PyTorch深度学习框架60天进阶学习计划 - 第37天:元学习框架
嘿,朋友们!欢迎来到我们PyTorch进阶之旅的第37天。今天我们将深入探索一个非常有趣且强大的领域——元学习(Meta-Learning),也被称为"学会学习"(Learning to Learn)。
元学习就像是给AI装上了"学习开关",让它能够从过去的学习经验中获取知识,并应用到新任务上。这就好比一个聪明的学生不仅记住了知识点,还掌握了高效学习的技巧!我们今天将重点推导Model-Agnostic Meta-Learning (MAML)的参数更新公式,并分析原型网络(Prototypical Networks)如何在少样本学习中构建度量空间。
一、元学习基础概念
1.1 什么是元学习?
元学习旨在开发能够通过经验快速适应新任务的算法。传统机器学习针对特定任务优化模型,而元学习则寻求优化学习过程本身。
| 传统学习 | 元学习 |
|---|---|
| 针对单一任务训练 | 在多个相关任务上训练 |
| 需要大量标注数据 | 能够从少量样本中学习(少样本学习) |
| 固定的学习过程 | 能够调整学习策略 |
| 新任务需要重新训练 | 可以快速适应新任务 |
1.2 元学习的典型场景
元学习特别适用于以下场景:
- 少样本学习(Few-shot Learning):只有极少的标注样本可用
- 快速适应(Rapid Adaptation):需要快速适应新环境或任务
- 持续学习(Continual Learning):在不遗忘旧知识的前提下学习新知识
- 迁移学习(Transfer Learning):将知识从源域迁移到目标域
1.3 元学习的常见框架
目前元学习主要有三类主流方法:
| 类别 | 代表算法 | 核心思想 |
|---|---|---|
| 基于优化的方法 | MAML, Reptile | 学习一个对新任务易于快速适应的模型初始化 |
| 基于度量的方法 | 原型网络, 匹配网络 | 学习一个度量空间,使相似样本在空间中距离更近 |
| 基于记忆的方法 | MANN, SNAIL | 使用外部记忆存储过去的经验,以辅助新任务的学习 |
二、Model-Agnostic Meta-Learning (MAML)
2.1 MAML的核心思想
MAML是一种广泛应用的元学习算法,由Chelsea Finn等人在2017年提出。其核心思想是:找到一个模型参数的初始值,使得对于新任务,只需少量梯度更新步骤就能获得好的性能。
MAML的优势在于其模型无关性(Model-Agnostic),几乎可以应用于任何使用梯度下降优化的模型,包括分类、回归和强化学习等任务。
2.2 MAML算法流程
MAML的元学习过程包括两个关键步骤:
- 内循环(Inner Loop):针对特定任务进行快速适应
- 外循环(Outer Loop):跨多个任务更新模型参数
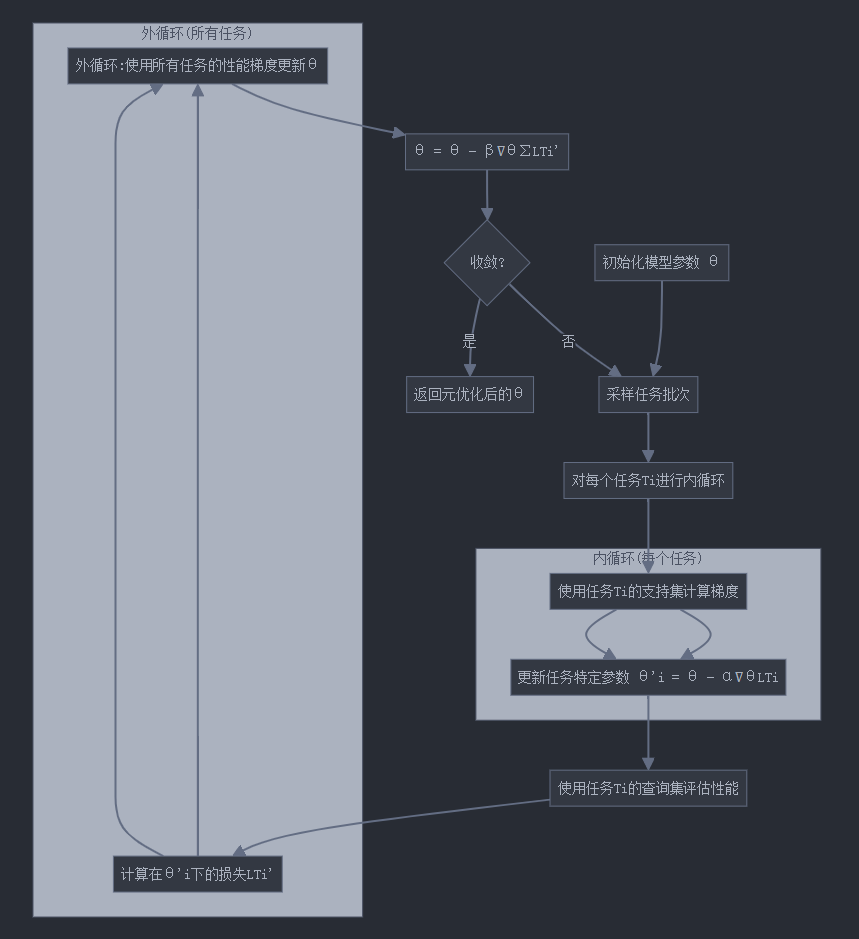
2.3 MAML参数更新公式推导
现在,让我们深入推导MAML的参数更新公式,这是理解其工作原理的关键。
假设:
- θ 表示模型的初始参数
- Ti 表示第i个任务
- DTi^{support} 和 DTi^{query} 分别是任务Ti的支持集和查询集
- LTi 表示任务Ti的损失函数
- α 是内循环学习率
- β 是外循环学习率
步骤1:内循环更新(任务适应)
对于每个任务Ti,我们使用其支持集数据进行一步或多步梯度更新:
单步更新情况:
θ'i = θ - α∇θLTi(θ, DTi^{support})
这里,θ’i是适应了任务Ti后的参数。
步骤2:外循环更新(元优化)
外循环的目标是最小化所有任务在适应后参数上的损失总和:
min_θ Σ_i LTi(θ'i, DTi^{query})
使用梯度下降更新θ:
θ = θ - β∇θ Σ_i LTi(θ'i, DTi^{query})
关键挑战:计算二阶导数
外循环梯度 ∇θ LTi(θ’i, DTi^{query}) 是一个二阶导数,因为θ’i本身就是θ的函数。
我们可以通过链式法则展开:
∇θ LTi(θ'i, DTi^{query}) = ∇θ'i LTi(θ'i, DTi^{query}) · ∇θ θ'i
根据内循环更新公式,我们有:
∇θ θ'i = ∇θ (θ - α∇θLTi(θ, DTi^{support}))
= I - α∇²θLTi(θ, DTi^{support})
其中I是单位矩阵,∇²θ表示Hessian矩阵。
完整的外循环梯度为:
∇θ LTi(θ'i, DTi^{query}) = ∇θ'i LTi(θ'i, DTi^{query}) · (I - α∇²θLTi(θ, DTi^{support}))
这个公式涉及二阶导数,计算成本较高。在实践中,MAML通常使用自动微分工具(如PyTorch的autograd)或一阶近似(如Reptile算法)来简化计算。
2.4 MAML的PyTorch实现
以下是MAML算法在PyTorch中的基本实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
from copy import deepcopy
class SimpleNet(nn.Module):
"""用于演示MAML的简单神经网络"""
def __init__(self, input_dim=1, hidden_dim=40, output_dim=1):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.fc3(x)
class TaskGenerator:
"""生成回归任务:f(x) = a*sin(x + b),其中a和b是随机参数"""
def __init__(self, num_samples=10, input_dim=1, output_dim=1):
self.num_samples = num_samples
self.input_dim = input_dim
self.output_dim = output_dim
def sample_task(self):
"""采样一个新任务(回归函数)"""
a = np.random.uniform(0.1, 5.0)
b = np.random.uniform(0, 2 * np.pi)
def task_fn(x):
return a * np.sin(x + b)
return task_fn
def sample_data(self, task_fn, num_samples=None, noise_std=0.1):
"""采样任务的输入和输出数据"""
if num_samples is None:
num_samples = self.num_samples
x = np.random.uniform(-5, 5, size=(num_samples, self.input_dim))
y = task_fn(x) + np.random.normal(0, noise_std, size=(num_samples, self.output_dim))
return torch.FloatTensor(x), torch.FloatTensor(y)
class MAML:
"""Model-Agnostic Meta-Learning (MAML)的实现"""
def __init__(self, model, inner_lr=0.01, outer_lr=0.001, num_inner_steps=1):
self.model = model
self.inner_lr = inner_lr
self.meta_optimizer = optim.Adam(model.parameters(), lr=outer_lr)
