_docs:
corpus.append(id2word.doc2bow(doc))
# Fit NMF model: See [1] for more details
nmf_model = gensim.models.Nmf(
corpus = corpus, # Document-Term Matrix
id2word = id2word, # Map word IDs to words
num_topics = 30, # Number of latent topics to extract
random_state = 100,
passes = 100, # N° of passes through the corpus during training
)
# Get the topics sorted by sparsity
nmf_model.show_topics()
2.6 BERTopic 和 Top2Vec
Grootendorst¹¹ (2022)
\text{Grootendorst¹¹ (2022)}
Grootendorst¹¹ (2022) 和
Angelov¹² (2020)
\text{Angelov¹² (2020)}
Angelov¹² (2020) 提出了新颖的主题建模方法,分别是 BERTopic 和 Top2Vec。这些模型解决了迄今为止讨论的传统策略的局限性。我们在下面的段落中一起探讨它们。
2.6.1 文本嵌入(Document embedding)
BERTopic 和 Top2Vec 从输入文档中制造语义嵌入。
在最初的论文中,BERTopic 利用 BERT 句子变换器(SBERT)来制造高质量的、有上下文的单词和句子矢量表示。相反,Top2Vec 使用 Doc2Vec 来创建联合嵌入的单词、文档和主题向量。
在写这篇文章的时候,这两种算法都支持各种嵌入策略,尽管 BERTopic 有更广泛的嵌入模型覆盖。
| Embedding Model | BERTopic [Reference] | Top2Vec [Reference] |
|---|---|---|
| BERT Sentence Transformers [Reference] | ✔️ original paper | ✔️ |
| Doc2Vec | ✔️ with custom embeddings | ✔️ original paper |
| HuggingFace Transformers | ✔️ | |
| Flair | ✔️ | |
| Spacy | ✔️ | |
| Universal Sentence Encoder (USE) | ✔️ | ✔️ |
| Gensim | ✔️ | |
| Combinations for word and document embeddings | ✔️ | |
| Custom Backend / Embeddings | ✔️ |
BERTopic 和
Top2Vec 支持的嵌入模型。
2.6.2 用UMAP降低维度
人们可以直接对嵌入采用聚类算法,但这将增加计算消耗,并导致聚类性能不佳(由于 维度诅咒)。
因此,在聚类之前要应用降维技术。UMAP,Uniform Manifold Approximation and Projection
(McInnes¹³等人,2018)
\text{(McInnes¹³等人,2018)}
(McInnes¹³等人,2018) 提供了几个好处。
- 它在较低的投影维度上保留了更多高维数据的局部和全局特征 (McInnes¹³等人,2018) \text{(McInnes¹³等人,2018)} (McInnes¹³等人,2018)。
UMAP对嵌入尺寸没有计算限制 (McInnes¹³等人,2018) \text{(McInnes¹³等人,2018)} (McInnes¹³等人,2018)。因此,它可以有效地使用不同的文档嵌入策略。- 用
UMAP降低嵌入维度可以提高K-Means和HDBSCAN在精度和时间上的聚类性能 (Allaoui¹⁴等人,2020) \text{(Allaoui¹⁴等人,2020)} (Allaoui¹⁴等人,2020)。 UMAP可以很容易地扩展到大型数据集 (Angelov¹², 2020) \text{(Angelov¹², 2020)} (Angelov¹², 2020)。
2.6.3 聚类
BERTopic 和 Top2Vec 最初都是利用 HDBSCAN
(McInnes¹⁵等人,2017)
\text{(McInnes¹⁵等人,2017)}
(McInnes¹⁵等人,2017)作为聚类算法的。
优点
HDBSCAN继承了DBSCAN的优点并加以改进 (McInnes¹⁵等人,2017) \text{(McInnes¹⁵等人,2017)} (McInnes¹⁵等人,2017)。HDBSCAN(和DBSCAN一样)并不强迫观测值进入一个群组。它将不相关的观察值作为离群值。这提高了主题的代表性和一致性。
缺点
