文章目录
- 一、8.0版本的递归
- 1、CTE递归
- 2、举例
- 3、递归CTE的限制
- 二、5.7版本的递归
- 1、find_in_set 函数
- 2、concat函数
- 3、自定义函数实现递归查询
- 4、向上递归
- 5、可能遇到的问题
一、8.0版本的递归
1、CTE递归
先看8.0版本的递归查询CET。语法规则:
WITH RECURSIVE cte_name[(col_name [, col_name] ...)] AS (
initial_query -- anchor member
UNION ALL
recursive_query -- recursive member that references to the CTE name
)
SELECT * FROM cte_name;
以上SQL主要有三部分组成:
➢ 形成CTE结构的基本结果集的初始查询(initial_query),初始查询部分被称为锚成员
➢ 递归查询部分是引用CTE名称的查询,因此称为递归成员。递归成员由一个UNION、UNION ALL或者UNION DISTINCT运算符与锚成员相连
➢ 终止条件是当递归成员没有返回任何行时,确保递归停止
2、举例
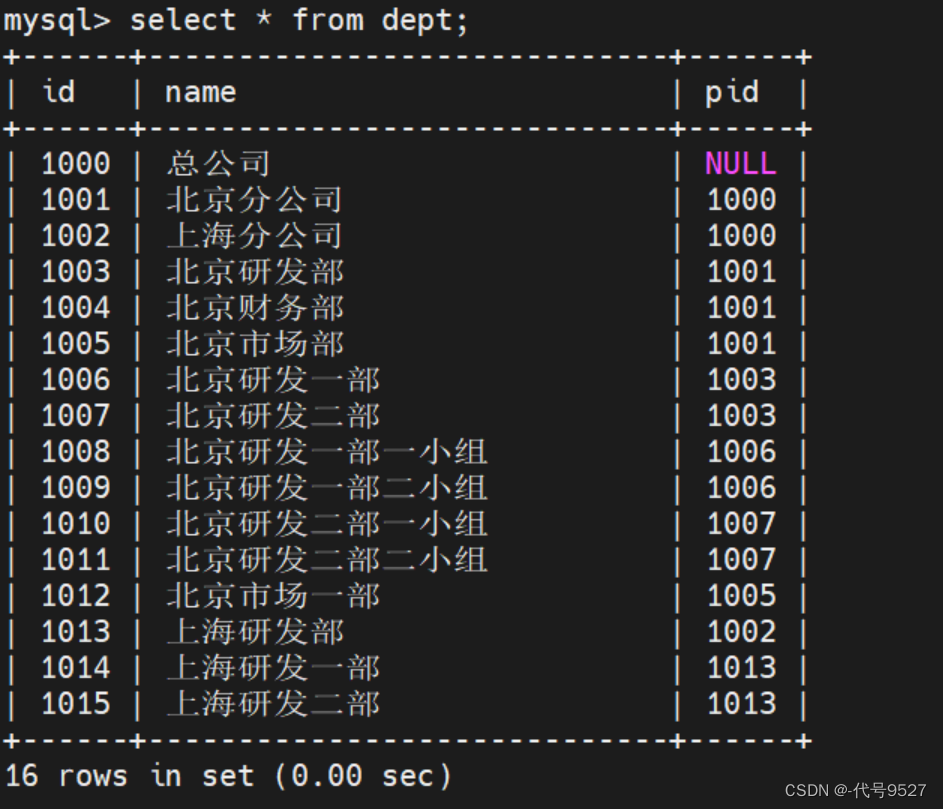
递归某公司部门信息,用下其他帖子的测试数据:
DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (
`id` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`pid` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1000', '总公司', NULL);
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1001', '北京分公司', '1000');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1002', '上海分公司', '1000');