【动手学深度学习】现代卷积神经网络:ALexNet
- 1,ALexNet简介
- 2,AlexNet和LeNet的对比
- 3, AlexNet模型详细设计
- 4,AlexNet采用ReLU激活函数
- 4.1,ReLU激活函数
- 4.2,sigmoid激活函数
- 4.3,为什么采用ReLu做激活函数
- 5,AlexNet的实现
- 5.1,定义AlexNet模型
- 5.2,卷积层输出矩阵形状计算
- 5.3,池化层输出矩阵形状计算
- 5.4,校验每层形状
- 5.5,读取Fashion-MNIST数据集
- 5.6,训练AlexNet模型
1,ALexNet简介
AlexNet是由多伦多大学的 Alex Krizhevsky 等人在2012年首次提出的。AlexNet不仅利用了GPU的强大计算能力,还引入了ReLU激活函数、Dropout正则化和重叠池化等创新技术,显著提升了模型的训练效率和准确性。
在AlexNet之前,尽管已经存在卷积神经网络(如LeNet),但它们的应用范围相对有限,且未能充分展示出深度学习相对于传统机器学习方法的优势。AlexNet的成功展示了深层网络的强大能力,特别是在处理复杂图像识别任务上的优越性能,在2012年的ImageNet大规模视觉识别挑战赛中,AlexNet以压倒性的优势夺冠,错误率远低于其他参赛者。这一胜利标志着深度学习时代的到来,激发了全球对AI研究的新一轮热潮,并催生了一系列基于其架构改进的先进模型。
2,AlexNet和LeNet的对比
如下图所示,AlexNet(右)本质上像是一个更深更大的LeNet(左),AlexNet在LeNet基础上做出的主要改进有:
- 引入效果更好的ReLu激活函数(LeNet采用Sigmoid激活函数);
- 池化层采用了最大池化(LeNet采用平均池化);
- AlexNet采用Dropout正则化减少过拟合;
- AlexNet的输入是像素更大的三通道彩色图片(LeNet是单通道灰度图片);
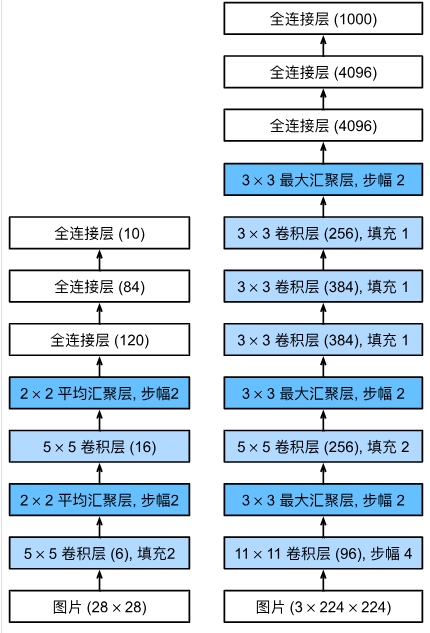
3, AlexNet模型详细设计
通过上图AlexNet的架构可以看到:
- AlexNet的第一层,卷积核的形状是 11 × 11 11\times11 11×11。由于ImageNet数据集中大多数图像的宽和高比MNIST图像的多10倍以上,因此,需要一个更大的卷积窗口来捕获目标;
- AlexNet第二层中的卷积核形状被缩减为 5 × 5 5\times5 5×5,然后是 3 × 3 3\times3 3×3。此外,在第一层、第二层和第五层卷积层之后,都加入窗口形状为 3 × 3 3\times3 3×3、步幅为2的最大池化层;
- 由于AlexNet的输入数据更复杂,
需要识别的模式更多,因此AlexNet的卷积输出通道数目远多于LeNet。比如第一个卷积层AleNet的输出通道数是96,LeNet的输出通道数是6; - 在最后一个卷积层后有两个全连接的隐藏层,分别有4096个输出;
- 输出层也是一个全连接层。使用Softmax回归做输出,用于输出每个类别的概率分布。1000个输出对应ImageNet数据集的1000个类别;
4,AlexNet采用ReLU激活函数
AlexNet使用了ReLU激活函数。而不是采用LeNet中的Sigmoid激活函数
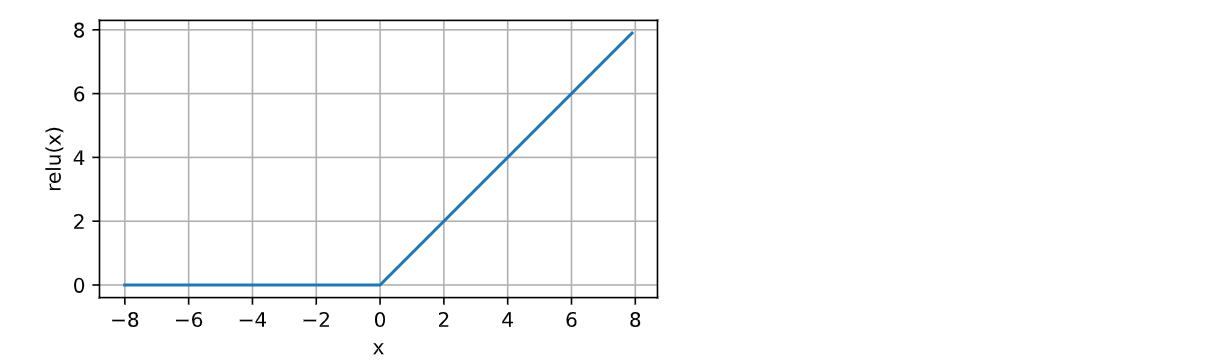
