Datawhale干货
作者:仲泰,Datawhale成员
1. 作者知乎:https://www.zhihu.com/people/yong-tan-39-67
2.我用GPT搭建了一个虚拟女友-哔哩哔哩:https://b23.tv/GYYwMcq
3. 五月学习:ChatGPT应用组队学习来了!
本项目是Datawhale四月学习的优秀分享。
心路历程
从去年年底ChatGPT问世以来,我对LLMs做了很多学习探索,从最初体验各种好玩的prompt,到开放API后部署QQ,VX的GPT机器人,套壳做镜像版GPT等,到忍痛开通GPT Plus,到几个账号被封,最后再到加入Datawhale,参加AIGC学习活动,我已经从一个无知的小白,成长为一个有经验的小白了,非常幸运在这段时间里认识了许多志同道合的伙伴和前辈,感谢你们的不吝赐教与无私分享,让一个AI本科生看到了希望。
我是那种想法很多但不太爱敲代码的人,我曾经梦想创业,拥有自己的公司和品牌,自高中起就做着各种尝试,但是理想很丰满,现实很骨感,目前的职业规划是AI产品经理(因为我相信产品经理是CEO最好的预科)。LLM的出现,极大地帮助了我这样代码能力一般(能看懂代码,但想要实现某种功能写出对应的代码比较吃力)的人来说无疑是巨大的福音。在这几个月里,陆陆续续看到国内外基于大语言模型做的很多项目,新的开源大模型发布,每每看到这样的讯息都让我热血沸腾。
