CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.Reprompting: Automated Chain-of-Thought Prompt Inference Through Gibbs Sampling

标题:重新提示:通过 Gibbs 采样的自动思维链提示推理
作者:Weijia Xu, Andrzej Banburski-Fahey, Nebojsa Jojic
文章链接:https://arxiv.org/abs/2305.09993
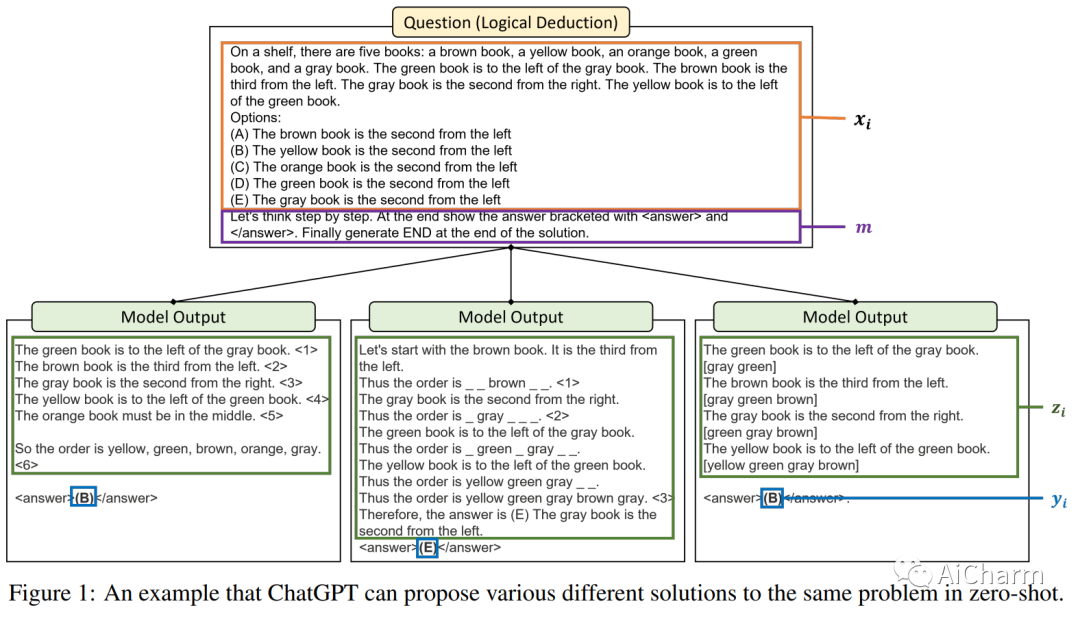



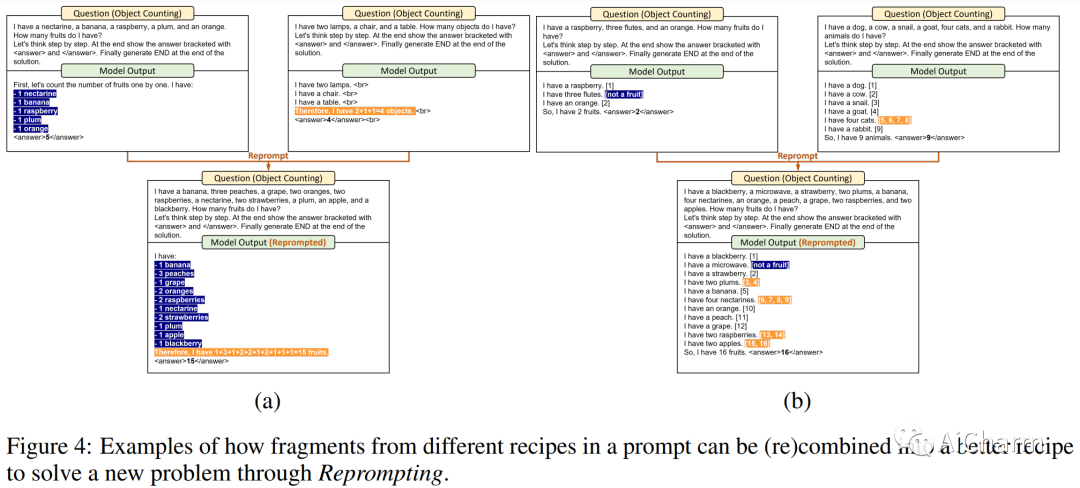
摘要:
我们介绍了 Reprompting,这是一种迭代采样算法,无需人工干预即可搜索给定任务的思维链 (CoT) 配方。通过 Gibbs 抽样,我们推断出对一组训练样本始终有效的 CoT 方法。我们的方法使用先前采样的解决方案迭代地对新食谱进行采样,作为父母提示来解决其他训练问题。在五个需要多步推理的 Big-Bench Hard 任务中,Reprompting 的性能始终优于零样本、少样本和人工编写的 CoT 基线。重新提示还可以促进知识从较强模型转移到较弱模型,从而显着提高较弱模型的性能。总体而言,与之前使用人工编写的 CoT 提示的最先进方法相比,Reprompting 带来了高达 +17 点的改进。
2.DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining

标题:DoReMi:优化数据混合加速语言模型预训练
作者:Sang Michael Xie, Hieu Pham, Xuanyi Dong, Nan Du, Hanxiao Liu, Yifeng Lu, Percy Liang, Quoc V. Le, Tengyu Ma, Adams Wei Yu
文章链接:https://arxiv.org/abs/2305.10429



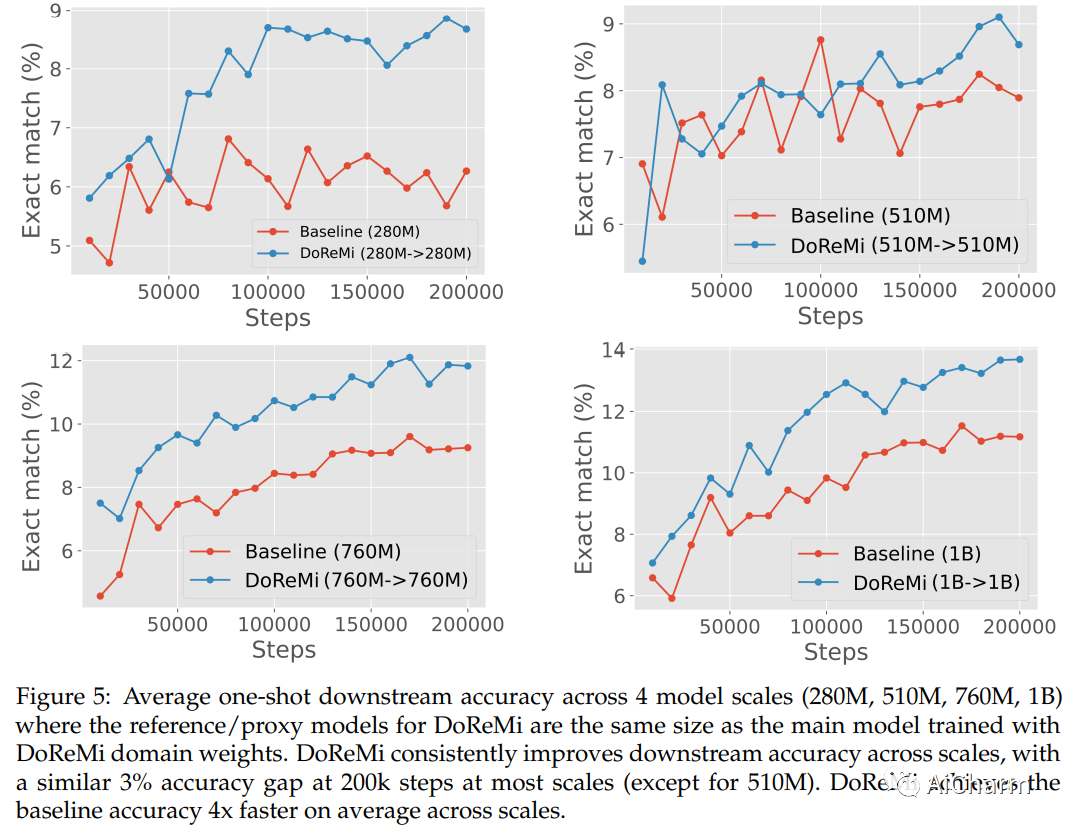

摘要:
预训练数据域(例如,维基百科、书籍、网络文本)的混合比例极大地影响了语言模型 (LM) 的性能。在本文中,我们提出了使用极小极大优化 (DoReMi) 进行域重加权,它首先使用域上的组分布鲁棒优化 (Group DRO) 训练一个小型代理模型,以在不知道下游任务的情况下生成域权重(混合比例)。然后,我们使用这些域权重对数据集进行重新采样,并训练一个更大的全尺寸模型。在我们的实验中,我们在 280M 参数代理模型上使用 DoReMi 来找到域权重,以便更有效地训练 8B 参数模型(大 30 倍)。在 The Pile 上,DoReMi 提高了所有领域的困惑度,即使它降低了一个领域的权重。与使用 The Pile 的默认域权重训练的基线模型相比,DoReMi 将平均少镜头下游准确度提高了 6.5%,并以减少 2.6 倍的训练步骤达到基线准确度。在 GLaM 数据集上,不了解下游任务的 DoReMi 的性能甚至与使用针对下游任务调整的域权重的性能相当。
3.Seeing is Believing: Brain-Inspired Modular Training for Mechanistic Interpretability

标题:眼见为实:受大脑启发的机械可解释性模块化训练
作者:Ziming Liu, Eric Gan, Max Tegmark
文章链接:https://arxiv.org/abs/2305.08746