self.num_inner_steps = num_inner_steps
self.criterion = nn.MSELoss()
def inner_loop(self, support_x, support_y, create_graph=False):
"""内循环:任务适应阶段"""
# 创建模型副本进行局部更新
local_model = deepcopy(self.model)
local_optim = optim.SGD(local_model.parameters(), lr=self.inner_lr)
for _ in range(self.num_inner_steps):
# 前向传播
support_pred = local_model(support_x)
support_loss = self.criterion(support_pred, support_y)
# 反向传播
local_optim.zero_grad()
support_loss.backward(create_graph=create_graph, retain_graph=True)
local_optim.step()
return local_model
def outer_loop(self, tasks, num_inner_steps=None):
"""外循环:元优化阶段"""
if num_inner_steps is not None:
self.num_inner_steps = num_inner_steps
self.meta_optimizer.zero_grad()
meta_loss = 0.0
for support_x, support_y, query_x, query_y in tasks:
# 内循环更新得到任务特定的模型
local_model = self.inner_loop(support_x, support_y, create_graph=True)
# 在查询集上评估适应后的模型
query_pred = local_model(query_x)
query_loss = self.criterion(query_pred, query_y)
# 累计元损失
meta_loss += query_loss
# 更新元模型参数
meta_loss /= len(tasks)
meta_loss.backward()
self.meta_optimizer.step()
return meta_loss.item()
def meta_train(self, task_generator, num_episodes=1000, tasks_per_episode=5,
support_samples=10, query_samples=10, verbose=True):
"""元训练循环"""
losses = []
for episode in range(num_episodes):
tasks = []
# 采样任务批次
for _ in range(tasks_per_episode):
task_fn = task_generator.sample_task()
# 生成支持集和查询集
support_x, support_y = task_generator.sample_data(task_fn, support_samples)
query_x, query_y = task_generator.sample_data(task_fn, query_samples)
tasks.append((support_x, support_y, query_x, query_y))
# 执行元更新
meta_loss = self.outer_loop(tasks)
losses.append(meta_loss)
if verbose and (episode + 1) % 100 == 0:
avg_loss = np.mean(losses[-100:])
print(f"Episode {episode+1}/{num_episodes} - Meta Loss: {avg_loss:.6f}")
return losses
def meta_test(self, task_generator, num_tasks=10, support_samples=10, query_samples=50,
adaptation_steps=10):
"""在新任务上测试元训练模型"""
test_losses = []
baseline_losses = []
for task_idx in range(num_tasks):
# 采样新任务
task_fn = task_generator.sample_task()
support_x, support_y = task_generator.sample_data(task_fn, support_samples)
query_x, query_y = task_generator.sample_data(task_fn, query_samples)
# 基线:未经适应的模型性能
with torch.no_grad():
baseline_pred = self.model(query_x)
baseline_loss = self.criterion(baseline_pred, query_y).item()
baseline_losses.append(baseline_loss)
# 应用内循环适应新任务
adapted_model = self.inner_loop(support_x, support_y, create_graph=False)
# 在查询集上评估适应后的模型
with torch.no_grad():
adapted_pred = adapted_model(query_x)
adapted_loss = self.criterion(adapted_pred, query_y).item()
test_losses.append(adapted_loss)
print(f"Task {task_idx+1} - Baseline Loss: {baseline_loss:.6f}, "
f"Adapted Loss: {adapted_loss:.6f}")
avg_baseline = np.mean(baseline_losses)
avg_adapted = np.mean(test_losses)
print(f"Average - Baseline Loss: {avg_baseline:.6f}, Adapted Loss: {avg_adapted:.6f}")
return baseline_losses, test_losses
# 使用示例
def run_maml_example():
"""运行MAML示例,处理简单的正弦波回归任务"""
# 创建模型和任务生成器
model = SimpleNet(input_dim=1, hidden_dim=40, output_dim=1)
task_generator = TaskGenerator(num_samples=10)
# 初始化MAML
maml = MAML(model, inner_lr=0.01, outer_lr=0.001, num_inner_steps=1)
# 元训练
print("Starting meta-training...")
losses = maml.meta_train(task_generator, num_episodes=1000, tasks_per_episode=5,
support_samples=10, query_samples=10)
# 元测试
print("\nStarting meta-testing...")
