Linux-0.11 文件系统namei.c详解
模块简介
namei.c是整个linux-0.11版本的内核中最长的函数,总长度为700+行。其核心是namei函数,即根据文件路径寻找对应的i节点。 除此以外,该模块还包含一些创建目录,删除目录,创建目录项等系统调用。
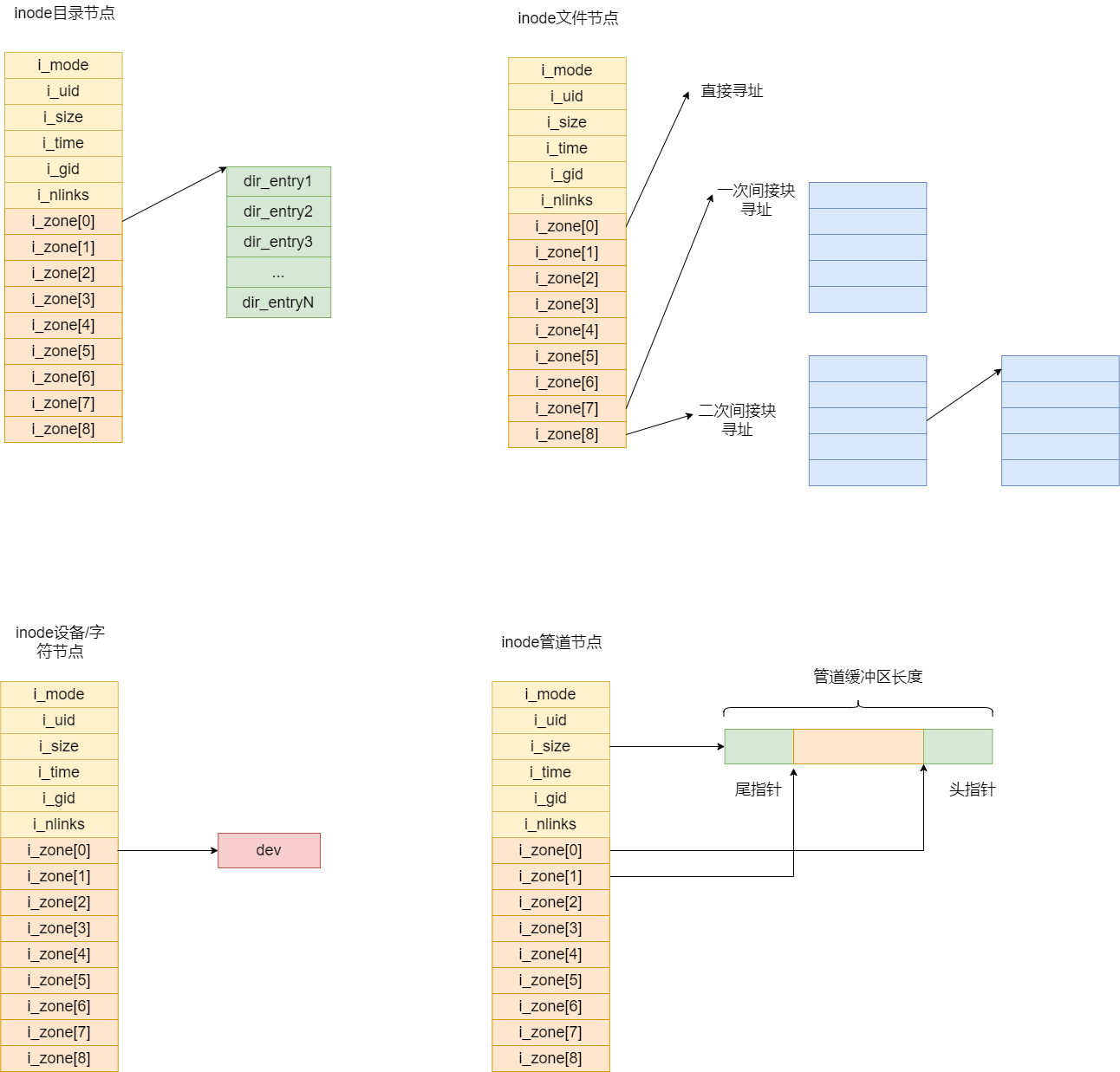
在接触本模块的具体函数之前,可以回顾一下不同的i节点,这将对理解本模块的函数非常有帮助。
对于目录节点,其i_zone[0]指向的block中存放的是dir_entry。
对于文件节点,其i_zone[0] - i_zone[6]是直接寻址块。i_zone[7]是一次间接寻址块,i_zone[8]是二次间接寻址块。
对于设备节点, 其i_zone[0]存放的是设备号。
对于管道节点, 其i_size指向的是管道缓冲区的起始位置,i_zone[0]为已用缓冲区的头指针, i_zone[1]是已用缓冲区的尾指针。
函数详解
permission
static int permission(struct m_inode * inode,int mask)
该函数用于检查进程操作文件inode的权限。
inode的权限存储在i_mode字段中,其是一个16位长度的无符号整型数据。其0-2位代表其他用户对该i节点的操作权限,其3-5位代表同一个用户组的用户对该i节点的操作权限,其6-8位代表文件所属用户的对i节点的操作权限。如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UnnaCjuB-1685200748390)(null)]
有了对i_mode的理解之后,可以更好地理解permission函数。
入参mask用于检查权限,其检查内容可以从下表中获取。
| mask的值 | 含义 |
|---|---|
| mask = 4 | 检查进程是否有权限读该inode |
| mask = 2 | 检查进程是否有权限写该inode |
| mask = 1 | 检查进程是否有权限执行该inode |
| mask = 5 | 检查进程是否有权限读和执行该inode |
| mask = 3 | 检查进程是否有权限写和执行该inode |
| mask = 6 | 检查进程是否有权限读和写该inode |
| mask = 7 | 检查进程是否有权限读写和执行该inode |
下面开始理解permission中的代码。
int mode = inode->i_mode;//首先从inode节点中的i_mode字段获取i节点权限
/* special case: not even root can read/write a deleted file */
if (inode->i_dev && !inode->i_nlinks)//如果一个i节点已经被删除是不可以被读取的
return 0;
else if (current->euid==inode->i_uid)//如果用户id相同,向右移动6位
mode >>= 6;
else if (current->egid==inode->i_gid)//如果组id相同,向右移动3位
mode >>= 3;
if (((mode & mask & 0007) == mask) || suser())//访问权限和掩码相同,或者是超级用户
return 1;
return 0;
match
static int match(int len,const char * name,struct dir_entry * de)
该函数用于比较name的和de->name的前len个字符是否相等。(注意name处于用户空间)。
首先对参数进行校验。如果目录项指针de为空, 或者de中的inode节点指针为空,或者长度len大于文件名的最大长度,则直接返回0。
接下来是对目录项中文件名的长度进行校验,如果其长度大于len,则de->name[len]的值不为NULL。在这种情况下,直接返回0。
register int same ;
if (!de || !de->inode || len > NAME_LEN)
return 0;
if (len < NAME_LEN && de->name[len])
return 0;
下面通过一段汇编实现字符串指定长度的比较。
其中,esi指向name,edi指向de->name, ecx的值为len, 将eax的值赋值给same。
__asm__("cld\n\t"//清方向位
"fs ; repe ; cmpsb\n\t"//用户空间 执行循环比较 while(ecx--) fs:esi++ == es:edi++
"setz %%al"//如果结果一样,则设置al = 1
:"=a" (same)
:"0" (0),"S" ((long) name),"D" ((long) de->name),"c" (len)
);
return same;
其中,下面这行汇编较难理解,
fs ; repe ; cmpsb
cmpsb指令用于比较ds:esi和es:edi指向的一个字节的内容。 而加上了前缀repe之后,就代表重复执行cmpsb指令,直到ecx等于0,或者ds:esi和es:edi的值不等。 但是由于name在用户空间,因此还需要加上fs前缀,使得被操作数修改为fs:esi。
find_entry
static struct buffer_head * find_entry(struct m_inode ** dir,
const char * name, int namelen, struct dir_entry ** res_dir)
该函数的作用是是去指定的目录下用文件名搜索相应的文件,返回对应的dir_entry结构。
