目录
- 1.matplotlib概述
- 2.风格设置
- 3.条形图
- 4.盒图
- 5.直方图和散点图
- 6.3D图
- 7.pie图和布局
- 8.Pandas与sklearn结合实例
1.matplotlib概述
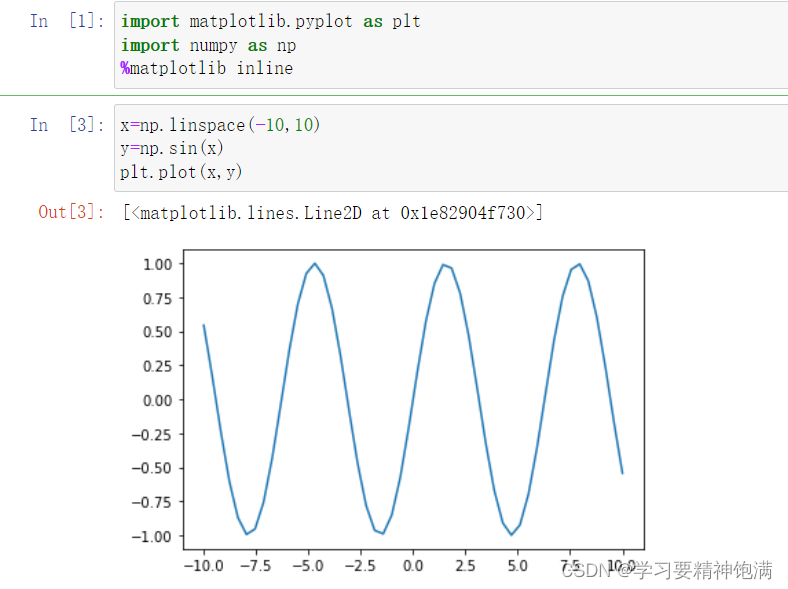
Matplotlib 是一个用 Python 编程语言编写的、基于 NumPy 的开源数据可视化库。它提供了一套完整的兼容 MATLAB 的 API,支持各种常用的二维数据可视化、三维数据可视化以及动画制作等功能,能够轻松生成高质量的数据图表和图形。下面主要介绍其中的pyplot的常用绘图操作。
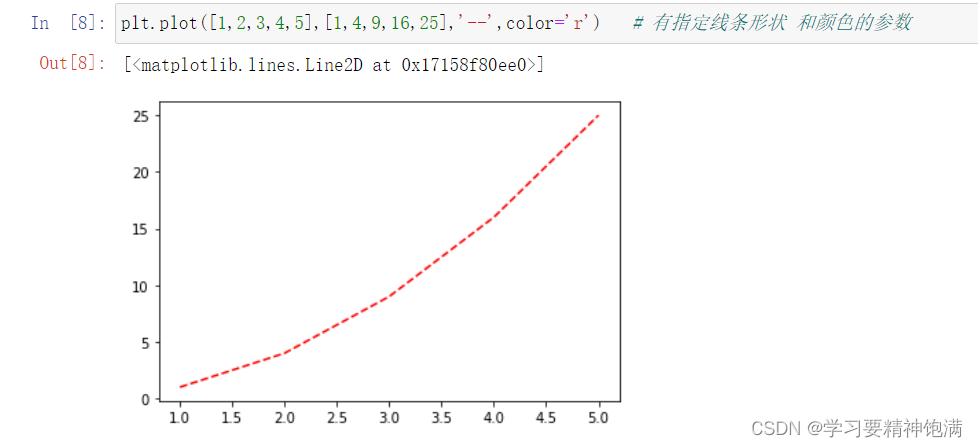
常用的线条样式
| 字符 | 类型 | 字符 | 类型 |
|---|---|---|---|
'-' | 实线 | '--' | 虚线 |
'-.' | 虚点线 | ':' | 点线 |