在Datawhale四月AIGC的学习活动中,我决心要做一个自己满意的作业,起初我是尝试AI+教育方向的,因为我认为GPT凸显了应试教育的低效和短视,并且本科教育与社会生产存在一定的知识脱节,所以我想尝试用AI工具赋能K12或本科教育,改善现状,但后来我发现GPT存在一定的事实错误,但教育是严肃的严谨的,尽管我做的一些尝试是有一定价值的,但短期来看很难落地。

因此我换赛道到了AI+游戏上,我认识到近些年很多新兴技术的落地往往是从游戏行业开始的,因为具有娱乐性质更容易进入大众视野,最终我选择了虚拟女友这个方向,学习借鉴了一些开源项目,最终也算是实现了预期的效果。
实现思路
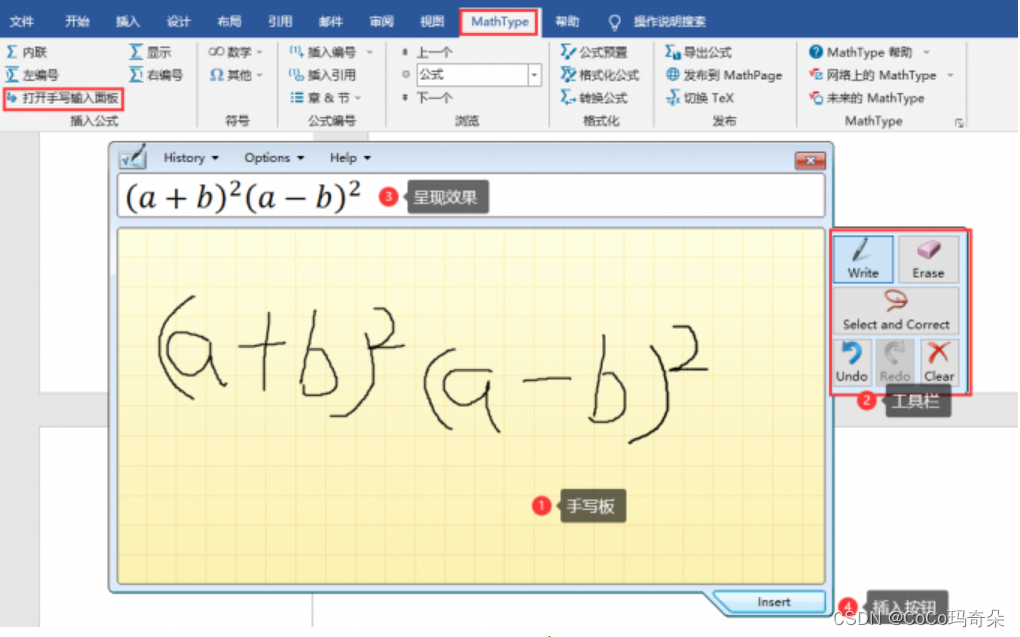
整个项目是由四个部分组成的,首先ChatGPT大家很熟悉,然后Vits是一个语音合成模型,前段时间很火的AI孙燕姿也是基于这个技术做的,然后Unity是游戏开发引擎,Live2D是一种应用于电子游戏的绘图渲染技术,简单讲就是做皮套人的。
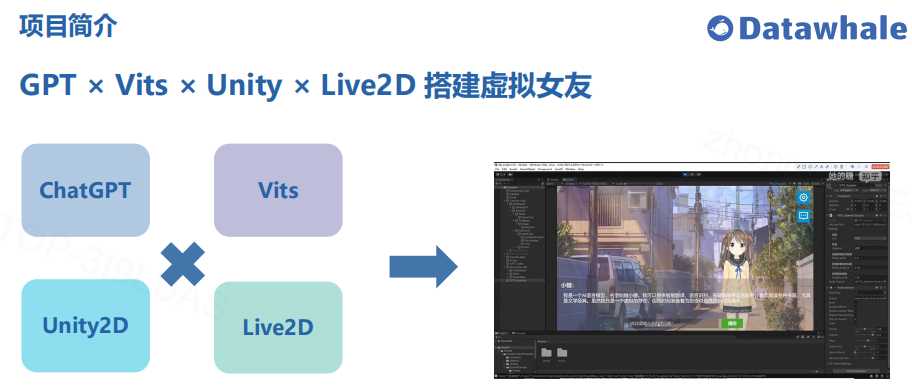
项目整体思路其实挺简单的,首先我们先去Live2D官网下载一个untiy的SDK,然后再选一个用的比较多的也比较可爱的皮肤,直接导入到unity里面就行,然后就是写一个接入GPT的脚本,可以加一个预设,比如:你叫小糖,请扮演我可爱的女朋友。最后再写一个脚本调用Vits的API就行了。
