CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
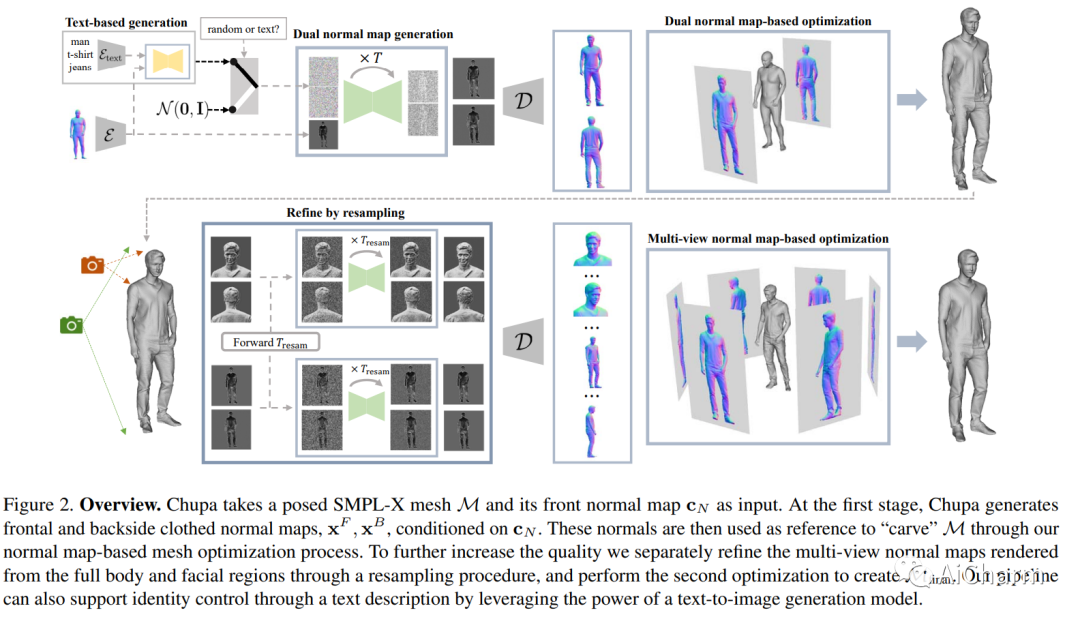
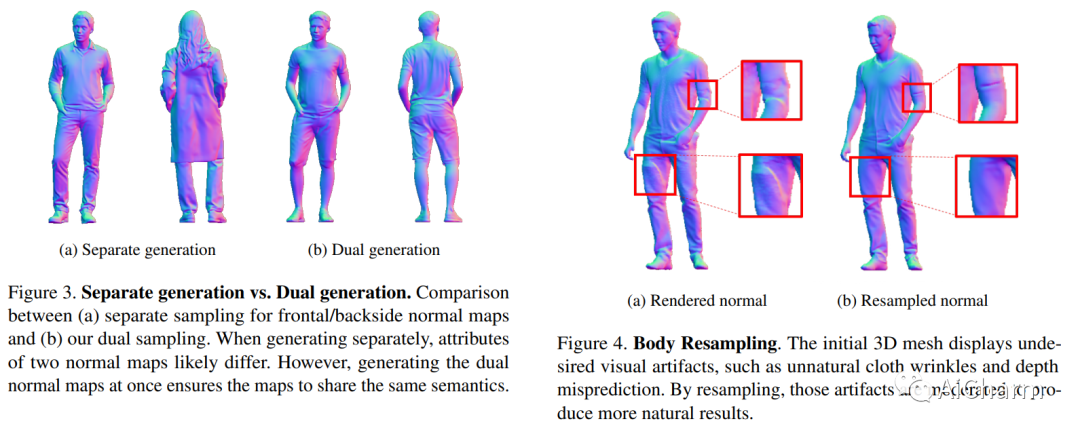
1.Chupa: Carving 3D Clothed Humans from Skinned Shape Priors using 2D Diffusion Probabilistic Models

标题:Chupa:使用 2D 扩散概率模型从蒙皮形状先验雕刻 3D 穿衣人
作者:Byungjun Kim, Patrick Kwon, Kwangho Lee, Myunggi Lee, Sookwan Han, Daesik Kim, Hanbyul Joo
文章链接:https://arxiv.org/abs/2305.11870