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1003', '北京研发部', '1001');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1004', '北京财务部', '1001');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1005', '北京市场部', '1001');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1006', '北京研发一部', '1003');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1007', '北京研发二部', '1003');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1008', '北京研发一部一小组', '1006');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1009', '北京研发一部二小组', '1006');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1010', '北京研发二部一小组', '1007');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1011', '北京研发二部二小组', '1007');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1012', '北京市场一部', '1005');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1013', '上海研发部', '1002');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1014', '上海研发一部', '1013');
INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1015', '上海研发二部', '1013');
此时表数据:
接下来写这个树形结构的CET递归SQL:
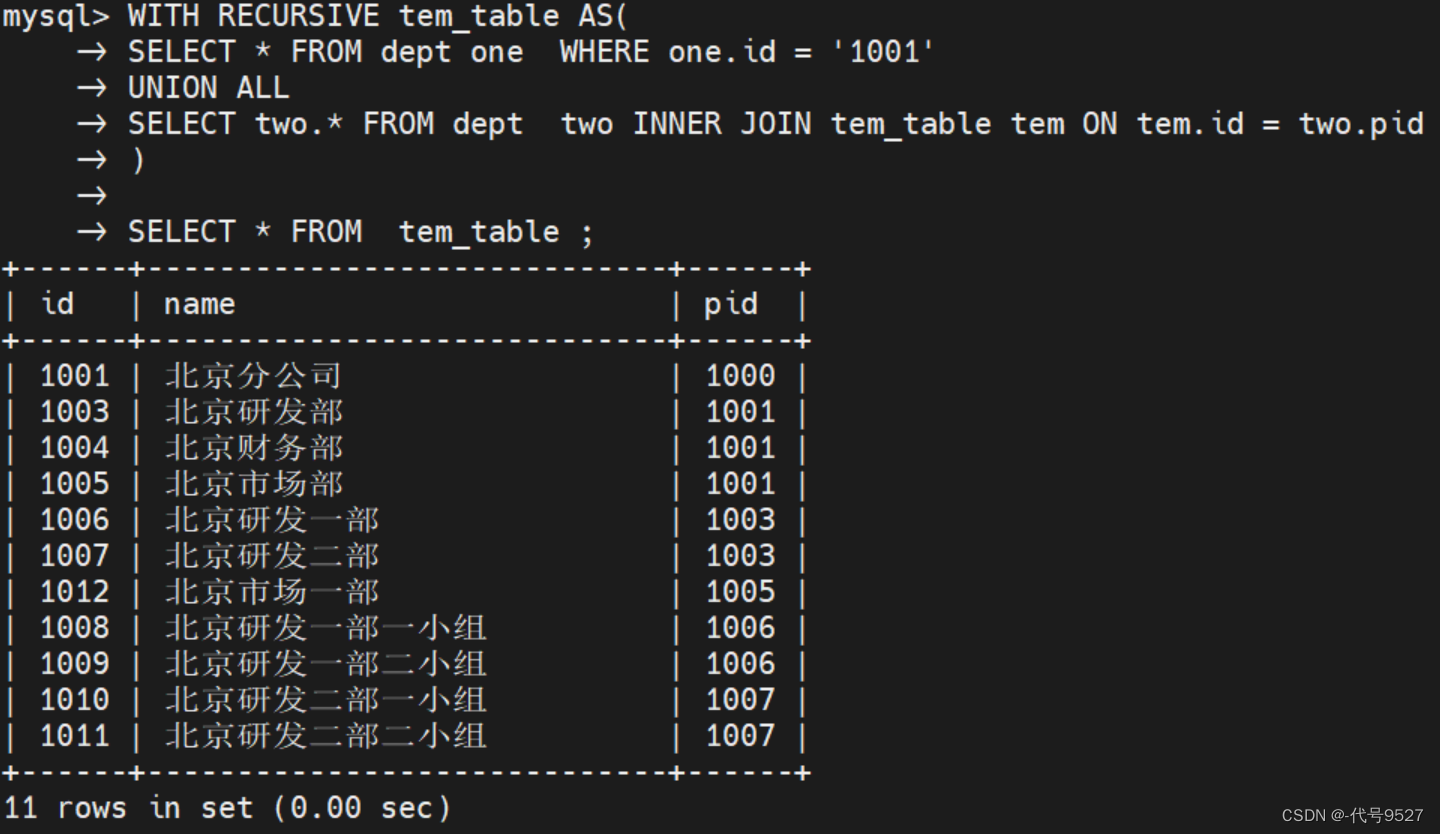
with recursive t_tem as (
select * from dept where id= '1001'
union all
select d.* from dept d inner join t_tem t on t.id = d.pid
)
select * from t_tem ;
- t_tem 是一个表名
- 使用UNION ALL 不断将每次递归得到的数据加入到表t_tem 中
- select * from dept where id= ‘1001’ 即t_tem 表中的初始数据是id=1000的记录,即根节点
- 通过inner join t_tem t on t.id = d.pid 找到id='1001’的下级节点
- 最后select * from t_tem 拿递归得到的所有数据
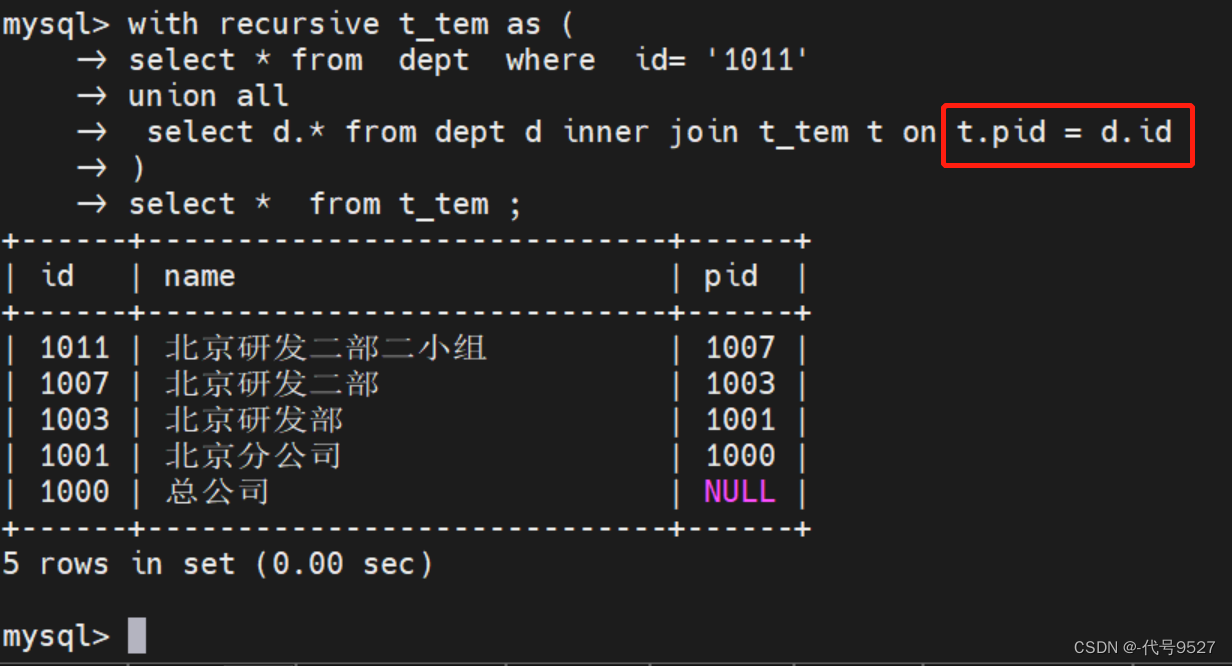
以上是向下递归,即查父查子。向上递归则稍微改一下就行:
with recursive t_tem as (
select * from dept where id= '1011'
union all
select d.* from dept d inner join t_tem t on t.pid = d.id
)
select * from t_tem ;
3、递归CTE的限制
递归CTE的查询语句中需要包含一个终止递归查询的条件。当由于某种原因在递归CTE的查询语句中未设置终止条件时,MySQL会根据相应的配置信息,自动终止查询并抛出相应的错误信息。在MySQL中默认提供了如下两个配置项来终止递归CTE。
- cte_max_recursion_depth:如果在定义递归CTE时没有设置递归终止条件,当达到cte_max_recursion_depth参数设置的执行次数后,MySQL会报错。
- max_execution_time:表示SQL语句执行的最长毫秒时间,当SQL语句的执行时间超过此参数设置的值时,MySQL报错。