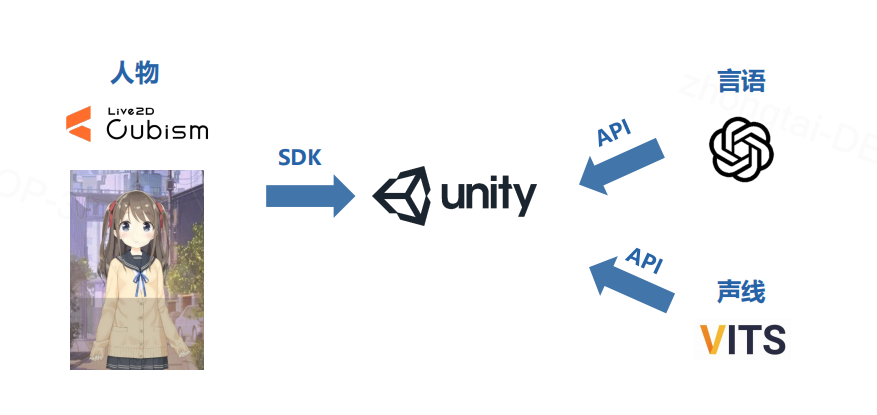
具体代码详见后续package文件内。
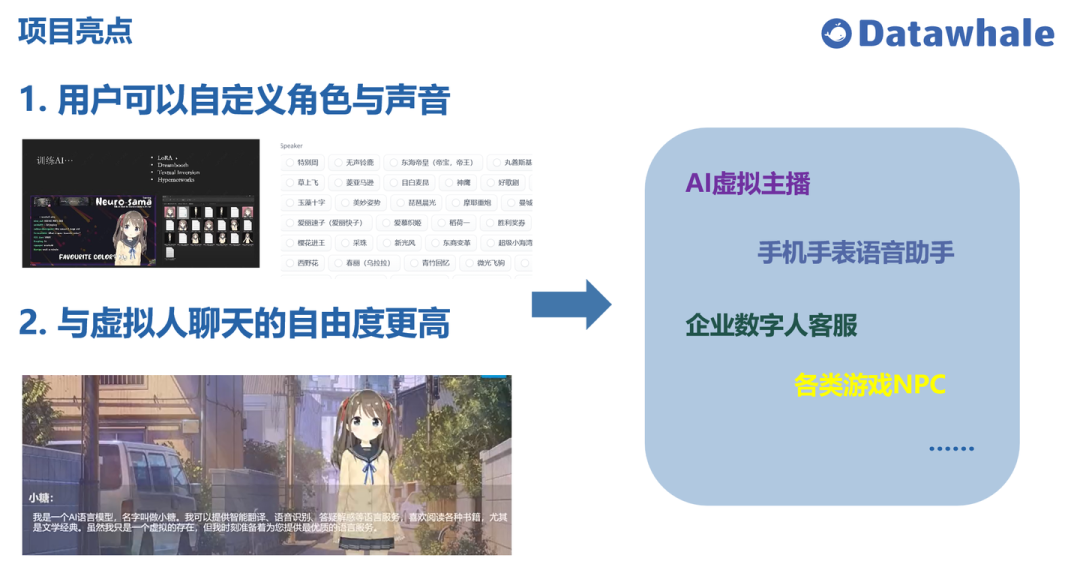
这个基于GPT的虚拟女友相比于以前传统的那种虚拟人,更加私人定制,自由度更高,比如再做一个捏脸系统,用户可以选择自己喜欢的角色和声音,然后以前像siri,天猫精灵这样的语音助手回答的内容比较固定单一,但是得益于chatgpt这样的生产式大语言模型,虚拟人每次的反馈都会是一个惊喜,再比如可以迭代一个语音识别的功能,用户不用打字只需要说话就可以和虚拟人进行互动。
基于虚拟女友这个想法出发,其实可以优化包装成别的产品,比如vtuber,手机手表语音助手,企业数字人客服,还有游戏里的NPC。
这版AI虚拟女友做的比较仓促,还是有一定的优化空间的,比如:
人称错乱,有时虚拟人的回答会用“她”而不是“我”
延迟较高,等待时间稍长
上下文记忆较短,体验欠佳
肢体动作和口型较为单一
人物情感不够丰富
可以采用微调模型训练,使用metahuman或VRoid建模,对输入的文本进行情感分析来改善
具体流程
Live2D人物准备
前往https://www.live2d.com/zh-CHS/download/cubism-sdk/下载
打开unity,新建一个2D项目