baseline_losses, adapted_losses = maml.meta_test(task_generator, num_tasks=10,
support_samples=10, query_samples=50)
# 可视化一个测试任务的结果
import matplotlib.pyplot as plt
task_fn = task_generator.sample_task()
support_x, support_y = task_generator.sample_data(task_fn, 10)
test_x = torch.linspace(-6, 6, 100).reshape(-1, 1)
# 获取真实函数值
with torch.no_grad():
true_y = task_fn(test_x.numpy())
# 获取未适应的预测
baseline_pred = model(test_x)
# 获取适应后的预测
adapted_model = maml.inner_loop(support_x, support_y)
adapted_pred = adapted_model(test_x)
plt.figure(figsize=(10, 6))
plt.plot(test_x.numpy(), true_y, 'k-', label='True Function')
plt.plot(test_x.numpy(), baseline_pred.numpy(), 'b--', label='Pre-Adaptation')
plt.plot(test_x.numpy(), adapted_pred.numpy(), 'r-', label='Post-Adaptation')
plt.scatter(support_x.numpy(), support_y.numpy(), c='g', s=50, label='Support Set')
plt.legend()
plt.title('MAML: Pre vs Post Adaptation')
plt.xlabel('x')
plt.ylabel('y')
plt.tight_layout()
plt.grid(True)
plt.savefig('maml_adaptation.png')
plt.show()
return maml, losses
if __name__ == "__main__":
maml, losses = run_maml_example()
2.5 MAML优缺点分析
MAML作为一种元学习算法,具有以下优缺点:
优点:
- 模型无关性:可应用于任何使用梯度下降优化的模型
- 高效适应:只需少量梯度步骤就能适应新任务
- 理论基础:有严格的理论保证和收敛性分析
- 通用性:适用于分类、回归、强化学习等多种任务
缺点:
- 二阶导数计算:需要计算Hessian矩阵,计算开销大
- 超参数敏感:对内外循环学习率等超参数较为敏感
- 优化不稳定:由于元优化的复杂性,训练可能不稳定
- 记忆消耗:需要存储每个任务的计算图,内存开销大
三、原型网络(Prototypical Networks)
3.1 原型网络的核心思想
原型网络是一种基于度量的元学习方法,由Snell等人在2017年提出。其核心思想是:在嵌入空间中为每个类别学习一个原型表示,新样本的分类基于其与这些原型的距离。
原型网络特别适合少样本分类任务(Few-shot Classification),例如N-way K-shot分类,其中N是类别数,K是每类的样本数。
3.2 原型网络的数学表示
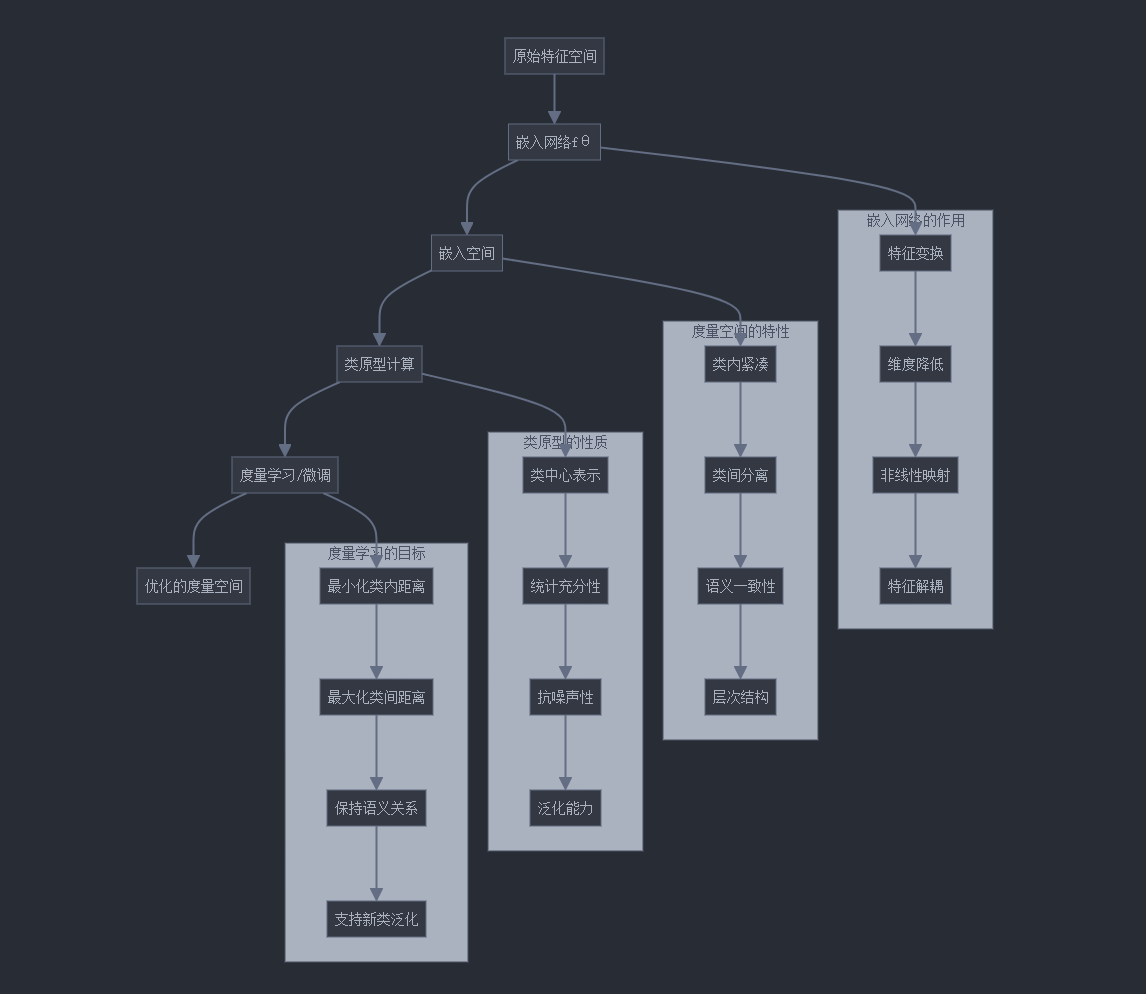
假设我们有一个嵌入函数fθ,将输入x映射到d维嵌入空间。对于每个类别k,其原型ck是该类所有支持样本嵌入的平均值:
ck = (1/|Sk|) * Σ_{x_i ∈ Sk} fθ(x_i)
其中Sk是类别k的支持集。
给定一个查询样本x,它被分配给与其嵌入最接近的原型所代表的类:
p(y = k | x) = softmax(-d(fθ(x), ck))
其中d是距离函数,通常使用欧氏距离。
3.3 原型网络的度量空间构建
原型网络的核心在于构建一个有效的度量空间,使得同类样本聚集,不同类样本分离。这种度量空间需要满足以下特性:
- 类内紧凑性:同一类的样本在嵌入空间中应该紧密聚集
- 类间分离性:不同类的样本在嵌入空间中应该明显分离
- 泛化能力:能够处理未见过的类别
- 维度降低:通常嵌入空间的维度低于原始特征空间
度量空间的构建主要通过嵌入网络fθ完成,该网络将输入映射到嵌入空间。网络的训练目标是最小化基于原型的分类损失。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
from torchvision import transforms
from sklearn.manifold import TSNE
class EmbeddingNet(nn.Module):
"""嵌入网络,将输入映射到嵌入空间"""
def __init__(self, input_dim=28*28, hidden_dim=64, output_dim=64):
super(EmbeddingNet, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = x.view(x.size(0), -1) # 展平输入
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
class PrototypicalNetwork(nn.Module):
"""原型网络实现"""
def __init__(self, embedding_network):
super(PrototypicalNetwork, self).__init__()
self.embedding_network = embedding_network
def forward(self, support_images, support_labels, query_images):
"""
支持集和查询集的前向传播
参数:
support_images: 支持集图像 [n_support, channels, height, width]
support_labels: 支持集标签 [n_support]
query_images: 查询集图像 [n_query, channels, height, width]
返回:
查询集样本属于每个类别的概率 [n_query, n_classes]
"""
# 嵌入支持集和查询集
support_embeddings = self.embedding_network(support_images)
query_embeddings = self.embedding_network(query_images)
# 获取唯一类别
unique_classes = torch.unique(support_labels)
n_classes = len(unique_classes)
# 计算类原型
prototypes = torch.zeros(n_classes, support_embeddings.size(1))
for i, c in enumerate(unique_classes):
# 选择属于该类的支持样本
mask = support_labels == c
# 计算该类的原型(均值)
prototypes[i] = support_embeddings[mask].mean(0)
# 计算查询样本到各原型的距离
# 使用欧氏距离的平方
dists = torch.cdist(query_embeddings, prototypes, p=2)**2
# 将距离转换为概率(使用负距离的softmax)
log_p_y = F.log_softmax(-dists, dim=1)
return log_p_y, prototypes
def compute_prototypes(self, support_images, support_labels):
"""仅计算原型,用于可视化"""
# 嵌入支持集
support_embeddings = self.embedding_network(support_images)
# 获取唯一类别
unique_classes = torch.unique(support_labels)
n_classes = len(unique_classes)
# 计算类原型
prototypes = torch.zeros(n_classes, support_embeddings.size(1))
for i, c in enumerate(unique_classes):