'.' | 点 | ',' | 像素点 |
'o' | 圆点 | 'v' | 下三角点 |
'^' | 上三角点 | '<' | 左三角点 |
'>' | 右三角点 | '1' | 下三叉点 |
'2' | 上三叉点 | '3' | 左三叉点 |
'4' | 右三叉点 | 's' | 正方点 |
'p' | 五角点 | '*' | 星形点 |
'h' | 六边形点1 | 'H' | 六边形点2 |
'+' | 加号点 | 'x' | 乘号点 |
'D' | 实心菱形点 | 'd' | 瘦菱形点 |
'_' | 横线点 |
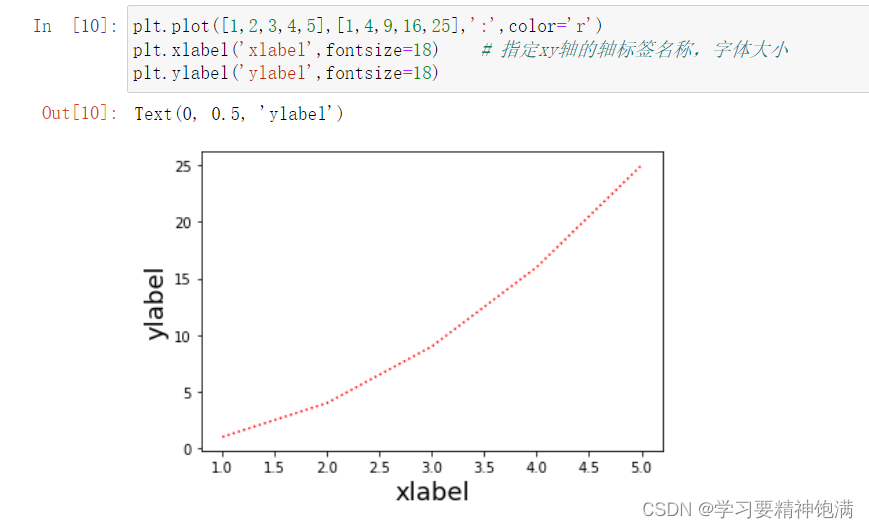
表示颜色的字符参数有:
| 字符 | 颜色 |
|---|---|
‘b’ | 蓝色,blue |
‘g’ | 绿色,green |
‘r’ | 红色,red |
‘c’ | 青色,cyan |
‘m’ | 品红,magenta |
