CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CL
1.Tree of Thoughts: Deliberate Problem Solving with Large Language Models

标题:思想树:用大型语言模型有意识地解决问题
作者:Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, Karthik Narasimhan
文章链接:https://arxiv.org/abs/2305.10601
项目代码:https://github.com/ysymyth/tree-of-thought-llm



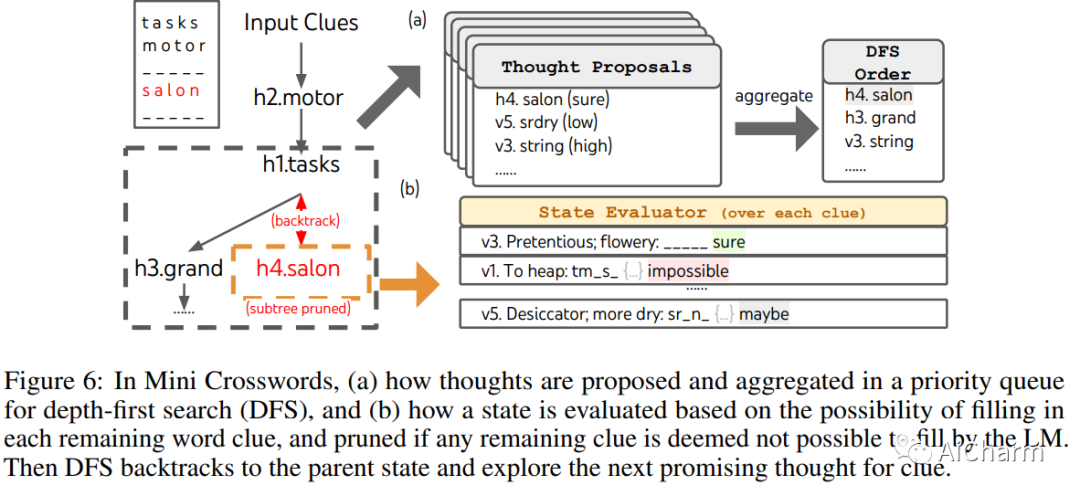
摘要:
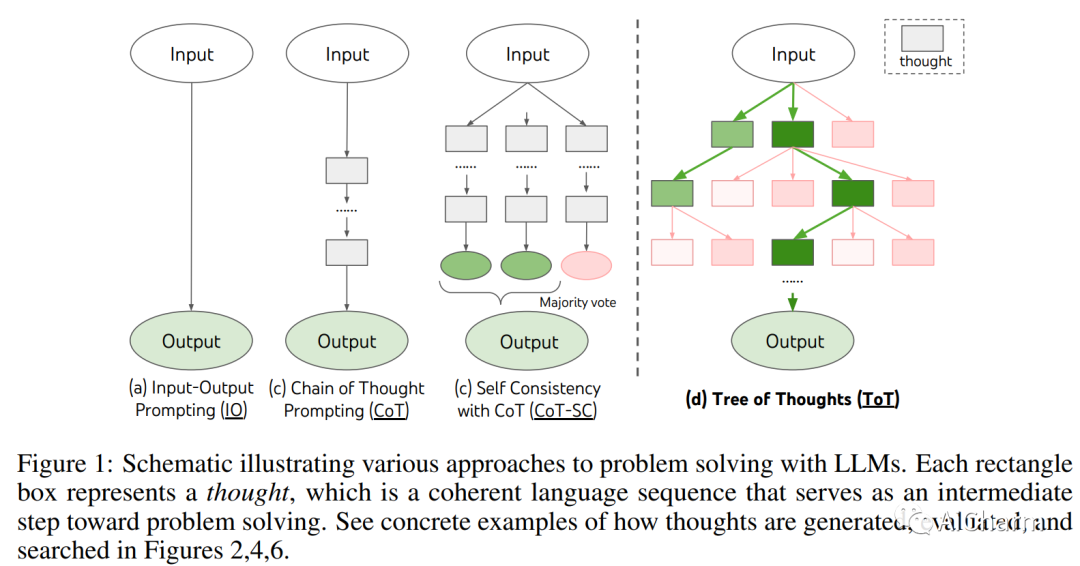
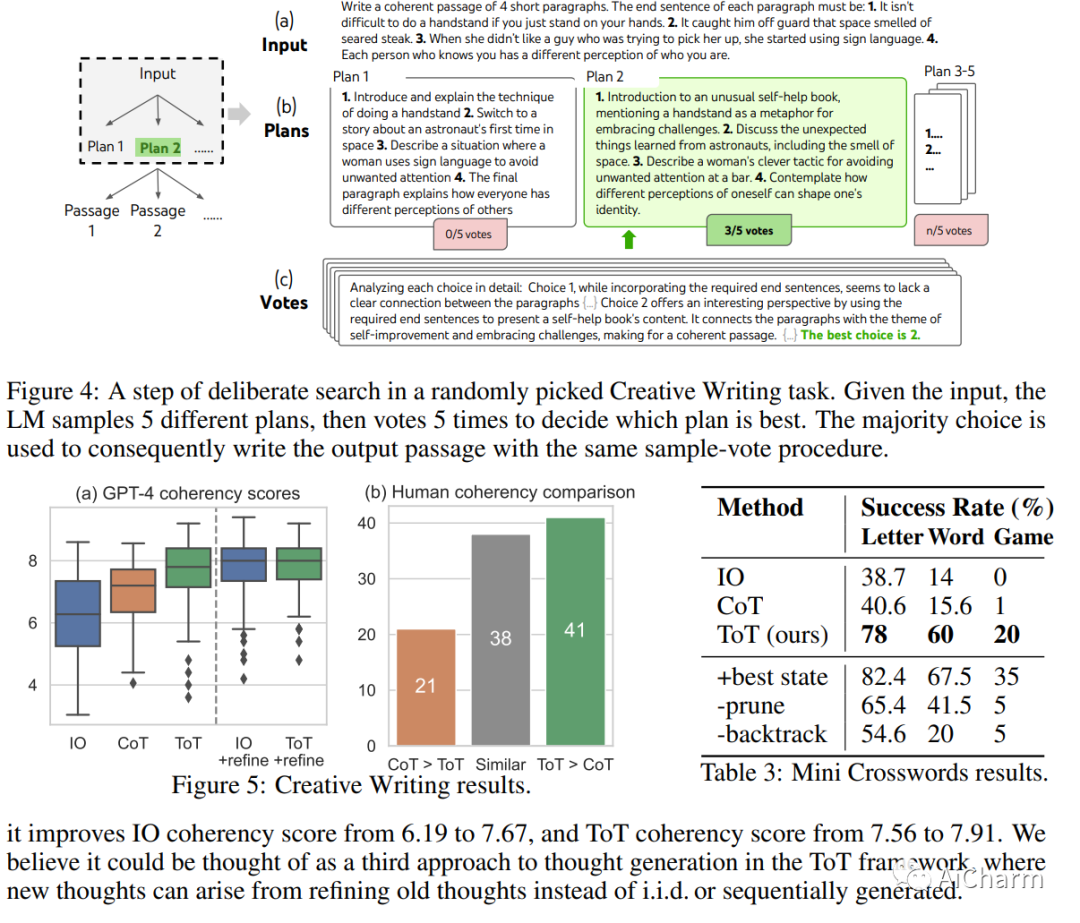