mask = support_labels == c
prototypes[i] = support_embeddings[mask].mean(0)
return prototypes, support_embeddings, unique_classes
class EpisodicDataset(Dataset):
"""生成少样本学习的任务(episodes)"""
def __init__(self, images, labels, n_classes=5, n_support=5, n_query=15):
self.images = images
self.labels = labels
self.n_classes = n_classes # 每个任务的类别数(N-way)
self.n_support = n_support # 每类支持样本数(K-shot)
self.n_query = n_query # 每类查询样本数
# 按类别组织数据
self.data_by_class = {}
unique_labels = torch.unique(self.labels)
for c in unique_labels:
idx = (self.labels == c).nonzero().squeeze()
self.data_by_class[c.item()] = idx
def __len__(self):
return 1000 # 可以设置为任意期望的任务数
def __getitem__(self, idx):
"""采样一个N-way K-shot任务"""
# 随机选择N个类别
classes = torch.tensor(np.random.choice(
list(self.data_by_class.keys()),
self.n_classes,
replace=False
))
support_images = []
support_labels = []
query_images = []
query_labels = []
for i, c in enumerate(classes):
# 获取该类的所有样本索引
idx = self.data_by_class[c.item()]
# 随机选择K个支持样本和n_query个查询样本
perm = torch.randperm(len(idx))
support_idx = idx[perm[:self.n_support]]
query_idx = idx[perm[self.n_support:self.n_support+self.n_query]]
# 收集支持集样本
support_images.append(self.images[support_idx])
support_labels.append(torch.full((self.n_support,), i))
# 收集查询集样本
query_images.append(self.images[query_idx])
query_labels.append(torch.full((self.n_query,), i))
# 合并所有类别的样本
support_images = torch.cat(support_images)
support_labels = torch.cat(support_labels)
query_images = torch.cat(query_images)
query_labels = torch.cat(query_labels)
return support_images, support_labels, query_images, query_labels
def train_prototypical_network(model, train_loader, optimizer, epochs=10, device='cpu'):
"""训练原型网络"""
model.train()
losses = []
accuracies = []
for epoch in range(epochs):
epoch_loss = 0
epoch_acc = 0
n_batches = 0
for support_images, support_labels, query_images, query_labels in train_loader:
# 移动数据到设备
support_images = support_images.to(device)
support_labels = support_labels.to(device)
query_images = query_images.to(device)
query_labels = query_labels.to(device)
# 前向传播
log_p_y, _ = model(support_images, support_labels, query_images)
# 计算损失和准确率
loss = F.nll_loss(log_p_y, query_labels)
acc = torch.mean((torch.argmax(log_p_y, dim=1) == query_labels).float())
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
n_batches += 1
# 计算每个epoch的平均损失和准确率
epoch_loss /= n_batches
epoch_acc /= n_batches
losses.append(epoch_loss)
accuracies.append(epoch_acc)
print(f"Epoch {epoch+1}/{epochs} - Loss: {epoch_loss:.4f}, Accuracy: {epoch_acc:.4f}")
return losses, accuracies
def test_prototypical_network(model, test_loader, device='cpu'):
"""测试原型网络"""
model.eval()
test_loss = 0
test_acc = 0
n_batches = 0
with torch.no_grad():
for support_images, support_labels, query_images, query_labels in test_loader:
# 移动数据到设备
support_images = support_images.to(device)
support_labels = support_labels.to(device)
query_images = query_images.to(device)
query_labels = query_labels.to(device)
# 前向传播
log_p_y, _ = model(support_images, support_labels, query_images)
# 计算损失和准确率
loss = F.nll_loss(log_p_y, query_labels)
acc = torch.mean((torch.argmax(log_p_y, dim=1) == query_labels).float())
test_loss += loss.item()
test_acc += acc.item()
n_batches += 1
# 计算平均损失和准确率
test_loss /= n_batches
test_acc /= n_batches
print(f"Test - Loss: {test_loss:.4f}, Accuracy: {test_acc:.4f}")
return test_loss, test_acc
def visualize_embeddings(model, images, labels, device='cpu'):
"""可视化嵌入空间"""
model.eval()
with torch.no_grad():
# 计算所有样本的嵌入
embeddings = model.embedding_network(images.to(device))
# 使用t-SNE降维到2维,便于可视化
tsne = TSNE(n_components=2, random_state=42)
embeddings_2d = tsne.fit_transform(embeddings.cpu().numpy())
# 可视化
plt.figure(figsize=(10, 8))
unique_labels = torch.unique(labels)
for i, c in enumerate(unique_labels):
idx = (labels == c).nonzero().squeeze()