4.1,ReLU激活函数
ReLU函数被定义为该元素与0中的最大者。 ReLU函数的数学表达式如下:
ReLU函数图像为:
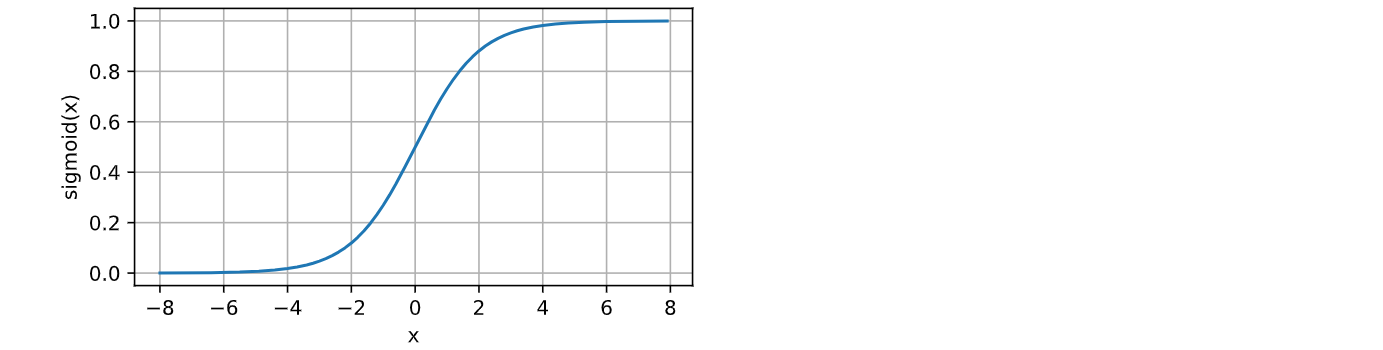
4.2,sigmoid激活函数
sigmoid函数能够将输入的实数值压缩到0和1之间。 sigmoid函数数学表达式为:
sigmoid函数图像为:
4.3,为什么采用ReLu做激活函数
AlexNet使用ReLU激活函数,原因如下:
- ReLU激活函数的计算更简单,它不需要如sigmoid激活函数那般复杂的求幂运算;
- ReLU激活函数使训练模型更加容易。当sigmoid激活函数的输出非常接近于0或1时,这些区域的梯度几乎为0,从而使模型无法得到有效的训练。 因此反向传播无法继续更新一些模型参数。相反,
ReLU激活函数在正区间的梯度总是1,可以有效缓解梯度消失问题;
5,AlexNet的实现
接下来使用深度学习框架实现AlexNet模型,结合Fashion-MNIST图像分类数据集进行训练和测试。
Fashion-MNIST数据集基本情况如下:
- 训练集:有60,000张图像,用于模型训练;
- 测试集:有10,000张图像,用于评估模型性能;
- 数据集由灰度图像组成,其通道数为1;
- 每个图像的高度和宽度均为28像素;
- 调用load_data_fashion_mnist()函数加载数据集;
- Fashion-MNIST中包含的10个类别;
5.1,定义AlexNet模型
定义AlexNet模型
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
# 第一个卷积层:使用11*11的卷积核,步幅为4(以减少输出的高度和宽度)。
# 输入通道为1(Fashion-MNIST数据集为灰度图像),输出通道的数目为96
# 采用ReLU激活函数
# 注意:padding=1表示上下左右各填充1
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
# 采用步幅为2,形状3×3的最大池化层
nn.MaxPool2d(kernel_size=3, stride=2),
# 第二个卷积层:使用5×5卷积核,填充为2保证输入与输出的高和宽一致
# 输入通道为96,输出通道数增至256
# 采用ReLU激活函数
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
# 依然采用步幅为2,形状3×3的最大池化层
nn.MaxPool2d(kernel_size=3, stride=2),
# 三个连续的卷积层:均使用和3×3的卷积核,采用填充为1 保证输入与输出的高和宽一致
# 前两个卷积层的输出通道数为384,最后一个卷积层的输出通道数为256
# 采用ReLU激活函数
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
# 三个卷积层之后,依然采用步幅为2,形状3×3的最大池化层
nn.MaxPool2d(kernel_size=3, stride=2),
# 将多维张量展平成一维向量,以便输入到全连接层。
nn.Flatten(),
# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合