---查看、修改cte_max_recursion_depth参数的默认值
--- 默认1000
SHOW VARIABLES LIKE 'cte_max%';
--- 会话级别设置该值
SET SESSION cte_max_recursion_depth=999999999;
---查看、修改MySQL中max_execution_time参数的默认值
--- 0:表示没有限制
SHOW VARIABLES LIKE 'max_execution%';
---单位为毫秒
SET SESSION max_execution_time=1000;
二、5.7版本的递归
8.0以下不支持CTE递归,先看下要用的几个函数。
1、find_in_set 函数
语法:
find_in_set(str,strlist)
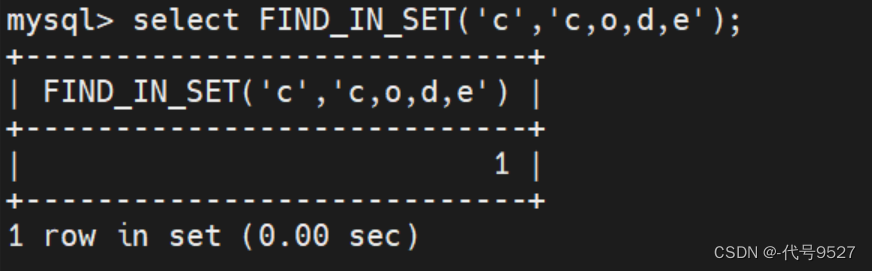
作用:
查找 str 字符串在字符串 strlist 中的位置,返回结果为 1 ~ n 。若没有找到,则返回0。
举例:
select FIND_IN_SET('c','c,o,d,e');
举例:
select * from dept where FIND_IN_SET(id,'1000,1001,1002');
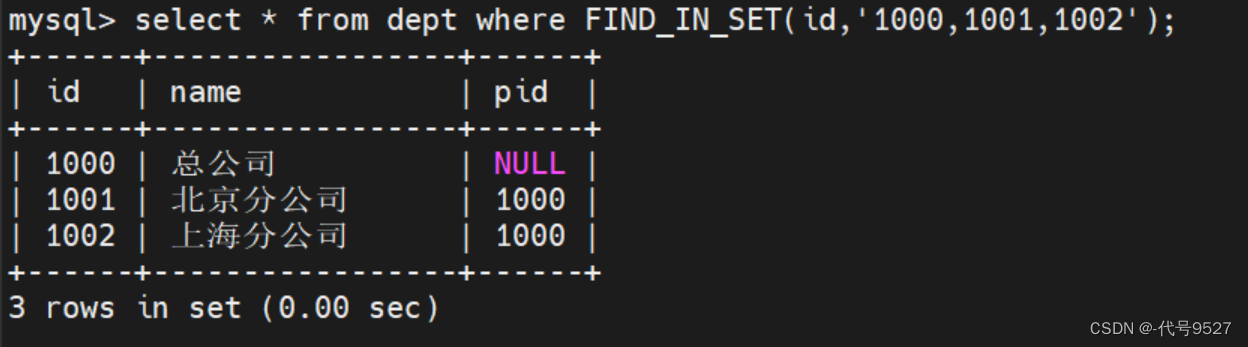
到此,如果我们可以把某个节点的和其所有子节点的id用逗号拼接成上面函数中的strlist,就可以得到所需的数据了。
2、concat函数
concat函数是MySQL中用来拼接字符串的。
语法:
select CONCAT(column 1, column 2) from xxx
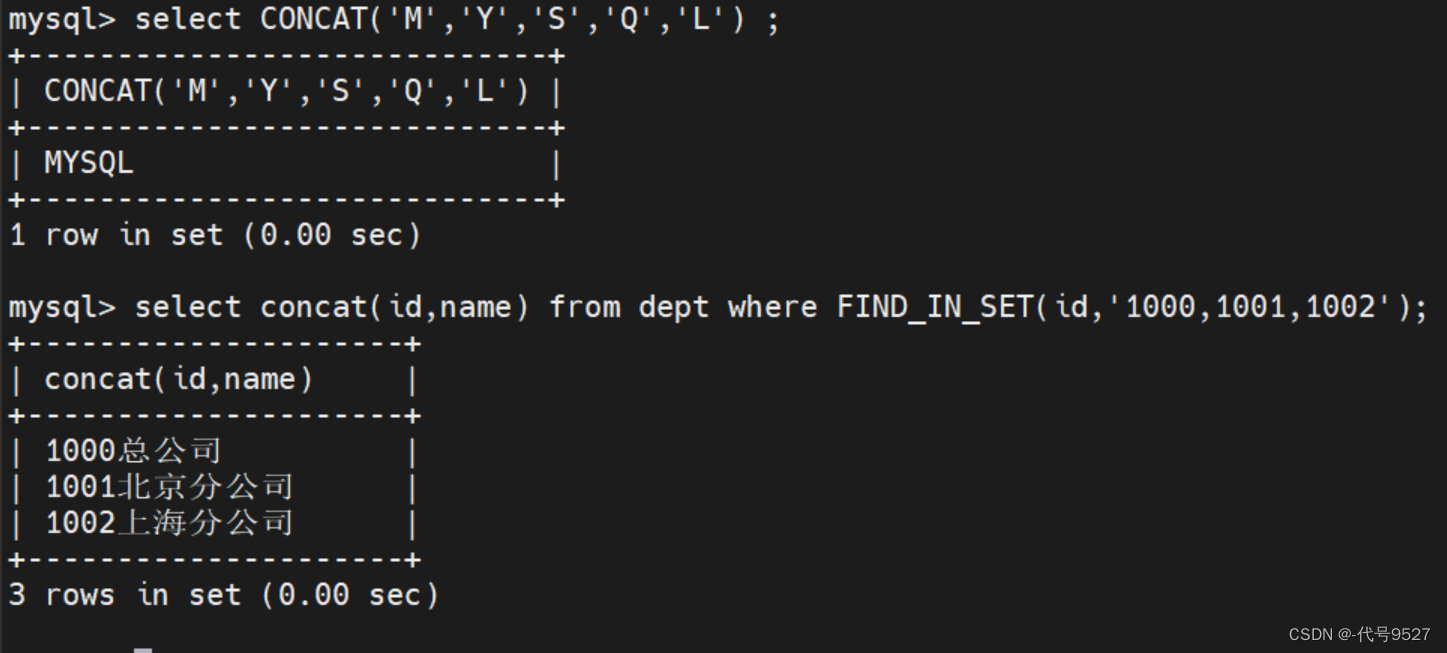
在concat的基础上,还有concat_ws 则可以指定分隔符,第一个参数传入分隔符。
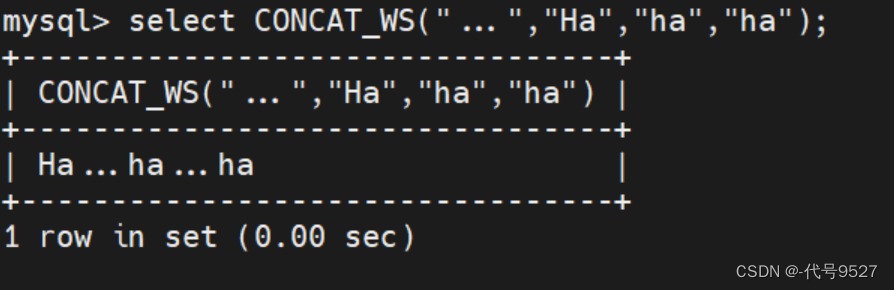
select CONCAT_WS("...","Ha","ha","ha");
group_concat函数 可以对将要拼接的字段值去重,也可以排序,指定分隔符。若没有指定,默认以逗号分隔