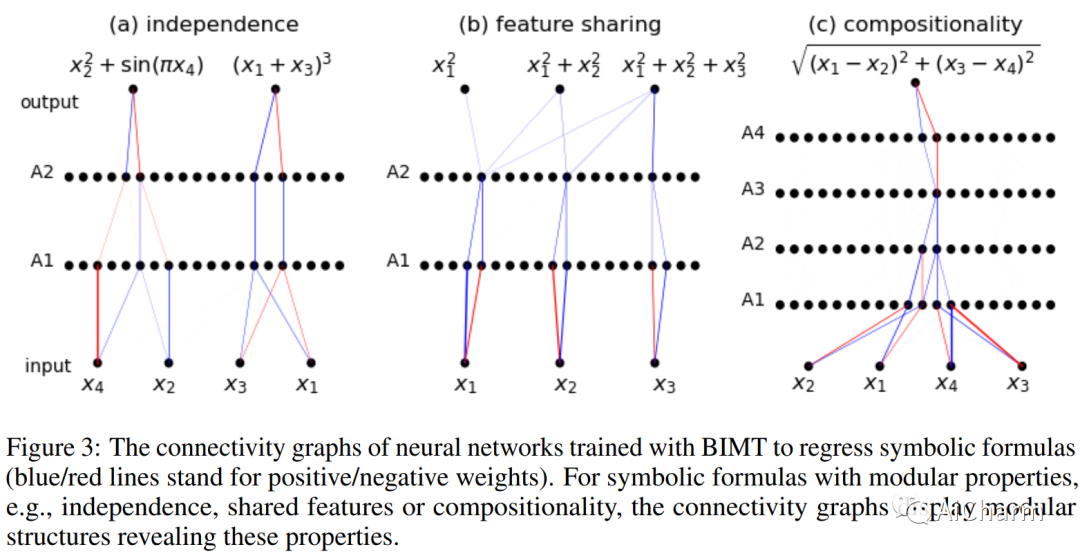
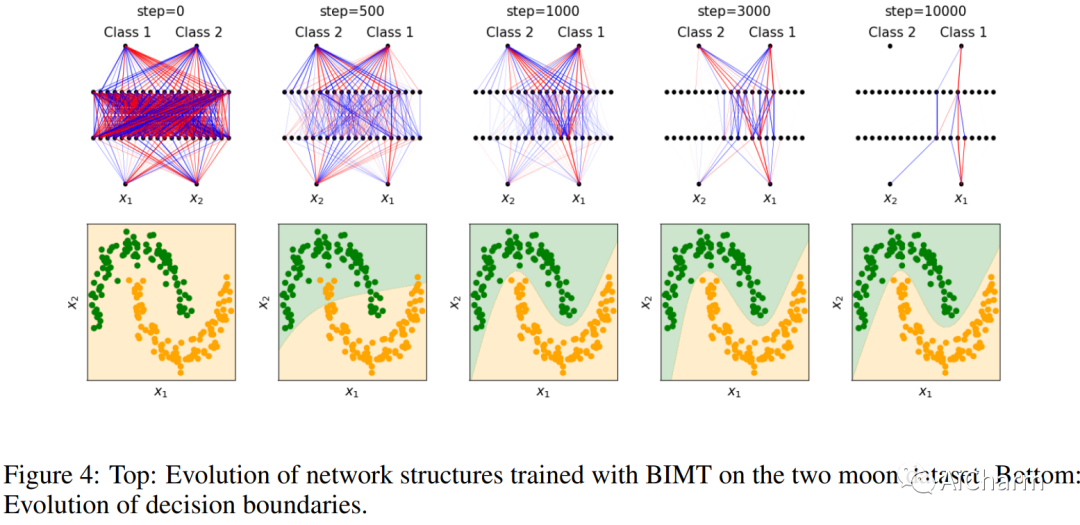
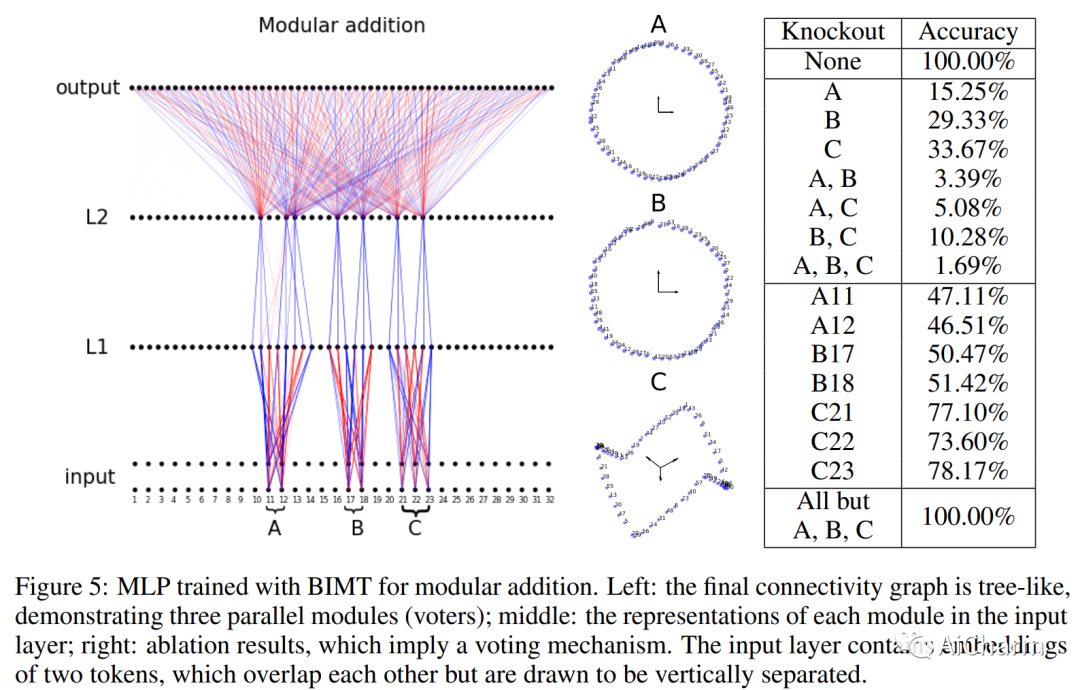

摘要:
我们介绍了 Brain-Inspired Modular Training (BIMT),这是一种使神经网络更加模块化和可解释的方法。受大脑的启发,BIMT 将神经元嵌入几何空间,并以与每个神经元连接的长度成正比的成本来增加损失函数。我们证明 BIMT 为许多简单任务发现了有用的模块化神经网络,揭示了符号公式中的组成结构、可解释的决策边界和分类特征,以及算法数据集中的数学结构。用肉眼直接看到模块的能力可以补充当前的机械可解释性策略,例如探测、干预或盯着所有重量。
更多Ai资讯:公主号AiCharm