‘y’ | 黄色,yellow |
‘k’ | 黑色,black |
‘w’ | 白色,white |
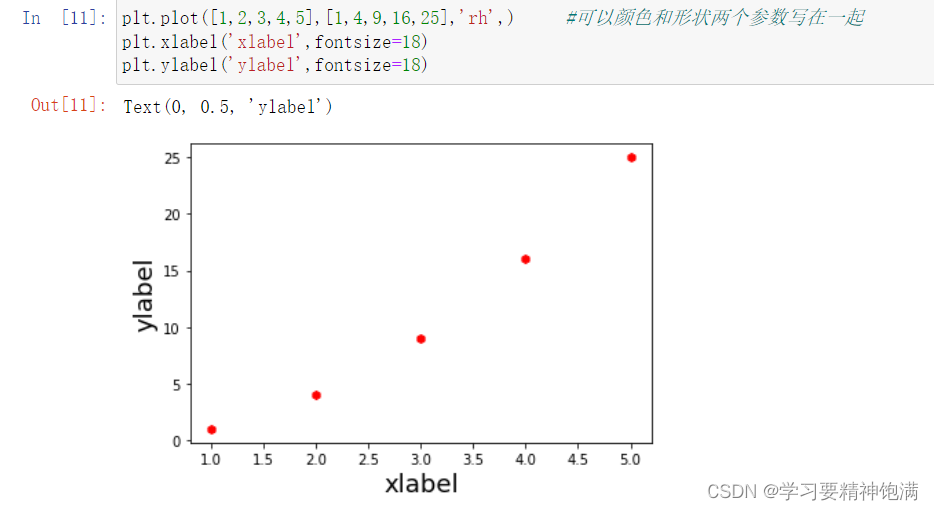
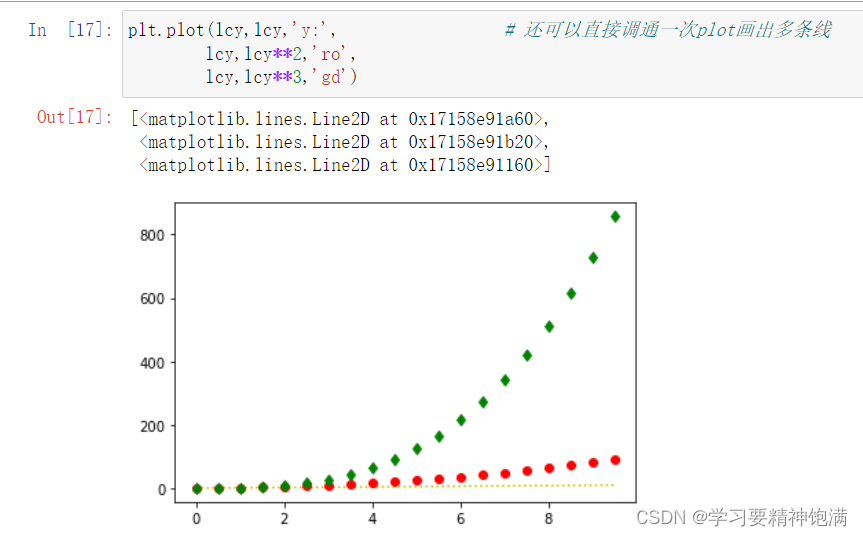
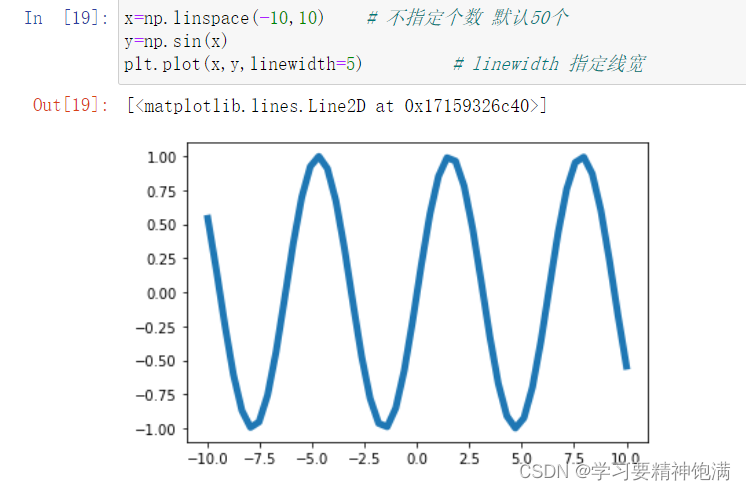
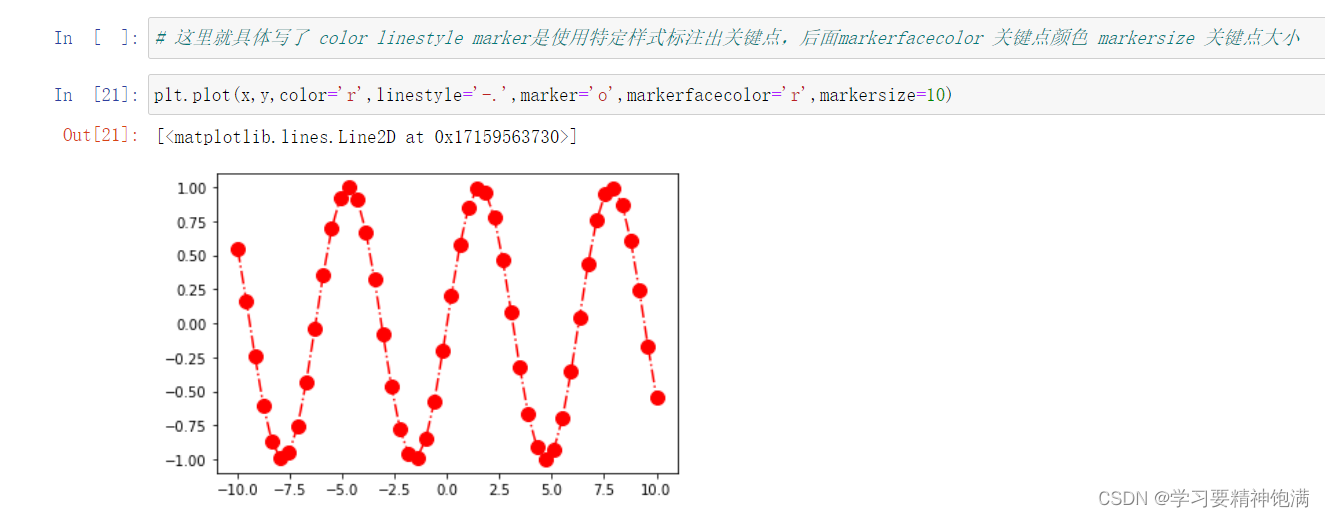
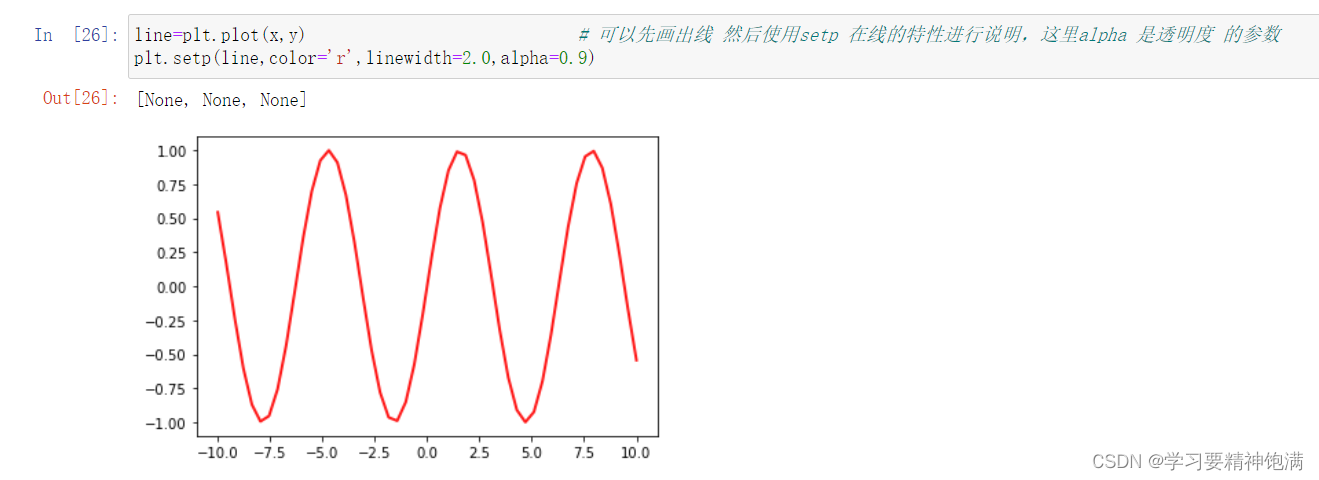
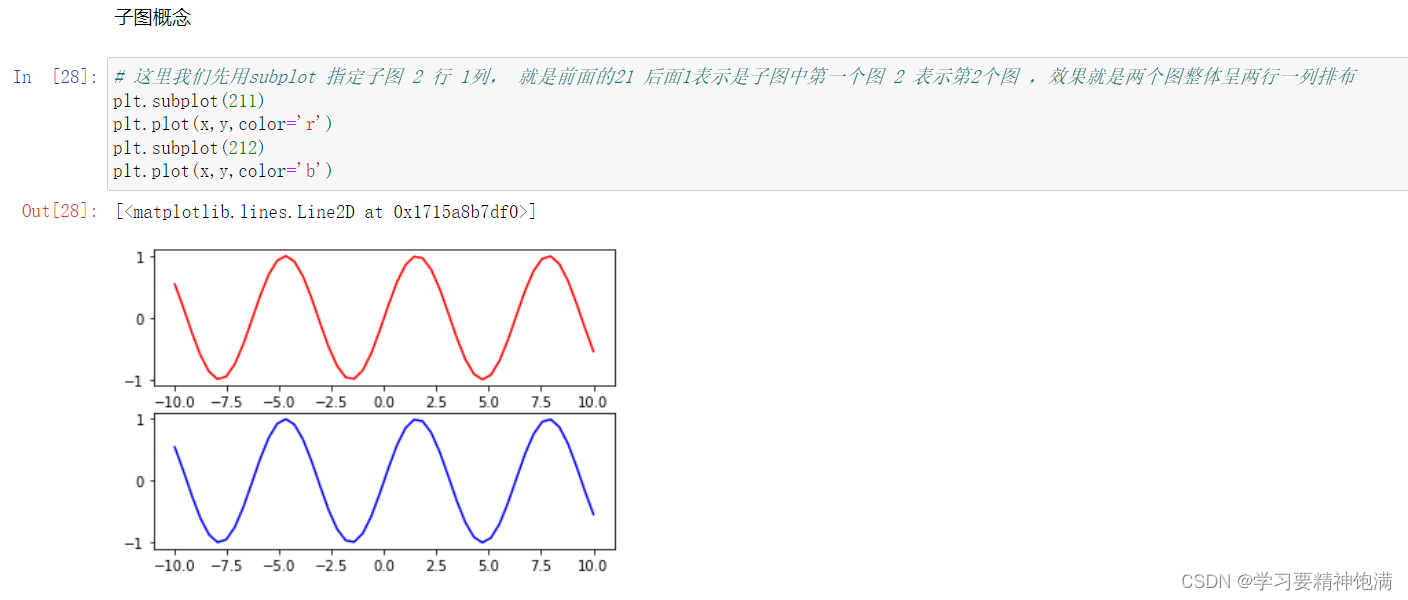
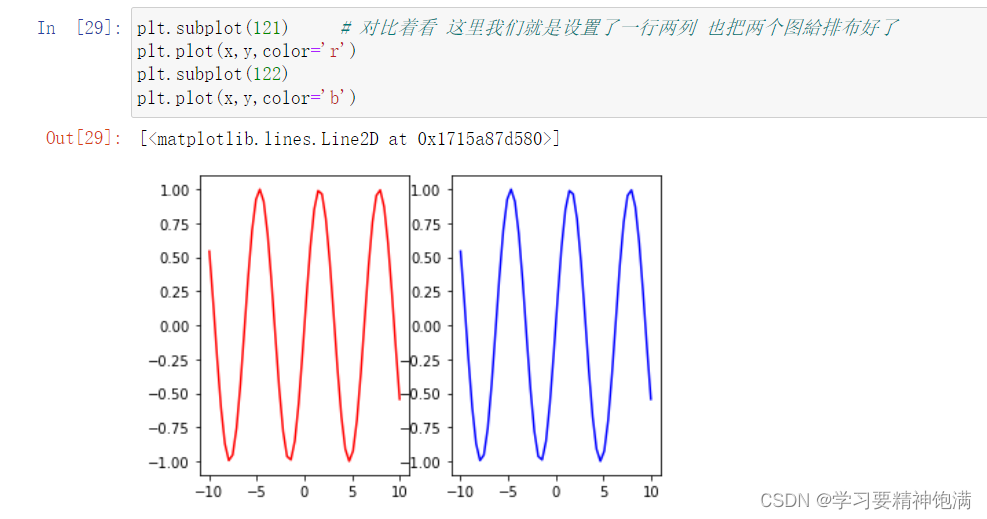
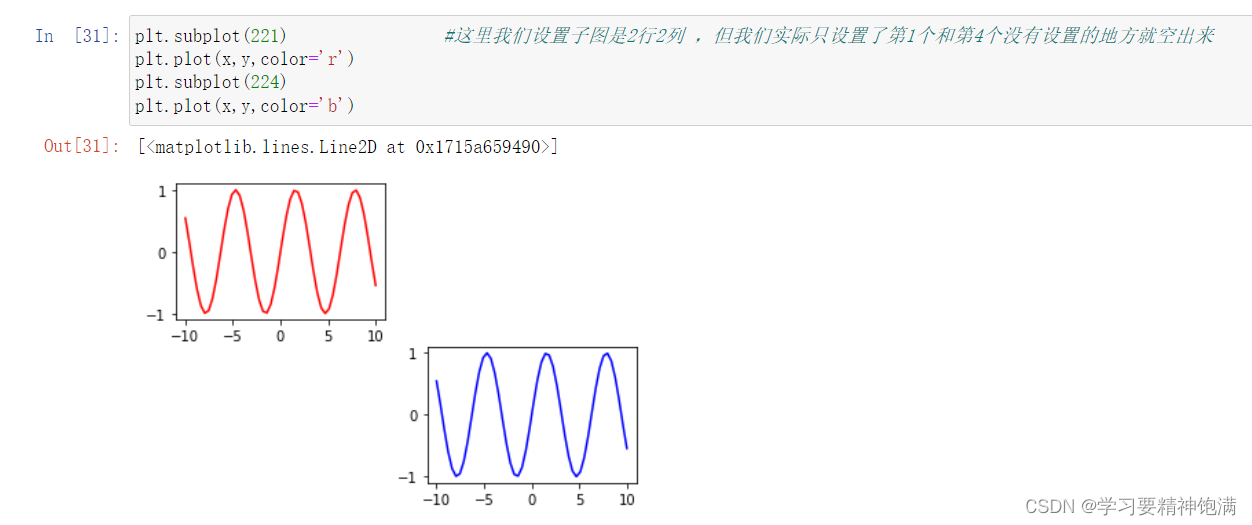
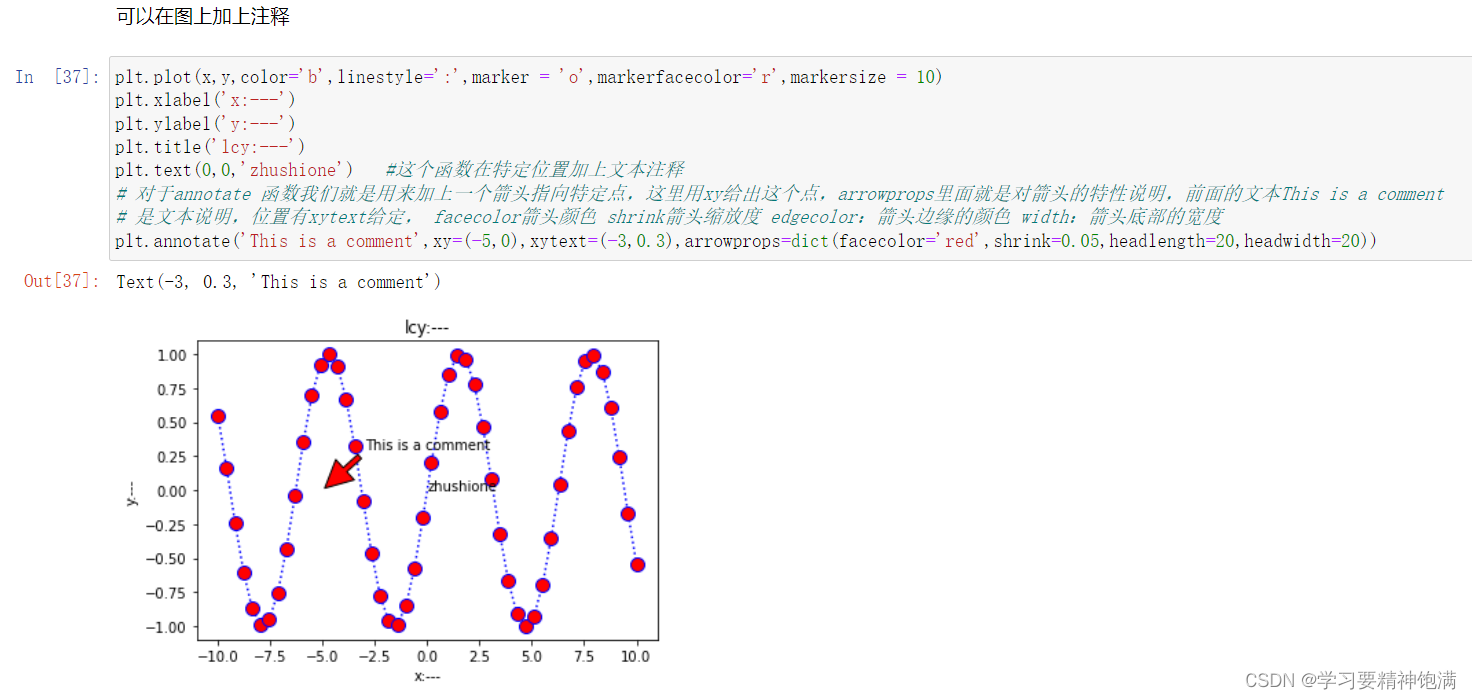