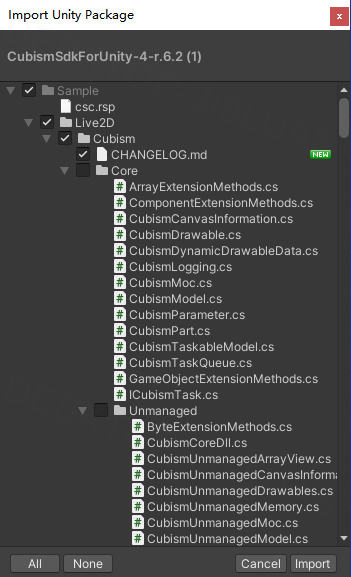
访问下载https://gitee.com/DammonSpace/vits-chatgpt-live2d-unity-wife,将SDK和package直接导入即可
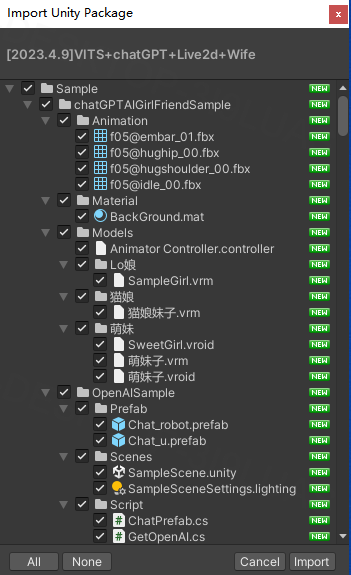
找到项目内的sample场景拖拽出来
这时候可能会遇到一个报错
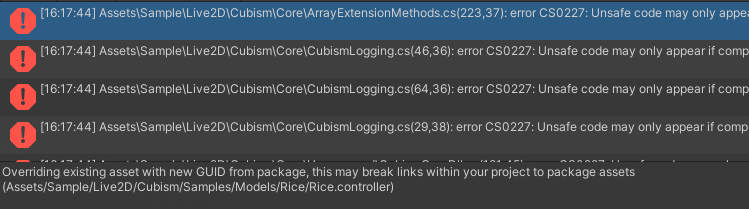
解决办法:Edit->Project Settings->Player, 勾选上Allow Unsafe Code选项
到此人物就加载完成了
本地vits部署
首先要安装anaconda(安装教程略)
git lfs install
git clone https://huggingface.co/spaces/zomehwh/vits-uma-genshin-honkai如果模型安装失败,可以到这里手动下载:https://huggingface.co/spaces/zomehwh/vits-uma-genshin-honkai/tree/main/model
注意这里可能会报错安装pyopenjtalk依赖失败 解决办法可以查看链接:https://www.bilibili.com/video/BV13t4y1V7DV/
