Python爬虫笔记
一. Urllib
1. 基础请求
- 指定url
- 请求
- 返回值解码
- 返回结果的一些操作
import urllib.request as req
# 定义一个url
url = 'http://www.baidu.com'
# 发送请求获得相应
res = req.urlopen(url)
# read返回字节形式的二进制数据,需要用指定编码来解码
content = res.read().decode('utf-8')
# 读5个字节
content2 = res.read(5)
# 读一行
content3 = res.readline()
# 一行一行全部读完,返回一个数组
content4 = res.readlines()
# 获取状态码,如果是200就是正常的
code = res.getcode
# 获取头信息
res.getheaders()
# 获取请求的url
res.geturl()
下载
url = 'http://www.baidu.com'
req.urlretrieve(url, 'baidu.html')
UA校验和Request对象
- 在headers中携带了浏览器和操作系统等信息,叫user-agent,是网站的一种反爬机制,需要在header中携带
- ua只需要在浏览器中的network中随便找一个请求就可以找到ua信息
- 之后请求的时候,不是在req.urlopen中直接传入url了,而是传入一个Request对象
import urllib.request as ureq
# 下载网页/视频/照片
url = 'https://www.baidu.com'
# UA全称UserAgent 是个请求头信息,让浏览器能识别用户的操作系统版本,cpu类型等等信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.46'
}
# 构造请求对象
request = ureq.Request(url=url, headers=headers)
# 发送请求的时候放进去的是一个request对象
res = ureq.urlopen(request)
content = res.urlopen(res)
get请求
- get请求的参数是在url中的,但是请求的时候有中文的时候,需要编码成gbk才行
- 使用urllib.parse.quote来将中文编码
# 请求url中的中文要被转换为Unicode编码,才能正常进行访问
import urllib.parse
import urllib.request as ureq
name = urllib.parse.quote('周杰伦')
# 下载网页/视频/照片
url = 'https://www.baidu.com/s?wd='+name
# UA全称UserAgent 是个请求头信息,让浏览器能识别用户的操作系统版本,cpu类型等等信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.46'
}
# 构造请求对象
request = ureq.Request(url=url, headers=headers)
# 发送请求的时候放进去的是一个request对象
res = ureq.urlopen(request)
print(res.read())
post请求
- post请求和get的最大不同就是post请求的请求参数是放在请求体里的,不在url中直接写出来
- 注意!!!:先用urlencode编码之后,还要编码一次成utf-8,请求参数应该写在一个字典中
import urllib.parse
import urllib.request as ureq
import json
parms = {
'text': 'red',
}
# post请求的参数必须要编码,注意要调用encode方法
data = urllib.parse.urlencode(parms).encode('utf-8')
url = 'https://dict.youdao.com/keyword/key'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.46',
'Cookie': 'OUTFOX_SEARCH_USER_ID=-1182920945@10.110.96.160; OUTFOX_SEARCH_USER_ID_NCOO=977276189.4843129'
# 如果请求不成功可能是头信息不足,比如缺了cookie
}
request = urllib.request.Request(url=url, data=data, headers=headers)
res = ureq.urlopen(request)
# 返回JSON对象,转换为一个字典类型
content = res.read().decode('utf-8')
content = json.loads(content)
print(content)
cookies
- 一般登录信息都存放在cookies中,需要登录才能访问的界面如果是用的cookie校验的化,在header中携带cookie才可以进行访问
headler
import urllib.request
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.46'