将不相关的文档建模为离群值可能会导致信息损失。在嘈杂的数据集中,异常值可能成为原始语料库的相关部分。
BERTopic 目前也支持 K-Means 和层次聚类算法,提供灵活的选择。K-Means 允许选择所需的聚类数量,并强制每个文档进入一个聚类。这避免了异常值的产生,但也可能导致较差的主题代表性和一致性。
2.6.4 主题表示
BERTopic 和 Top2Vec 在为主题制造表示方法上有所不同。
BERTopic 将同一聚类(主题)内的所有文档连接起来,并应用一个修改过的
T
F
−
I
D
F
TF-IDF
TF−IDF。简而言之,它用原始
T
F
−
I
D
F
TF-IDF
TF−IDF 公式中的聚类来代替文档。然后,它使用每个集群的第一个最重要的词作为主题的代表。
这个分数被称为基于类的 T F − I D F TF-IDF TF−IDF( c TF-IDF \text{c TF-IDF} c TF-IDF),因为它估计的是集群中的词的重要性,而不是文档。
相反,Top2Vec 用最接近集群中心点的词来制造一个表示。特别是,对于通过 HDBSCAN 获得的每个密集区域,它计算原始维度的文档向量的中心点,然后选择最接近的单词向量。
BERTopic 和 Top2Vec 的优点
- 主题的数量不一定事先给定。
BERTopic和Top2Vec都支持分层减少主题以优化主题的数量。 - 高质量的嵌入考虑到了语料库中词与词之间的语义关系,这与词包的方法不同。这导致了更好和更多信息的主题。
- 由于嵌入的语义性质,在大多数情况下不需要对文本进行预处理(词干提取、词形还原、去掉停止词…)。
BERTopic支持动态主题建模。- 模块化。每个步骤(文档嵌入、降维、聚类)实际上都是自洽的,并且可以根据该领域的进展、特定项目的特殊性或技术限制来改变或发展。例如,我们可以使用带有
Doc2Vec嵌入的BERTopic而不是SBERT,或者应用K-Means聚类代替HDBSCAN。
与传统方法相比,它们在大型语料库中的扩展性更好 (Angelov¹²,2020) \text{(Angelov¹²,2020)} (Angelov¹²,2020)。
BERTopic 和 Top2Vec 都提供先进的内置搜索和可视化功能。它们使调查主题的质量和推动进一步的优化变得更加简单,同时也为演示制作了高质量的图表。
BERTopic 和 Top2Vec 的缺点
- 它们对较短的文本效果更好,例如社交媒体帖子或新闻标题。大多数基于转化器的嵌入在建立语义表征时,对它们所能考虑的标记数量都有限制。在较长的文档中使用这些算法是可能的。例如,人们可以在嵌入步骤之前,将文档分成句子或段落。然而,对于较长的文档来说,这不一定有利于生成有意义和有代表性的主题。
- 每个文档只被分配给一个主题。相反,像
LDA这样的传统方法是建立在每个文档包含一个混合主题的假设之上的。 - 与传统模型相比,它们的速度较慢 (Grootendorst¹¹,2022) \text{(Grootendorst¹¹,2022)} (Grootendorst¹¹,2022)。此外,更快的训练和推理可能需要更昂贵的硬件加速器(GPU)。
- 虽然
BERTopic利用基于转换器的大型语言模型来制造文档嵌入,但主题表示仍然使用词包方法 (c TF-IDF) \text{(c TF-IDF)} (c TF-IDF)。
对于小型数据集( < 1000 <1000 <1000 份文件),它们可能不太有效 (Egger¹⁶等人,2022) \text{(Egger¹⁶等人,2022)} (Egger¹⁶等人,2022)。
'''
Topic Modeling with BERTopic: Minimum Viable Example
References:
[1] https://maartengr.github.io/BERTopic/getting_started/embeddings/embeddings.html
[2] https://maartengr.github.io/BERTopic/getting_started/clustering/clustering.html
[3] https://maartengr.github.io/BERTopic/getting_started/visualization/visualization.html
'''
from bertopic import BERTopic
from sentence_transformers import SentenceTransformer
from hdbscan import HDBSCAN
from sklearn.datasets import fetch_20newsgroups
# Fetch 20newsgropus dataset
docs = fetch_20newsgroups(subset = 'all', remove = ('headers', 'footers', 'quotes'))['data']
# Embedding model: See [1] for more details
embedding_model = SentenceTransformer("all-MiniLM-L6-v2")