conda create -n vits
activate vits
cd <项目文件夹>
pip install -r requirements.txt注意这里可能会报错安装pyopenjtalk依赖失败 解决办法可以查看链接:https://www.bilibili.com/video/BV13t4y1V7DV/
部署完成后运行python app.py 复制URL打开
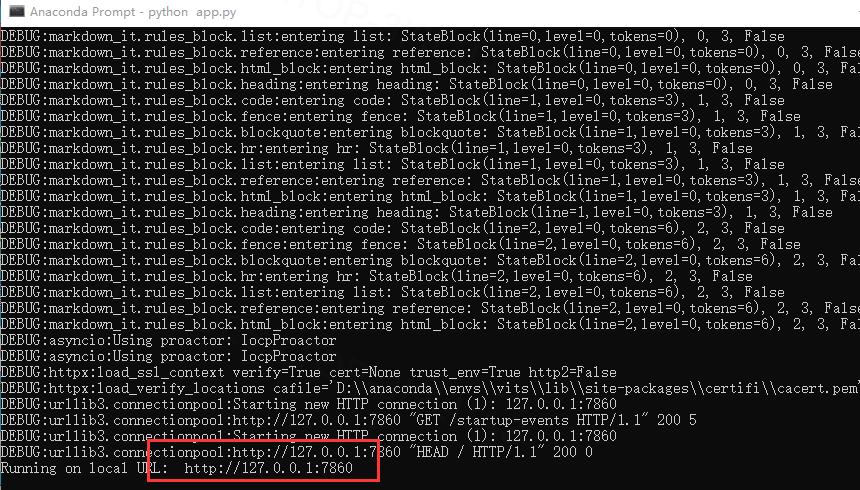
页面下方有个use via API,点进去可查看API调用方法,记得安装gradio_client(安装教程略)
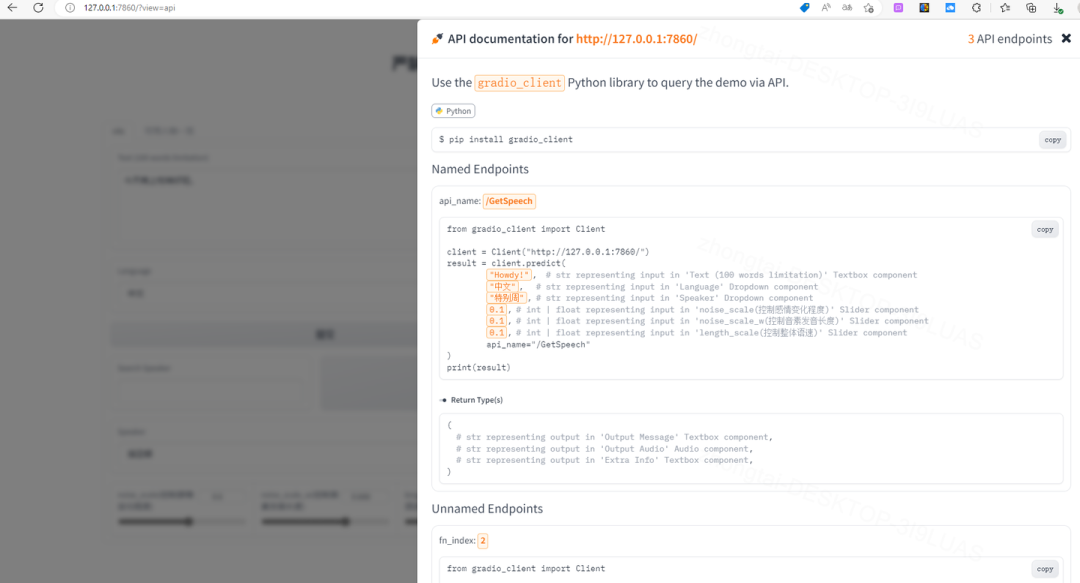
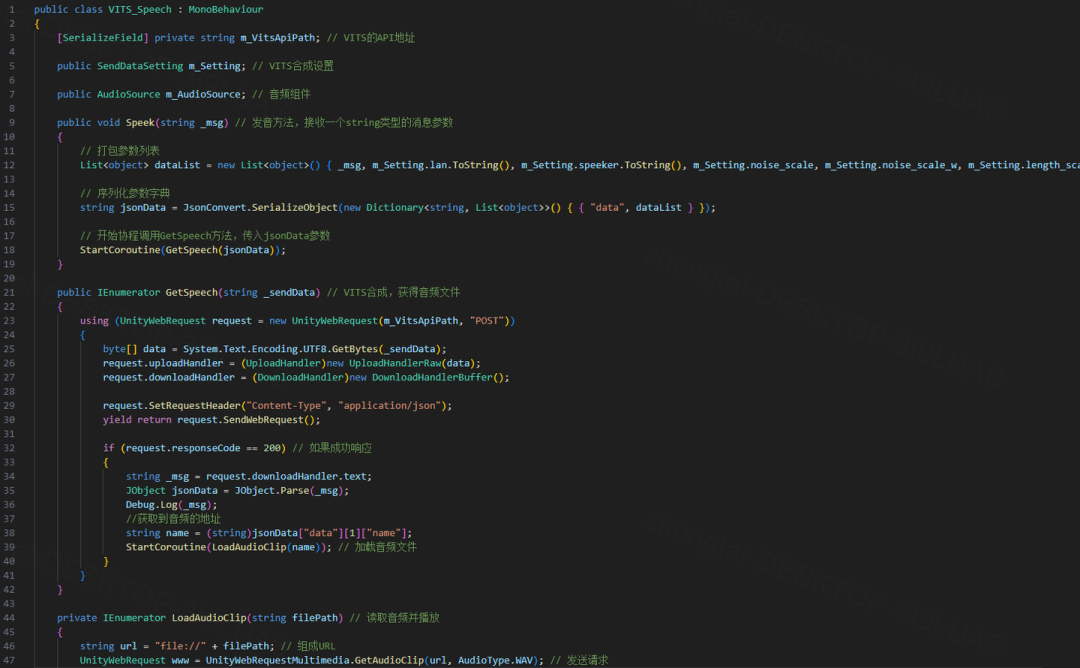
GPT和VITS的API接入
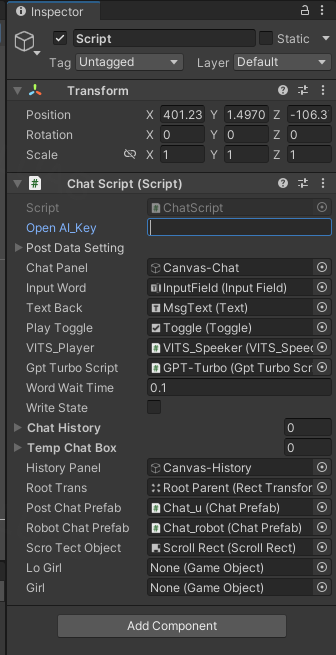
将你的APIkey填写到GPT脚本的Open AI_Key处
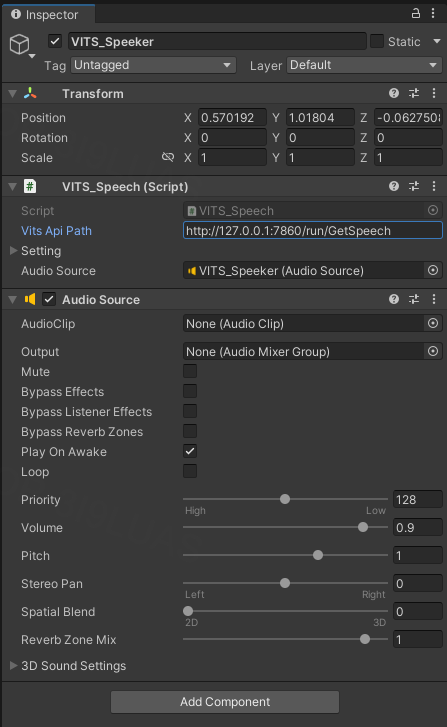
将http://127.0.0.1:7860/run/GetSpeech填写到vits的脚本里
最后,点击Game,然后改一下显示的分辨率,再运行项目即可
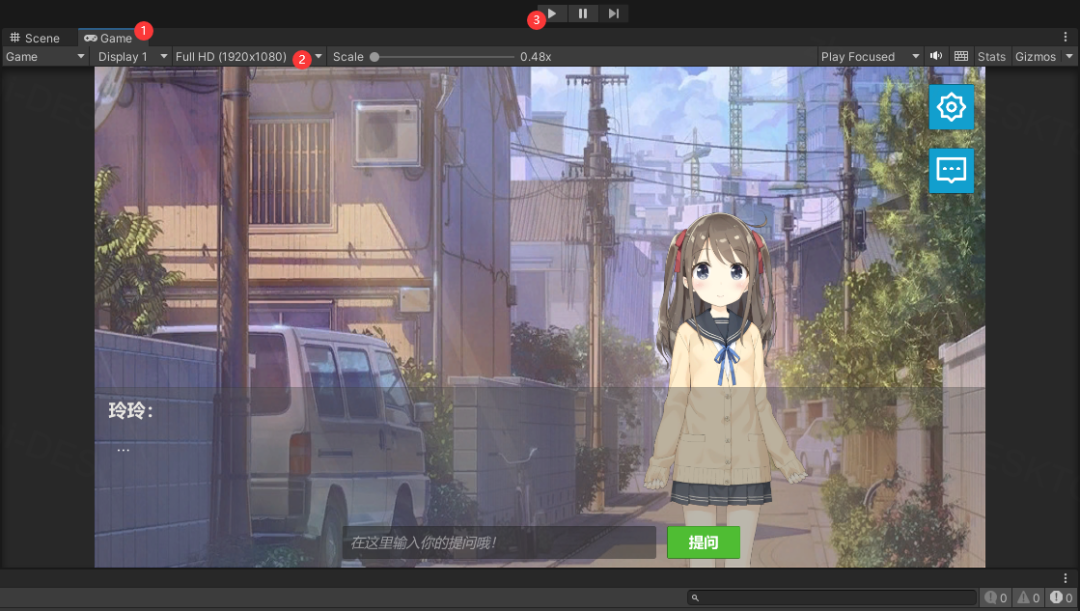