假设现在有一个路径/home/work/test.txt,dir指向的是/home,name指向的是work/test.txt,namelen=4, 那么该函数将会找到/home/work对应的dir_entry(dir_entry中包含了inode号和目录名字)。
整个find的过程可以参考下面这张图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1cmz0JXb-1685200747440)(null)]
刚开始定义了一些参数,并对一些参数的有效性进行了校验。 如果定义了宏NO_TRUNCATE, 如果长度超长,就直接返回NULL。如果没有定义该宏, 长度超长,则进行截断。
int entries;
int block,i;
struct buffer_head * bh;
struct dir_entry * de;
struct super_block * sb;
#ifdef NO_TRUNCATE
if (namelen > NAME_LEN)
return NULL;
#else
if (namelen > NAME_LEN)
namelen = NAME_LEN;
#endif
接下来取出当前的目录中有多少个目录项。
entries = (*dir)->i_size / (sizeof (struct dir_entry));
*res_dir = NULL;
if (!namelen)
return NULL;
接下来对一些特别的场景进行处理,即当name=..的情况。
首先,假设一个进程的根目录是/home/work,但是目前访问的地址是/home/work/.., 这种情况是不被允许的,因此这里会将/home/work/..处理成/home/work/.。
另外,如果该目录的i节点号等于1,说明是某个文件系统的根inode节点。这个时候如果要执行…操作就需要特殊处理。 首先取出文件系统的超级块,查看该文件系统被安装到了哪个inode节点上,如果该节点是存在的,那么会将(*dir)指向安装的inode节点。
/* check for '..', as we might have to do some "magic" for it */
if (namelen==2 && get_fs_byte(name)=='.' && get_fs_byte(name+1)=='.') {
/* '..' in a pseudo-root results in a faked '.' (just change namelen) */
if ((*dir) == current->root)
namelen=1;
else if ((*dir)->i_num == ROOT_INO) {
/* '..' over a mount-point results in 'dir' being exchanged for the mounted
directory-inode. NOTE! We set mounted, so that we can iput the new dir */
sb=get_super((*dir)->i_dev);
if (sb->s_imount) {
iput(*dir);
(*dir)=sb->s_imount;
(*dir)->i_count++;
}
}
}
如果name不为…,则进入下面的逻辑。
接着取出dir对应的inode节点对应的数据块的内容(dir目录下的文件)。
if (!(block = (*dir)->i_zone[0]))
return NULL;
if (!(bh = bread((*dir)->i_dev,block)))
return NULL;
i = 0;
de = (struct dir_entry *) bh->b_data;
接下来便进行遍历所有的目录项的内容,比较de->name和name 相同的项。
while (i < entries) {
if ((char *)de >= BLOCK_SIZE+bh->b_data) {
brelse(bh);
bh = NULL;
if (!(block = bmap(*dir,i/DIR_ENTRIES_PER_BLOCK)) ||
!(bh = bread((*dir)->i_dev,block))) {
i += DIR_ENTRIES_PER_BLOCK;
continue;
}
de = (struct dir_entry *) bh->b_data;
}
if (match(namelen,name,de)) { //如果匹配上了,就返回对应的dir_entry
*res_dir = de;
return bh;
}
de++;
i++;
}
add_entry
static struct buffer_head * add_entry(struct m_inode * dir,
const char * name, int namelen, struct dir_entry ** res_dir)
该函数用于向指定的目录添加一个目录项。
刚开始定义了一些参数,并对一些参数的有效性进行了校验。 如果定义了宏NO_TRUNCATE, 如果长度超长,就直接返回NULL。如果没有定义该宏, 长度超长,则进行截断。
int block,i;
struct buffer_head * bh;
struct dir_entry * de;
*res_dir = NULL;
#ifdef NO_TRUNCATE
if (namelen > NAME_LEN)
return NULL;
#else
if (namelen > NAME_LEN)
namelen = NAME_LEN;
#endif
if (!namelen)