group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator '分隔符'] )
3、自定义函数实现递归查询
delimiter $$
drop function if exists get_child_list$$
create function get_child_list(in_id varchar(10)) returns varchar(1000)
begin
declare ids varchar(1000) default '';
declare tempids varchar(1000);
set tempids = in_id;
while tempids is not null do
set ids = CONCAT_WS(',',ids,tempids);
select GROUP_CONCAT(id) into tempids from dept where FIND_IN_SET(pid,tempids)>0;
end while;
return ids;
end
$$
delimiter ;
解释:
delimiter $$,定义结束符为$$,MySQL默认语句的结束为封号,但在函数定义中我希望封号不是结束。- drop function if exists get_child_list,和drop table if exists xx目的类似
- create function get_child_list 创建函数,后面是传形参的类型和形参名、返回值类型
- begin 和 end 中间包围的就是函数体,真正的逻辑部分
- declare 声明变量,default 给变量设置默认值,这里声明ids是为了后面拼接递归字符串,并返回给调用者
- tempids 是为了记录下边 while 循环中临时生成的所有子节点以逗号拼接成的字符串
- set 用来给变量赋值
- while do … end while; 循环语句,end while 末尾需要加上分号
- CONCAT_WS 函数把最终结果 ids 和 临时生成的 tempids 用逗号拼接起来
- FIND_IN_SET(pid,tempids)>0 为条件,遍历在 tempids 中的所有 pid