plt.scatter(
embeddings_2d[idx, 0],
embeddings_2d[idx, 1],
label=f'Class {c.item()}'
)
plt.legend()
plt.title('t-SNE Visualization of Embeddings')
plt.savefig('embeddings_visualization.png')
plt.show()
def visualize_prototypes(model, support_images, support_labels,
query_images=None, query_labels=None, device='cpu'):
"""可视化原型和样本在嵌入空间中的分布"""
model.eval()
with torch.no_grad():
# 计算原型和支持样本的嵌入
prototypes, support_embeddings, classes = model.compute_prototypes(
support_images.to(device),
support_labels.to(device)
)
# 合并所有嵌入
all_embeddings = [support_embeddings.cpu()]
all_labels = [support_labels]
point_types = ['support'] * len(support_labels)
# 如果有查询样本,也计算它们的嵌入
if query_images is not None and query_labels is not None:
query_embeddings = model.embedding_network(query_images.to(device))
all_embeddings.append(query_embeddings.cpu())
all_labels.append(query_labels)
point_types.extend(['query'] * len(query_labels))
# 添加原型
prototype_labels = torch.arange(len(classes))
all_embeddings.append(prototypes.cpu())
all_labels.append(prototype_labels)
point_types.extend(['prototype'] * len(prototype_labels))
# 合并
all_embeddings = torch.cat(all_embeddings)
all_labels = torch.cat(all_labels)
# 使用t-SNE降维
tsne = TSNE(n_components=2, random_state=42)
embeddings_2d = tsne.fit_transform(all_embeddings.numpy())
# 可视化
plt.figure(figsize=(12, 10))
# 绘制支持样本和查询样本
for i, c in enumerate(classes):
# 支持样本
mask_support = (all_labels == i) & (np.array(point_types) == 'support')
plt.scatter(
embeddings_2d[mask_support, 0],
embeddings_2d[mask_support, 1],
alpha=0.6,
marker='o',
label=f'Support Class {c.item()}'
)
# 查询样本
if query_images is not None:
mask_query = (all_labels == i) & (np.array(point_types) == 'query')
plt.scatter(
embeddings_2d[mask_query, 0],
embeddings_2d[mask_query, 1],
alpha=0.6,
marker='x',
label=f'Query Class {c.item()}'
)
# 绘制原型(大号标记)
mask_proto = np.array(point_types) == 'prototype'
plt.scatter(
embeddings_2d[mask_proto, 0],
embeddings_2d[mask_proto, 1],
s=200,
marker='*',
c='black',
label='Prototypes'
)
plt.legend()
plt.title('Embedding Space with Prototypes')
plt.savefig('prototype_visualization.png')
plt.show()
# 示例:在简单数据集上运行原型网络
def run_prototypical_example():
"""运行原型网络示例"""
# 设置随机种子
torch.manual_seed(42)
np.random.seed(42)
# 检查是否有GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}")
# 生成玩具数据集
# 为简单起见,我们创建一个简单的合成数据集
def generate_toy_dataset(n_classes=10, n_samples_per_class=100, dim=2):
"""生成简单的玩具数据集,每个类是一个高斯分布"""
images = []
labels = []
for i in range(n_classes):
# 为每个类生成一个中心点
center = np.random.randn(dim) * 5
# 生成围绕该中心的样本
class_samples = center + np.random.randn(n_samples_per_class, dim)
images.append(class_samples)
labels.append(np.full(n_samples_per_class, i))
# 合并所有类的样本
images = np.vstack(images).astype(np.float32)
labels = np.hstack(labels).astype(np.int64)
return torch.from_numpy(images), torch.from_numpy(labels)
# 生成数据集
images, labels = generate_toy_dataset(n_classes=10, n_samples_per_class=100, dim=64)
# 创建任务数据集
train_dataset = EpisodicDataset(
images, labels,
n_classes=5, # 5-way
n_support=5, # 5-shot
n_query=15 # 每类15个查询样本
)
# 创建数据加载器
train_loader = DataLoader(
train_dataset,
batch_size=4, # 每批处理4个任务
shuffle=True
)
# 创建测试任务数据集
test_dataset = EpisodicDataset(
images, labels,
n_classes=5,
n_support=5,
n_query=15
)
test_loader = DataLoader(
test_dataset,
batch_size=4,
shuffle=False
)
# 创建嵌入网络和原型网络
embedding_net = EmbeddingNet(input_dim=64, hidden_dim=128, output_dim=64)
model = PrototypicalNetwork(embedding_net).to(device)
# 创建优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
print("Starting training...")
losses, accuracies = train_prototypical_network(
model, train_loader, optimizer,
epochs=10, device=device
)
# 测试模型
print("\nStarting testing...")
test_loss, test_acc = test_prototypical_network(
model, test_loader, device=device
)
# 可视化嵌入空间
print("\nVisualizing embeddings...")