return NULL;
下面从读取i_zone[0]对应的磁盘块,其中存储了dir_entry。
if (!(block = dir->i_zone[0]))
return NULL;
if (!(bh = bread(dir->i_dev,block)))
return NULL;
i = 0;
de = (struct dir_entry *) bh->b_data;
接下来的过程便是遍历所有的目录项,从中找到空的目录项,用于创建新的目录项。
如果当前目录项的所有数据块都已经搜索完毕,但是还是没有找到需要的空目录,则会去下一个逻辑块中查找。如果下一个逻辑块不存在则会进行创建。
while (1) {
if ((char *)de >= BLOCK_SIZE+bh->b_data) {
brelse(bh);
bh = NULL;
block = create_block(dir,i/DIR_ENTRIES_PER_BLOCK);
if (!block)
return NULL;
if (!(bh = bread(dir->i_dev,block))) {
i += DIR_ENTRIES_PER_BLOCK;
continue;
}
de = (struct dir_entry *) bh->b_data;
}
if (i*sizeof(struct dir_entry) >= dir->i_size) {
de->inode=0;
dir->i_size = (i+1)*sizeof(struct dir_entry);
dir->i_dirt = 1;
dir->i_ctime = CURRENT_TIME;
}
if (!de->inode) {
dir->i_mtime = CURRENT_TIME;
for (i=0; i < NAME_LEN ; i++)
de->name[i]=(i<namelen)?get_fs_byte(name+i):0;
bh->b_dirt = 1;
*res_dir = de;
return bh;
}
de++;
i++;
}
brelse(bh);
return NULL;
get_dir
static struct m_inode * get_dir(const char * pathname)
该函数的作用是搜寻最下层的目录的inode号。 该函数将在dir_namei中被调用。
如果pathname是/home/work/test.txt,那么get_dir将返回/home/work目录的inode。
如果pathname是/home/work/test,那么get_dir将返回/home/work目录的inode。
如果pathname是/home/work/test/,那么get_dir将返回/home/work/test目录的inode。
程序的开始检测路径是绝对路径还是相对路径。绝对路径就从current->root开始寻找,相对路径就从current->pwd开始寻找。
char c;
const char * thisname;
struct m_inode * inode;
struct buffer_head * bh;
int namelen,inr,idev;
struct dir_entry * de;
if (!current->root || !current->root->i_count)//对current->root进行校验
panic("No root inode");
if (!current->pwd || !current->pwd->i_count)//对current->pwd进行校验
panic("No cwd inode");
if ((c=get_fs_byte(pathname))=='/') {// 起始字符是/,说明是绝对路径
inode = current->root;
pathname++;
} else if (c) //否则是相对路径
inode = current->pwd;
else
return NULL; /* empty name is bad */
inode->i_count++;
接下来进行循环,每次读取路径中的一个目录(文件)名。 因为路径名是以/进行分割的,因此可以将/作为标记进行寻找。当c=get_fs_byte(pathname++) = NULL时,寻找结束,代表已经到达了pathname字符串的末尾。
这里需要考虑目录名是其他文件系统的挂载节点的场景, 这个场景在iget函数内部会进行处理,即当一个目录是另一个文件系统的挂载节点的时候,就会去超级块中寻找真正的i节点。
while (1) {
thisname = pathname;
if (!S_ISDIR(inode->i_mode) || !permission(inode,MAY_EXEC)) {
iput(inode);
return NULL;
}
for(namelen=0;(c=get_fs_byte(pathname++))&&(c!='/');namelen++)
/* nothing */ ;
if (!c)
return inode;
if (!(bh = find_entry(&inode,thisname,namelen,&de))) {
iput(inode);
return NULL;
}
inr = de->inode;
idev = inode->i_dev;
brelse(bh);
iput(inode);
if (!(inode = iget(idev,inr)))
return NULL;
}
dir_namei
static struct m_inode * dir_namei(const char * pathname,
