目录
前言
结构解析
默认成员函数
构造函数
拷贝构造
赋值重载
析构函数
迭代器
const迭代器
数据修改
insert
erase
尾插尾删头插头删
容量查询
源码
前言
🍉list之所以摆脱了单链表尾插麻烦,只能单向访问等缺点,正是因为其在结构上升级成了带头双向循环链表。不仅如此,list中迭代器的实现更是能拓宽我们对迭代器的认识,话不多说,马上开始今天的内容。
结构解析
🍉以前我们实现单链表的时候就只定义了节点的结构体,之后传回第一个节点就作为首个节点直接开始使用。而今天我们要封装的是一个 list,因此需要用一个类代表整个 list,之后还需要再定义一个类来表示节点。看下下图,可以了解得比较直观一些。
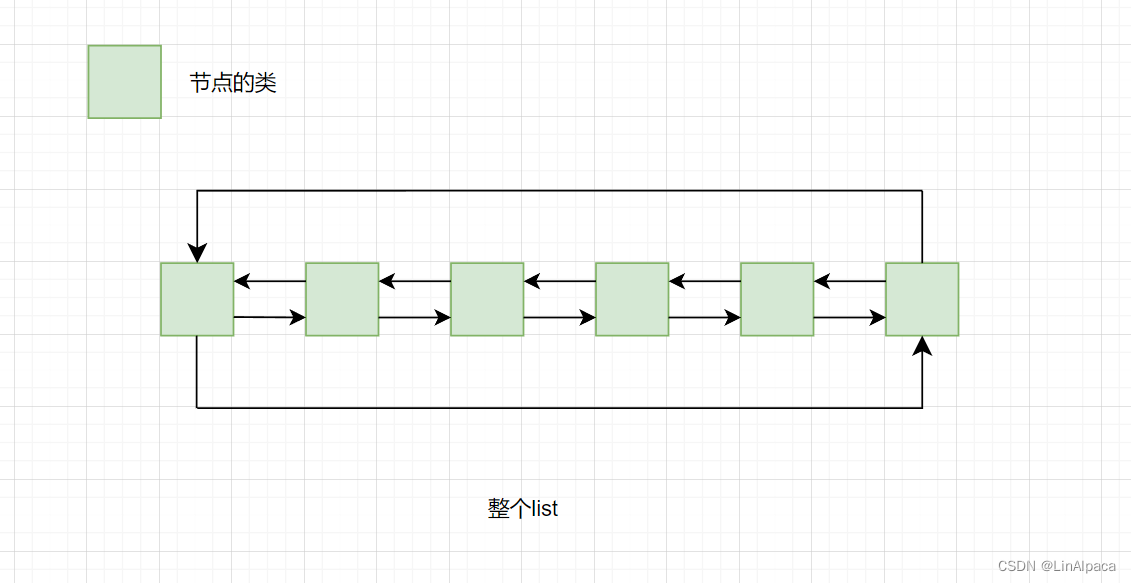
🍉之后我们将二者放进命名空间中,避免与库中的 list 重复。在这之中,由于结构是带头双向循环链表,所以一个节点中需要存放前后节点的指针和当前节点的数据,而头结点作为链表的首位,因此 list 中只要存头结点的指针即可。
namespace Alpaca
{
template <class T>
struct list_node //节点的类
{
list_node* _next;
list_node* _prev;
T _data;
};
template <class T>
class list //list的类
{
public:
typedef list_node<T> node;
private:
node* _head;
};
}🍉提到一个容器,除了它的数据结构之外,迭代器的组成也是十分重要,之前模拟实现 string 和 vector 的时候,我们都是使用原生指针作为迭代器进行使用的,这是因为二者都是在连续的空间存储的。直接 ++ 指针便可以直接访问到下一个数据。但链表的各个节点并不是开辟在相邻的空间之中,而是使用节点中的指针访问下一节点的,因此继续用原生指针 ++ 并不能达到访问的目的。所以我们需要手动封装一个迭代器来满足访问数据的需求。
template <class T, class Ref, class Ptr>
struct list_iterator
{
typedef list_node<T> node;
typedef list_iterator<T, Ref, Ptr> self;
node* _node;
};🍉至于为什么模板参数那么多,在下面迭代器部分会详细讲解。
默认成员函数
🍉即便 list 中没有其余数据,但可以确定其中至少有一个头结点,因此不论是什么类型的构造函数,都要对头结点进行初始化。为了简化代码,不妨将这个操作单独写成一个函数。
void empty_init()
{
_head = new node; //开辟节点
_head->_next = _head; //维持循环关系
_head->_prev = _head;
}构造函数
🍉与库中的构造函数靠齐,这里我们还是实现三种构造函数。
- 无参数构造
- n个值构造
- 迭代器区间构造
🍉第一个无参数构造实际上只需要初始化头结点即可,因此直接调用上面实现的函数即可。
list()
{
empty_init();
}🍉第二个构造则是以 n 个值来构造,因此只需要限定次数后依次插入相同数据即可。
🍉值得注意的一点是,传入的数据类型可能是自定义类型,因此不能使用浅拷贝,而必须使用深拷贝(即调用类型本身的构造函数)。
🍉因此这里使用了 push_back,具体实现在数据修改部分讲解,本质就是调用原数据类型的拷贝构造生成一个新的数据。
list(int n, const T& value = T())
{
empty_init();