打开控制台,可以看到每次生成语音的耗时,显卡配置越好,生成所耗时间就越短,体验就越好

后记
在新时代来临之时,不少同学会感到迷茫,在知乎上也有很多相关提问,“XXX会不会失业”,“觉得AI是风口,我该如何学习”,“普通人如何利用GPT赚钱”等等。而在我看来为在AIGC的猛烈冲击下,心态很重要:
第一是要拥抱未来,持续学习
保持开放心态:“君子善假于物也”,我们需要拥抱AI时代并保持开放和乐观的心态,不畏惧新技术所带来的挑战。更新知识结构:在AI时代,我们需要不断更新自己的知识结构,特别是与AI相关的领域(如计算机科学、数据分析、统计学等),最近看到一句话说的挺好,“不是每个人生来都握着一副好牌,但学好数学+编程+机器学习,一定是王牌”。深度思考:既要持续关注AI领域的动态和趋势,使自己始终与时代同步,又要警惕追风捉影,深度思考问题,需求的本质。
第二是要应用场景并解决问题,实现自我和社会价值
深入行业:我们需要深入研究所处行业的需求和痛点,并发现AI技术可以解决的具体问题。创新与发展:通过挖掘AI技术的新应用场景,推动整个行业的创新与发展,并实现个人价值的提升。比如ControlNet为斯坦福计算机在读华人博士开发。传播AI:作为AI的使用者,我们可以帮助更多的人了解和使用AI技术,从而解决实际生活中的问题,促进个人和社会的进步。
参与学习:ChatGPT应用组队学习来了!

一起“收藏、点赞”三连↓