# Clustering model: See [2] for more details
cluster_model = HDBSCAN(min_cluster_size = 15,
metric = 'euclidean',
cluster_selection_method = 'eom',
prediction_data = True)
# BERTopic model
topic_model = BERTopic(embedding_model = embedding_model,
hdbscan_model = cluster_model)
# Fit the model on a corpus
topics, probs = topic_model.fit_transform(docs)
# Visualization examples: See [3] for more details
# Save intertopic distance map as HTML file
topic_model.visualize_topics().write_html("/intertopic_dist_map.html")
# Save topic-terms barcharts as HTML file
topic_model.visualize_barchart(top_n_topics = 25).write_html("/barchart.html")
# Save documents projection as HTML file
topic_model.visualize_documents(docs).write_html("/projections.html")
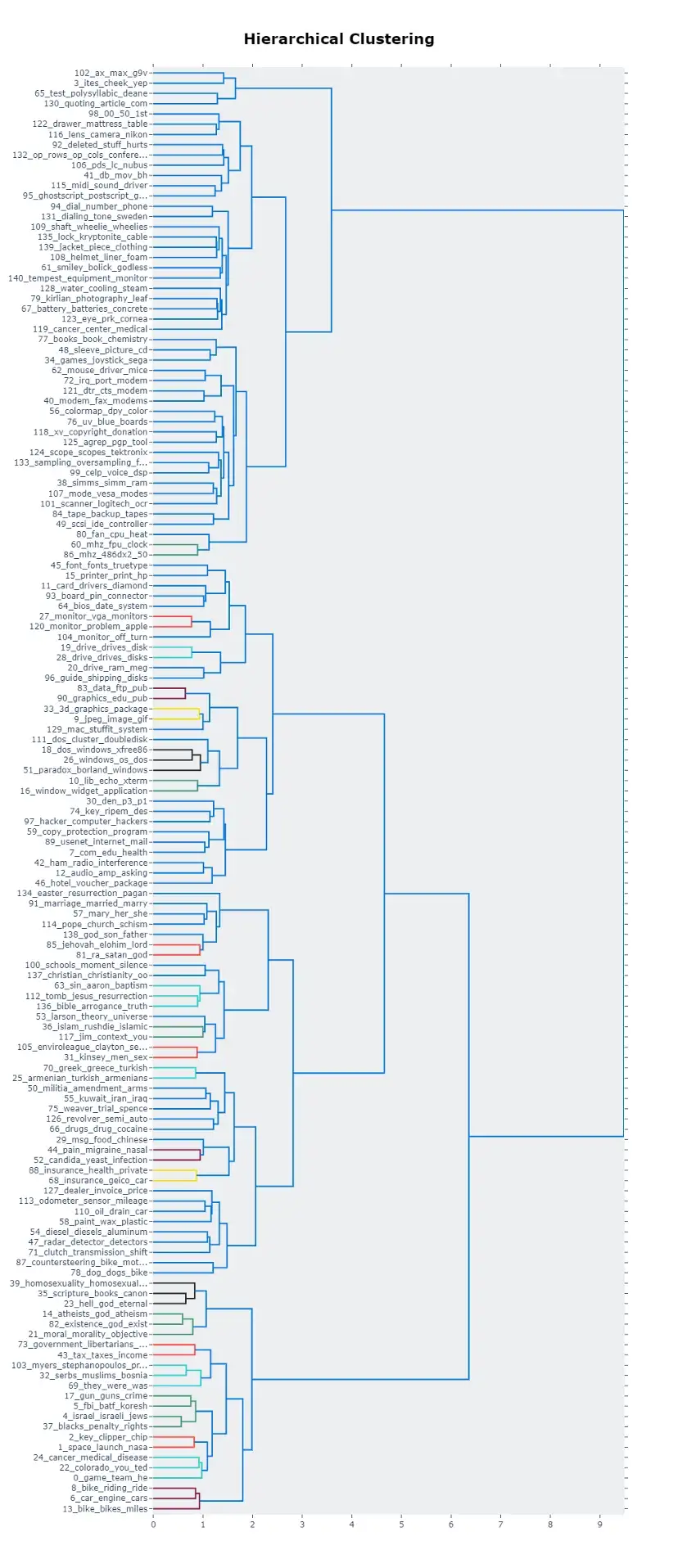
# Save topics dendrogram as HTML file
topic_model.visualize_hierarchy().write_html("/hieararchy.html")

pyLDAvis 得到的相似

'''
Topic Modeling with Top2Vec: Minimum Viable Example
References:
[1] https://github.com/ddangelov/Top2Vec
[2] https://top2vec.readthedocs.io/_/downloads/en/stable/pdf/
'''
from top2vec import Top2Vec
from sklearn.datasets import fetch_20newsgroups
# Fetch 20newsgropus dataset
docs = fetch_20newsgroups(subset = 'all', remove = ('headers', 'footers', 'quotes'))['data']
# Create jointly embedded topic, document and word vectors
topic_model = Top2Vec(
docs,
embedding_model = 'doc2vec', # Embedding model: See [1,2] for supported models
min_count = 50, # Ignore words less frequent than this value
umap_args = None, # Dict of custom args for UMAP
hdbscan_args = None # Dict of custom argd for HDBSCAN
)
# Visualization examples: See [1,2] for more details
# Search the closest 5 topics to the input query "faith"
topic_words, word_scores, topic_scores, topic_nums = topic_model.search_topics(
keywords = ["faith"],
num_topics = 5)
# Plot the resulting topics as wordclouds
for topic in topic_nums:
topic_model.generate_topic_wordcloud(topic)

3.比较
下表总结了不同主题建模策略在实际应用场景中的突出特点。
| Metric | LDA | NMF | BERTopic | Top2Vec |
|---|---|---|---|---|