}
url = 'https://movie.douban.com/j/chart/top_list?type=25&interval_id=100%3A90&action=&start=0&limit=20'
request = urllib.request.Request(url=url, headers=headers)
# 获取handler对象
handler = urllib.request.HTTPHandler()
# 获取opener对象
opener = urllib.request.build_opener(handler)
# 调用open方法
res = opener.open(request)
print(res.read().decode('utf-8'))
handler方式
- 用自己的ip可能不安全或者访问过于频繁被封ip,可以使用代理ip
- 用handler和opener方式请求可以使用代理ip
import urllib.request
import random
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.46'
}
url = 'https://www.baidu.com/s?wd=ip'
request = urllib.request.Request(url=url, headers=headers)
# 用random随机在代理池中选择
proxy_pool = [
{'http': '61.216.156.222:60805'},
{'http': '61.216.156.222:60808'},
{'http': '61.216.156.222:60802'},
]
proxy = random.choice(proxy_pool)
# 获取handler对象
handler = urllib.request.ProxyHandler()
# 获取opener对象
opener = urllib.request.build_opener(handler)
# 调用open方法
res = opener.open(request)
content = res.read().decode('utf-8')
with open('代理.html', 'w', encoding='utf-8') as f:
f.write(content)
xpath
下载和安装
按这篇文章
解压之后在chrome中开发者模式中选择解压好之后的文件夹即可完成安装
- 重启浏览器,ctrl+shift+x 出现小黑框
基础解析语法
from lxml import html
import urllib.request
import json
et = html.etree
# 创建树节点
html_tree = et.parse('demo01.html')
# xpath路径
# //表示所有子孙节点
# /表示子节点
res1 = html_tree.xpath('//body/ul/li')
# [@id]可以获取当前层级下所有写了id的标签
res2 = html_tree.xpath('//body/ul/li[@id]')
# 也可以指定id是谁来获取
res3 = html_tree.xpath('//body/ul/li[@id=2]')
# /text可以获取标签里的文本信息
res4 = html_tree.xpath('//body/ul/li[@id=2]/text()')
# @class可以获取该元素的class属性
res5 = html_tree.xpath('//body/ul/li[@id=2]/@class')
# 模糊查询
res6 = html_tree.xpath('//body/ul/li[contains(@id, "l")]')
# 模糊查询2
res7 = html_tree.xpath('//body/ul/li[starts-with(@id, "l")]')
# 逻辑运算
res8 = html_tree.xpath('//ul/li[@id=1 or @class="adfass"]')
beautifulSoup
可以像操作对象一样进行标签的选择
基础操作
from bs4 import BeautifulSoup
# 打开本地页面数据,注意默认编码格式是gbk
bs = BeautifulSoup(open('demo01.html', encoding='utf-8'), 'lxml')
# 根据标签查找第一个符合要求的
res1 = bs.ul.li
# 输出标签的属性
res2 = bs.ul.li.attrs
两种find函数
# find函数,可以根据一些条件找到符合条件的第一个
res3 = bs.find('li', id=1)
res4 = bs.find('li', class_="adfass")
# find_all 找到所有的,寻找多个的时候要放到一个列表中
res5 = bs.findAll(['li', 'body', 'ul'])
# 用limit可以控制返回前几个
res6 = bs.findAll(['li', 'body', 'ul'], limit=2)
select选择器
# 使用select,可以使用一些选择器语法
res7 = bs.select('li')