摘要:
我们提出了一个 3D 生成管道,它使用扩散模型来生成逼真的人类数字化身。由于人类身份、姿势和随机细节的多样性,3D 人体网格的生成一直是一个具有挑战性的问题。为了解决这个问题,我们将问题分解为 2D 法线贴图生成和基于法线贴图的 3D 重建。具体来说,我们首先使用姿势条件扩散模型同时为穿着衣服的人的正面和背面生成逼真的法线贴图,称为双法线贴图。对于 3D 重建,我们通过网格优化根据法线贴图将先前的 SMPL-X 网格“雕刻”为详细的 3D 网格。为了进一步增强高频细节,我们在身体和面部区域提出了扩散重采样方案,从而鼓励生成逼真的数字化身。我们还无缝整合了最近的文本到图像扩散模型,以支持基于文本的人类身份控制。我们的方法,即 Chupa,能够生成具有更好感知质量和身份多样性的逼真 3D 穿衣人。
2.RoomDreamer: Text-Driven 3D Indoor Scene Synthesis with Coherent Geometry and Texture

标题:RoomDreamer:具有连贯几何和纹理的文本驱动 3D 室内场景合成
作者:Liangchen Song, Liangliang Cao, Hongyu Xu, Kai Kang, Feng Tang, Junsong Yuan, Yang Zhao
文章链接:https://arxiv.org/abs/2305.11337
项目代码:https://www.youtube.com/watch?v=p4xgwj4QJcQ&feature=youtu.be


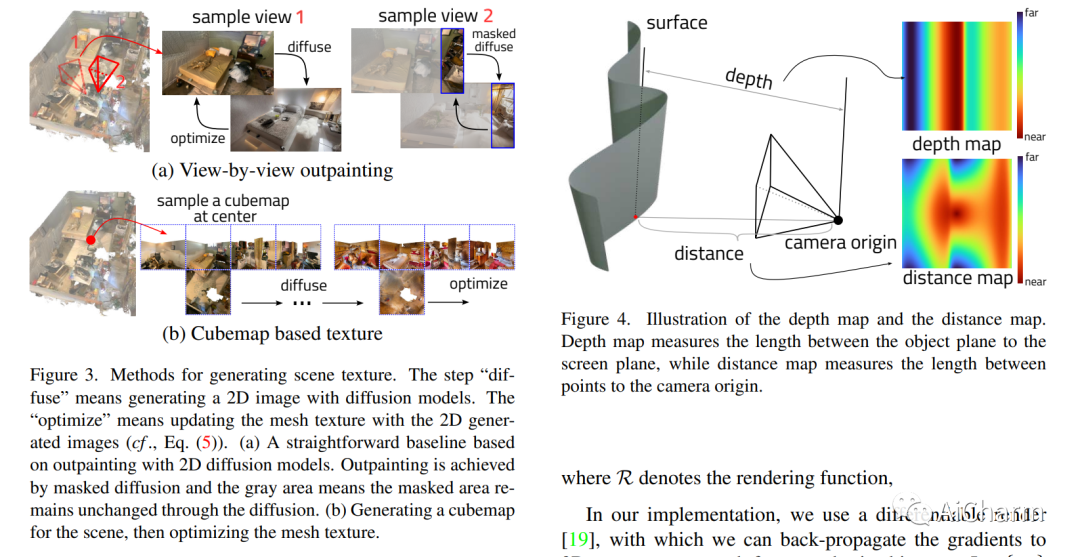

摘要:
视3D 室内场景捕捉技术被广泛使用,但生成的网格还有很多不足之处。在这篇论文中,我们提出了“RoomDreamer”,它利用强大的自然语言来合成一个具有不同风格的新房间。与现有的图像合成方法不同,我们的工作解决了同时合成与输入场景结构和提示对齐的几何和纹理的挑战。关键的见解是场景应该被视为一个整体,同时考虑场景纹理和几何形状。拟议的框架由两个重要组成部分组成:几何引导扩散和网格优化。Geometry Guided Diffusion for 3D Scene 通过在整个场景同时应用 2D 先验来保证场景风格的一致性。网格优化共同改进了几何形状和纹理,并消除了扫描场景中的伪影。为了验证所提出的方法,使用智能手机扫描的真实室内场景进行了大量实验,通过这些实验证明了我们方法的有效性。
3.Any-to-Any Generation via Composable Diffusion