int * namelen, const char ** name)
该函数的作用是返回指定路径(pathname)所在目录的i节点, 并返回pathname路径最末端的文件名。
例如:pathname = /home/work/test.txt, dir_namei将返回目录/home/work的i节点,同时设置name = “test.txt”, namelen = 8。
char c;
const char * basename;
struct m_inode * dir;
if (!(dir = get_dir(pathname)))//调用get_dir函数获取靠近末端的上层目录的i节点
return NULL;
basename = pathname;
while ((c=get_fs_byte(pathname++)))
if (c=='/')
basename=pathname;
*namelen = pathname-basename-1; //获取路径中最右侧的文件名
*name = basename;
return dir;
namei
struct m_inode * namei(const char * pathname)
该函数的作用是根据路径名字获取文件的inode节点,是该文件中最重要的函数。namei综合运行了上面的dir_namei和find_entry函数。
const char * basename;
int inr,dev,namelen;
struct m_inode * dir;
struct buffer_head * bh;
struct dir_entry * de;
if (!(dir = dir_namei(pathname,&namelen,&basename)))//调用dir_namei获取上层目录的i节点和最右侧文件的名字。
return NULL;
if (!namelen) /* special case: '/usr/' etc */
return dir;
bh = find_entry(&dir,basename,namelen,&de);//获取文件的dir_entry项
if (!bh) {
iput(dir);
return NULL;
}
inr = de->inode;//从dir_entry中获取i节点编号
dev = dir->i_dev;//从目录的i节点中获取设备号
brelse(bh);
iput(dir);
dir=iget(dev,inr);//调用iget获取i节点
if (dir) {
dir->i_atime=CURRENT_TIME;
dir->i_dirt=1;
}
return dir;
open_namei
int open_namei(const char * pathname, int flag, int mode,
struct m_inode ** res_inode)
该函数作用是根据文件路径pathname打开一个文件,找到其inode。是open函数使用的namei函数。
函数的开始对文件的flag对一些检查,关于这些flag的含义可以参考 Q & A 2.open 文件时的一些flag的作用。
如果文件访问模式是只读, 但是文件截0标志O_TRUNC却置位了,则需要在文件打开标志中增加只写标志O_WRONLY,原因是截0操作必须要有文件可写。
const char * basename;
int inr,dev,namelen;
struct m_inode * dir, *inode;
struct buffer_head * bh;
struct dir_entry * de;
if ((flag & O_TRUNC) && !(flag & O_ACCMODE))
flag |= O_WRONLY; //增加可写的标记
mode &= 0777 & ~current->umask; //和进程的打开文件的掩码相与
mode |= I_REGULAR;//创建普通文件
接下来根据路径名寻找文件上层目录的i节点。需要处理路径为/usr/这种以/结尾的路径。
if (!(dir = dir_namei(pathname,&namelen,&basename)))
return -ENOENT;
if (!namelen) { /* special case: '/usr/' etc */
if (!(flag & (O_ACCMODE|O_CREAT|O_TRUNC))) { //如果路径是/usr/, 若操作不是读写,创建和文件长度截0,则表示是在打开一个目录名文件操作。
*res_inode=dir;
return 0;
}
iput(dir);
return -EISDIR;
}
下面使用find_entry查看要打开的文件是否已经存在。下面这段是文件不存在进行创建的逻辑。
bh = find_entry(&dir,basename,namelen,&de);//查找打开文件的dir_entry
if (!bh) { //不存在
if (!(flag & O_CREAT)) { //检查0_CREAT标记
iput(dir);
return -ENOENT;
}
if (!permission(dir,MAY_WRITE)) {//检查目录写权限
iput(dir);
return -EACCES;
}
inode = new_inode(dir->i_dev);
if (!inode) {
iput(dir);
return -ENOSPC;
}
inode->i_uid = current->euid;
inode->i_mode = mode;
inode->i_dirt = 1;
bh = add_entry(dir,basename,namelen,&de);//添加到目录中