for (int i = 0; i < n; i++)
{
push_back(value);
}
}🍉使用迭代器区间进行拷贝,但是这个迭代器并不一定是 list 的迭代器,可能是 vector 的也可能是 string 的。所以要再使用一个模板来表示迭代器的类型。因此这里同样要使用深拷贝才能确保不出错。
template<class InputIterator>
list(InputIterator first, InputIterator last)
{
empty_init();
while (first != last) //遍历迭代器区间
{
push_back(*first);
first++;
}
}拷贝构造
🍉传入一个 list,需要复制一个值一样的 list 出来,但转念一想不就跟上面使用迭代器区间构造一样吗?
list(const list<T>& l)
{
empty_init();
const_iterator cur = l.begin();
while (cur != l.end())
{
push_back(*cur);
cur++;
}
}🍉咻一下,很快啊代码就写好了。 这时候我们不禁想,既然代码重合度那么高,我们能否能够复用迭代器区间构造来实现拷贝构造呢?
🍉在这之前,有一个重要的拼图我们还没有实现,那就是交换函数,实际上我们通过复用库中的交换函数交换头结点即可。
void swap(list<T>& l)
{
std::swap(_head, l._head);
}🍉下面就是见证奇迹的时刻,我们通过迭代器区间构造出一个临时的 list,之后将临时的 list 和当前 list 交换,即完成拷贝构造。
list(const list<T>& l)
{
empty_init();
list<T> tmp(l.begin(), l.end());
swap(tmp);
}🍉函数结束后,tmp 就会调用析构,释放原来 list 中的节点。
赋值重载
🍉之前 vector 和 string 实现之中,我们也是直接使用了这个方法,直接传值调用赋值重载,之后交换两个 list 即可。
list<T>& operator=(list<T> l)
{
swap(l);
return *this;
}析构函数
🍉list 与 vector 不一样,析构 list 时需要释放链表中的所有节点,之后再销毁头结点,因此可以单独写一个 clear 函数释放节点。
🍉从头开始删除节点即可,为了避免迭代器失效,因此要接收 erase 的返回值。
void clear()
{
iterator it = begin();
while (it != end())
{
it = erase(it);
}
}
~list()
{
clear();
delete _head;
_head = nullptr;
}迭代器
🍉在上面,我们讲过我们要对迭代器进行封装来满足实际访问时的需求,迭代器内部实际上存着一个节点的指针。
🍉一般都是以节点地址作为参数来构建迭代器,而当拷贝构造时,直接赋值即可。
🍉这是因为迭代器本身起一个访问的效果,与两个指向同一地址的指针的地址并不相同是同一个道理。
list_iterator(node* n = nullptr) //默认构造
:_node(n)
{}
list_iterator(const self& s) //拷贝构造
:_node(s._node)
{}🍉同时这个迭代器的类并不需要写析构函数,因为在这个类中我们也并没有手动申请空间需要手动释放等情况,使用默认的析构即可。
🍉作为一个迭代器,我们自然要放眼于其的迭代区间,begin 和 end 的范围该如何判断?
