一、概述
title:The Power of Scale for Parameter-Efficient Prompt Tuning
论文地址:https://arxiv.org/abs/2104.08691
代码:GitHub - google-research/prompt-tuning: Original Implementation of Prompt Tuning from Lester, et al, 2021
1.1 Motivation
- 大模型对每个任务训练一个模型,开销和部署成本都比较高(一个大模型的权重可能要40G,多个任务成本比较高)。
- discrete prompts(离散prompts)是指人工设计prompts提示语加入到模型中,这样成本比较高,并且效果好像不太行。
1.2 Methods
- 方案概述:通过反向传播更新参数来学习prompts,而不是人工设置prompts,同时冻结模型原始权重,只训练prompts参数,训练完以后,用同一个模型可以做多任务推理,而不用像原始model tuning方法一样,对每个任务都训练一个模型了。
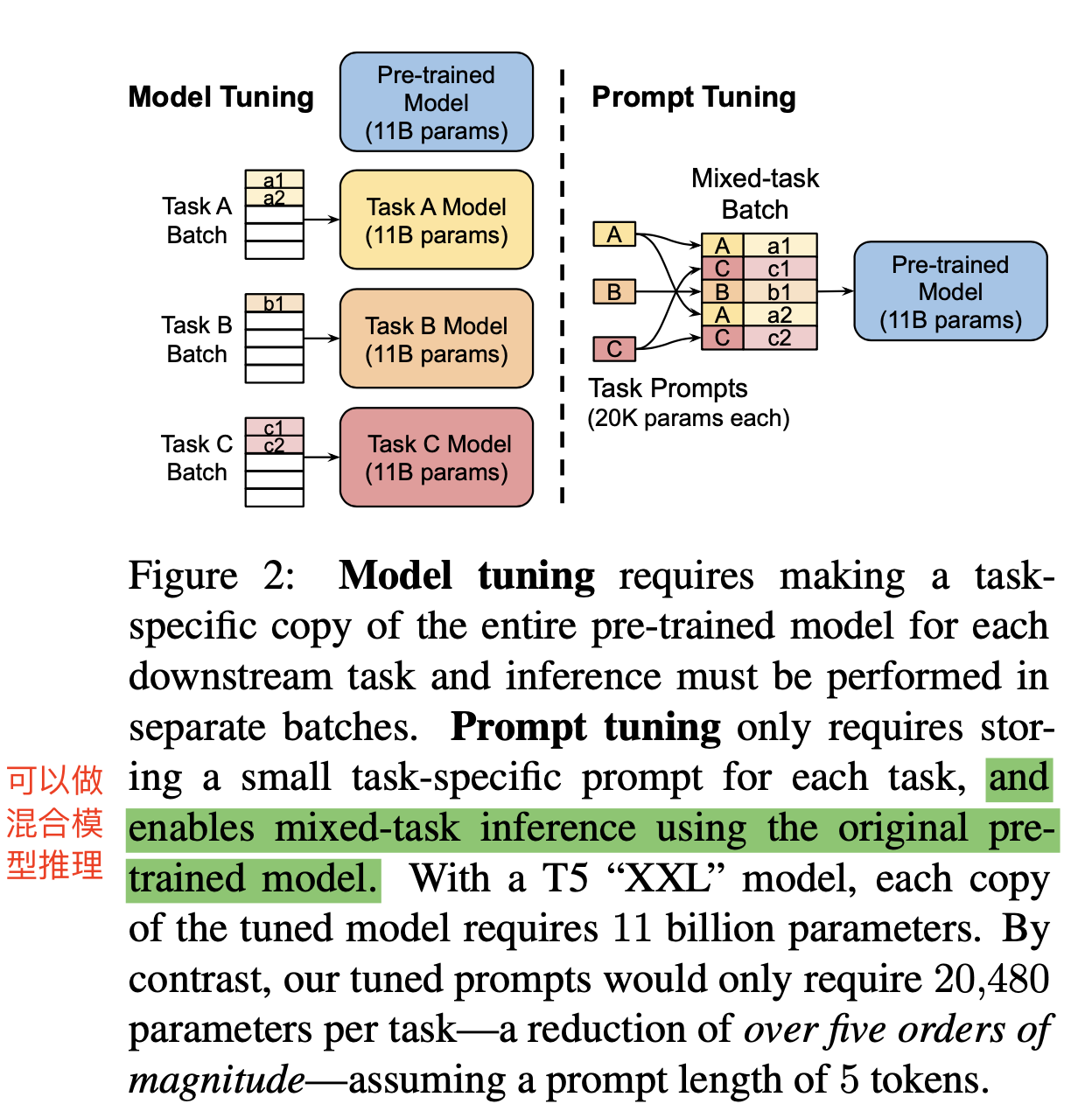
- 与prefix-tuning的不同:prefix-tuning是更新transformer所有中间层,prompt-tuning只在输入的embedding端添加,所以叫prompt tuning。

1.3 Conclusion
- 可以作为一个有竞争力的方案将大模型适配到下游任务中,在SuperGLUE上也取得不错的结果(T5),比GPT-3的few-shot效果好不少。
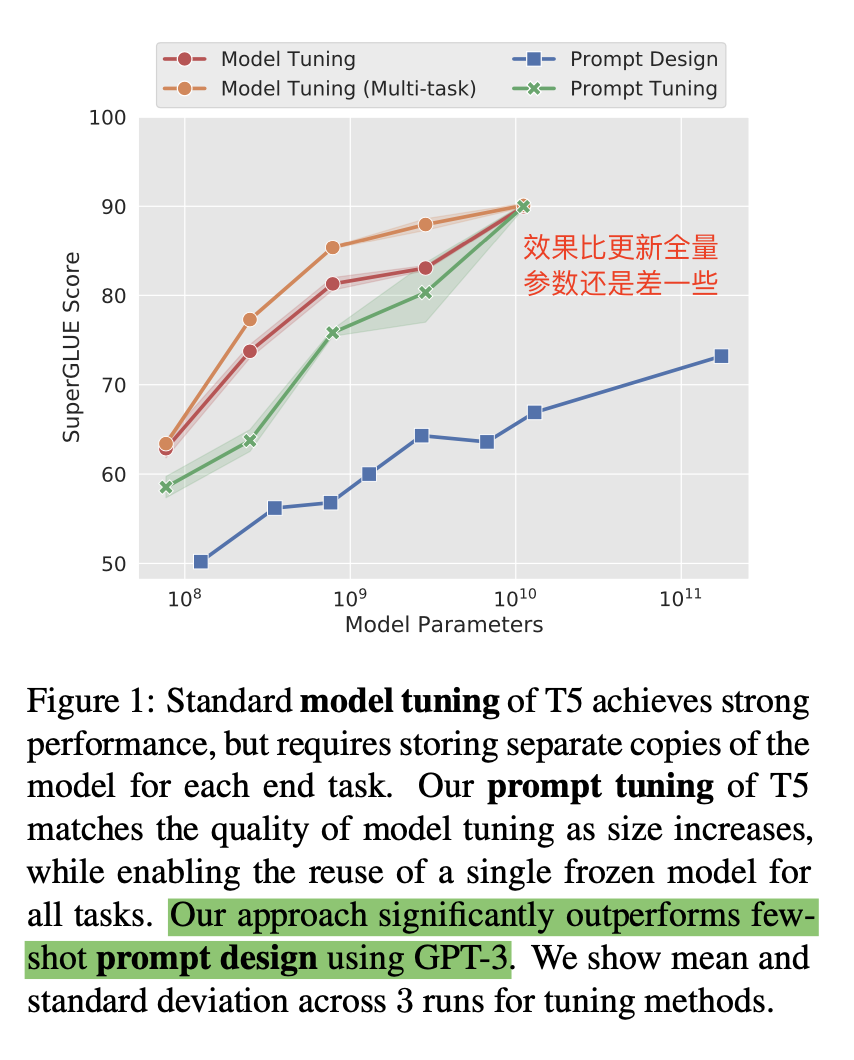
- 随着模型尺寸增加,prompt tuning和model tuning(全参数微调)gap消失。
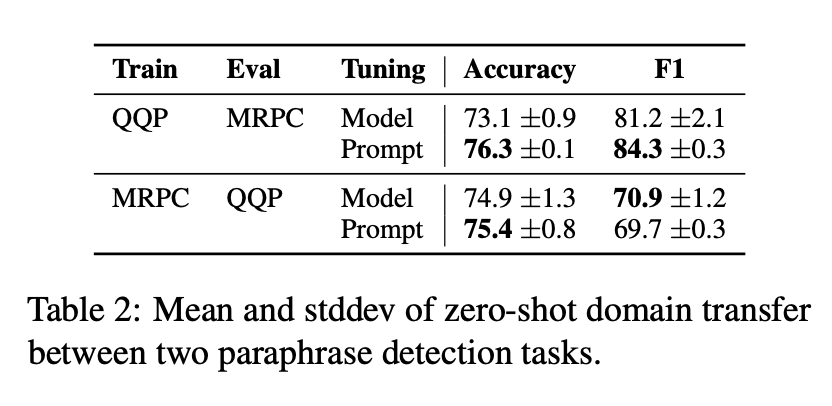