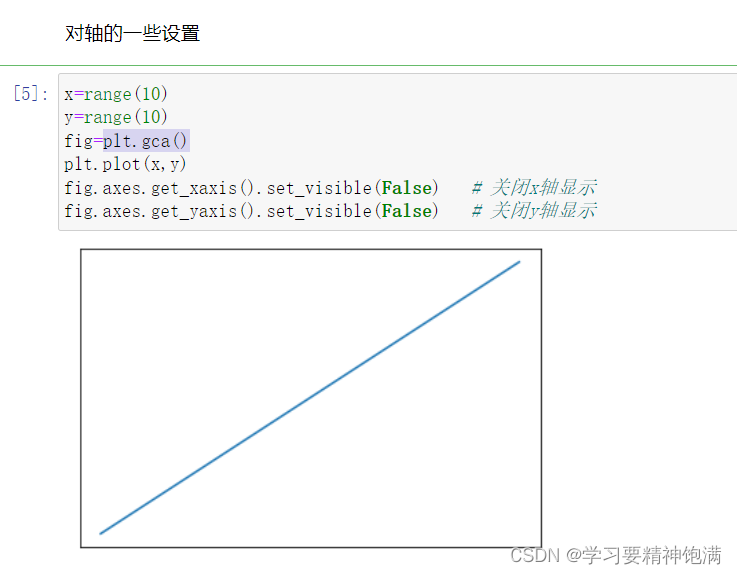
在 Matplotlib 的 pyplot 模块中,gca() 函数可以获取当前正在使用的 Axes 对象,或创建一个新的 Axes 对象并将其设置为当前 Axes。
gca() 可以用来获取和设置图表中的坐标轴对象(Axes)以及它们的属性。它可以内嵌于其他绘图函数中,用于获取当前的 Axes 对象以进行进一步设置,例如,设置坐标轴范围、标签、标题、刻度、网格线等。当然,如果图表中没有 Axes 对象,则需要通过 add_axes() 或其他函数创建一个新的 Axes 对象,然后将它设置为当前对象。
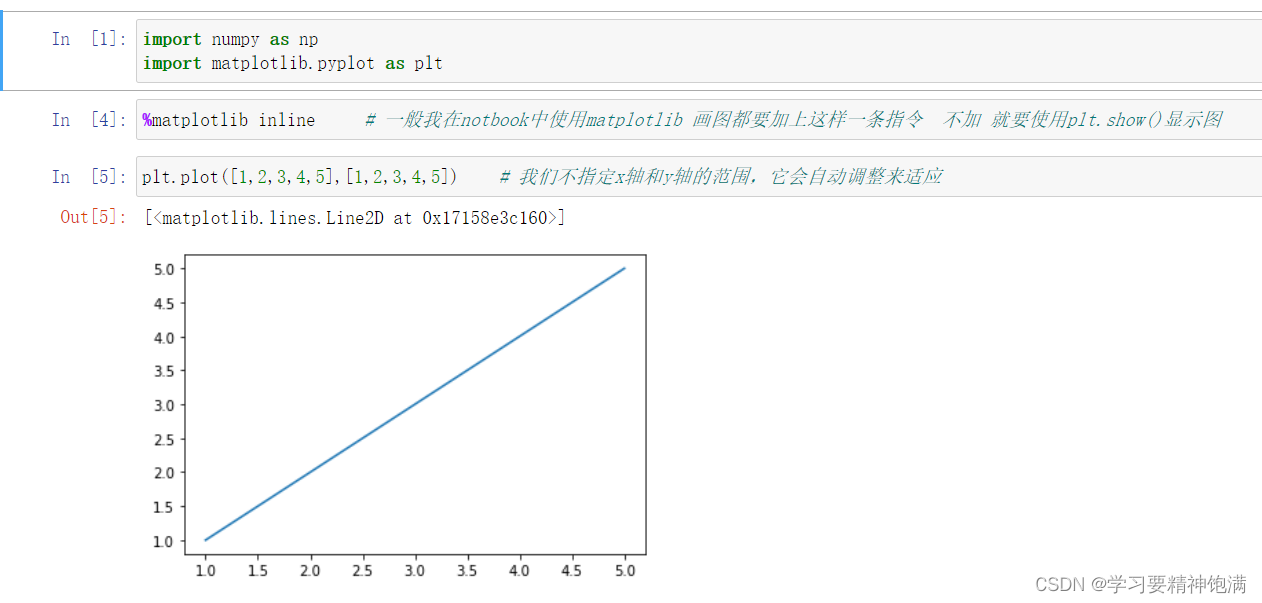
import numpy as np
import matplotlib.pyplot as plt
# 生成一组数据
x = np.linspace(-10, 10, 100)
y = np.sin(x)