| Number of topics | ❌ The number of topics must be known beforehand | ❌ The number of topics must be known beforehand | ✔️ Finds automatically the number of topics | ✔️ Finds automatically the number of topics |
| Data preparation | ❌ Pre-processing is essential | ❌ Pre-processing is essential | ✔️ Pre-processing not needed in most cases | ✔️ Pre-processing not needed in most cases |
| Document-topic relationship | ✔️ Each document is composed of a mixture of topics | ✔️ Each document is composed of a mixture of topics | ❌ Each document is assigned to one topic only | ❌ Each document is assigned to one topic only |
| Topic representation | ❌ Bag-of-words disregards semantics | ❌ Bag-of-words disregards semantics | ✔️ Semantic embeddings lead to more meaningful and coherent topics. TF-IDF (bag-of-words) based strategy for topic description. | ✔️ Semantic embeddings lead to more meaningful and coherent topics. Centroid-based strategy for topic description. |
| Finding the optimal number of topics | ❌ More complex | ❌ More complex | ✔️ Support for hierarchical topic reduction | ✔️ Support for hierarchical topic reduction |
| Outliers | ✔️ No outliers | ✔️ No outliers | ✔️ HDBSCAN leads to more coherent and consistent topics, but at the price of having a significant portion of outliers. K-Means can be used instead to avoid this behaviour | ❌ HDBSCAN leads to more coherent and consistent topics, but at the price of having a significant portion of outliers |
| Longer input documents | ✔️ | ✔️ | ❌ Better performances with shorter documents. Most embedding models have a limit on the number of input tokens. Strategy could deal with this (splitting, averaging, …) but may not necessarily lead to better topics | ❌ Better performances with shorter documents. Most embedding models have a limit on the number of input tokens. Strategy could deal with this (splitting, averaging, …) but may not necessarily lead to better topics |
| Shorter input documents | ✔️ | ✔️ | ✔️ | ✔️ |
| Small datasets (<1000 docs) | ✔️ | ✔️ | ❌ May be less effective with small datasets | ❌ May be less effective with small datasets |
| Large datasets (>1000 docs) | ✔️ | ✔️ | ✔️ Scales better with larger corpora than traditional models | ✔️ Scales better with larger corpora than traditional models |