# 设置p=0.5表示训练过程中,每层神经元有50%的概率被暂时从网络中丢弃(即其输出被置为零)。可强制模型学习更加鲁棒的特征,并减少对特定神经元的依赖
nn.Linear(6400, 4096), nn.ReLU(), nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(p=0.5),
# 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10
nn.Linear(4096, 10))
5.2,卷积层输出矩阵形状计算
假设输入形状为 n h × n w n_h\times n_w nh×nw,卷积核形状为 k h × k w k_h\times k_w kh×kw。
无填充、步幅默认为1时,输出矩阵形状为:
( n h − k h + 1 ) × ( n w − k w + 1 ) (n_h-k_h+1) \times (n_w-k_w+1) (nh−kh+1)×(nw−kw+1)
添加 p h p_h ph行填充(大约一半在顶部,一半在底部)和 p w p_w pw列填充(左侧大约一半,右侧一半),步幅为1时。输出矩阵形状为:
( n h − k h + p h + 1 ) × ( n w − k w + p w + 1 ) 。 (n_h-k_h+p_h+1)\times(n_w-k_w+p_w+1)。 (nh−kh+ph+1)×(nw−kw+pw+1)。
添加 p h p_h ph行、 p w p_w pw列填充,设置垂直步幅 s h s_h sh,水平步幅 s w s_w sw时,输出矩阵形状为:
⌊ n h − k h + p h s h + 1 ⌋ × ⌊ n w − k w + p w s w + 1 ⌋ \lfloor\frac{n_h-k_h+p_h}{s_h}+1\rfloor \times \lfloor\frac{n_w-k_w+p_w}{s_w}+1\rfloor ⌊shnh−kh+ph+1⌋×⌊swnw−kw+pw+1⌋
此时输出形状可换算为:
⌊ ( n h − k h + p h + s h ) / s h ⌋ × ⌊ ( n w − k w + p w + s w ) / s w ⌋ \lfloor(n_h-k_h+p_h+s_h)/s_h\rfloor \times \lfloor(n_w-k_w+p_w+s_w)/s_w\rfloor ⌊(nh−kh+ph+sh)/sh⌋×⌊(nw−kw+pw+sw)/sw⌋
如果我们设置了 p h = k h − 1 p_h=k_h-1 ph=kh−1和 p w = k w − 1 p_w=k_w-1 pw=kw−1,则输出形状将简化为: ⌊ ( n h + s h − 1 ) / s h ⌋ × ⌊ ( n w + s w − 1 ) / s w ⌋ \lfloor(n_h+s_h-1)/s_h\rfloor \times \lfloor(n_w+s_w-1)/s_w\rfloor ⌊(nh+sh−1)/sh⌋×⌊(nw+sw−1)/sw⌋
更进一步,如果输入的高度和宽度可以被垂直和水平步幅整除,则输出形状将为:
(
n
h
/
s
h
)
×
(
n
w
/
s
w
)
(n_h/s_h) \times (n_w/s_w)
(nh/sh)×(nw/sw)
5.3,池化层输出矩阵形状计算