语言模型越来越多地用于解决各种任务的一般问题,但在推理过程中仍局限于令牌级、从左到右的决策过程。这意味着他们可能无法完成需要探索、战略前瞻或初始决策起关键作用的任务。为了克服这些挑战,我们引入了一个新的语言模型推理框架,即思想树 (ToT),它概括了流行的思想链方法来提示语言模型,并能够探索连贯的文本单元(思想)作为解决问题的中间步骤。ToT 允许 LM 通过考虑多种不同的推理路径和自我评估选择来执行深思熟虑的决策,以决定下一步的行动方案,并在必要时向前看或回溯以做出全局选择。我们的实验表明,ToT 显着增强了语言模型在需要非平凡计划或搜索的三个新任务上的问题解决能力:24 岁游戏、创意写作和迷你填字游戏。例如,在 Game of 24 中,虽然带有思维链提示的 GPT-4 只解决了 4% 的任务,但我们的方法达到了 74% 的成功率。
2.Learning the Visualness of Text Using Large Vision-Language Models

标题:使用大型视觉语言模型学习文本的视觉效果
作者:Gaurav Verma, Ryan A. Rossi, Christopher Tensmeyer, Jiuxiang Gu, Ani Nenkova
文章链接:https://arxiv.org/abs/2305.10434

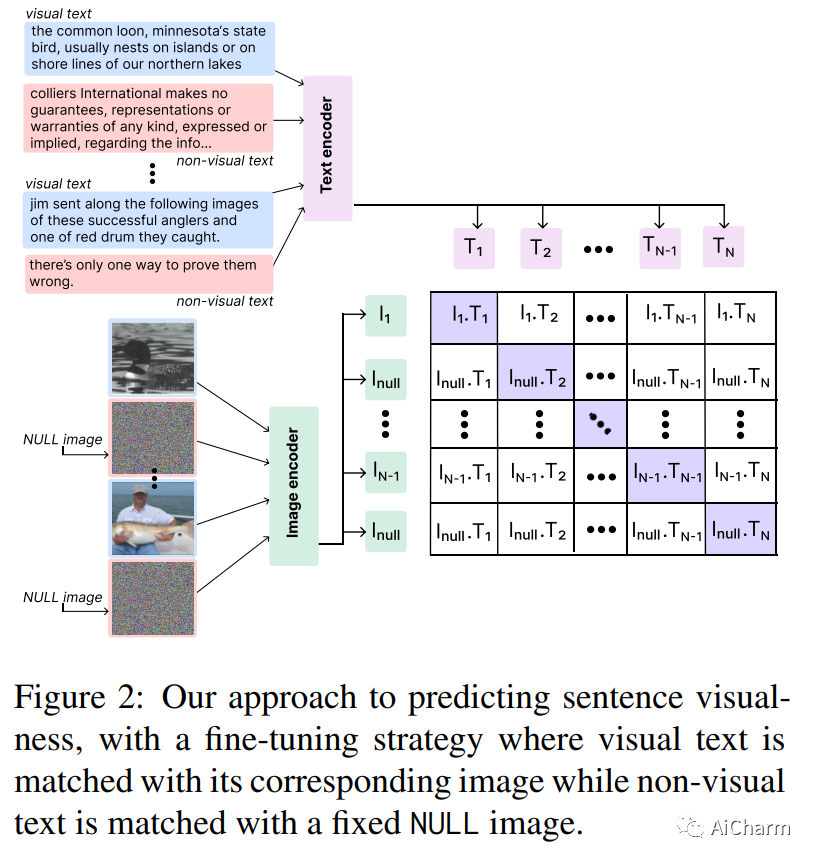
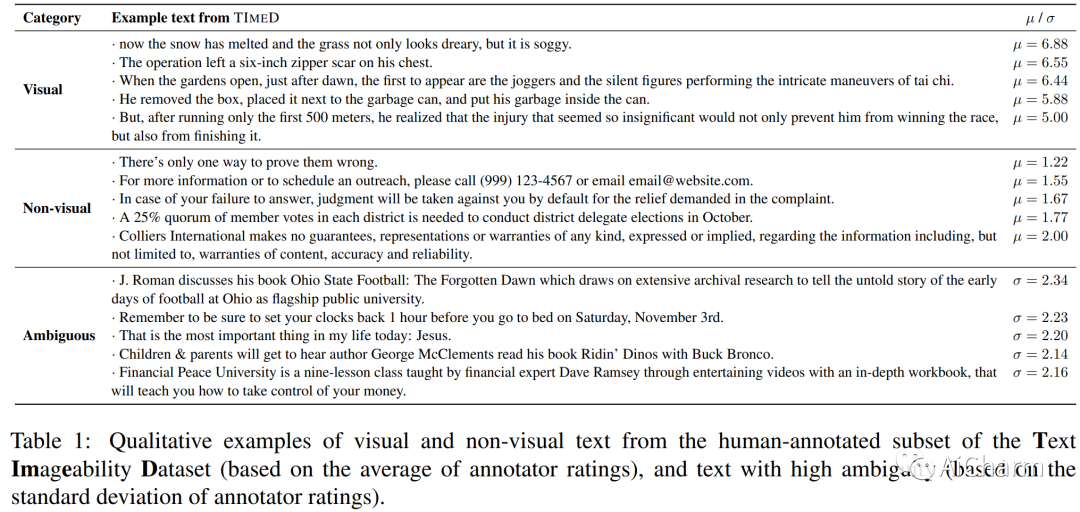

摘要:
视觉文本会在人们的脑海中唤起图像,而非视觉文本则无法做到这一点。一种自动检测文本视觉性的方法将解锁用相关图像增强文本的能力,因为神经文本到图像的生成和检索模型在输入文本本质上是视觉的隐含假设下运行。我们整理了一个包含 3,620 个英语句子的数据集及其由多个人工注释者提供的视觉分数。此外,我们使用包含文本和视觉资产的文档来创建文档文本和相关图像的远程监督语料库。我们还提出了一种微调策略,使大型视觉语言模型(如 CLIP)适应假设文本和图像之间存在一对一对应关系的大型视觉语言模型,以完成仅从文本输入中对文本视觉性进行评分的任务。我们的策略涉及修改模型的对比学习目标,将识别为非视觉的文本映射到普通的 NULL 图像,同时将视觉文本与文档中的相应图像匹配。我们评估所提出的方法的能力 (i) 准确地对视觉和非视觉文本进行分类,以及 (ii) 关注在心理语言学研究中被识别为视觉的单词。