if (!bh) {
inode->i_nlinks--;
iput(inode);
iput(dir);
return -ENOSPC;
}
de->inode = inode->i_num;
bh->b_dirt = 1;
brelse(bh);
iput(dir);
*res_inode = inode;
return 0;
}
下面这段逻辑要打开的文件已经存在的逻辑。通过iget返回文件的i节点。
inr = de->inode;
dev = dir->i_dev;
brelse(bh);
iput(dir);
if (flag & O_EXCL)
return -EEXIST;
if (!(inode=iget(dev,inr)))
return -EACCES;
if ((S_ISDIR(inode->i_mode) && (flag & O_ACCMODE)) ||
!permission(inode,ACC_MODE(flag))) {
iput(inode);
return -EPERM;
}
inode->i_atime = CURRENT_TIME;
if (flag & O_TRUNC) //如果设置了截0标记
truncate(inode); //调用truncate将文件长度截为0
*res_inode = inode;
return 0;
sys_mknod
int sys_mknod(const char * filename, int mode, int dev)
该函数的作用是创建一个设备特殊文件或者普通文件节点。
根据mode的值的不同会创建不同的节点,当mode为块设备或者是字符设备,则是创建一个设备i节点,除此以外,其他mode将会创建普通i节点。
设备节点和普通节点的区别可以参考Q&A 1.S_ISREG/S_ISDIR/S_ISCHR/S_ISBLK/S_ISFIFO 是如何判断文件类型的。
const char * basename;
int namelen;
struct m_inode * dir, * inode;
struct buffer_head * bh;
struct dir_entry * de;
if (!suser())//如果不是超级用户,返回出错
return -EPERM;
if (!(dir = dir_namei(filename,&namelen,&basename)))///获取上层的目录i节点
return -ENOENT;
if (!namelen) {
iput(dir);
return -ENOENT;
}
if (!permission(dir,MAY_WRITE)) {//检查是否有上层目录的写权限
iput(dir);
return -EPERM;
}
bh = find_entry(&dir,basename,namelen,&de);//检查是否已经存在
if (bh) {
brelse(bh);
iput(dir);
return -EEXIST;
}
inode = new_inode(dir->i_dev);//否则创建一个i节点
if (!inode) {
iput(dir);
return -ENOSPC;
}
inode->i_mode = mode;
if (S_ISBLK(mode) || S_ISCHR(mode))
inode->i_zone[0] = dev; //i_zone存放设备号
inode->i_mtime = inode->i_atime = CURRENT_TIME; //修改时间
inode->i_dirt = 1;//将该i节点标记为含有脏数据
bh = add_entry(dir,basename,namelen,&de);//添加到目录下
if (!bh) {
iput(dir);
inode->i_nlinks=0;
iput(inode);
return -ENOSPC;
}
de->inode = inode->i_num;//将dir_entry中的i节点序号指向inode->i_num
bh->b_dirt = 1;
iput(dir);
iput(inode);
brelse(bh);
return 0;
sys_mkdir
int sys_mkdir(const char * pathname, int mode)
该函数的作用是用于创建一个目录。
const char * basename;
int namelen;
struct m_inode * dir, * inode;
struct buffer_head * bh, *dir_block;
struct dir_entry * de;
if (!suser()) //如果不是超级用户,则返回权限问题。
return -EPERM;
if (!(dir = dir_namei(pathname,&namelen,&basename)))//获取该路径所在目录的i节点
return -ENOENT;
if (!namelen) {
iput(dir);
return -ENOENT;
}
if (!permission(dir,MAY_WRITE)) {//如果对该目录没有写权限
iput(dir);
return -EPERM;
}
bh = find_entry(&dir,basename,namelen,&de);//从该目录中
if (bh) {
brelse(bh);
iput(dir);
return -EEXIST;
}
inode = new_inode(dir->i_dev);//创建一个新的i节点
if (!inode) {
iput(dir);
return -ENOSPC;
}
inode->i_size = 32; //设置目录的大小,因为有两个默认的目录.和..