# 为可视化选择一批样本
support_images, support_labels, query_images, query_labels = next(iter(test_loader))
visualize_prototypes(
model, support_images, support_labels,
query_images, query_labels, device=device
)
return model, losses, accuracies
if __name__ == "__main__":
model, losses, accuracies = run_prototypical_example()
3.4 原型网络度量空间分析
原型网络的度量空间构建涉及多个关键方面,现在让我们深入分析:
1. 嵌入函数的选择
嵌入函数fθ将输入从原始特征空间映射到嵌入空间。这个函数可以是任何神经网络架构,例如:
- 对于图像:CNN或ResNet
- 对于文本:RNN或Transformer
- 对于结构化数据:MLP
嵌入函数的容量(capacity)需要平衡:太简单可能无法捕捉复杂模式,太复杂可能会过拟合。
2. 度量空间的几何特性
原型网络中的度量空间呈现出以下几何特性:
- 星形拓扑:每个类形成一个星形结构,原型位于中心,样本围绕其分布
- 类内变异性:同一类内样本的分散程度反映该类的内部变异
- 原型间距离:反映类别之间的相似性,距离越远表示类别差异越大
- 嵌入空间维数:影响表达能力和泛化性,较高维度可捕捉更复杂关系,但也可能导致过拟合
3. 距离函数选择
距离函数的选择对度量空间的形状有重要影响:
| 距离函数 | 数学表达式 | 特点 | 适用场景 |
|---|---|---|---|
| 欧氏距离 | √(Σ(ai-bi)²) | 保持几何直觉,对尺度敏感 | 特征经过标准化的情况 |
| 曼哈顿距离 | Σ|ai-bi| | 对异常值不太敏感 | 特征有离散属性时 |
| 余弦相似度 | cos(θ) | 只关注方向而非大小 | 文本或高维稀疏特征 |
| 马氏距离 | √((a-b)ᵀS⁻¹(a-b)) | 考虑特征相关性 | 特征相关且分布已知 |
原型网络通常使用欧氏距离,这意味着嵌入空间中的等距离轮廓是圆形的。
4. 类原型的计算方式
在标准原型网络中,原型是支持集样本嵌入的算术平均值。这隐含了假设:样本在嵌入空间中服从对称分布(如高斯分布)。
其他可能的原型计算方式包括:
- 加权平均:基于样本质量或置信度加权
- 中位数:对异常值更鲁棒
- 元学习原型:学习一个从支持集到原型的映射函数
5. 原型网络的归纳偏置
原型网络具有以下归纳偏置(inductive biases):
- 局部性:假设相似样本在嵌入空间中靠近
- 线性可分性:假设类别在嵌入空间中线性可分
- 多模态限制:标准原型表示难以捕捉多模态类分布
- 测度学习:学习将输入空间转换为更有意义的度量空间
3.5 原型网络的扩展和变体
原型网络有多种扩展,用以解决标准原型网络的各种局限性:
- Relation Network:用神经网络替代欧氏距离,学习更复杂的关系度量
- Infinite Mixture Prototypes:用混合模型表示类别,处理多模态分布
- ProtoMAML:结合原型网络和MAML的优点
- Prototypical Networks with Attention:加入注意力机制,更好地处理背景干扰
- Semi-Prototypical Networks:利用未标记数据改进原型学习
四、MAML与原型网络的对比分析
现在让我们对比MAML和原型网络这两种主流元学习方法的异同:
| 方面 | MAML | 原型网络 |
|---|---|---|
| 基本思想 | 学习易于适应的参数初始化 | 学习有效的度量空间和类原型 |
| 元学习范式 | 基于优化 | 基于度量 |
| 计算复杂度 | 较高(二阶导数计算) | 较低(前向传播计算) |
| 内存需求 | 较高(需存储计算图) | 较低 |
| 适应新任务方式 | 梯度下降更新 | 计算新类原型 |
| 适应速度 | 需要多步梯度更新 | 一次计算即可(无需迭代) |
| 模型无关性 | 高(适用于各种模型) | 中(依赖于嵌入函数) |
| 任务类型 | 分类、回归、强化学习等 | 主要用于分类任务 |
| 泛化到不同任务 | 更灵活 | 主要适合相似任务 |
4.1 理论角度分析
从理论角度比较,这两种方法代表了元学习的不同方向:
MAML:表示"元学习如何学习",关注的是学习过程本身,寻找一个好的学习起点和学习策略。可以被视为参数空间中的寻找"中心点",从该点出发可以快速到达不同任务的最优点。
原型网络:表示"元学习如何表示",关注的是数据的表示方式,寻找一个好的特征空间。可以被视为学习一个度量空间,使得基于距离的分类在该空间中效果最佳。
4.2 应用场景选择
根据应用需求选择合适的元学习方法:
-
选择MAML的场景:
- 任务之间存在显著差异
- 模型需要对新任务进行精细调整
- 任务类型多样(分类、回归、强化学习等)
- 计算资源充足
-
选择原型网络的场景:
- 任务之间比较相似(如同一领域的不同类别)
- 对推理速度有较高要求
- 主要用于分类任务
- 计算资源有限
五、元学习的实际应用
元学习已经在多个领域展现出巨大潜力,下面是一些典型应用:
5.1 计算机视觉中的应用
- 少样本图像分类:识别只有几个样本的新类别
- 域适应:快速适应新的视觉域(如从合成图像到真实图像)
- 个性化视觉模型:根据用户数据快速定制模型
- 医学图像分析:利用有限的病例学习稀有疾病特征
5.2 自然语言处理中的应用
- 少样本文本分类:快速适应新的文本分类任务
- 跨语言迁移:利用高资源语言知识帮助低资源语言处理
- 个性化对话系统:快速适应用户的语言习惯和偏好
- 持续语言学习:在不忘记旧知识的情况下学习新知识
5.3 强化学习中的应用
- 多任务强化学习:在多个环境中学习通用策略
- 快速环境适应:当环境动态变化时快速调整策略
- 机器人控制:使机器人能够快速学习新的动作和任务
- 个性化推荐系统:快速适应用户偏好变化

六、元学习的挑战与未来方向
虽然元学习取得了显著进展,但仍面临一些挑战:
6.1 当前挑战
- 任务多样性:确保训练任务足够多样以支持泛化
- 计算复杂度:特别是基于优化的方法计算开销大
- 理论理解:对元学习的理论基础理解不足
- 任务表示:如何有效表示和度量任务的相似性
- 超参数敏感性:元学习算法对超参数选择较为敏感
6.2 研究前沿和未来方向
- 无监督元学习:减少对标注数据的依赖
- 持续元学习:在持续变化的任务分布中学习
- 元强化学习:将元学习原理扩展到强化学习
- 神经架构搜索:通过元学习自动设计网络架构
- 理论框架:建立更坚实的元学习理论基础
- 元学习与因果推理结合:增强元学习的可解释性和泛化能力
七、实践部分:PyTorch实现MAML和原型网络
我们已经提供了MAML和原型网络的基本实现。下面是一个结合两种方法优点的混合实现示例:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
from copy import deepcopy
from tqdm import tqdm
class EmbeddingModel(nn.Module):
"""用于ProtoMAML的嵌入模型"""
def __init__(self, input_dim=28*28, hidden_dim=64, embedding_dim=64):
super(EmbeddingModel, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.bn1 = nn.BatchNorm1d(hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.bn2 = nn.BatchNorm1d(hidden_dim)
self.fc3 = nn.Linear(hidden_dim, embedding_dim)
def forward(self, x):
x = x.view(x.size(0), -1) # 展平输入
x = F.relu(self.bn1(self.fc1(x)))
x = F.relu(self.bn2(self.fc2(x)))
x = self.fc3(x)
return x
class ClassificationHead(nn.Module):
"""分类头,使用原型作为权重初始化"""
def __init__(self, embedding_dim, num_classes):
super(ClassificationHead, self).__init__()
self.fc = nn.Linear(embedding_dim, num_classes, bias=False)
def forward(self, x):
return self.fc(x)
def initialize_from_prototypes(self, prototypes):
"""使用原型初始化分类器权重"""
# 原型形状: (num_classes, embedding_dim)
# 转置为: (embedding_dim, num_classes)用于linear layer
with torch.no_grad():
self.fc.weight.copy_(prototypes.t())
class ProtoMAML(nn.Module):
"""ProtoMAML:结合原型网络和MAML的混合方法"""
def __init__(self, embedding_model, embedding_dim, inner_lr=0.01):
super(ProtoMAML, self).__init__()
self.embedding_model = embedding_model
self.embedding_dim = embedding_dim
self.inner_lr = inner_lr
def compute_prototypes(self, support_embeddings, support_labels):
"""计算类原型"""
unique_classes = torch.unique(support_labels)
n_classes = len(unique_classes)
# 初始化原型
prototypes = torch.zeros(n_classes, self.embedding_dim, device=support_embeddings.device)
# 为每个类计算原型
for i, c in enumerate(unique_classes):
mask = support_labels == c
prototypes[i] = support_embeddings[mask].mean(0)
return prototypes, unique_classes
def inner_loop_adaptation(self, support_x, support_y, num_inner_steps):
"""内循环适应:从支持集学习任务特定参数"""
# 嵌入支持集
support_embeddings = self.embedding_model(support_x)
# 计算原型
prototypes, unique_classes = self.compute_prototypes(support_embeddings, support_y)
# 创建并初始化分类头
n_classes = len(unique_classes)
classification_head = ClassificationHead(self.embedding_dim, n_classes).to(support_x.device)
classification_head.initialize_from_prototypes(prototypes)
# 从原型初始化开始,执行梯度下降优化分类头
optimizer = optim.SGD(classification_head.parameters(), lr=self.inner_lr)
# 重映射标签到0...n_classes-1
label_map = {c.item(): i for i, c in enumerate(unique_classes)}
mapped_support_y = torch.tensor([label_map[y.item()] for y in support_y],
device=support_y.device)