假设输入形状为
n
h
×
n
w
n_h\times n_w
nh×nw,卷积核形状为
k
h
×
k
w
k_h\times k_w
kh×kw,池化操作一般无填充,池化输出的矩阵形状如下:
输出的高为:
⌊
n
h
−
k
h
s
h
+
1
⌋
输出的高为:\lfloor\frac{n_h-k_h}{s_h}+1\rfloor
输出的高为:⌊shnh−kh+1⌋
输出的宽为:
⌊
n
w
−
k
w
s
w
+
1
⌋
输出的宽为:\lfloor\frac{n_w-k_w}{s_w}+1\rfloor
输出的宽为:⌊swnw−kw+1⌋
5.4,校验每层形状
输出每一层的形状做检查
# 模拟形状为 (1, 1, 224, 224)的输入张量X,X的元素是从标准正态分布(均值为0,标准差为1)中随机抽取的
X = torch.randn(1, 1, 224, 224)
for layer in net:
# 对于每一层,使用当前层处理输入张量 X
X=layer(X)
print(layer.__class__.__name__,'output shape:\t',X.shape)
运行结果如下:

5.5,读取Fashion-MNIST数据集
d2l包内部定义的load_data_fashion_mnist加载数据集
"""
下载Fashion-MNIST数据集,然后将其加载到内存中
参数resize表示调整图片大小
"""
def load_data_fashion_mnist(batch_size, resize=None):
# trans是一个用于转换的 *列表*
trans = [transforms.ToTensor()]
if resize: # resize不为空,表示需要调整图片大小
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(
root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="../data", train=False, transform=trans, download=True)
return (data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers()),
data.DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=get_dataloader_workers()))
直接调用API加载数据
batch_size = 128
# 直接调用API获取
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
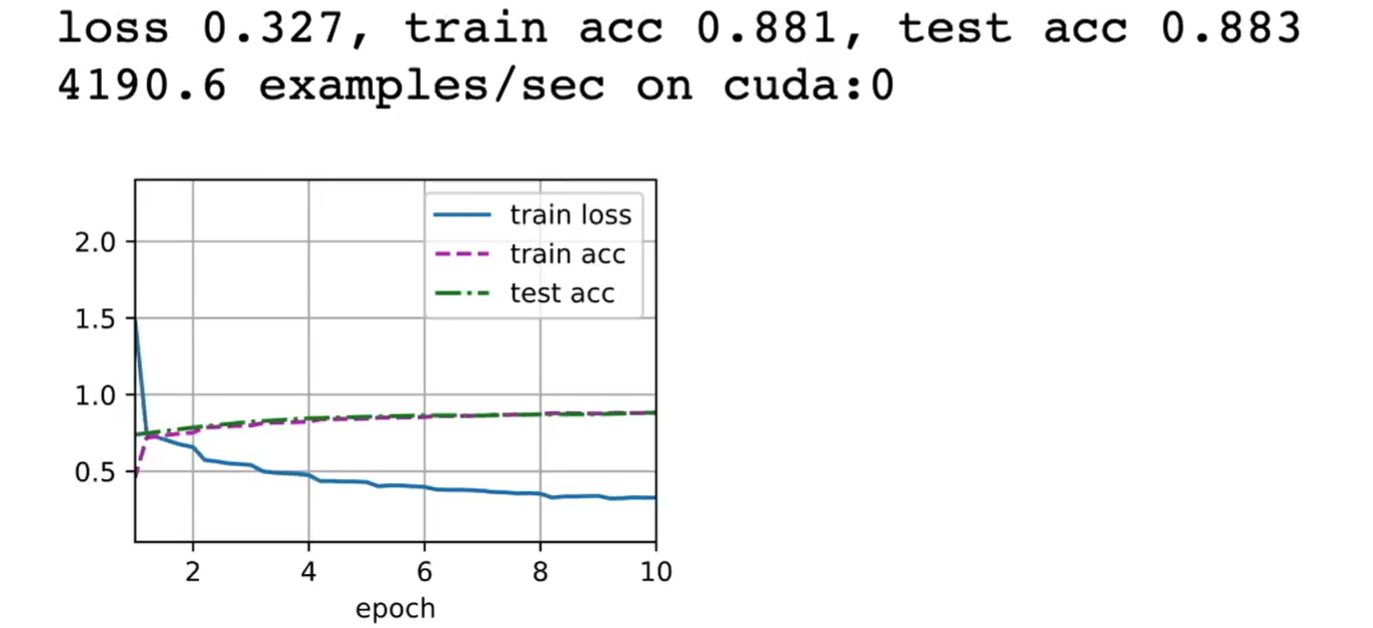
5.6,训练AlexNet模型
# 设置学习率核训练轮数
lr, num_epochs = 0.01, 10
# 训练模型
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
运行结果如下:



![STM32单片机入门学习——第22节: [7-2] AD单通道AD多通道](https://i-blog.csdnimg.cn/direct/bcaa845ace1d4c01869bdf3a785a8b50.png)