inode->i_dirt = 1;
inode->i_mtime = inode->i_atime = CURRENT_TIME;
if (!(inode->i_zone[0]=new_block(inode->i_dev))) {
iput(dir);
inode->i_nlinks--;
iput(inode);
return -ENOSPC;
}
inode->i_dirt = 1;
if (!(dir_block=bread(inode->i_dev,inode->i_zone[0]))) {
iput(dir);
free_block(inode->i_dev,inode->i_zone[0]);
inode->i_nlinks--;
iput(inode);
return -ERROR;
}
de = (struct dir_entry *) dir_block->b_data;
de->inode=inode->i_num;
strcpy(de->name,"."); //创建.目录项
de++;
de->inode = dir->i_num;
strcpy(de->name,".."); //创建..目录项
inode->i_nlinks = 2;
dir_block->b_dirt = 1;
brelse(dir_block);
inode->i_mode = I_DIRECTORY | (mode & 0777 & ~current->umask);
inode->i_dirt = 1;
bh = add_entry(dir,basename,namelen,&de);
if (!bh) {
iput(dir);
free_block(inode->i_dev,inode->i_zone[0]);
inode->i_nlinks=0;
iput(inode);
return -ENOSPC;
}
de->inode = inode->i_num;
bh->b_dirt = 1;
dir->i_nlinks++;//新建目录项会增加上层目录的链接数,与此对应的是删除目录的时候会减少上层目录的链接数
dir->i_dirt = 1;
iput(dir);
iput(inode);
brelse(bh);
return 0;
empty_dir
static int empty_dir(struct m_inode * inode)
该函数的作用是检查指定的目录是否为空。
int nr,block;
int len;
struct buffer_head * bh;
struct dir_entry * de;
len = inode->i_size / sizeof (struct dir_entry);
if (len<2 || !inode->i_zone[0] ||
!(bh=bread(inode->i_dev,inode->i_zone[0]))) { //如果当前目录的目录项小于两个, 获取i_zone[0]为空
printk("warning - bad directory on dev %04x\n",inode->i_dev);
return 0;
}
de = (struct dir_entry *) bh->b_data;
if (de[0].inode != inode->i_num || !de[1].inode ||
strcmp(".",de[0].name) || strcmp("..",de[1].name)) { //检查目录项是否是.或者..