- GROUP_CONCAT(id) into tempids 把这些子节点 id 都用逗号拼接起来,并覆盖更新 tempids
- 等下次循环进来时,就会再次拼接并覆盖tempids ,并再次查找所有子节点的所有子节点。没有子节点时,拼接为空,tempids为空,循环结束
- delimiter ; 把结束符重新设置为默认的结束符分号
定义变量:
declare 变量名[,变量名2…] 变量类型 [default 默认值]
赋值变量:
set 变量名1=变量值1(或者表达式)[ ,变量名2=变量值2(或者表达式)]
使用变量:
select 列名[,列名…] into 变量名1[,变量名二…]
以这个表为例:
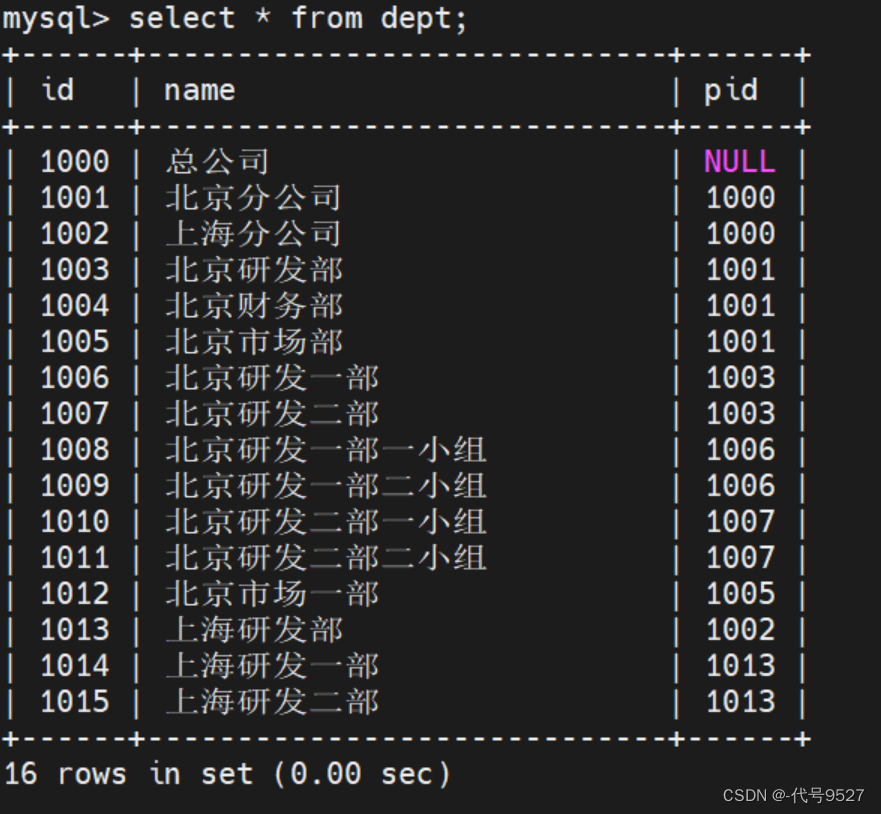
调用上面定义的函数,传参1000:ids='' , tempids=1000,进入while循环
- 第一次循环:ids = 1000, tempids = 1001,1002(找pid为tempids的节点id拼接,并覆盖tempids的值,到此,1000子节点的id被全部拿走拼接)
- 第二次循环:ids=1000,1001,1002 tempids=1003,1104,1005,1013(到此,id为1000的孙子节点全部拿到)
- 第三次循环:ids=1000,1001,1002,1003,1104,1005,1013,tempids = 1006,1007,1012,1014,1015(id为1000的孙节点的子节点全部拿到)
- 第四次循环:ids=1000,1001,1002,1003,1104,1005,1013,1006,1007,1012,1014,1015 tempids = 1008,1009,1010,1011
- 第五次循环:ids=1000,1001,1002,1003,1104,1005,1013,1006,1007,1012,1014,1015,1008,1009,1010,1011 tempids = null(上一次循环的id,不是任何节点的pid,即没有子节点了,遍历完了)
- while tempids is not null不成立,跳出循环