| Dynamic Topic Modeling | ✔️ See Blei and Lafferty, 2006 and Hoffman and Blei, 2010. Dynamic Topic Modeling with LDA Sequence model in Gensim, and from Jiaxiang Li for sklearn/Gensim | ❌ | ✔️ BERTopic supports dynamic Topic Modeling | ❌ |
| Speed & Resources | ✔️ | ✔️ | ❌ Longer training times compared to classical models and potentially expensive computational resources (GPU). Optimization strategies exist, but LDA and NMF remain faster and less expensive | ❌ Longer training times compared to classical models and potentially expensive computational resources (GPU). Optimization strategies exist, but LDA and NMF remain faster and less expensive |
| Visualization & Search | ✔️ pyLDAvis for visualization; no search capabilities | ❌ | ✔️ Advanced visualization and search tools | ✔️ Advanced visualization and search tools |
不同主题建模技术之间的比较。注:LSA 和 pLSA 没有包括在内,因为 LDA 克服了它们的局限性,它被认为是这三种方法中最好的。
这个总结表为一个特定的用例提供了高层次的选择标准。
想象一下,需要在推文中找到趋势性的话题,而不需要做什么预处理。在这种情况下,人们可以选择使用 Top2Vec 和 BERTopic。它们在较短的文本来源上工作得非常出色,不需要太多的预处理。
相反,想象一下这样的场景:客户对发现一个给定的文件如何包含多个主题的混合物感兴趣。在这种情况下,像 LDA 和 NMF 这样的方法会比较好。BERTopic 和 Top2Vec 只将一个文档分配给一个主题。尽管 HDBSCAN 的概率分布可以作为主题分布的代理,但 BERTopic 和 Top2Vec 在设计上不是混合成员模型。
4.补充说明
在讨论主题建模时,有两个值得注意的点。
4.1 一个主题并不(一定)是我们认为的那样
当我们在等候室看到一本杂志时,我们一眼就知道它属于哪种类型。当我们进入一场谈话时,几句话就足以让我们猜到讨论的对象。从人的角度看,这是一个 “话题”。
不幸的是,“话题” 一词在迄今为止讨论的模型中具有完全不同的含义。
让我们记住 文档-单词 矩阵。在高层次上,我们想把它分解为 文档-主题 和 主题-单词 矩阵的产物,并在这个过程中提取潜在的维度–话题。这些策略(如 LSA)的目标是使分解误差最小化。
概率生成模型(如 LDA)以稳健而优雅的贝叶斯方法增加了一层统计形式主义,但它们真正要做的是以最小的误差重现原始 文档-单词 分布。
这些模型都不能确保获得的主题从人类的角度来看是有信息的或有用的。
用 Blei³ 等人(2013) \text{Blei³ 等人(2013)} Blei³ 等人(2013)的话来说。
我们将
LDA模型中的潜在多项式变量称为话题,以便利用面向文本的直觉,但除了在代表词组的概率分布方面的效用外,我们对这些潜在变量没有提出认识论上的主张。
另一方面,BERTopic 和 Top2Vec 利用了语义嵌入。因此,用于表示文档的向量从 “人类” 的角度来看,带有一个代理(到目前为止我们最接近的)其 “意义”。这些惊人的模型假设,对这些嵌入的投影进行聚类可能会导致更有意义和具体的主题。
研究(举几个例子: Grootendorst¹¹ 2022, Angelov¹² 2020, Egger¹⁶ et al. 2022 \text{Grootendorst¹¹ 2022, Angelov¹² 2020, Egger¹⁶ et al. 2022} Grootendorst¹¹ 2022, Angelov¹² 2020, Egger¹⁶ et al. 2022)表明,利用语义嵌入获得的话题在多个领域中信息量更大,也更连贯。
请不要误会:这是一个杰出而独特的结果,它在该领域开辟了一个全新的领域,并取得了前所未有的表现。
但是我们仍然可以就这如何接近人类对主题的定义,以及在什么情况下,进行辩论。
如果你认为这是一个微不足道的细枝末节,你有没有试过向商业利益相关者解释 mail_post_email_posting 这样的话题?是的,它是连贯的,可解释的,但这是他们想象中的 “主题” 吗?