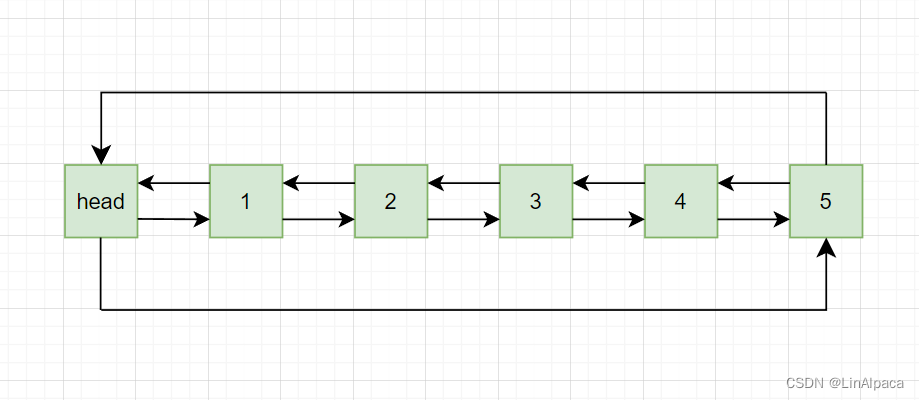
🍉再看了一眼结构图,其中头结点自然是不能访问的,头结点的下一个节点才是有效节点,那什么时候才能算访问完整个 list 呢?
🍉由于带头双向循环链表中是不会出现 nullptr 的,因此在访问完所有数据后就会回到头结点。
🍉因此 begin 就是头节点的下一位,而 end 就是头节点,同时这里使用匿名对象是为了贴合编译器的优化方式。
iterator begin()
{
return iterator(_head->_next);
}
iterator end()
{
return iterator(_head);
}🍉之后就是对运算符进行重载了,结合实际的使用,++ 就是转换成下一个节点,-- 就是转换成上一个节点。
🍉通过对节点地址的比较便可实现两个迭代器的比较。
🍉其中 self 类型就是 typedef 之后的当前迭代器类型。
self& operator ++()
{
_node = _node->_next;
return *this;
}
self operator ++(int)
{
self tmp = *this;
_node = _node->_next;
return tmp;
}
self operator --(int)
{
self tmp = *this;
_node = _node->_prev;
return tmp;
}
self& operator --()
{
_node = _node->_prev;
return *this;
}
bool operator != (const self& s) const
{
return _node != s._node;
}
bool operator == (const self& s) const
{
return _node == s._node;
}
const迭代器
🍉这时候,有人看了一眼迭代器的模板参数,问说为什么这个迭代器需要三个模板参数呢?
iterator begin()
{
return iterator(_head->_next);
}🍉若我们直接像上面进行重载,在我们使用 const 迭代器时就会出现权限放大的情况。
🍉那在 iterator 前再加上 const 呢?虽然不会报错,但是实际使用起来,并不能保护我们的数据不被修改。
const iterator begin()
{
return iterator(_head->_next);
}🍉这是由于在只有一个模板参数的情况下, iterator 的原型就是 list_iterator<T> 而加了一个 const 就代表保护类中的指针不被修改,但实际上我们要保护不被修改的对象是类中指针指向的那个数据,因此直接在 iterator 前加 const 是没有效果的。这个时候摆在我们面前就只有两个选择了,一是专门写一份const 迭代器,二则是增加一个迭代器模板参数在使用时传入一个 const T 供我们使用。
[注意]: 直接在迭代器代码中设置返回 const 那也是不可以的,因为不是所有的链表都被限定不再修改。
🍉同样的道理不仅在 & 中并且在 * 类型中的数据也要确保能被 const 保护起来,因此,在list中便可以这样定义。
typedef list_iterator<T, T&, T*> iterator;
typedef list_iterator<T, const T&, const T*> const_iterator;🍉迭代器的模板为
template <class T, class Ref, class Ptr>🍉如此,我们便可以将上面漏掉的 * 和 -> 重载给补上了。
Ref operator *()
{
return _node->_data;
}
Ptr operator ->()
{
return &(operator*());