# 绘制折线图
plt.plot(x, y)
# 获取当前 Axes 对象
ax = plt.gca()
# 设置坐标轴范围
ax.set_xlim([-10, 10])
ax.set_ylim([-1, 1])
# 设置坐标轴刻度
ax.set_xticks([-10, -5, 0, 5, 10])
ax.set_yticks([-1, -0.5, 0, 0.5, 1])
# 设置坐标轴标签
ax.set_xlabel('x')
ax.set_ylabel('sin(x)')
# 设置图表标题
ax.set_title('y=sin(x)')
# 显示图表
plt.show()

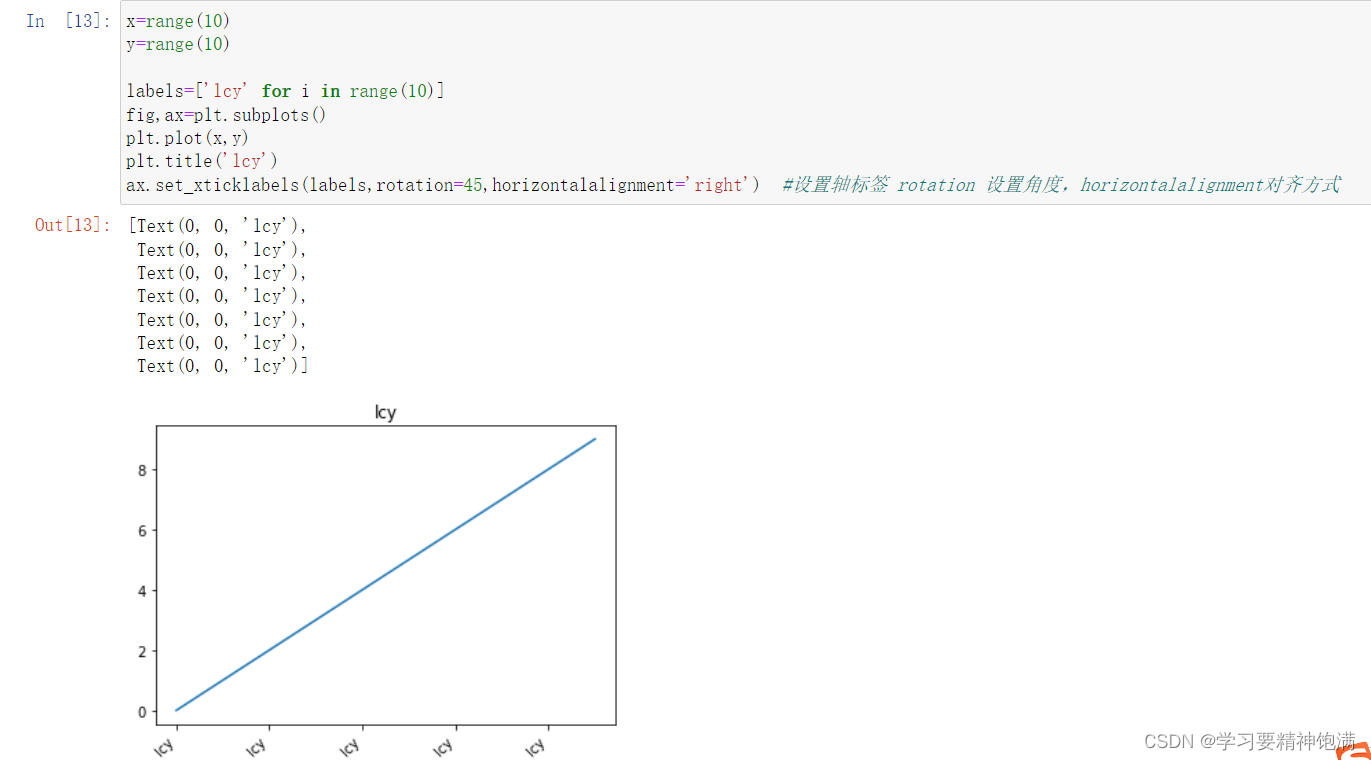
2.风格设置
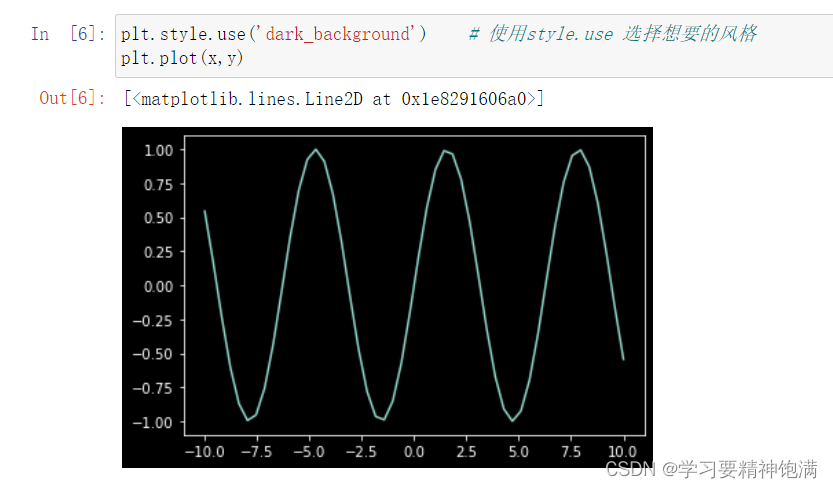
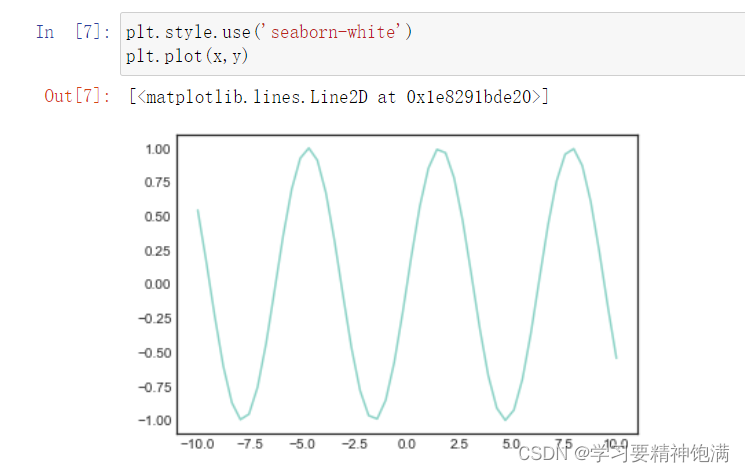