# 类选择器,加一个.
res8 = bs.select('.adfass')
# id选择器,加一个#
res9 = bs.select('#l1')
# 属性选择器,选择li中有id的
res10 = bs.select('li[id]')
res10 = bs.select('li[id="l1"]')
# 层级选择器
# 后代选择器,用空格分开,两者之间只要是后代关系,隔多少层级都可以
res11 = bs.select('div li')
# 子代选择器,用>隔开,只有第一代子代会被选中
res12 = bs.select('div > ul')
# 获取多个标签
res13 = bs.select("li, a, div")
# 获取节点信息
obj = res13[5]
s1 = obj.get_text()
attr = obj.attrs
print(attr)
selenium
驱动浏览器去上网,骗过反爬机制
使用方式
- 先去下载对应浏览器对应版本的驱动程序
- 将驱动程序放在当前目录下
- pip install selenium
基础操作
from selenium import webdriver
import time
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
# 控制浏览器访问这个url
browser.get('https://www.baidu.com/')
# 获取网页源码
content = browser.page_source
# 获取元素
# 通过xpath表达式获取
time.sleep(2)
input = browser.find_element(by='xpath', value='//input[@id="kw"]')
input.send_keys('周杰伦')
btn = browser.find_element(by='xpath', value='//input[@id="su"]')
btn.click()
# 通过js代码来操控
time.sleep(4)
js = "window.scrollTo(0, document.body.scrollHeight)"
browser.execute_script(js)
交互操作
from selenium import webdriver
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
# 控制浏览器访问这个url
browser.get('https://cn.bing.com/')
# 获取网页源码
content = browser.page_source
# 获取元素
# 通过xpath表达式获取
btn = browser.find_element(by='xpath', value='//label[@id]')
print(tag)
requests库
requests是python原生的可用于爬虫的库,比urllib方便,比如get和post的时候不用对参数进行编码,或者创建Request对象再进行请求‘
基础操作
url = 'https://www.baidu.com/s?'
headers = {
'User-Agent': 'xxxxxx',
}
data ={
'wd': '周杰伦'
}
# params:请求参数,无需像urllib一样编码了
res = requests.get(url, params=data, headers=headers)
res.encoding = 'utf-8'
text = res.text # 字符串形式的页面源码
res_url = res.url
content = res.content # 返回二进制数据
code = res.status_code # 状态码
headers = res.headers # 头信息
post请求
注意点:
- 留意那些隐藏了登录参数,可以进行错误登录查看请求内容,然后去源码中进行定位获取
- 验证码的url每次访问都是出现不一样的,因此需要用到session
- 可以使用超级鹰等验证码识别平台进行验证码的识别
url = 'https://fanyi.baidu.com/sug'
headers = {
'User-Agent': 'xxxx',
}
data = {
'kw': 'eye'
}
proxy = {
'http': 'xxx.xxx.xxx:xxxx'
}
res = requests.post(url=url, data=data, headers=headers, proxies=proxy)
res.encoding='utf-8'
res = json.loads(res.text, encoding='utf-8')
print(res)
验证码登录案例
import requests
import bs4
import urllib.request
login_index_url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.46',
}
# 有两个隐藏起来的用于验证的,需要先获取
res = requests.get(url=login_index_url, headers=headers)
soup = bs4.BeautifulSoup(res.text, features='lxml')
VIEWSTATE = soup.select('#__VIEWSTATE')[0].attrs['value']