printk("warning - bad directory on dev %04x\n",inode->i_dev);
return 0;
}
nr = 2;
de += 2;
while (nr<len) {
if ((void *) de >= (void *) (bh->b_data+BLOCK_SIZE)) { //循环检测剩下所有的目录项的指向的i节点值是否会等于0
brelse(bh);
block=bmap(inode,nr/DIR_ENTRIES_PER_BLOCK);
if (!block) {
nr += DIR_ENTRIES_PER_BLOCK;
continue;
}
if (!(bh=bread(inode->i_dev,block)))
return 0;
de = (struct dir_entry *) bh->b_data;
}
if (de->inode) {
brelse(bh);
return 0;
}
de++;
nr++;
}
brelse(bh);
return 1;
sys_rmdir
int sys_rmdir(const char * name)
该函数的作用是用于删除目录。
const char * basename;
int namelen;
struct m_inode * dir, * inode;
struct buffer_head * bh;
struct dir_entry * de;
if (!suser()) //如果不是超级用户,返回权限错误
return -EPERM;
if (!(dir = dir_namei(name,&namelen,&basename)))//获取路径的上一层目录的i节点
return -ENOENT;
if (!namelen) {
iput(dir);
return -ENOENT;
}
if (!permission(dir,MAY_WRITE)) {//检查是否有目录的写权限
iput(dir);
return -EPERM;
}
bh = find_entry(&dir,basename,namelen,&de);//查找目录项dir_entry项
if (!bh) {
iput(dir);
return -ENOENT;
}
if (!(inode = iget(dir->i_dev, de->inode))) {//获取目录项对应的i节点
iput(dir);
brelse(bh);
return -EPERM;
}
if ((dir->i_mode & S_ISVTX) && current->euid && //如果目录设置了SBIT, 如果当前有效用户不等于该i节点的用户,并且不是root用户,则无权进行删除
inode->i_uid != current->euid) {
iput(dir);
iput(inode);
brelse(bh);
return -EPERM;
}
if (inode->i_dev != dir->i_dev || inode->i_count>1) {
iput(dir);
iput(inode);
brelse(bh);
return -EPERM;
}
if (inode == dir) { //如果删除的是.目录
iput(inode);
iput(dir);
brelse(bh);
return -EPERM;
}
if (!S_ISDIR(inode->i_mode)) {//如果该i节点不是一个目录类型的i节点,则不能进行操作。
iput(inode); //放回i节点
iput(dir); //放回目录节点
brelse(bh); //释放高速缓冲块
return -ENOTDIR;
}
if (!empty_dir(inode)) { //如果被删除的目录不是一个空目录则不能进行删除
iput(inode); //放回i节点
iput(dir); //放回目录节点
brelse(bh); //释放高速缓冲块
return -ENOTEMPTY;
}
if (inode->i_nlinks != 2)
printk("empty directory has nlink!=2 (%d)",inode->i_nlinks);
de->inode = 0; //将目录项指向的i节点设置为0
bh->b_dirt = 1; //将bh块设置为有脏数据
brelse(bh); //释放该bh块
inode->i_nlinks=0; //将i节点的链接数设置为0
inode->i_dirt=1; //将i节点设置为有脏数据
dir->i_nlinks--; //减少目录节点的链接数
dir->i_ctime = dir->i_mtime = CURRENT_TIME; //修改目录i节点的修改时间
dir->i_dirt=1; //将目录i节点设置为有脏数据
iput(dir); //放回要删除的目录的上层目录的i节点
iput(inode); //放回要删除的目录的i节点
return 0;
sys_unlink
int sys_unlink(const char * name)
该函数的作用是用于删除文件的一个链接。
const char * basename;
int namelen;
struct m_inode * dir, * inode;
struct buffer_head * bh;
struct dir_entry * de;
if (!(dir = dir_namei(name,&namelen,&basename)))//获取文件所在目录的i节点
return -ENOENT;
if (!namelen) {//如果文件名长度为0
iput(dir);
return -ENOENT;
}
if (!permission(dir,MAY_WRITE)) {//检查是否有目录的写权限
iput(dir);
return -EPERM;
}
bh = find_entry(&dir,basename,namelen,&de);//查找该文件的dir_entry
if (!bh) {
iput(dir);
return -ENOENT;
}
if (!(inode = iget(dir->i_dev, de->inode))) {//获取该文件的i节点
iput(dir);
brelse(bh);
return -ENOENT;
}
if ((dir->i_mode & S_ISVTX) && !suser() &&
current->euid != inode->i_uid &&