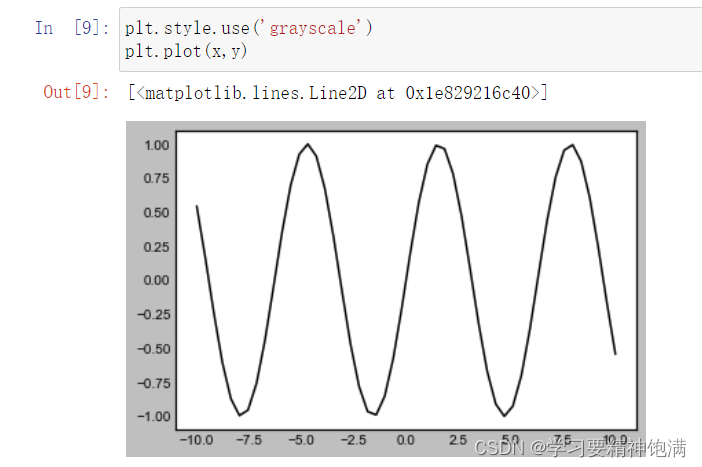
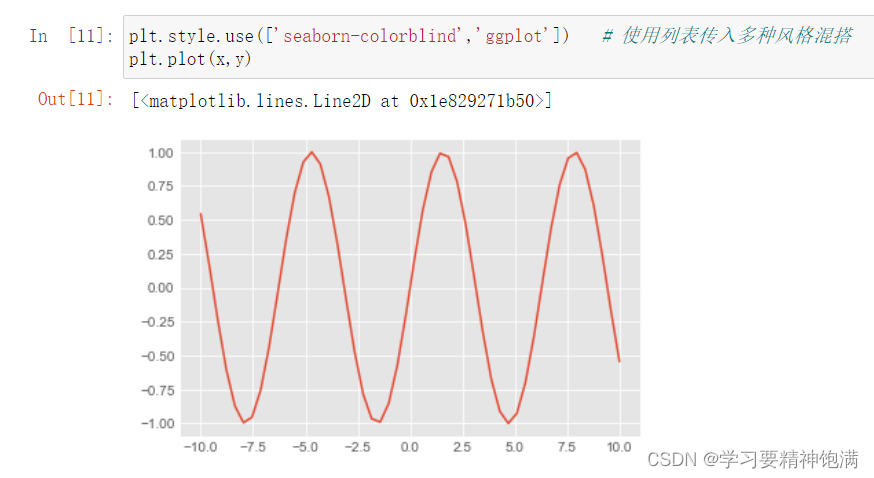
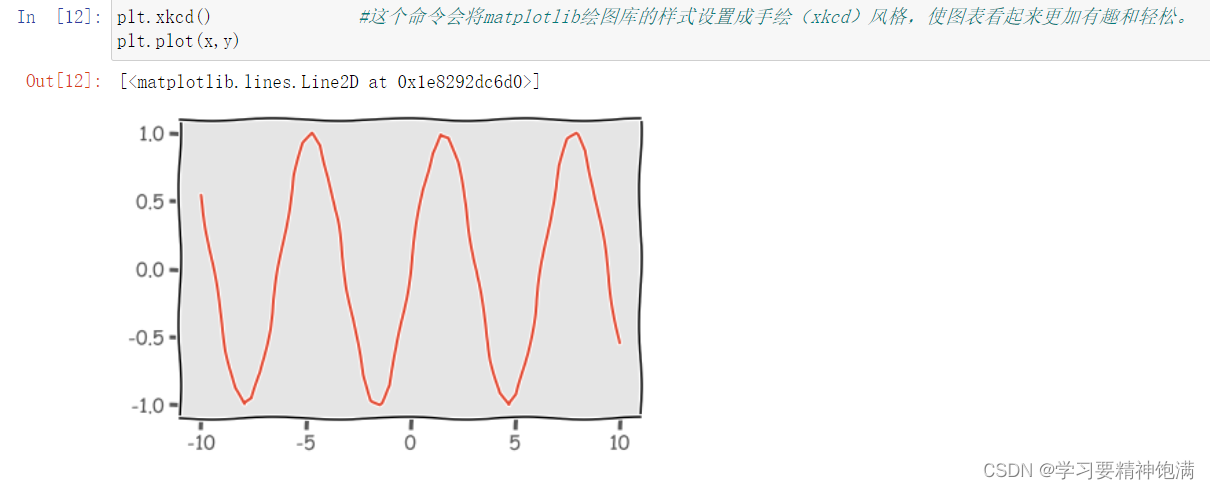
3.条形图
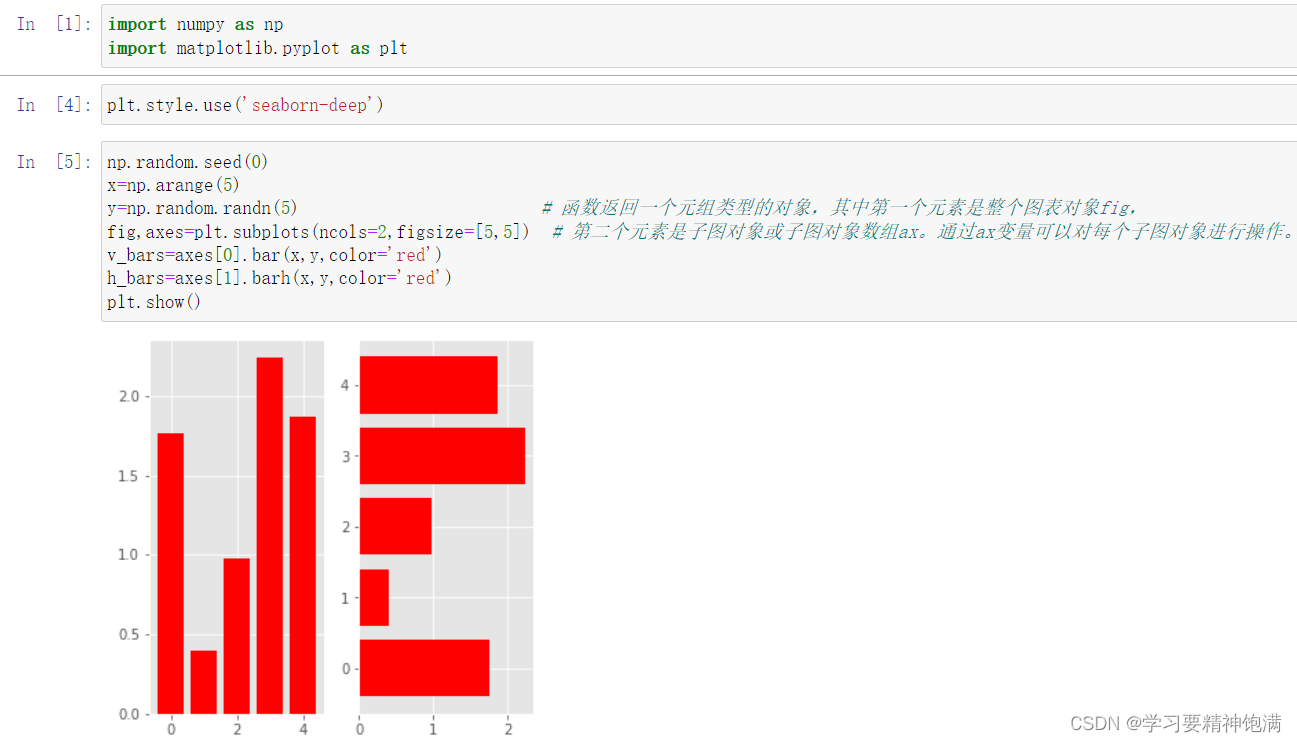
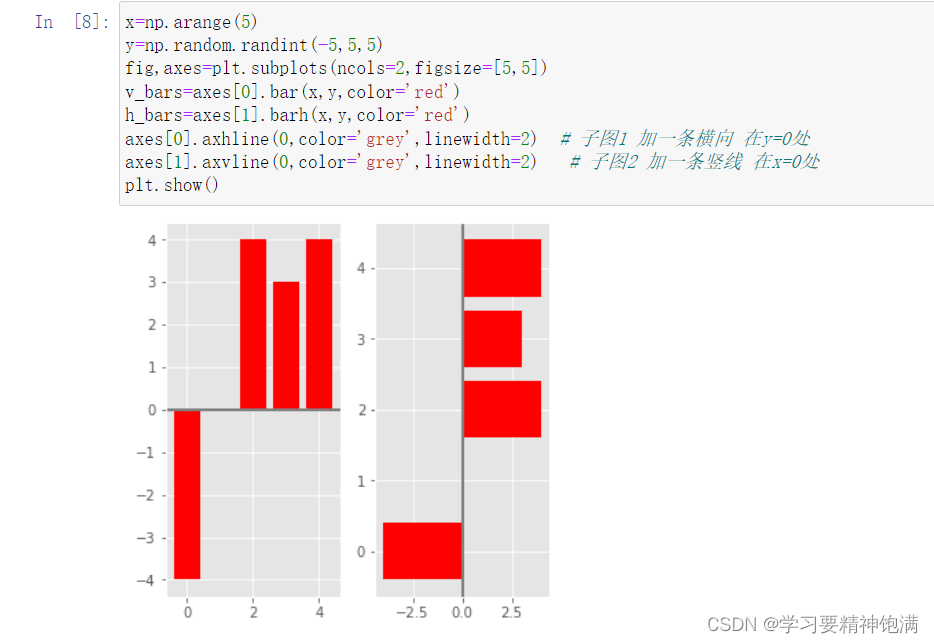
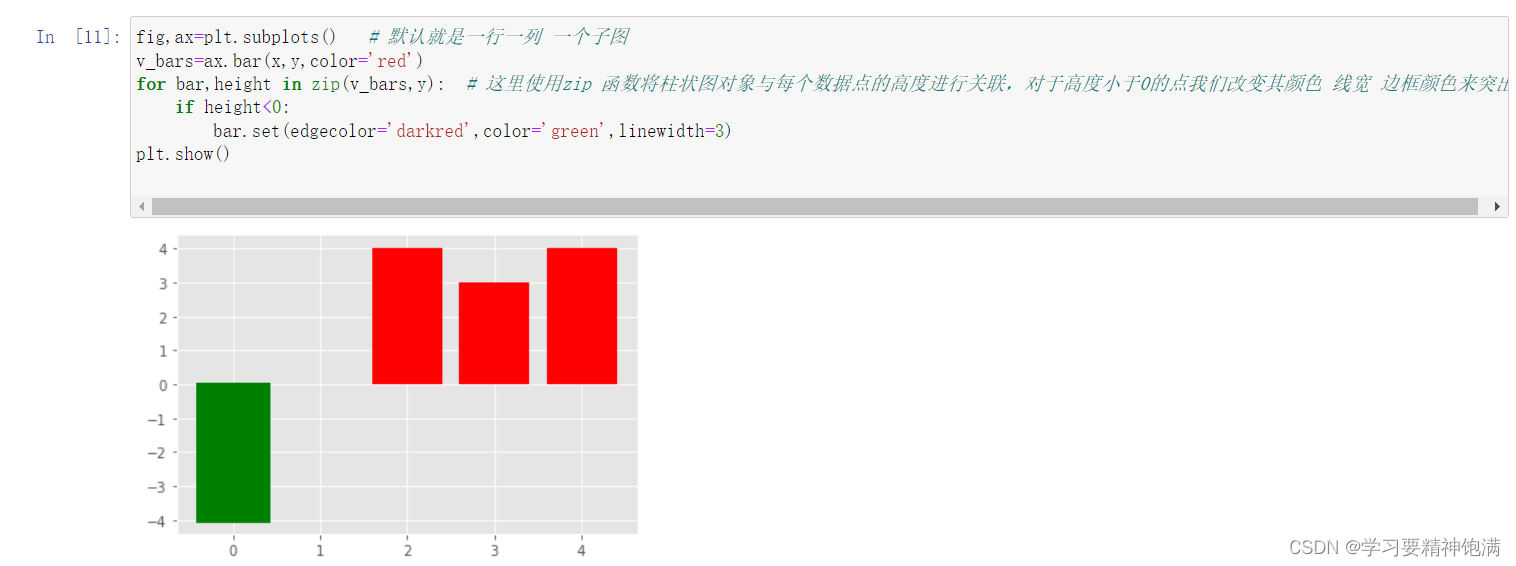
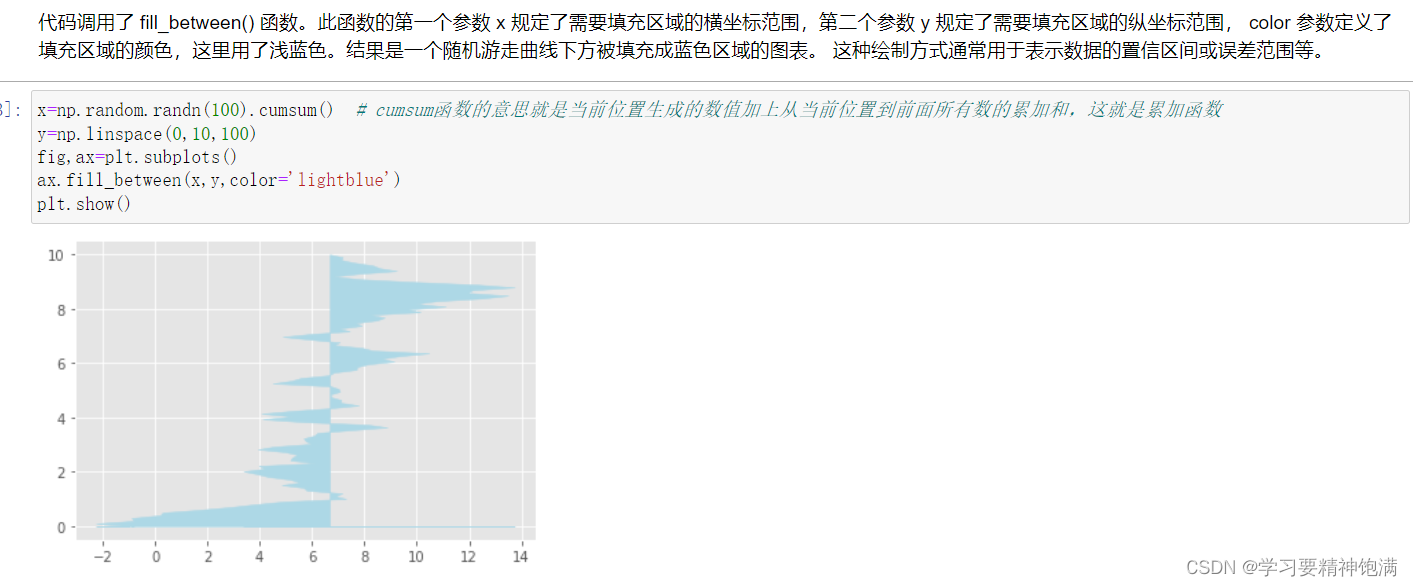
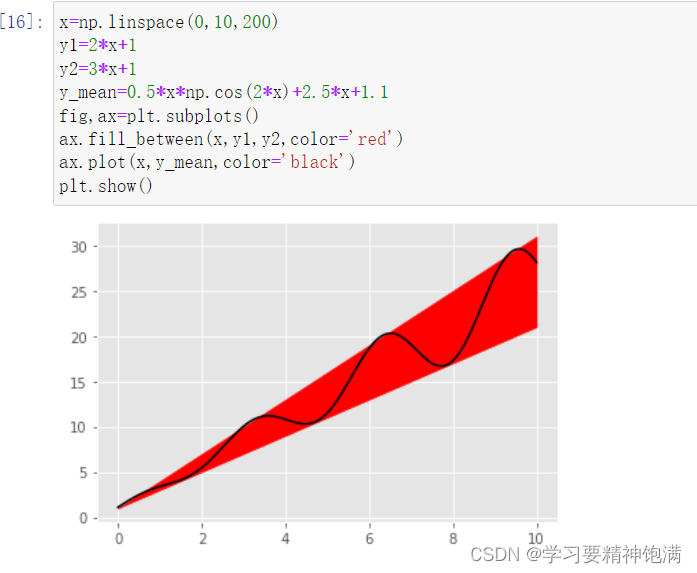
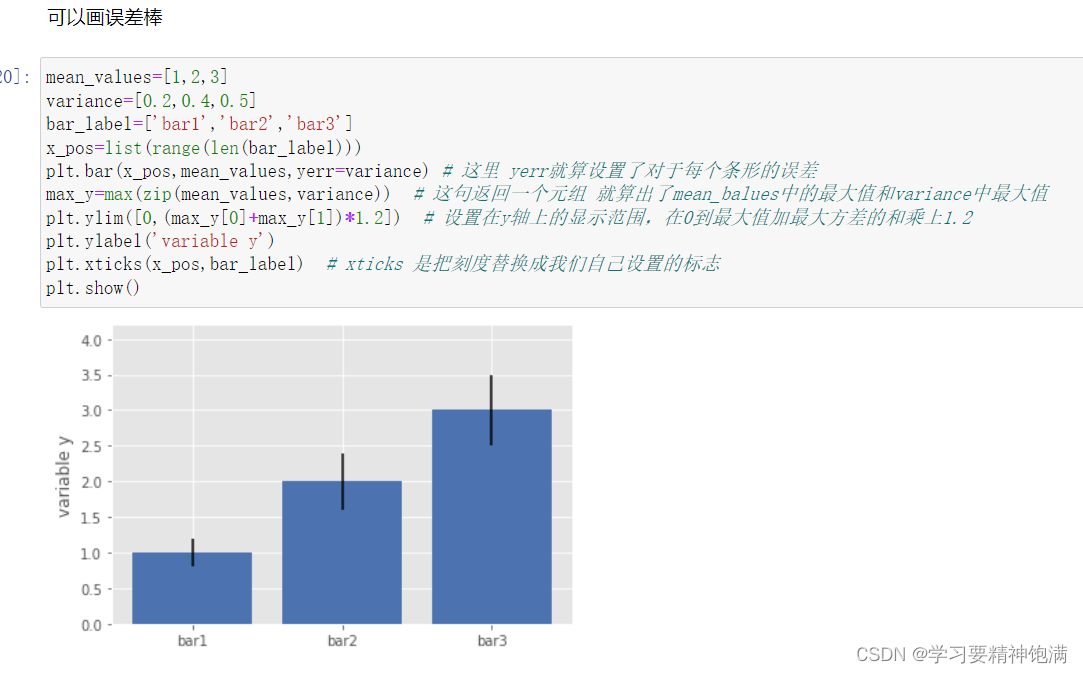

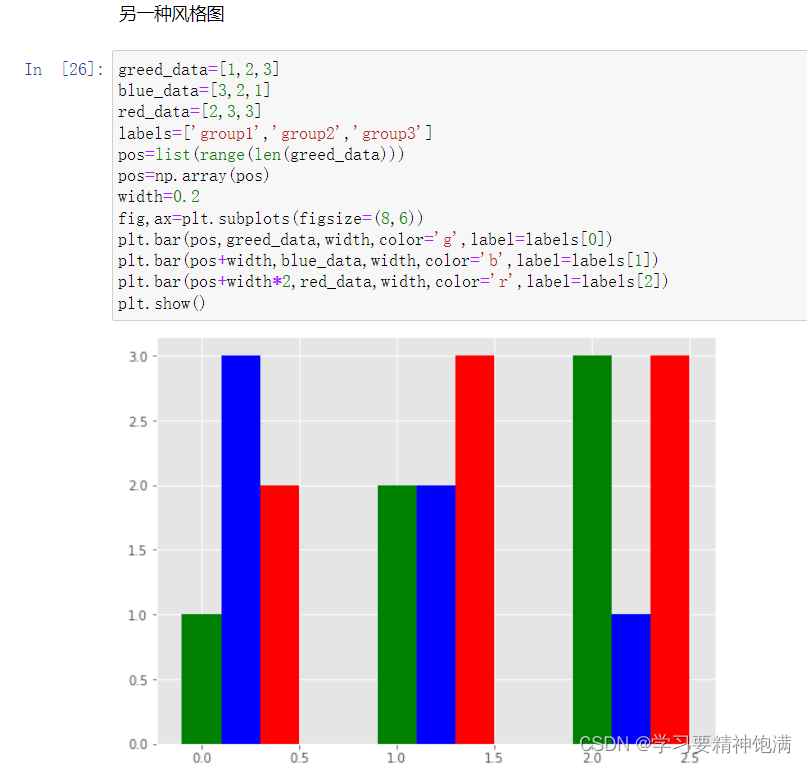
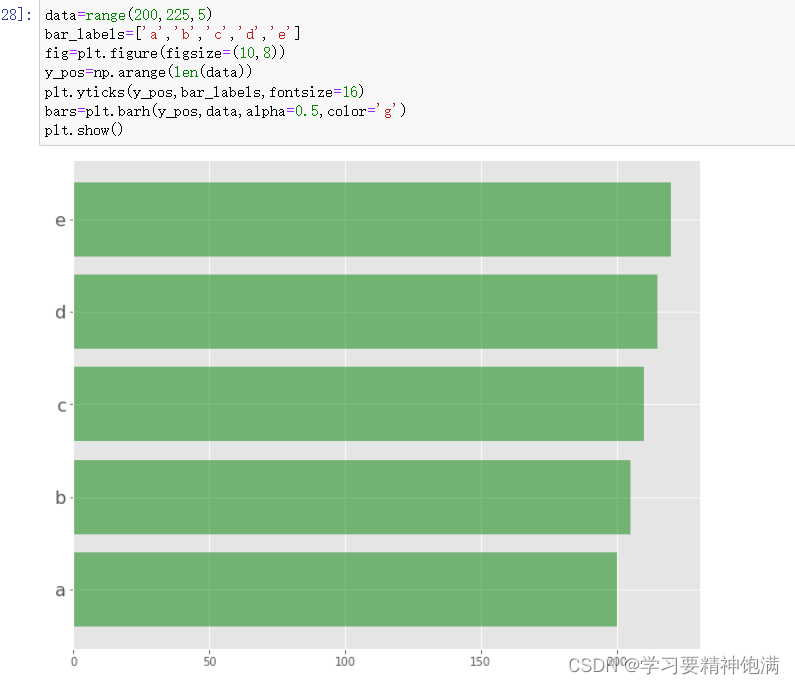