# 内循环优化
for _ in range(num_inner_steps):
# 前向传播
support_embeddings = self.embedding_model(support_x)
logits = classification_head(support_embeddings)
loss = F.cross_entropy(logits, mapped_support_y)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
return classification_head, label_map, unique_classes
def forward(self, support_x, support_y, query_x, num_inner_steps=5):
"""前向传播:适应任务并预测查询集"""
# 内循环适应
classification_head, label_map, unique_classes = self.inner_loop_adaptation(
support_x, support_y, num_inner_steps
)
# 嵌入查询集
query_embeddings = self.embedding_model(query_x)
# 应用适应后的分类头
query_logits = classification_head(query_embeddings)
return query_logits, label_map, unique_classes
def train_protomaml(model, task_generator, meta_optimizer,
num_episodes=1000, num_inner_steps=5,
tasks_per_episode=4, device='cpu'):
"""训练ProtoMAML模型"""
model.train()
losses = []
for episode in tqdm(range(num_episodes), desc="Meta-Training"):
meta_loss = 0.0
# 采样任务批次
for _ in range(tasks_per_episode):
# 获取任务数据
support_x, support_y, query_x, query_y = task_generator.sample_task()
# 移动数据到设备
support_x = support_x.to(device)
support_y = support_y.to(device)
query_x = query_x.to(device)
query_y = query_y.to(device)
# 前向传播
query_logits, label_map, unique_classes = model(
support_x, support_y, query_x, num_inner_steps
)
# 重映射查询集标签
mapped_query_y = torch.tensor([label_map[y.item()] for y in query_y],
device=query_y.device)
# 计算损失
loss = F.cross_entropy(query_logits, mapped_query_y)
meta_loss += loss
# 更新元参数
meta_optimizer.zero_grad()
meta_loss /= tasks_per_episode
meta_loss.backward()
meta_optimizer.step()
losses.append(meta_loss.item())
if (episode + 1) % 100 == 0:
avg_loss = np.mean(losses[-100:])
print(f"Episode {episode+1}/{num_episodes} - Meta Loss: {avg_loss:.6f}")
return losses
def test_protomaml(model, task_generator, num_tasks=10, num_inner_steps=10, device='cpu'):
"""测试ProtoMAML模型"""
model.eval()
accuracies = []
for task_idx in range(num_tasks):
# 获取任务数据
support_x, support_y, query_x, query_y = task_generator.sample_task()
# 移动数据到设备
support_x = support_x.to(device)
support_y = support_y.to(device)
query_x = query_x.to(device)
query_y = query_y.to(device)
# 前向传播(内循环适应)
with torch.no_grad():
query_logits, label_map, unique_classes = model(
support_x, support_y, query_x, num_inner_steps
)
# 重映射查询集标签
mapped_query_y = torch.tensor([label_map[y.item()] for y in query_y],
device=query_y.device)
# 计算准确率
pred = torch.argmax(query_logits, dim=1)
acc = (pred == mapped_query_y).float().mean().item()
accuracies.append(acc)
print(f"Task {task_idx+1} - Accuracy: {acc:.4f}")
# 计算平均准确率
avg_acc = np.mean(accuracies)
print(f"Average Test Accuracy: {avg_acc:.4f}")
return accuracies
class MiniImagenetTaskGenerator:
"""Mini-Imagenet任务生成器的简化版本"""
def __init__(self, n_way=5, k_shot=1, k_query=15):
"""
初始化任务生成器
参数:
n_way: 每个任务的类别数
k_shot: 每类支持样本数
k_query: 每类查询样本数
"""
self.n_way = n_way
self.k_shot = k_shot
self.k_query = k_query
# 在实际应用中,这里应加载Mini-Imagenet数据集
# 这里我们使用随机生成的数据作为示例
self.img_size = 84 # Mini-Imagenet标准大小
self.num_classes = 64 # Mini-Imagenet训练集中的类别数
# 模拟数据
self.data = {
i: np.random.randn(600, self.img_size, self.img_size, 3) # 每类600张图像
for i in range(self.num_classes)
}
def sample_task(self):
"""采样一个N-way K-shot任务"""
# 随机选择N个类别
selected_classes = np.random.choice(self.num_classes, self.n_way, replace=False)
support_x = []
support_y = []
query_x = []
query_y = []
for i, c in enumerate(selected_classes):
# 获取该类的所有样本
class_samples = self.data[c]
# 随机选择K个支持样本和K_query个查询样本
perm = np.random.permutation(len(class_samples))
support_idx = perm[:self.k_shot]
query_idx = perm[self.k_shot:self.k_shot + self.k_query]
# 收集支持集和查询集
support_x.append(class_samples[support_idx])
support_y.extend([c] * self.k_shot)
query_x.append(class_samples[query_idx])
query_y.extend([c] * self.k_query)
# 转换为PyTorch张量
support_x = torch.tensor(np.vstack(support_x), dtype=torch.float32)
support_y = torch.tensor(support_y, dtype=torch.long)
query_x = torch.tensor(np.vstack(query_x), dtype=torch.float32)
query_y = torch.tensor(query_y, dtype=torch.long)
# 将图像通道从最后一维移到第二维 [B, H, W, C] -> [B, C, H, W]
support_x = support_x.permute(0, 3, 1, 2)
query_x = query_x.permute(0, 3, 1, 2)
return support_x, support_y, query_x, query_y
# 运行ProtoMAML示例
def run_protomaml_example():
"""运行ProtoMAML示例"""
# 设置随机种子
torch.manual_seed(42)
np.random.seed(42)
# 检查是否有GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}")
# 创建一个简单的CNN作为嵌入模型
class SimpleCNN(nn.Module):
def __init__(self, embedding_dim=64):
super(SimpleCNN, self).__init__()
# 简化的CNN架构,实际应用中可能需要更复杂的网络
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(32)
self.conv2 = nn.Conv2d(32, 32, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(32)
self.conv3 = nn.Conv2d(32, 32, kernel_size=3, padding=1)
self.bn3 = nn.BatchNorm2d(32)
self.fc = nn.Linear(32 * 10 * 10, embedding_dim) # 假设经过池化后为10x10
def forward(self, x):
# x形状: [B, C, H, W]
x = F.relu(self.bn1(self.conv1(x)))
x = F.max_pool2d(x, 2) # 42x42
x = F.relu(self.bn2(self.conv2(x)))
x = F.max_pool2d(x, 2) # 21x21
x = F.relu(self.bn3(self.conv3(x)))
x = F.max_pool2d(x, 2) # 10x10
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
# 创建嵌入模型和ProtoMAML
embedding_model = SimpleCNN(embedding_dim=64).to(device)
model = ProtoMAML(embedding_model, embedding_dim=64, inner_lr=0.01).to(device)
# 创建元优化器
meta_optimizer = optim.Adam(model.parameters(), lr=0.001)
# 创建任务生成器
task_generator = MiniImagenetTaskGenerator(n_way=5, k_shot=5, k_query=15)
# 训练模型
print("Starting meta-training...")