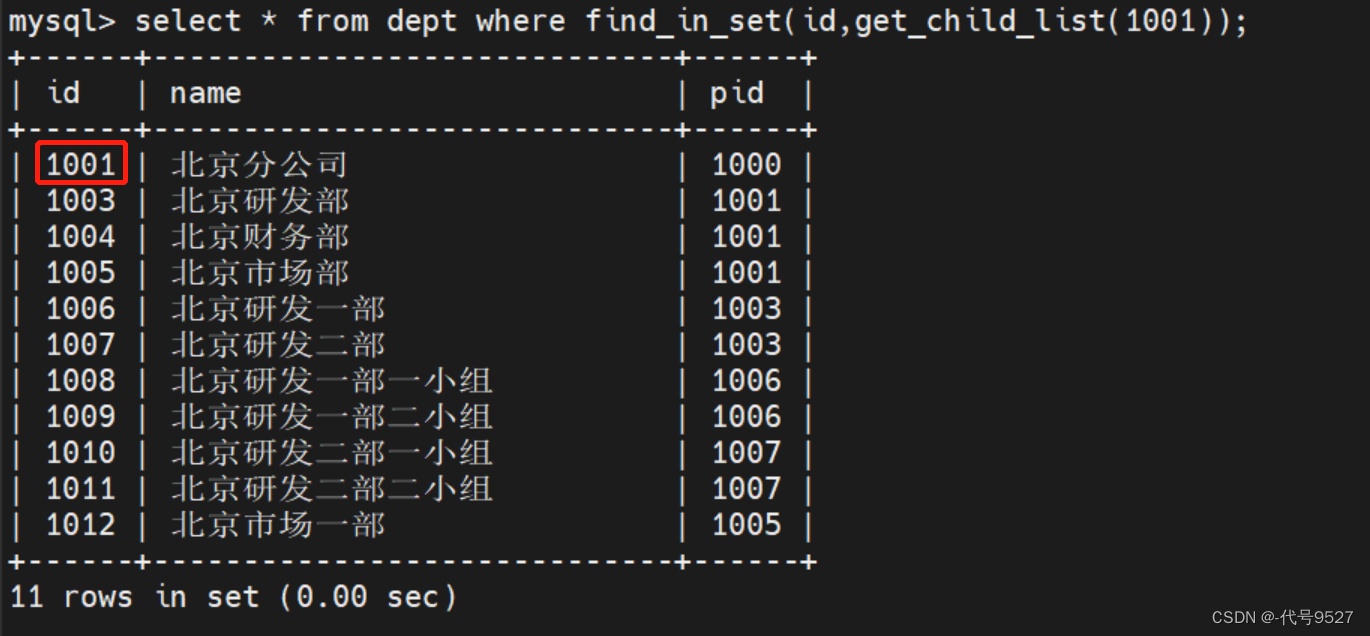
可以看到调用函数输出和分析的一样,能得到某个节点的所有子节点的id
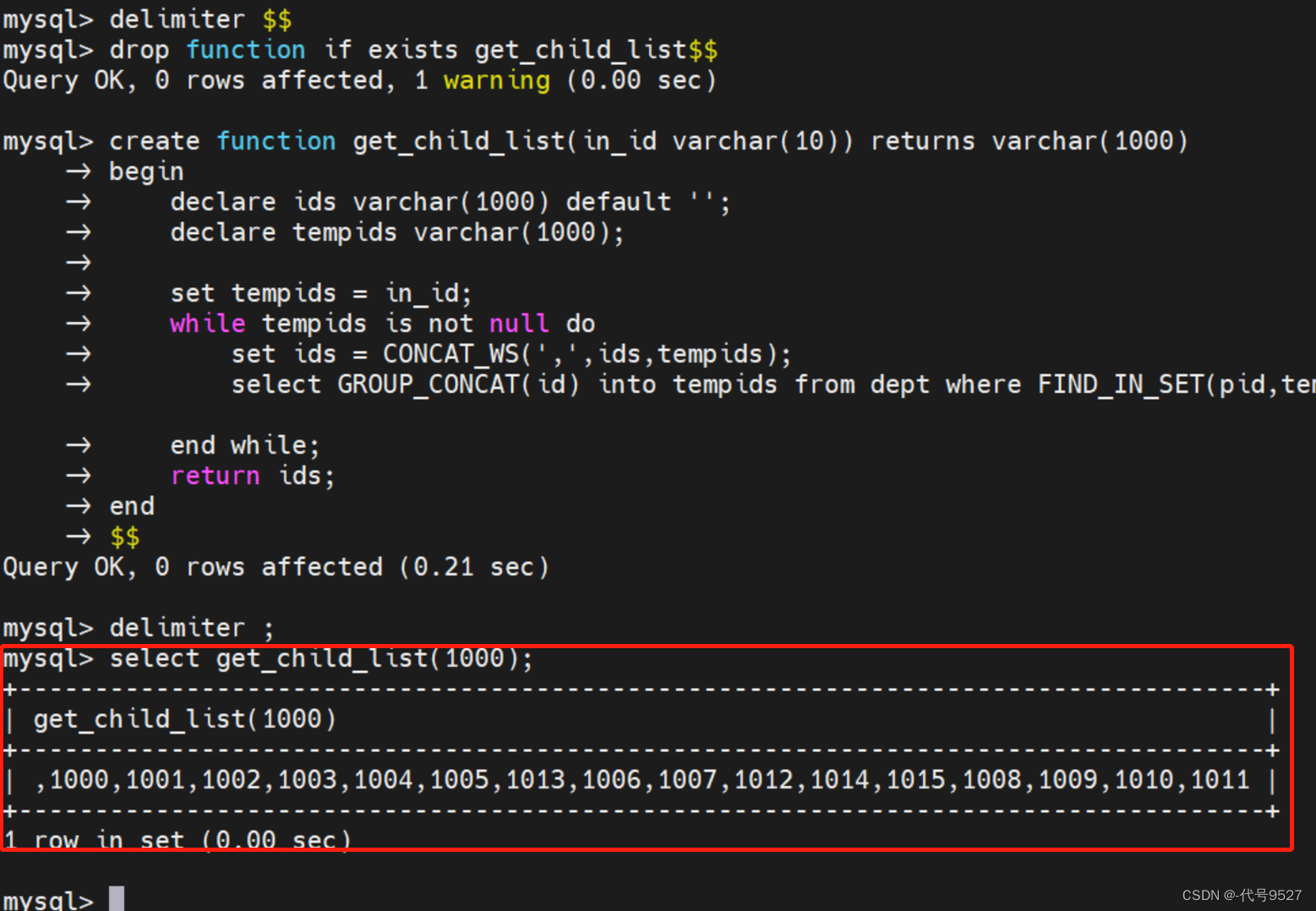
//查询某个节点的各级子节点
select * from dept where find_in_set(id,get_child_list(1001));
4、向上递归
delimiter $$
drop function if exists get_parent_list$$
create function get_parent_list(in_id varchar(10)) returns varchar(1000)
begin
declare ids varchar(1000) default '';
declare tempids varchar(1000);
set tempids = in_id;
while tempids is not null do
set ids = CONCAT_WS(',',ids,tempids);
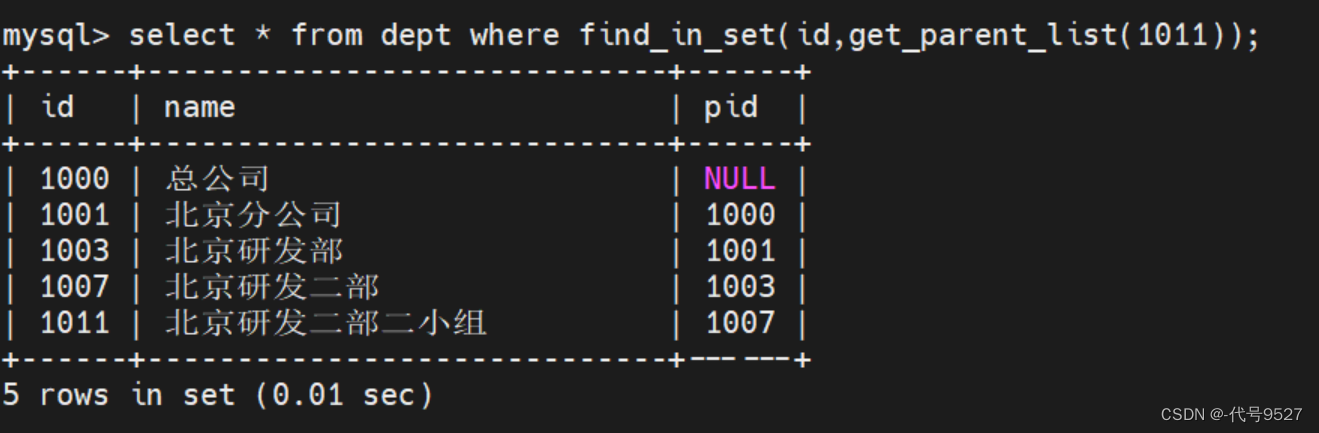
select pid into tempids from dept where id = tempids;
end while;
return ids;
end
$$
delimiter ;
有点不同的是,这里一个节点的父节点唯一,不用拼接,直接select pid into tempids即可
5、可能遇到的问题
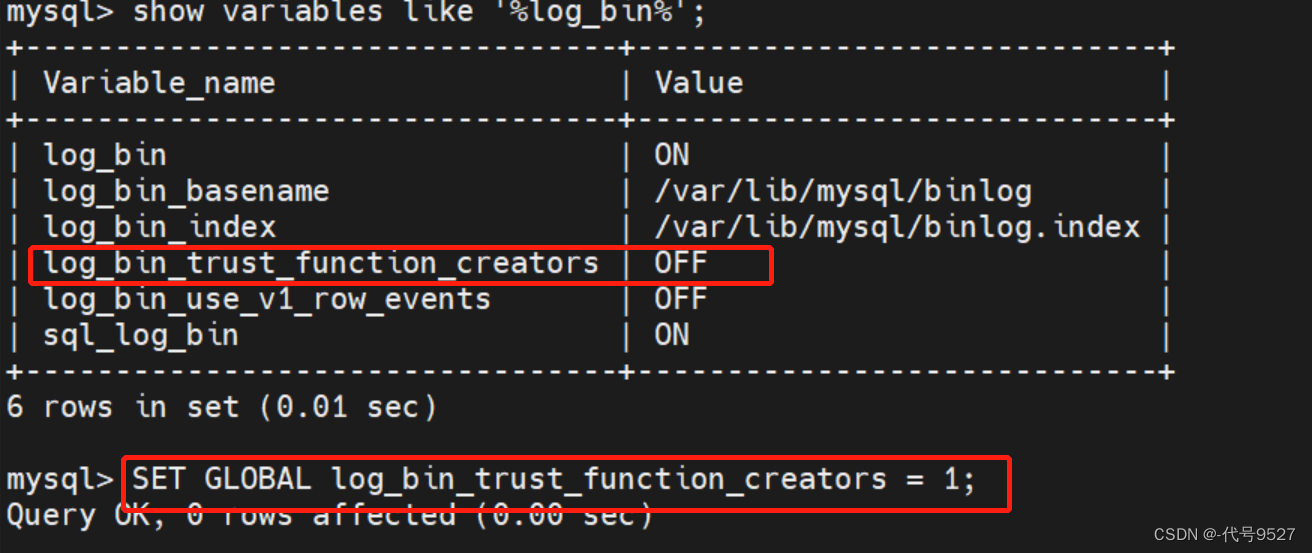
问题一:创建函数报错:
ERROR 1418 (HY000): This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (you might want to use the less safe log_bin_trust_function_creators variable)
原因:
因为开启了bin-log, 就必须指定我们的函数是否是:
1 DETERMINISTIC 不确定的
2 NO SQL 没有SQl语句,当然也不会修改数据