current->euid != dir->i_uid) {//检查用户权限
iput(dir);
iput(inode);
brelse(bh);
return -EPERM;
}
if (S_ISDIR(inode->i_mode)) {//检查是否是目录
iput(inode);
iput(dir);
brelse(bh);
return -EPERM;
}
if (!inode->i_nlinks) {
printk("Deleting nonexistent file (%04x:%d), %d\n",
inode->i_dev,inode->i_num,inode->i_nlinks);
inode->i_nlinks=1;
}
de->inode = 0;//将dir_entry指向的inode设置为0
bh->b_dirt = 1;
brelse(bh);
inode->i_nlinks--;//将i节点中的i_nlinks减1
inode->i_dirt = 1;
inode->i_ctime = CURRENT_TIME;
iput(inode);
iput(dir);
return 0;
sys_link
int sys_link(const char * oldname, const char * newname)
该函数的作用是为一个已经存在文件设置一个硬链接。
struct dir_entry * de;
struct m_inode * oldinode, * dir;
struct buffer_head * bh;
const char * basename;
int namelen;
oldinode=namei(oldname);//获取已经存在的文件的i节点
if (!oldinode)//源文件的i节点不存在,则返回错误
return -ENOENT;
if (S_ISDIR(oldinode->i_mode)) {//如果源文件的是一个目录,则放回该i节点,返回错误
iput(oldinode);
return -EPERM;
}
dir = dir_namei(newname,&namelen,&basename);//获取新路径所在目录的i节点
if (!dir) { //如果新路径所在的目录不存哎,则返回错误
iput(oldinode);
return -EACCES;
}
if (!namelen) {
iput(oldinode);
iput(dir);
return -EPERM;
}
if (dir->i_dev != oldinode->i_dev) {//硬链接不能跨越文件系统,因为每个文件系统的都有各自的i节点序号
iput(dir);
iput(oldinode);
return -EXDEV;
}
if (!permission(dir,MAY_WRITE)) {//检查是否对新的目录具有写权限
iput(dir);
iput(oldinode);
return -EACCES;
}
bh = find_entry(&dir,basename,namelen,&de);//检查新的路径是否已经存在,如果已经存在则也不能进行创建
if (bh) {
brelse(bh);
iput(dir);
iput(oldinode);
return -EEXIST;
}
bh = add_entry(dir,basename,namelen,&de);//在该目录下创建一个新的entry,entry的名字是basename
if (!bh) {
iput(dir);
iput(oldinode);
return -ENOSPC;
}
de->inode = oldinode->i_num;//将该entry指向源文件所在的i节点
bh->b_dirt = 1;//设置该目录i节点上存在脏数据
brelse(bh);
iput(dir);
oldinode->i_nlinks++;//将旧的i节点的硬链接数+1
oldinode->i_ctime = CURRENT_TIME;
oldinode->i_dirt = 1;
iput(oldinode);
return 0;
Q & A
1.S_ISREG/S_ISDIR/S_ISCHR/S_ISBLK/S_ISFIFO 是如何判断文件类型的?
这里需要再次重温一下i节点的i_mode的格式, 如下图所示,其中最高的四个bit位代表文件的类型:
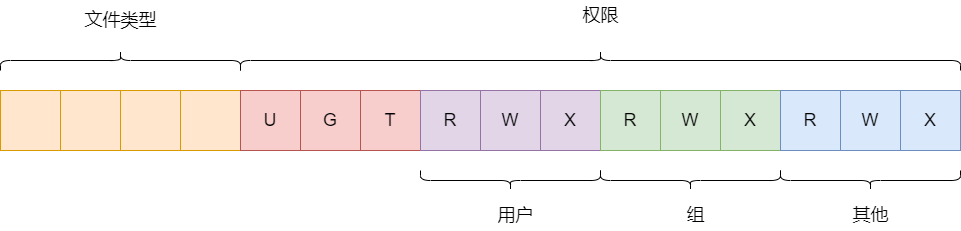
这四个位所表示的文件类型可以参考下面这张表:
| bit值 | 含义 |
|---|---|
| 1 0 0 0 | 普通文件 |
| 0 1 0 0 | 目录文件 |
| 0 0 1 0 | 字符设备文件 |
| 0 1 1 0 | 块设备文件 |
| 0 0 0 1 | 管道文件 |
2.open 文件时的一些flag的作用
O_TRUNC标志:
使用这个标志,在调用open函数打开文件的时候会将文件原本内容全部丢弃,文件大小变为0;
3.Linux的特殊权限位
对于一个文件的i节点,其9-11位是3个特殊权限位,SUID,SGID,SBIT。SUID和SGID用于执行时进行提权。
对于SUID:
- SUID 权限仅对二进制可执行文件有效
- 如果执行者对于该二进制可执行文件具有 x 的权限,执行者将具有该文件的所有者的权限
- 本权限仅在执行该二进制可执行文件的过程中有效
提权过程对二进制文件有效, 对于shell等脚本文件可能不生效。
对于SGUID:
当 SGID 作用于普通文件时,和 SUID 类似,在执行该文件时,用户将获得该文件所属组的权限。
当 SGID 作用于目录时,意义就非常重大了。当用户对某一目录有写和执行权限时,该用户就可以在该目录下建立文件,如果该目录用 SGID 修饰,则该用户在这个目录下建立的文件都是属于这个目录所属的组。
对于SBIT:
SBIT 与 SUID 和 SGID 的关系并不大。
SBIT 是 the restricted deletion flag or sticky bit 的简称。
SBIT 目前只对目录有效,用来阻止非文件的所有者删除文件。比较常见的例子就是 /tmp 目录,
[xu@localhost shell_proj]$ ls / -al |grep tmp
drwxrwxrwt. 23 root root 4096 Apr 20 22:50 tmp
权限信息中最后一位 t 表明该目录被设置了 SBIT 权限。SBIT 对目录的作用是:当用户在该目录下创建新文件或目录时,仅有自己和 root 才有权力删除。