标题:通过可组合扩散实现任意生成
作者:Zineng Tang, Ziyi Yang, Chenguang Zhu, Michael Zeng, Mohit Bansal
文章链接:https://arxiv.org/abs/2305.11846
项目代码:https://codi-gen.github.io/

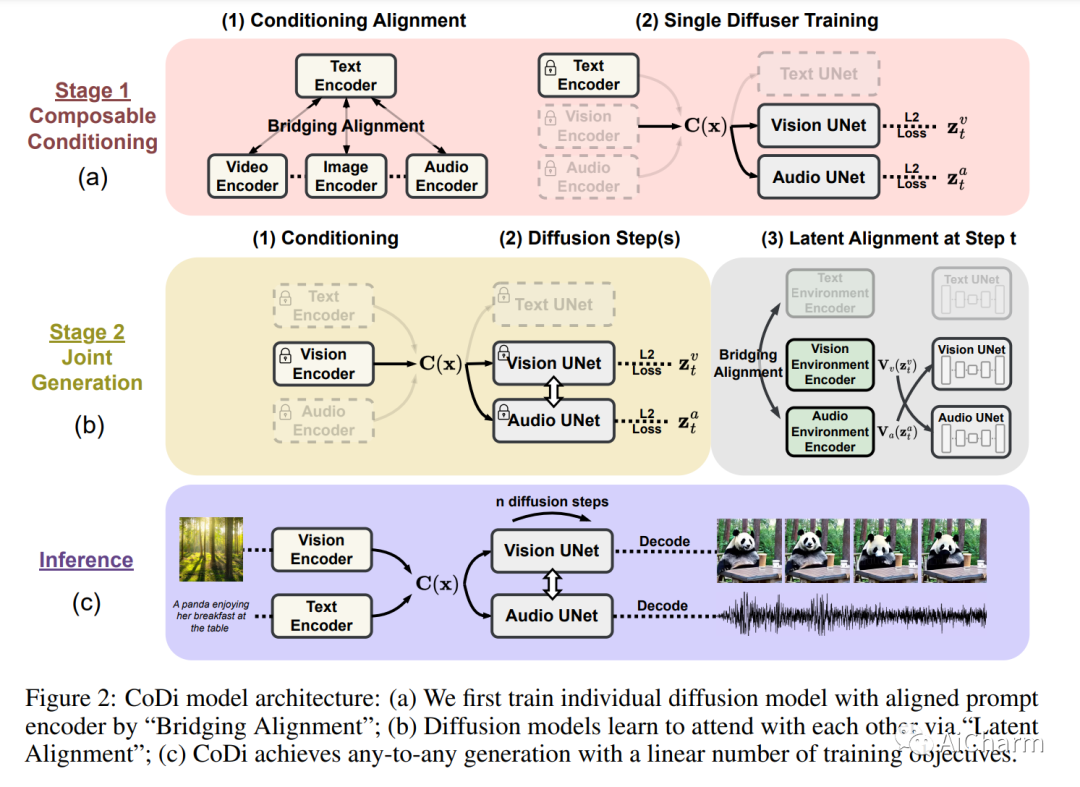



摘要:
我们提出了可组合扩散 (CoDi),这是一种新颖的生成模型,能够从输入模态的任意组合生成输出模态的任意组合,例如语言、图像、视频或音频。与现有的生成式 AI 系统不同,CoDi 可以并行生成多种模态,并且其输入不限于文本或图像等模态的子集。尽管缺乏许多模态组合的训练数据集,我们建议在输入和输出空间中对齐模态。这允许 CoDi 自由地以任何输入组合为条件并生成任何模态组,即使它们不存在于训练数据中。CoDi 采用了一种新颖的可组合生成策略,该策略涉及通过在扩散过程中桥接对齐来构建共享的多模态空间,从而能够同步生成相互交织的模态,例如时间对齐的视频和音频。高度可定制和灵活的 CoDi 实现了强大的联合模态生成质量,并且优于或与单模态合成的单模态最先进技术相当。包含演示和代码的项目页面位于此 https URL
更多Ai资讯:公主号AiCharm