3 READS SQL DATA 只是读取数据,当然也不会修改数据
4 MODIFIES SQL DATA 要修改数据
5 CONTAINS SQL 包含了SQL语句
其中在function里面,只有 DETERMINISTIC, NO SQL 和 READS SQL DATA 被支持。如果开启了 bin-log, 就必须为定义的function指定一个参数(log_bin_trust_function_creators )。
1)临时使用(重启后失效)
SET GLOBAL log_bin_trust_function_creators = 1;
2)永久生效
在my.cnf里面设置
log-bin-trust-function-creators=1
然后重启MySQL服务
问题二:遍历的结果不全
group_concat 函数来拼接字符串是有长度限制的,默认为 1024 字节。
//查看拼接的长度限制
show variables like "group_concat_max_len";
//单位是字节,不是字符。在 MySQL 中,单个字母占1个字节,而我们平时用的 utf-8下,一个汉字占3个字节
解决:
方式一:修改配置文件 my.cnf ,增加:
group_concat_max_len = 102400000 #需要的最大长度
方式二:临时生效
SET GLOBAL group_concat_max_len=102400;
或者
SET SESSION group_concat_max_len=102400;
区别在于,global是全局的,任意打开一个新的会话都会生效,但是注意,已经打开的当前会话并不会生效。而 session 是只会在当前会话生效,其他会话不生效。但都是重启后失效。
参考文章:
https://segmentfault.com/a/1190000023471353
https://www.cnblogs.com/wsx2019/p/15709044.html






![[MAUI]模仿Chrome下拉标签页的交互实现](https://img-blog.csdnimg.cn/fc17be3ae466459b960abd1aa0e31680.gif)