4.2 主题不容易评估
主题建模是一种无监督的技术。在评估过程中,没有标签可以依赖。
人们已经提出了一些一致性的测量方法来评估主题的可解释性质量。例如,归一化的点相互信息(Normalized pointwise mutual information,NPMI)
(Bouma¹⁷,2009)
\text{(Bouma¹⁷,2009)}
(Bouma¹⁷,2009)估计两个词
x
x
x 和
y
y
y 的共同出现的可能性比我们偶然预期的要大。
N P M I = l o g [ p ( x ) p ( y ) ] l o g p ( x , y ) − 1 NPMI=\frac{log[p(x)p(y)]}{logp(x,y)}-1 NPMI=logp(x,y)log[p(x)p(y)]−1
N P M I NPMI NPMI 可以从 − 1 -1 −1(无共现)到 + 1 +1 +1(完全共现)不等。 x x x 和 y y y 的出现是独立的,因此 N P M I = 0 NPMI=0 NPMI=0。
Lau¹⁸ 等人(2014) \text{Lau¹⁸ 等人(2014)} Lau¹⁸ 等人(2014)认为,这个指标在一定程度上合理地模拟了人类的判断。
也存在其他的连贯性测量。例如,Cv
(R
o
¨
der¹⁹ 等人,2015)
\text{(Röder¹⁹ 等人,2015)}
(Ro¨der¹⁹ 等人,2015)和 UMass
(Mimno²⁰ 等人,2011)
\text{(Mimno²⁰ 等人,2011)}
(Mimno²⁰ 等人,2011)。
这些一致性指标存在着一系列的缺点。
- 对于使用哪种指标来衡量定性表现,没有共同的约定 (Zuo²¹ 等人,2016;Blair²² 等人,2020;Doogan²³ 等人,2021) \text{(Zuo²¹ 等人,2016;Blair²² 等人,2020;Doogan²³ 等人,2021)} (Zuo²¹ 等人,2016;Blair²² 等人,2020;Doogan²³ 等人,2021)。
-
Blair²² 等人,(2020)
\text{Blair²² 等人,(2020)}
Blair²² 等人,(2020) 报告了不同的一致性衡量标准之间不一致的结果。
Doogan²³ 等人,(2021) \text{Doogan²³ 等人,(2021)} Doogan²³ 等人,(2021) 表明,在评估特定领域(Twitter 数据)的主题模型时,一致性措施是不可靠的。 - Hoyle²⁴ 等人,(2021) \text{Hoyle²⁴ 等人,(2021)} Hoyle²⁴ 等人,(2021) 提出 N P M I NPMI NPMI 等指标可能无法评估神经主题模型的可解释性。
- 由于报告的不一致性,
Cv的使用被其作者劝阻²⁵。
正如 Grootendorst¹¹(2022) \text{Grootendorst¹¹(2022)} Grootendorst¹¹(2022)所写的那样。
“验证措施,如话题一致性和话题多样性,是本质上的主观评价的代理。一个用户对一个话题的一致性和多样性的判断可能与另一个用户不同。因此,尽管这些措施可以用来获得一个模型性能的指示,但它们仅仅是一个指示”。
总而言之,验证措施不能清晰地估计一个主题模型的性能。它们不能像分类问题中的准确性或 F 1 F_1 F1 分数那样提供明确的解释。因此,对所获得的主题的 “良好程度” 的量化仍然需要领域知识和人工评估。对商业价值的评估(“这些主题会给项目带来好处吗?”)也不是一件小事,可能需要综合的衡量标准和整体的方法。
5. 结论
在这篇文章中,我们通俗地介绍了流行的主题建模算法,从生成性统计模型到基于转化器的方法。
我们还提供了一个表格,强调了每种技术的优势和劣势。这可以用来进行比较,并帮助在不同场景下进行初步的模型选择。
最后,我们分享了无监督文本数据分析中最具挑战性的两个方面。
首先,人类对 “主题” 的定义与作为 “主题建模” 算法结果的统计对应物之间的差异,常常被忽视。对这种差异的理解对于实现项目目标和指导商业利益相关者在 NLP 努力中的期望是至关重要的。
然后,我们通过介绍流行的指标和它们的缺点,讨论了定量评估主题模型性能的困难。
6. 参考文献
[1] Deerwester et al., Indexing by latent semantic analysis, Journal of the American Society for Information Science, Volume 41, Issue 6 p. 391–407, 1990 (link).