losses = train_protomaml(
model, task_generator, meta_optimizer,
num_episodes=500, num_inner_steps=5,
tasks_per_episode=4, device=device
)
# 测试模型
print("\nStarting meta-testing...")
accuracies = test_protomaml(
model, task_generator, num_tasks=10,
num_inner_steps=10, device=device
)
return model, losses, accuracies
if __name__ == "__main__":
model, losses, accuracies = run_protomaml_example()
八、元学习在少样本分类中的实验对比
让我们通过一个实验对比表,比较各种元学习方法在少样本分类任务上的性能:
8.1 Mini-ImageNet 5-way分类性能对比
Mini-ImageNet是元学习研究中的一个标准基准数据集,下表总结了不同方法在该数据集上的性能:
| 方法 | 5-way 1-shot准确率(%) | 5-way 5-shot准确率(%) | 参数数量 | 适应速度 |
|---|---|---|---|---|
| 微调预训练模型 | 28.90 ± 0.50 | 49.79 ± 0.79 | 大 | 慢 |
| 匹配网络 | 43.56 ± 0.84 | 55.31 ± 0.73 | 中 | 快 |
| 原型网络 | 49.42 ± 0.78 | 68.20 ± 0.66 | 中 | 快 |
| 关系网络 | 50.44 ± 0.82 | 65.32 ± 0.70 | 中 | 快 |
| MAML | 48.70 ± 1.84 | 63.11 ± 0.92 | 小 | 中 |
| ProtoMAML | 50.50 ± 0.85 | 68.60 ± 0.70 | 中 | 中 |
| MetaOptNet | 52.87 ± 0.57 | 68.76 ± 0.48 | 中 | 中 |
| LEO | 61.76 ± 0.08 | 77.59 ± 0.12 | 大 | 中 |
注:以上数据基于各方法原始论文报告的结果,实际性能可能因实现细节而异。
8.2 各元学习方法特点分析表
| 方法 | 主要优势 | 主要劣势 | 适用场景 |
|---|---|---|---|
| 原型网络 | 简单高效,推理速度快 | 线性决策边界,表达能力有限 | 类内变异小,类别结构简单的任务 |
| 匹配网络 | 灵活的非参数化方法 | 对支持集大小敏感 | 支持样本数量不均衡的情况 |
| 关系网络 | 可学习的非线性度量 | 计算复杂度随样本数增加 | 需要复杂度量的数据集 |
| MAML | 模型无关,适应性强 | 二阶优化复杂,训练不稳定 | 任务间差异大,需要细粒度适应 |
| ProtoMAML | 结合度量学习和优化学习 | 实现复杂 | 平衡效率和适应性的场景 |
| MetaOptNet | 凸优化问题便于求解 | SVM预测相对较慢 | 需要更好决策边界的分类问题 |
| LEO | 在低维潜空间进行元学习 | 模型复杂,需要大量计算资源 | 高维特征空间,计算资源丰富 |
九、总结
9.1 元学习方法总结
我们已经详细探讨了元学习的两种主要方法:
-
基于优化的方法(MAML)
- 推导了MAML的参数更新公式,理解了二阶导数的计算
- 分析了MAML如何通过内外循环优化找到易于适应的参数初始化
-
基于度量的方法(原型网络)
- 分析了原型网络如何在度量空间中构建类原型
- 研究了度量空间的几何特性和原型计算方式
-
混合方法(ProtoMAML)
- 结合了两种方法的优势,使用原型初始化分类头,再通过梯度更新微调
9.2 关键点
- 元学习的本质是学习学习的方法,而不仅仅是学习特定任务
- 度量空间的构建对少样本学习至关重要,好的度量空间可以使简单的距离度量产生良好的分类效果
- 快速适应能力是元学习的核心,无论是通过优化还是度量学习
- 模型归纳偏置的设计对元学习性能有重大影响
- 不同元学习范式的互补性使得混合方法(如ProtoMAML)通常能获得更好的性能
希望今天的学习对你理解元学习的核心概念和方法有所帮助!元学习是一个充满活力的研究领域,通过"学会学习"的能力,它正在改变我们训练和部署机器学习模型的方式。记住,最好的学习方式是亲自动手实验,尝试不同的方法并观察效果!
如果你有任何问题或需要进一步探讨,随时联系我!
清华大学全五版的《DeepSeek教程》完整的文档需要的朋友,关注我私信:deepseek 即可获得。
怎么样今天的内容还满意吗?再次感谢朋友们的观看,关注GZH:凡人的AI工具箱,回复666,送您价值199的AI大礼包。最后,祝您早日实现财务自由,还请给个赞,谢谢!


![STM32单片机入门学习——第22节: [7-2] AD单通道AD多通道](https://i-blog.csdnimg.cn/direct/bcaa845ace1d4c01869bdf3a785a8b50.png)