VIEWSTATEGENERATOR = soup.select('#__VIEWSTATEGENERATOR')[0].attrs['value']
code_url = soup.select('#imgCode')[0].attrs['src']
code_url = 'https://so.gushiwen.cn/'+code_url
# 如果使用的下载的话,等下将账号密码验证码发过去的时候,那个验证码请求回来的东西就和之前不一样了
# urllib.request.urlretrieve(code_url, filename='code.jpg')
# 要使用session
session = requests.session()
response_code = session.get(login_index_url)
# 图片是二进制数据下载下来的
content_code = response_code.content
with open('code.jpg', 'wb')as fp:
fp.write(content_code)
print(code_url)
code = input('请输入验证码')
login_url = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
data = {
'__VIEWSTATE': VIEWSTATE,
'__VIEWSTATEGENERATOR': VIEWSTATEGENERATOR,
'from': 'http://so.gushiwen.cn/user/collect.aspx',
'email': '18851605189',
'pwd': 'Xboxoneps4psv',
'code': code,
'denglu': '登录'
}
# 这里的请求也要用session对象的请求
res = session.post(url=login_url, data=data, headers=headers)
print(res.text)
Scrapy
常用的爬虫框架
使用
- pip install scrapy
- 初始化scrapy项目
scrapy startproject项目名称
- 在spiders文件夹中创建爬虫文件
scrapy genspider 文件名 起始域名
- 将settings中的robot协议改为否
- 执行爬虫程序
scrapy crawl 爬虫名称
项目结构
创建了scrapy工程之后默认会创建几个文件
- spiders:用来存放爬虫文件的
- items:自定义数据机构读的地方
- middleware:中间件
- pipelines:管道,用来处理下载数据的
- settings:配值文件
scrapy工作原理
工作原理
使用管道下载数据
- 在setting中开启管道
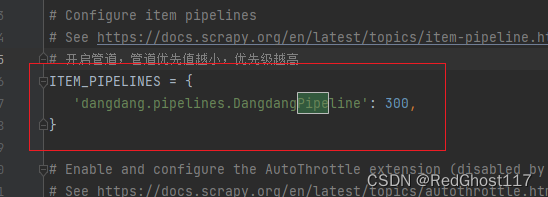
- 在items中将要储存的数据都有什么用**scrapy.Field()**创建Field对象
# 比如这里我要存的有三个字段
class DangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 在这里定义数据都有什么
src = scrapy.Field()
name = scrapy.Field()
price = scrapy.Field()
- 在爬虫主程序中,导入items中的类,并且将爬到的数据作为构造函数的参数,实例化有数据的对象,yield返回每次读到的数据,pipeline会读取到
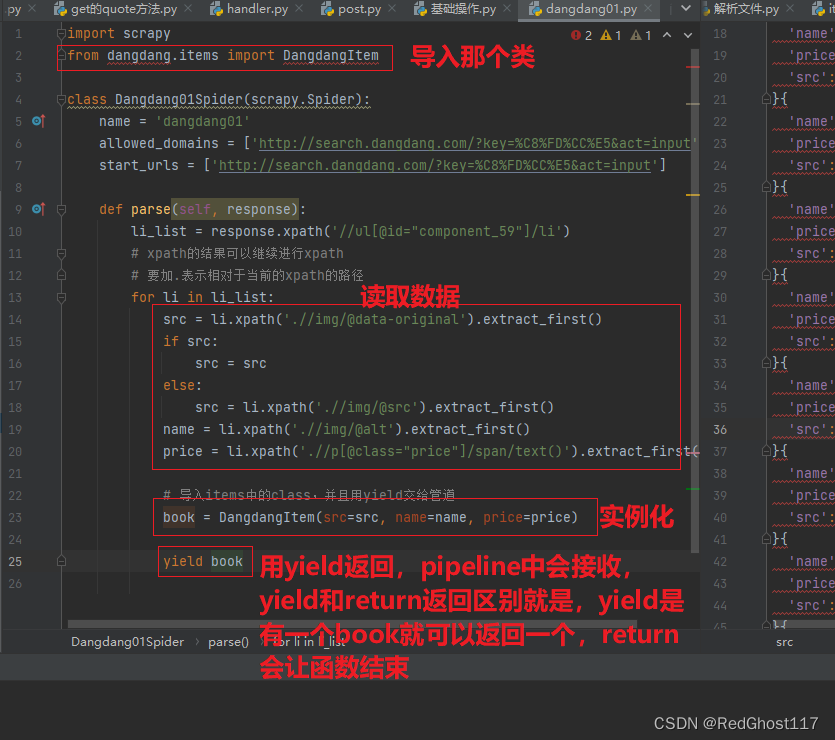
- pipeline中接收:process_item中的item参数就是yield返回的一个个值,这里可以定义生命周期函数,在开始爬虫前打开一个文件,爬虫结束后关闭,减少io操作
class DangdangPipeline:
def open_spider(self, spider):
self.fp = open('dangdang.json', 'w', encoding='utf-8')
# item就是yield出来的book对象
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self, spider):
self.fp.close()
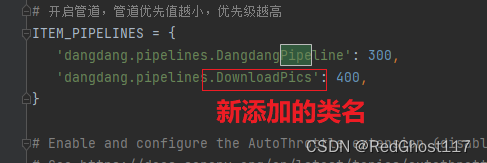
多管道下载
- 再创建一个类,也有一个process_item方法
- settings中的管道那里,将新增类对应的名字加入字典中,添加一条管道
import urllib.request
class DangdangPipeline:
def open_spider(self, spider):
self.fp = open('dangdang.json', 'w', encoding='utf-8')
# item就是yield出来的book对象
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self, spider):
self.fp.close()
# 开启另一个管道下载图片
class DownloadPics:
def process_item(self, item, spider):
url = item.get('src')
url = 'http:'+url
filename = './book/'+item.get('name')+'.jpg'
urllib.request.urlretrieve(url=url, filename=filename)