}🍉值得注意的是,这里对 -> 的解引用其实是经过编译器优化的,实际上应该是需要使用两个 -> 一个用于调用重载,一个用于访问类中的成员。之所以进行优化就是为了贴合使用增加可读性。
假设代码这样使用 l->val
转换成 &(_node->_data)->val
实际上 l->->val 🍉之后我们还要在 list 中加上获取 const 类型迭代器的版本。
const_iterator begin() const
{
return const_iterator(_head->_next);
}
const_iterator end() const
{
return const_iterator(_head);
}数据修改
insert
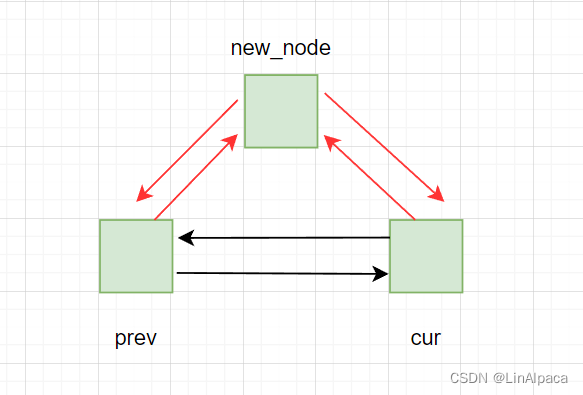
🍉用指定一个位置,在这个位置插入一个节点,这里我们就不需要向 vector 那样挪动数据了,只需要更改节点中的指针即可。
void insert(iterator pos, const T& x = T())
{
node* cur = pos._node; //当前位置节点
node* prev = cur->_prev; //上一个节点
node* new_node = new node(x); //新的节点
prev->_next = new_node; //更改指向
new_node->_prev = prev;
new_node->_next = cur;
cur->_prev = new_node;
}🍉下图中,黑色代表原来指针,红色代表之后各个节点的指向。 由于 list 中节点各自不互相影响,因此不会出现扩容的情况,即 insert 后迭代器并不会失效。
erase
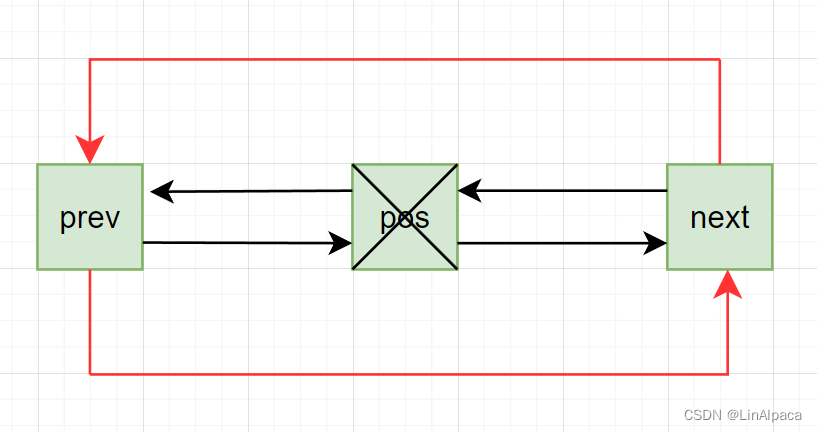
🍉erase 用于删除指定位置的节点,我们通过获取当前节点前后节点,更改二者指向后再删除当前节点。
🍉由于 erase 面临迭代器失效的问题,因此在最后我们需要返回指向下一位的迭代器用于更新。
iterator erase(iterator pos)
{
assert(pos != end()); //不删除头结点
node* prev = pos._node->_prev; //拿到后节点
node* next = pos._node->_next;
prev->_next = next; //更改指向
next->_prev = prev;
delete pos._node; //释放节点
return iterator(next); //返回下一个节点
}
尾插尾删头插头删
🍉通过对前面 insert 和 erase 的复用,我们便可以轻松地完成 尾插尾删 和 头插头删 的实现。
void push_back(const T& x)
{
insert(begin(), x);
}
void pop_back()
{
erase(--end());
}
void push_front(const T& x)
{
insert(begin(), x);
}
void pop_front()
{
erase(begin());
}容量查询
🍉查询 list 的容量只需要数一数节点的个数,我们遍历一遍 list 就能够得到结果。
size_t size() const
{
size_t count = 0;
for (auto it = begin(); it != end(); it++)
{
count++;
}
return count;
}🍉而判空就更加简单了,只要判断头结点的下一位是否还是头结点即可。
bool empty() const
{
return _head->_next == _head;
}源码
🍉感兴趣的可以来这里看看源码。
代码仓库
🍉好了,今天 list模拟实现 的相关内容到这里就结束了,如果这篇文章对你有用的话还请留下你的三连加关注。