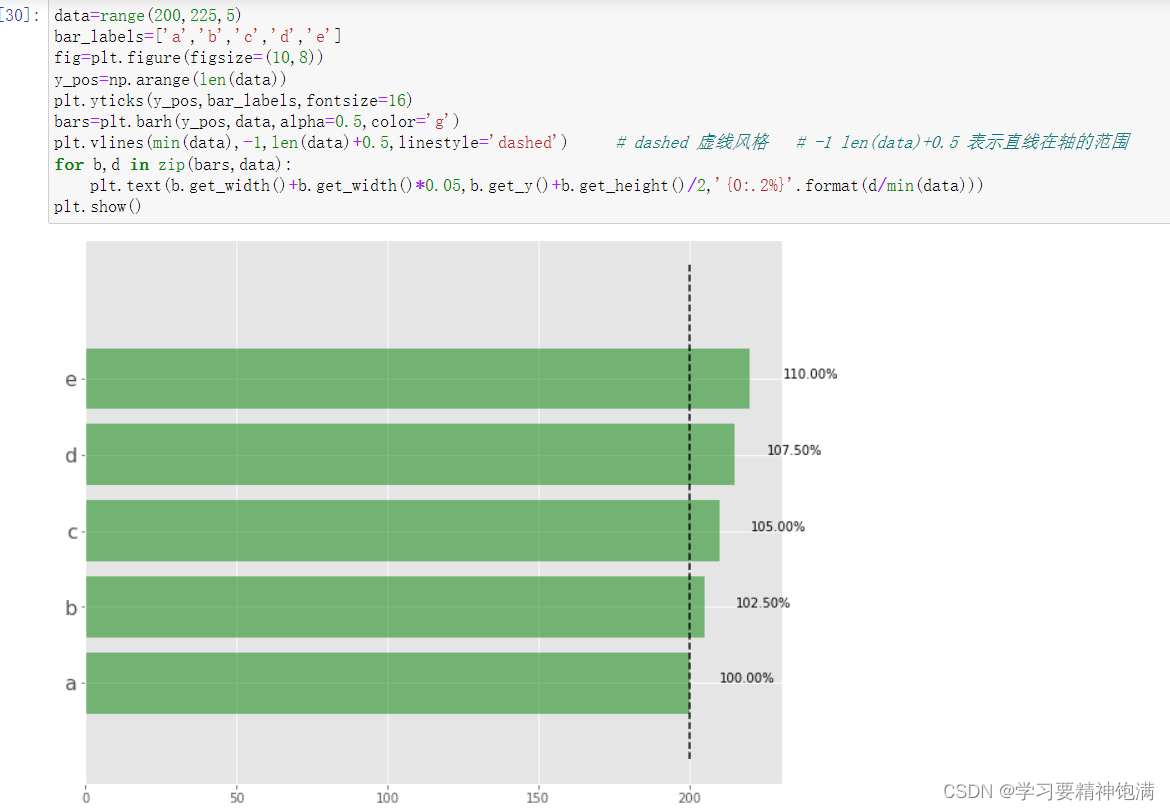
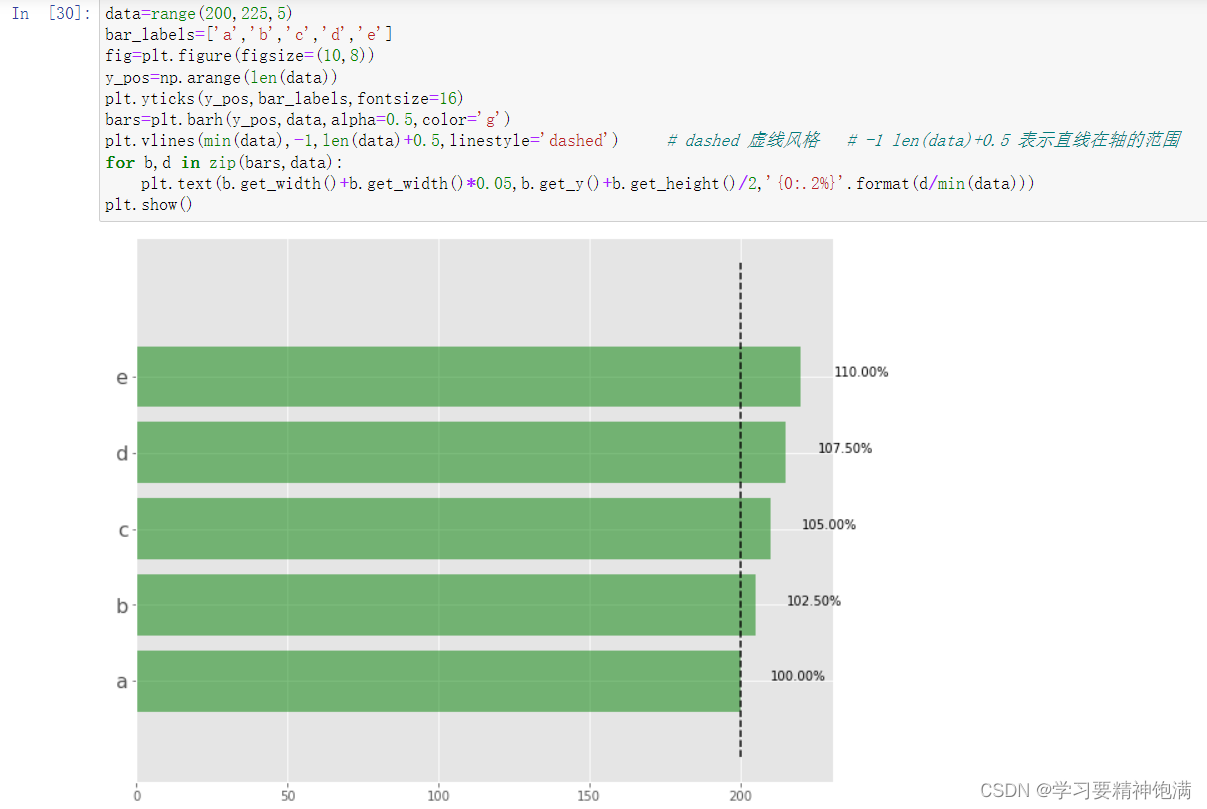
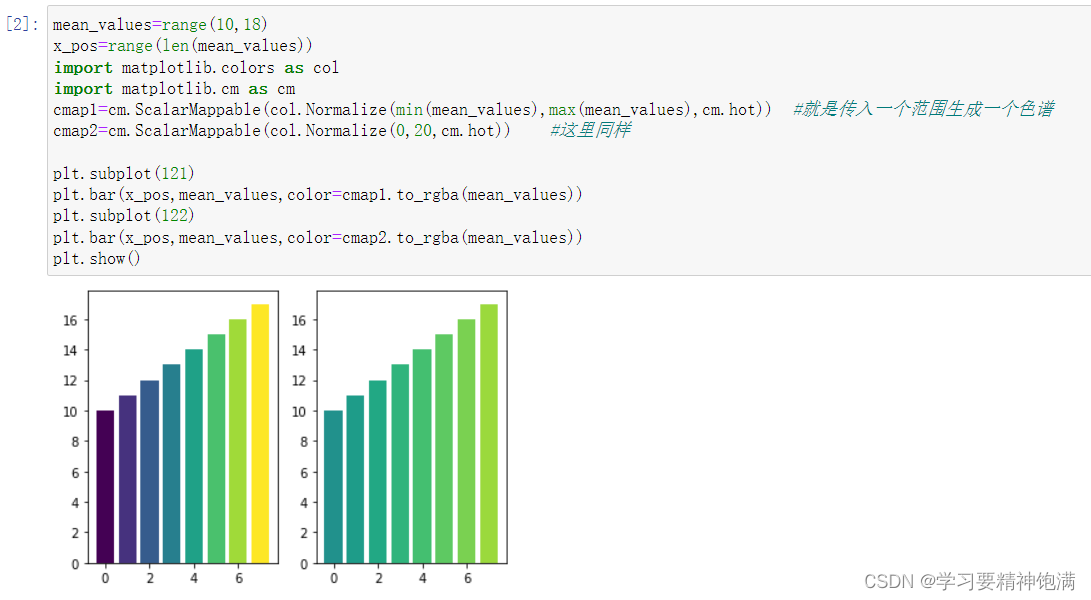
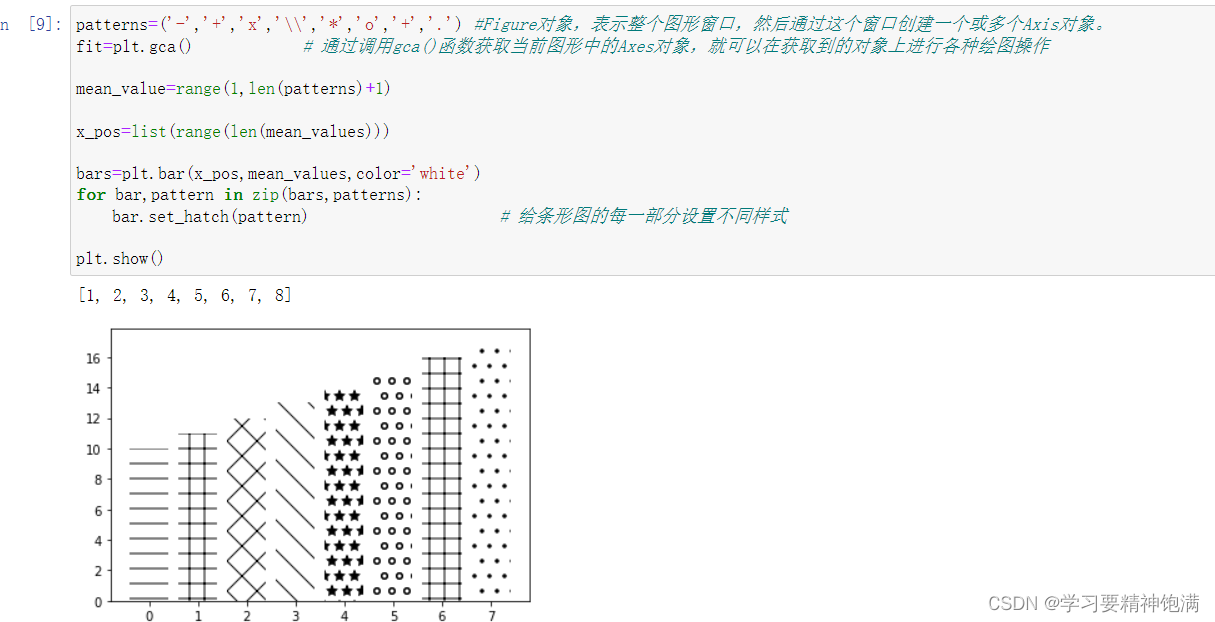
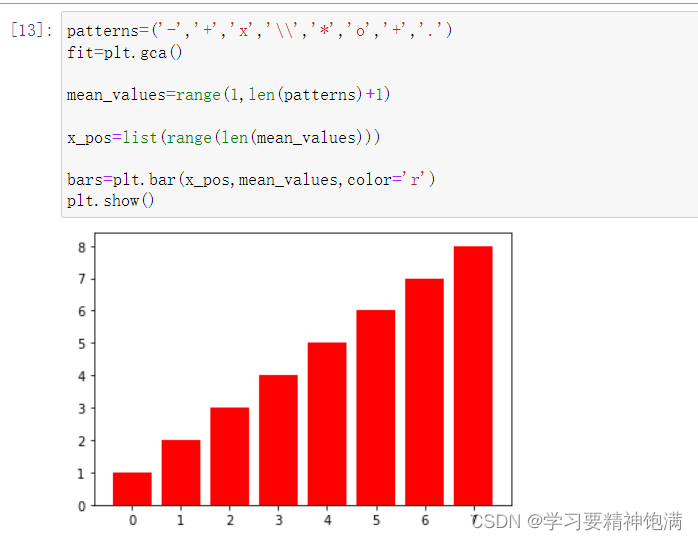
4.盒图
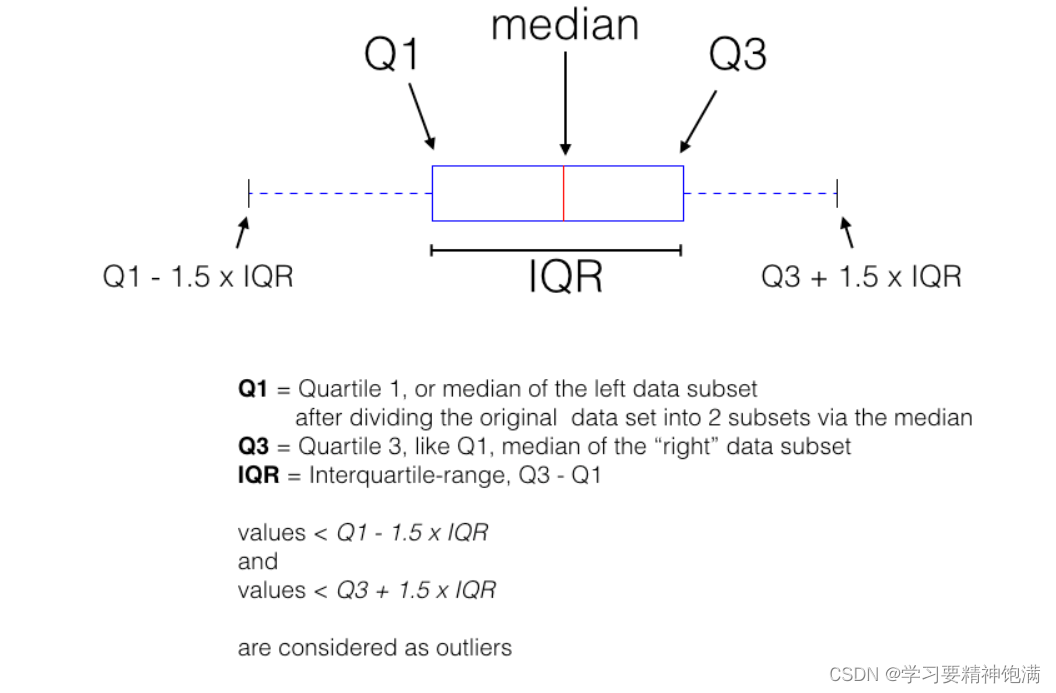
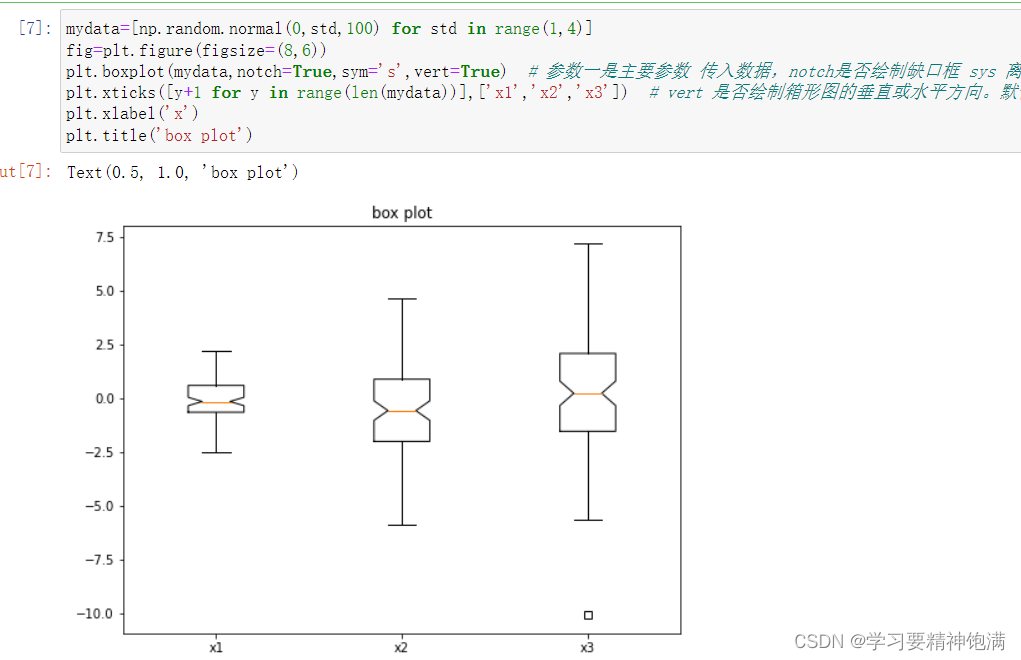
Q1 左半部分的中位数 Q3右半部分的中位数 中间是全体数据的中位数
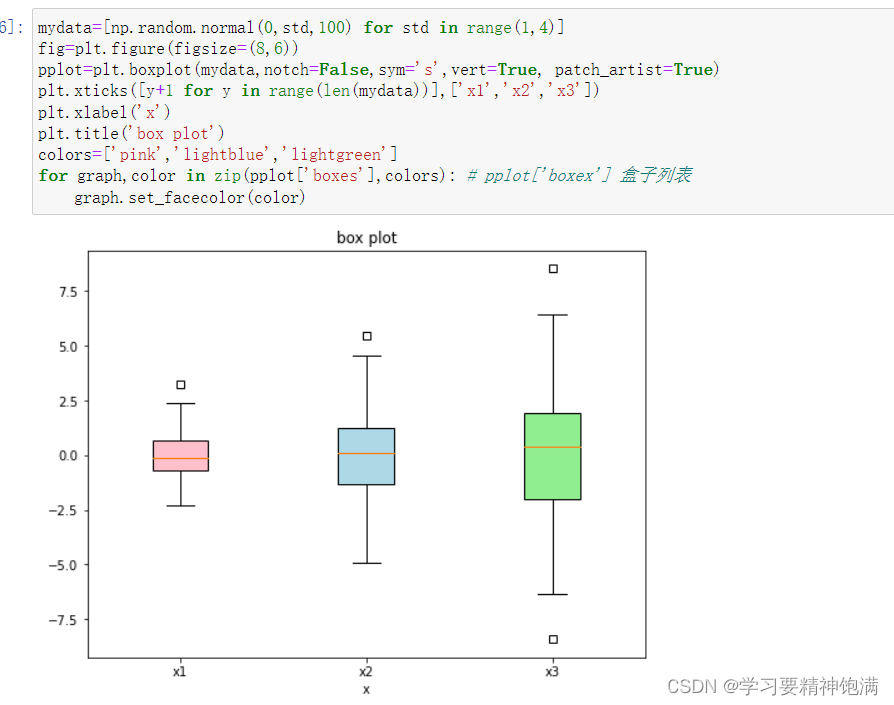
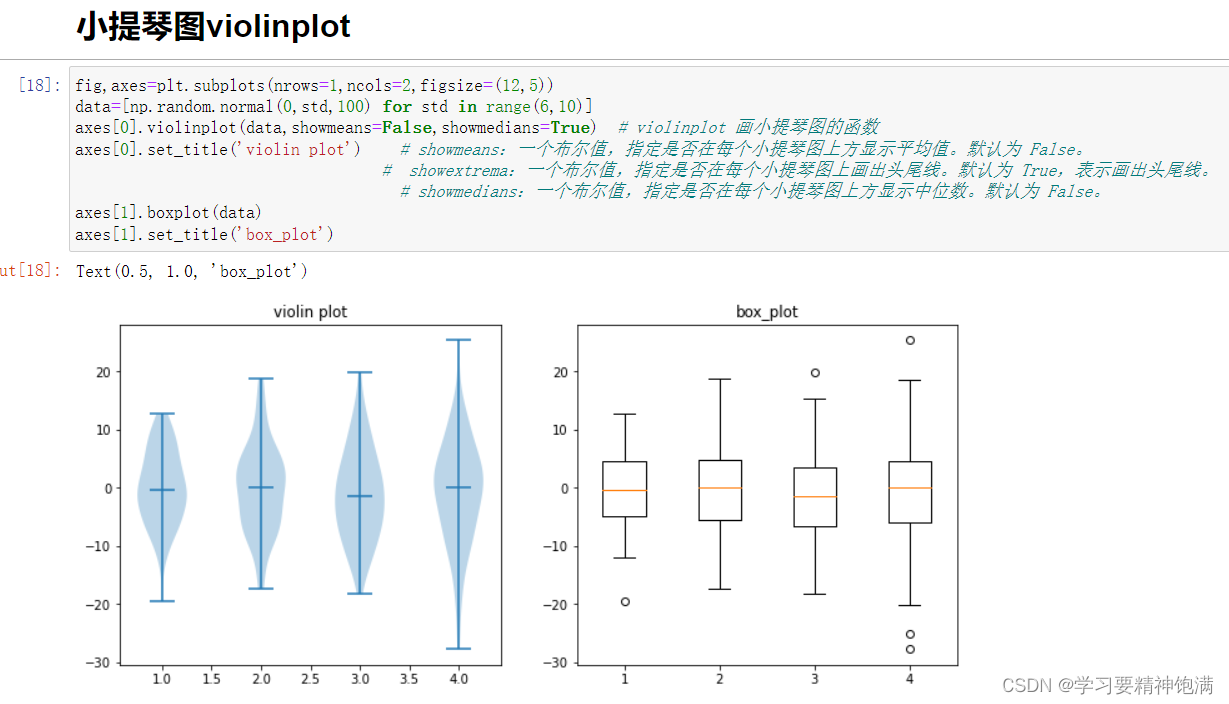
