在你的数据科学生涯的开始,混淆矩阵会非常混乱,我们会有很多问题,比如什么时候使用精度?什么时候使用召回?在哪些情况下可以使用精度?因此,我将尝试在本博客中回答这些问题。
什么是混淆矩阵?
混淆矩阵是一种将预测结果和实际值以矩阵形式汇总的方法,用来衡量分类问题的性能。
在这里,我们将预测表示为 Positive§ 或 Negative(N),将真值表示为 True(T) 或 False(F)。
将真实值和预测值一起表示,我们得到真阳性 (TP)、真阴性 (TN)、假阳性 (FP) 和假阴性 (FN)。
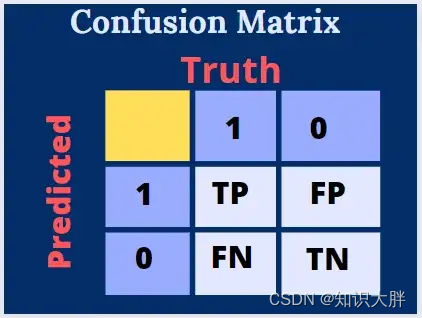
那么什么是 TP、TN、FP 和 FN?这里我们将考虑一个怀孕测试的例子,一个真正的孕妇和一个胖男人咨询医生,测试结果如下图所示。
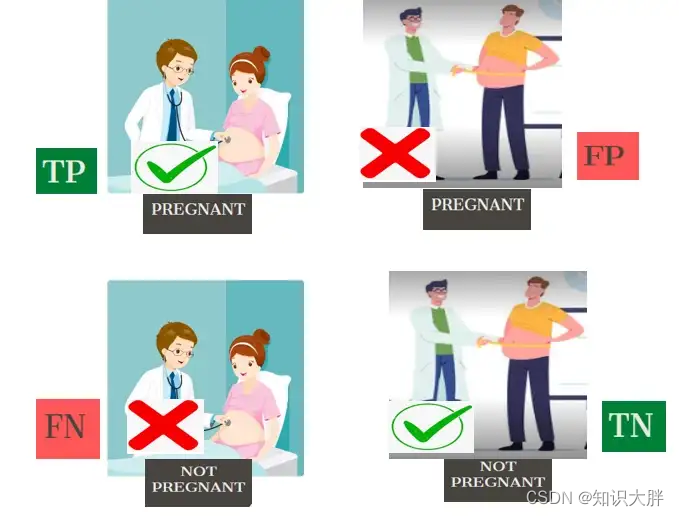
TP(True Positive):女人怀孕了,预测她怀孕了。这里 P 代表正向预测,T 表明我们的预测实际上是正确的。
FP(False Positive) : 一个胖子被预测怀孕了,其实是假的。这里P代表正预测,F代表我们的预测其实是假的。这也称为I 类错误。
FN(False Negative):实际怀孕的女性被预测为未怀孕。这里N代表负预测,F代表我们的预测其实是假的。这也称为II 类错误。
T