- prompt tuning(全量微调)比model tuning在zero-shot上的效果好很多。说明其有比较强的跨领域的迁移学习,能提升generalization,同时表明冻结大模型的参数,将更新限制在少量轻量级的参数上可能还有防止过拟合的效果。

1.3 Interpretability

- prompt design:
-
- 很好解释
- prompt tuning:
-
- 不好解释,所以利用学到的embeding,利用cosin相似度找到最相近的一些词,来看最终学到了什么prompt,发现还是和理想的prompt词差别不是特别大
- 用label的embedding进行初始化,发现tuning后embedding基本不变,而随机初始化或者sample初始化,也发现是在label附近继续找,说明模型可能就是想让label作为prompt。
- prompt设置比较长后(100),发现有些token会找到相同的邻居,说明太长了可能会超过prompt此处的容量。
二、实验
1 模型参数消融实验
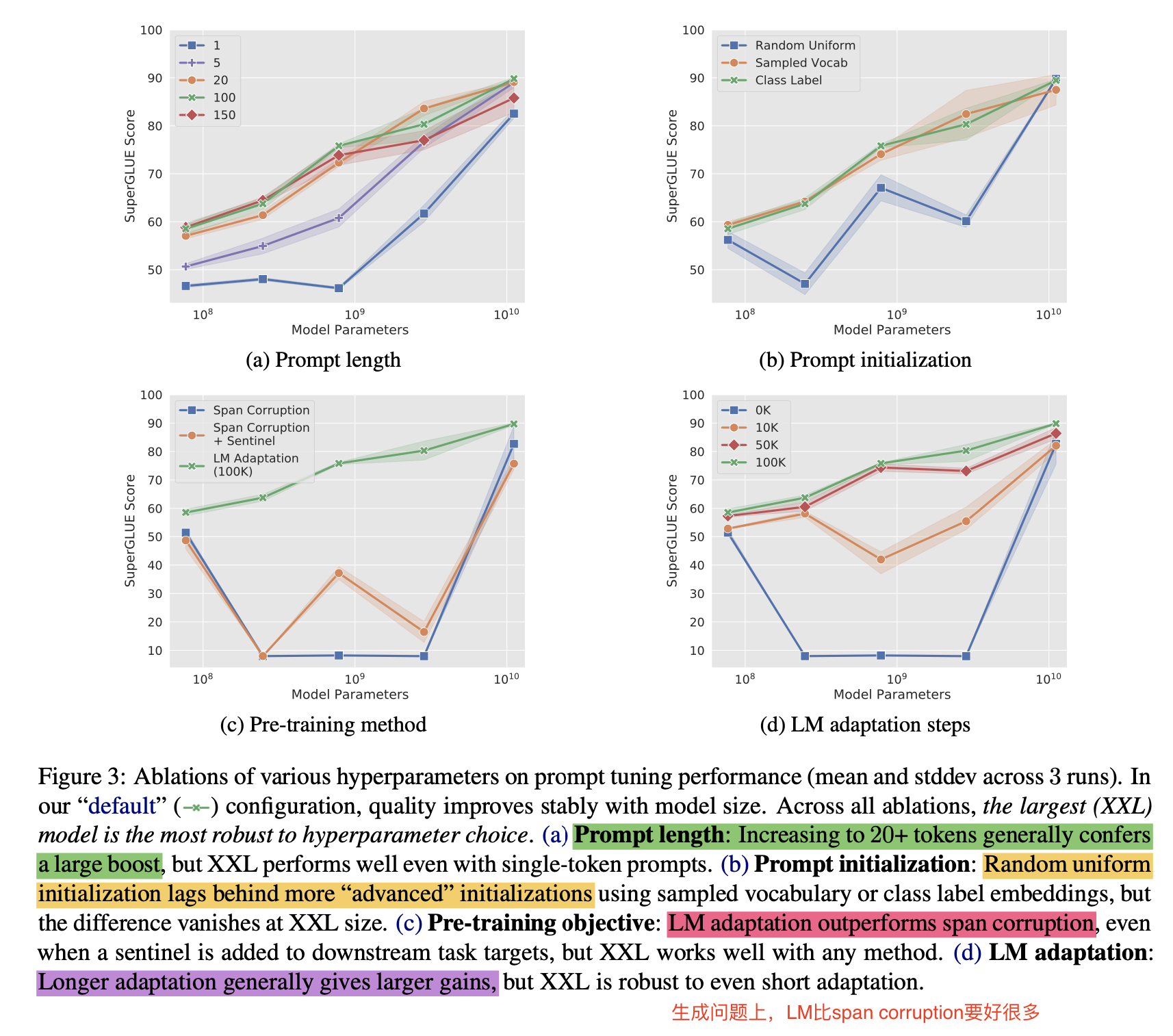
- 在prompt长度,prompt初始化方法,预训练方法,训练步数上都做了消融实验,模型变大后,超参数影响都不大了
-
- prompt长度:超过20效果就不错了
- 初始化方法:随机初始化效果很差
- 预训练方法:LM比span corruption要好
- 训练步数:训练越长效果越好
2 参数的量级对比
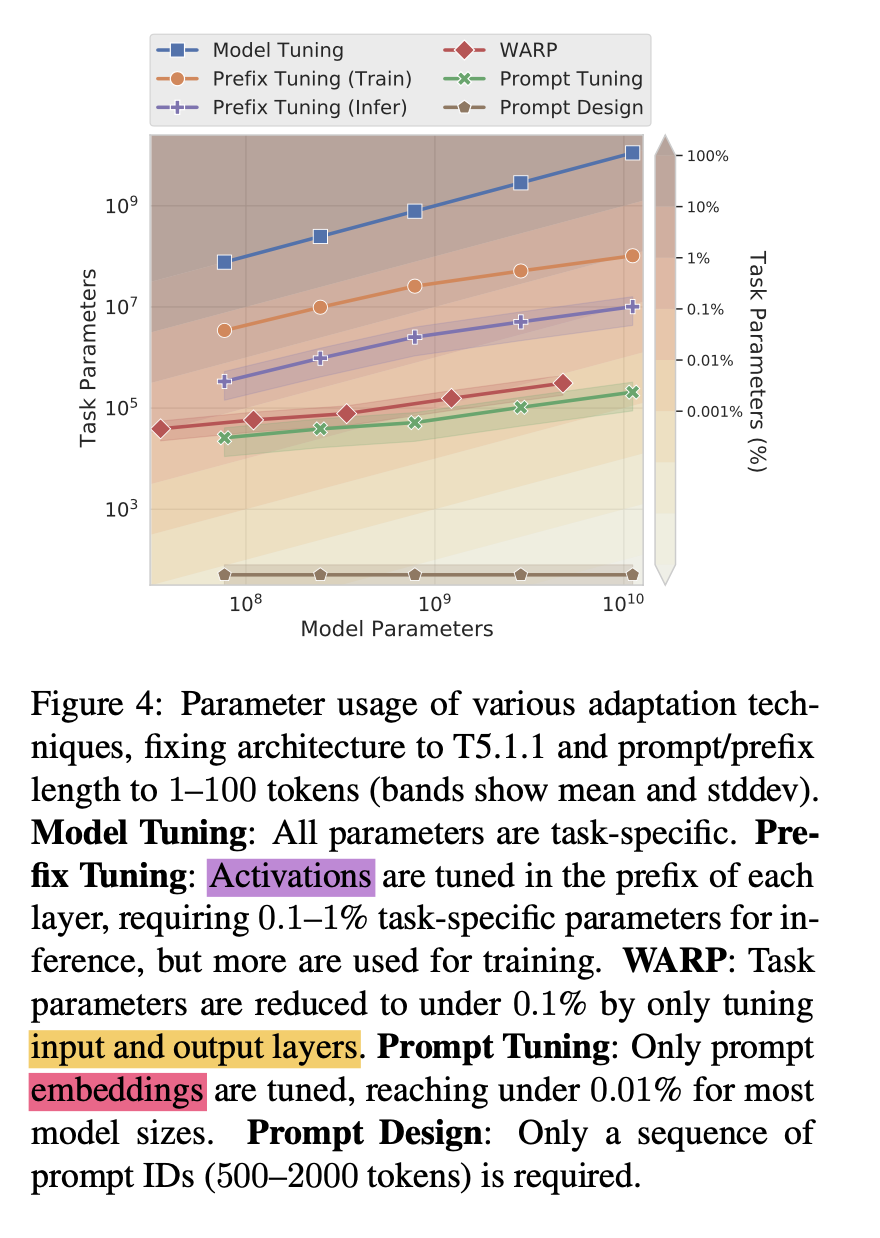
- Model Tuning:更新所有参数
- pre-fix tuning:更新activations
- WARP:更新输入输出层
- Prompt Tuning:prompt embedding更新
- prompt design:只需要添加prompt提示语