[2] Hofmann, Probabilistic Latent Semantic Analysis, Proceedings of the XV Conference on Uncertainty in Artificial Intelligence (UAI1999), 1999 (link).
[3] Blei et al., Latent dirichlet allocation, The Journal of Machine Learning Research, Volume 3, p. 993–1022, 2003 (link).
[4] Lee et al., Learning the parts of objects by non-negative matrix factorization, Nature, Volume 401, p. 788–791, 1999 (link).
[5] Barbieri et al., Probabilistic topic models for sequence data, Machine Learning, Volume 93, p. 5–29, 2013 (link).
[6] Rizvi et al., Analyzing social media data to understand consumers’ information needs on dietary supplements, Stud. Health Technol. Inform., Volume 264, p. 323–327, 2019 (link).
[7] Alnusyan et al., A semi-supervised approach for user reviews topic modeling and classification, International Conference on Computing and Information Technology, 1–5, 2020 (link).
[8] Egger and Yu, Identifying hidden semantic structures in Instagram data: a topic modelling comparison, Tour. Rev. 2021:244, 2021 (link).
[9] Xu et al., Document clustering based on non-negative matrix factorization, Proceedings of the 26th annual international ACM SIGIR conference on Research and development in information retrieval, p. 267–273, 2003 (link).
[10] Casalino et al., Nonnegative matrix factorizations for intelligent data analysis, Non-negative Matrix Factorization Techniques. Springer, p. 49–74, 2016 (link).
[11] Grootendorst, BERTopic: Neural topic modeling with a class-based TF-IDF procedure, 2022 (link).
[12] Angelov, Top2Vec: Distributed Representations of Topics, 2020 (link).
[13] McInnes et al., UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction, 2018 (link).
[14] Allaoui et al., Considerably improving clustering algorithms using umap dimensionality reduction technique: A comparative study, International Conference on Image and Signal Processing, Springer, p. 317–325, 2020 (link).
[15] McInnes et al., hdbscan: Hierarchical density based clustering, The Journal of Open Source Software, 2(11):205, 2017 (link).
[16] Egger et al., A Topic Modeling Comparison Between LDA, NMF, Top2Vec, and BERTopic to Demystify Twitter Posts, Frontiers in Sociology, Volume 7, Article 886498, 2022 (link).
[17] Bouma, Normalized (pointwise) mutual information in collocation extraction, Proceedings of GSCL, 30:31–40, 2009 (link).
[18] Lau et al., Machine reading tea leaves: Automatically evaluating topic coherence and topic model quality, Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics, p. 530–539, 2014 (link).
[19] Röder et al., Exploring the space of topic coherence measures, Proceedings of the eighth ACM international conference on Web search and data mining, p. 399–408. ACM, 2015 (link).
[20] Mimno et al., Optimizing semantic coherence in topic models, Proc. of the Conf. on Empirical Methods in Natural Language Processing, p. 262–272, 2011 (link).
[21] Y. Zuo et al., Word network topic model: a simple but general solution for short and imbalanced texts, Knowledge and Information Systems, 48(2), p. 379–398 (link)
[22] Blair et al., Aggregated topic models for increasing social media topic coherence, Applied Intelligence, 50(1), p. 138–156, 2020 (link).
[23] Doogan et al., Topic Model or Topic Twaddle? Re-evaluating Semantic Interpretability Measures, Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, p. 3824–3848, 2021 (link).
[24] Hoyle et al., Is automated topic model evaluation broken? the incoherence of coherence, Advances in Neural Information Processing Systems, 34, 2021 (link).
[25] https://github.com/dice-group/Palmetto/issues/13
数据集:本帖中的 Python 例子使用了 scikit-learn 软件包提供的 “20个新闻组数据集”。







![[MAUI]模仿Chrome下拉标签页的交互实现](https://img-blog.csdnimg.cn/fc17be3ae466459b960abd1aa0e31680.gif)