实证评估表明,我们的方法比拟议任务的几种启发式和基线模型表现更好。此外,为了强调文本可视化建模的重要性,我们对 DALL-E 等文本到图像生成系统进行了定性分析。
3.CooK: Empowering General-Purpose Language Models with Modular and Collaborative Knowledge

标题:Cook:使用模块化和协作知识增强通用语言模型
作者:Shangbin Feng, Weijia Shi, Yuyang Bai, Vidhisha Balachandran, Tianxing He, Yulia Tsvetkov
文章链接:https://arxiv.org/abs/2304.05977
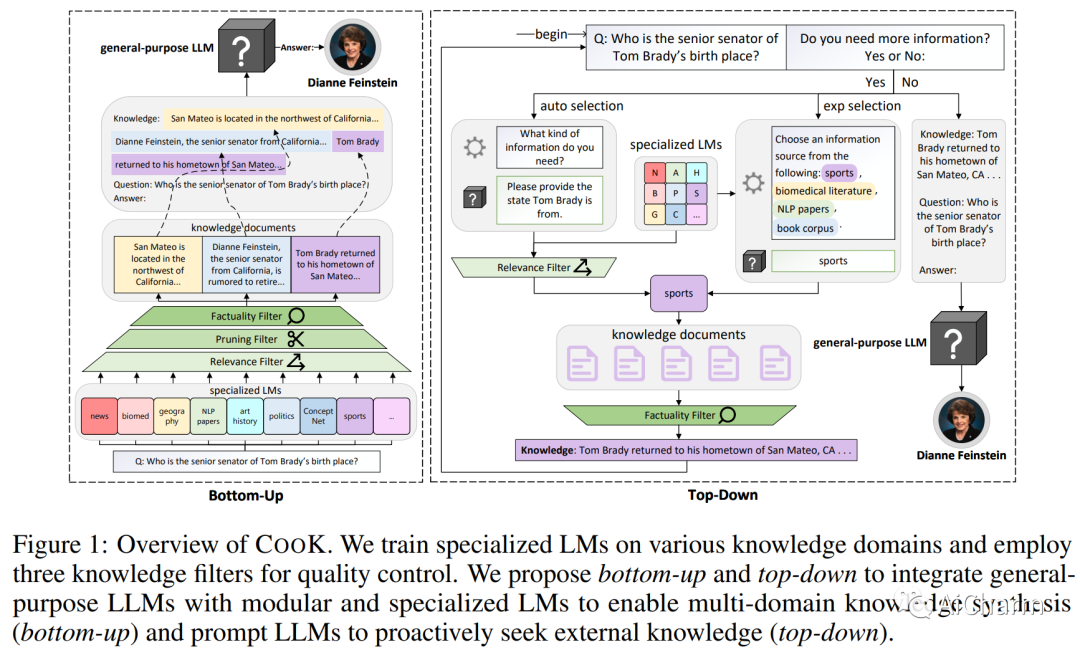
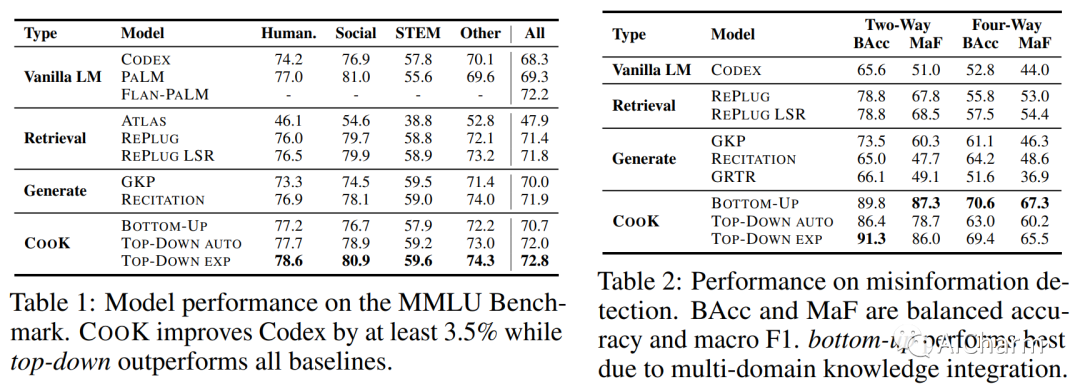

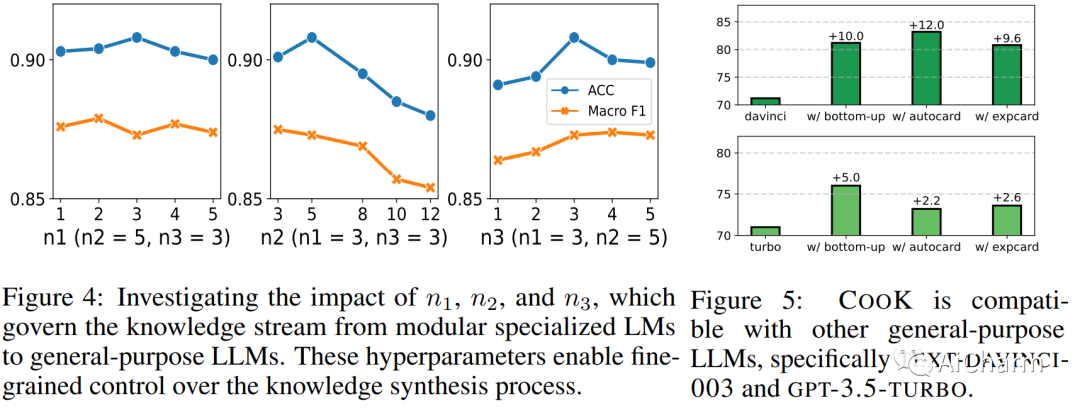
摘要:
大型语言模型 (LLM) 越来越多地被用于知识密集型任务和上下文。现有方法通过检索或生成知识提示来提高通用 LLM 的知识能力,但它们未能反映知识丰富模型的两个关键属性:知识应该是模块化的、不断增长的、来自不同领域的;知识的获取和生产应该是一个协作过程,不同的利益攸关方在此过程中提供新的信息。为此,我们提出了 CooK,这是一种新颖的框架,可以为通用大型语言模型提供模块化和协作来源的知识。我们首先介绍专门的语言模型,即在来自广泛领域和来源的语料库上训练的自回归模型。这些专门的 LM 作为参数化知识库,稍后会提示为通用 LLM 生成背景知识。然后,我们提出了三个知识过滤器,通过控制相关性、简洁性和真实性来动态选择和保留生成的文档中的信息。最后,我们提出了自下而上和自上而下的知识集成方法,以使用来自社区驱动的专业 LM 的精选(相关的、事实的)知识来增强通用 LLM,从而实现多领域知识合成和按需知识请求。通过广泛的实验,我们证明了 Cook 在六个基准数据集上实现了最先进的性能。我们的结果突出了用不断发展的模块化知识丰富通用 LLM 的潜力——相关知识可以通过研究界的集体努力不断更新。
更多Ai资讯:公主号AiCharm