return item
多页面下载
- scrapy.Request可以发起get请求,在parse方法内部,用yield调用可以每次循环都调用
import scrapy
from dangdang.items import DangdangItem
class Dangdang01Spider(scrapy.Spider):
name = 'dangdang01'
allowed_domains = ['category.dangdang.com']
start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html']
current_page = 1
def parse(self, response):
li_list = response.xpath('//ul[@id="component_59"]/li')
# xpath的结果可以继续进行xpath
# 要加.表示相对于当前的xpath的路径
for li in li_list:
src = li.xpath('.//img/@data-original').extract_first()
if src:
src = src
else:
src = li.xpath('.//img/@src').extract_first()
name = li.xpath('.//img/@alt').extract_first()
price = li.xpath('.//p[@class="price"]/span/text()').extract_first()
# 导入items中的class,并且用yield交给管道
book = DangdangItem(src=src, name=name, price=price)
yield book
if self.current_page <= 10:
self.current_page += 1
url = f'http://search.dangdang.com/?key=%C8%FD%CC%E5&act=input&page_index={self.current_page}'
yield scrapy.Request(url=url, callback=self.parse)
进入页面下载
- 需求:在一个页面获取到一个href链接后,访问这个链接
- 也是用scrapy.Request(url, callback=要调用的函数名, meta=可以通过这个向要调用的函数中传参)
import scrapy
from DYTT.items import DyttItem
class MovieSpider(scrapy.Spider):
name = 'movie'
allowed_domains = ['dygod.net']
start_urls = ['https://www.dygod.net/html/gndy/china/index.html']
def parse(self, response):
a_list = response.xpath('//table//a[2]')
for a in a_list:
title = a.xpath('./@title').extract_first()
href = a.xpath('./@href').extract_first()
href = 'https://www.dygod.net' + href
# 对链接进行访问,可以将值用meta传递給调用的函数
yield scrapy.Request(url=href, callback=self.parse_second, meta={'title': title})
def parse_second(self, res):
src = res.xpath('//div[@id="Zoom"]//img/@src')
title = res.meta['title']
movie = DyttItem(title=title, src=src)
yield movie
日志
- 日志等级
LOG_LEVEL = 'CRITICAL/ERROR/WARNING/INFO/DEBUG' # 对应不同的日志等级
- 输出日志
LOG_FILE = 'log01.log'
post请求
- post请求需要携带请求体才有意义
- 直接通过parse方法,带着起始url访问是无效的
- 要通过start_request方法,指定好请求参数之类的再请求
- 通过scrapy.FormRequest发送post请求
import scrapy
import json
class TestpostSpider(scrapy.Spider):
name = 'testPost'
allowed_domains = ['fanyi.baidu.com']
start_urls = ['https://fanyi.baidu.com/sug/']
def start_requests(self):
url = 'https://fanyi.baidu.com/sug/'
data = {
'kw': 'red'
}
# 发送post创建FormRequest
yield scrapy.FormRequest(url=url, formdata=data, callback=self.second_parse)
def second_parse(self, res):
content = res.text
obj = json.loads(content, encoding='utf-8')
print(obj)