上一篇博文是入门使用级别,但对于面试来说则不够,毕竟领导一问三不知必定over,其基本原理还是要搞清楚,因而有此博文。paper在此
0,绪论
考虑紧致特征以减少存储空间,提出在PQ( product quantization,也是笛卡尔乘积)基础之上存储词向量。文本分类可用于垃圾过滤。fastTEXT基于n-gram特征,降维,以及更快的softmax分类器,一些关键部分,特征剪枝,量化,hash,再训练使得文本分类模型很小(一般小于100kB)而并没有明显的牺牲acc和速度。由于不受纯二进制代码的约束,采用了更传统的编码方式,即采用矢量的幅度/方向参数化。因此,只需要编码/压缩一个酉d维向量,这很好地符合上述LSH和PQ方法。
1,方法
在文本分类中,线性分类器依旧是有竞争力的,而且训练更快。在线性文本分类中最有效的trick是使用一个低等级的约束减少计算负担,同时在不同类别之间共享信息。这在更大输出空间中更有效,尤其是一些类别训练样本较少时。本文中,一个类似的模型,取N个document的softmax loss的最小值,
xn是one-hot向量的bag,yn是第n个document的label,在大的词典和大的输出空间中,矩阵A,B是大的,可占据GB内存,因此我们的目的就是减少此内存。
PQ 是一个在压缩域(compressed-domain)近似近邻检索中流行的方法。一个隐式的定义:
一个d维度的向量x近似为:,那么PQ在压缩域估计内积为:
存储空间更依赖于词典大小,词典可能很大,而有很大部分的词典是无用的,或者多余的,直接减少高频词并不能令人满意,比如高频词“the” 和“is”. 发现哪个词或n-gram必须保留是特征选择的问题。hash也可进一步减少内存。
分类器中的B也经过压缩。总之这篇paper就是介绍的一个压缩技术PQ,而模型还是线性模型,激活函数可以是softmax,还可以是hierarchical softmax,也就是哈夫曼树:一个带权的路径长度最短的二叉树,也叫最优二叉树。
下图右边即是哈夫曼树,其权值为数值与深度的乘积和,13*1+7*2+2*3+5*3=48,此值小于左边的
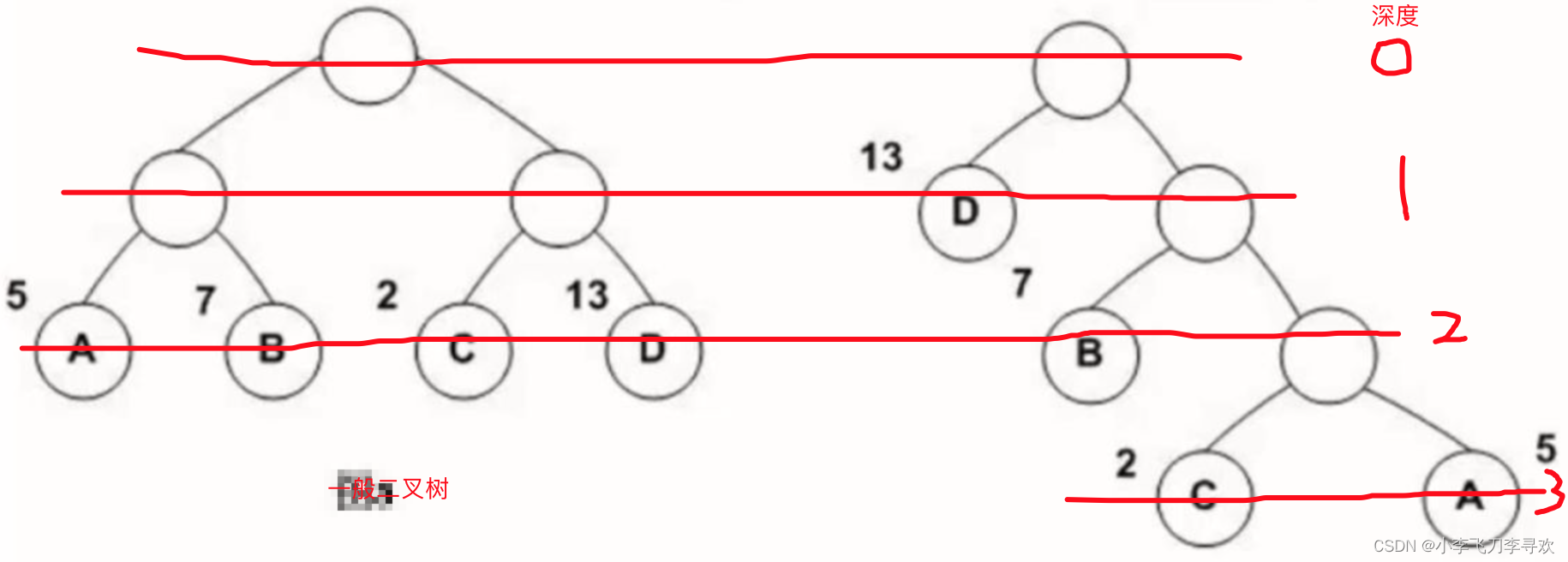
右边字母的分类可以表示为:D-0,B-10,C-110,A-111,是多个二分类综合在一起的。
其中的二分类由sigmoid来做,
3,压缩实例:参考博文
依旧以博文中的dbpedia数据为例:
#训练
fasttext supervised -input dbpedia.train -output train_out -dim 10 -lr 0.1 -wordNgrams 2 -minCount 1 -bucket 10000000 -epoch 5 -thread 4
#压缩
fasttext quantize -output train_out -input dbpedia.train -qnorm -retrain -epoch 1 -cutoff 100000
#测试原模型
fasttext test train_out.bin dbpedia.test
#测试压缩模型
fasttext test train_out.ftz dbpedia.test关注本专栏获取更多。






![[附源码]计算机毕业设计JAVA血库管理系统](https://img-blog.csdnimg.cn/3925942d292a48c895353ca9bece4430.png)