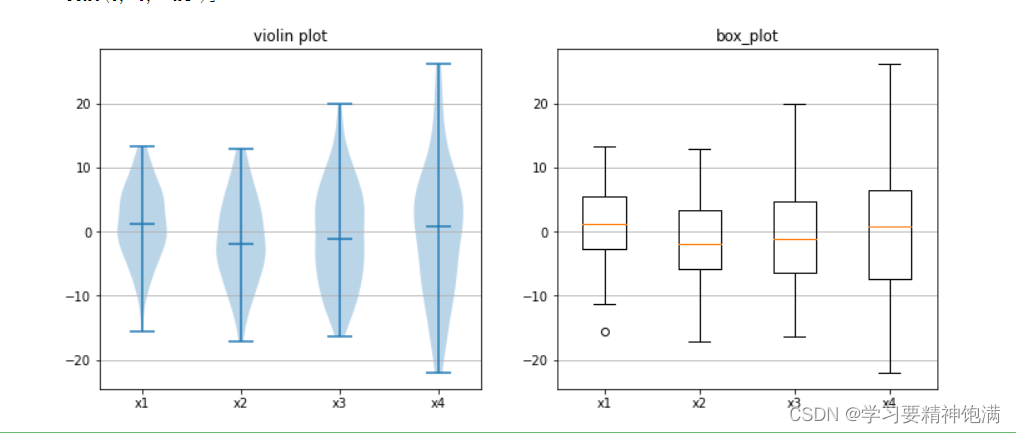
plt.boxplot 是 Matplotlib 库中用于绘制箱线图也即盒图的函数。 箱线图可以展示数据的主要统计特性,包括中位数、四分位数、最大最小值等, 可用于发现异常值或者检查数据的分布情况。
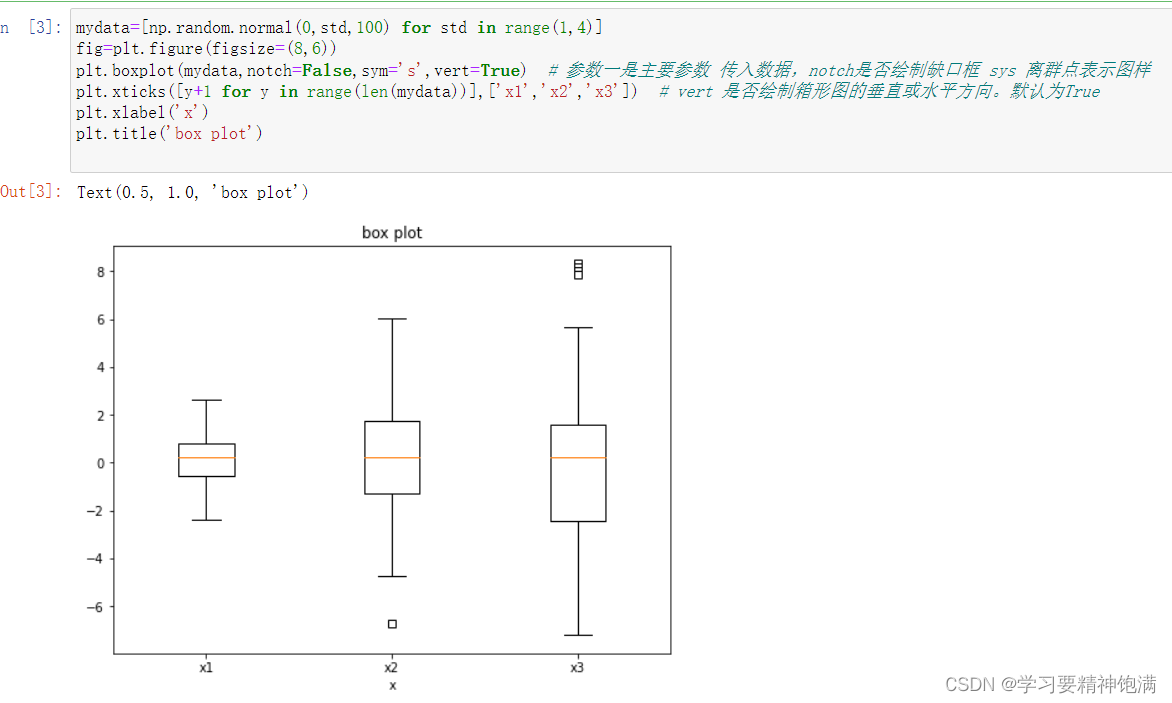
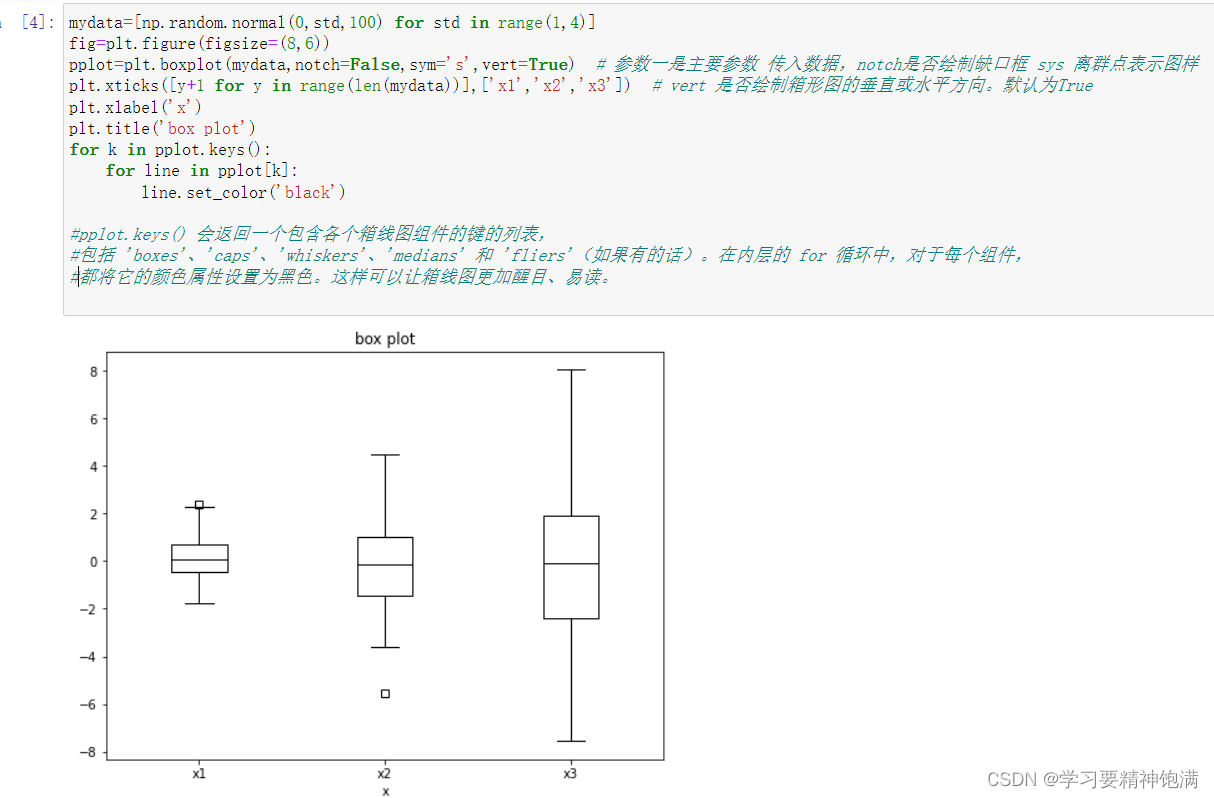
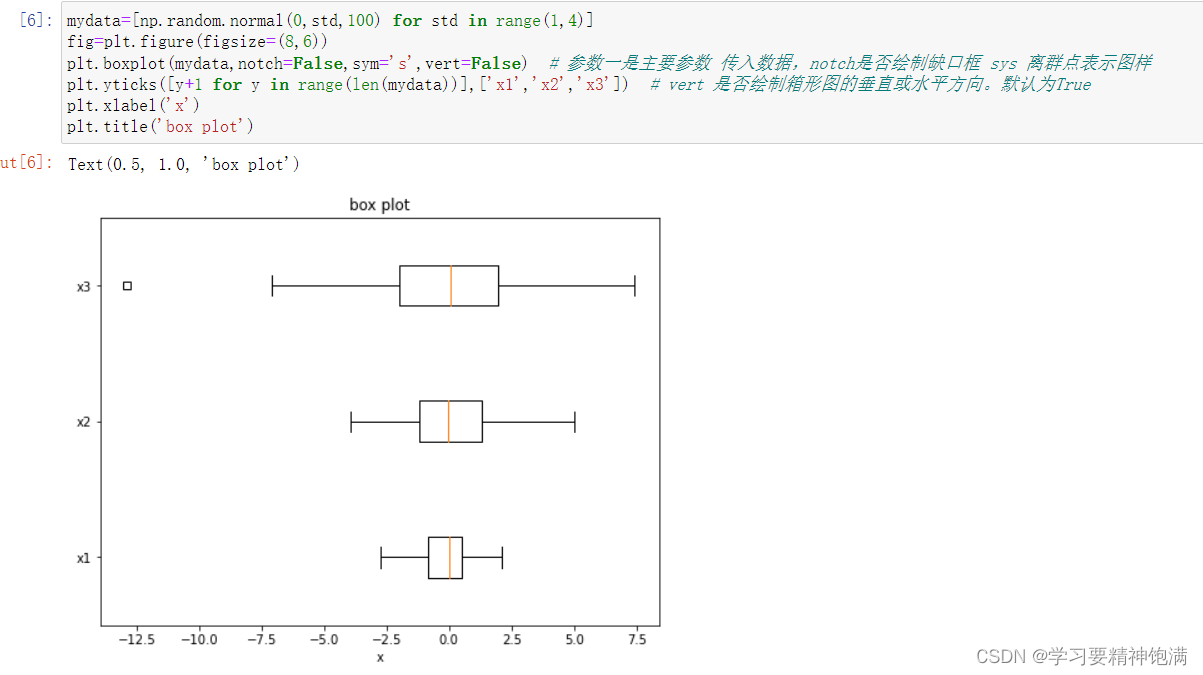

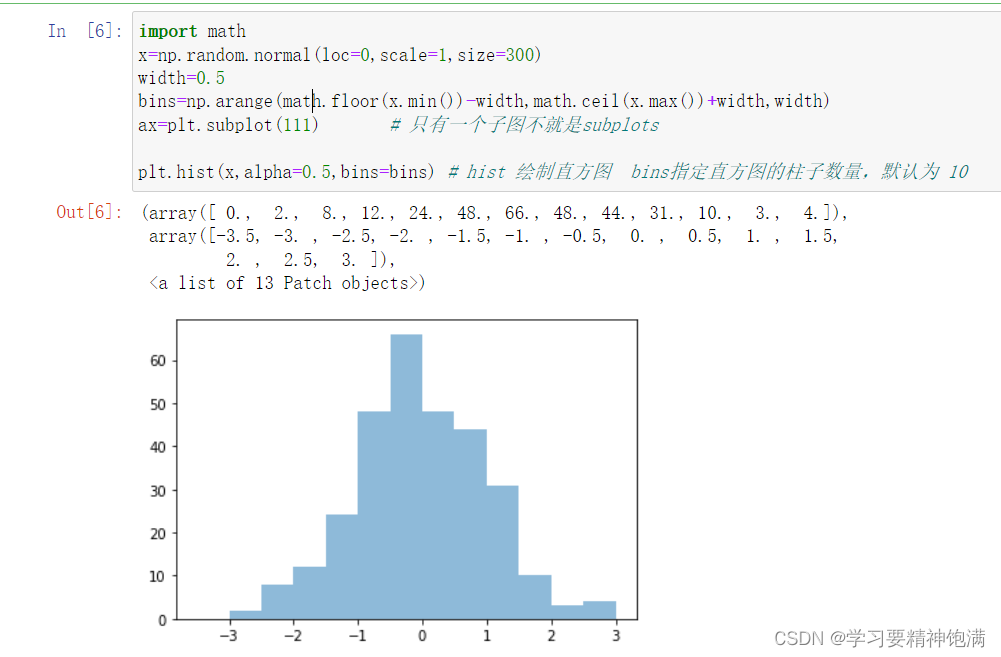
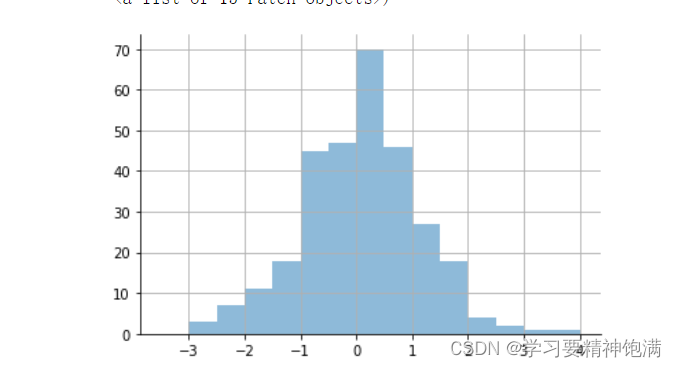
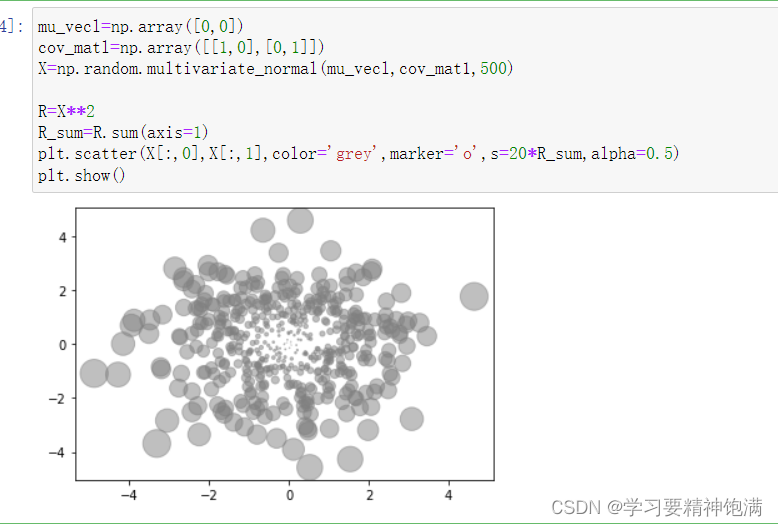
5.直方图和散点图
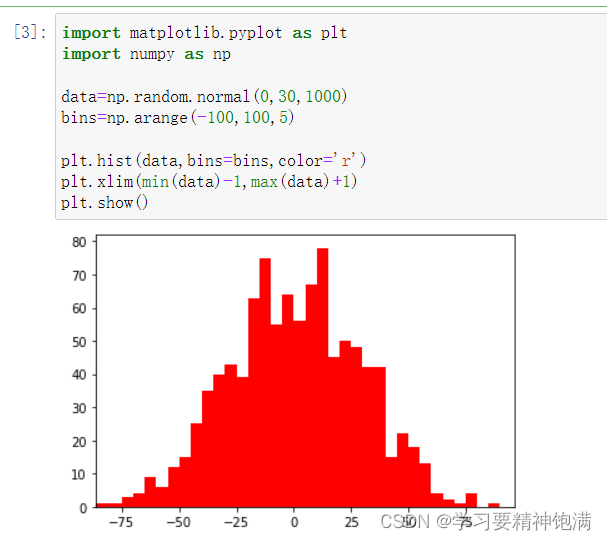
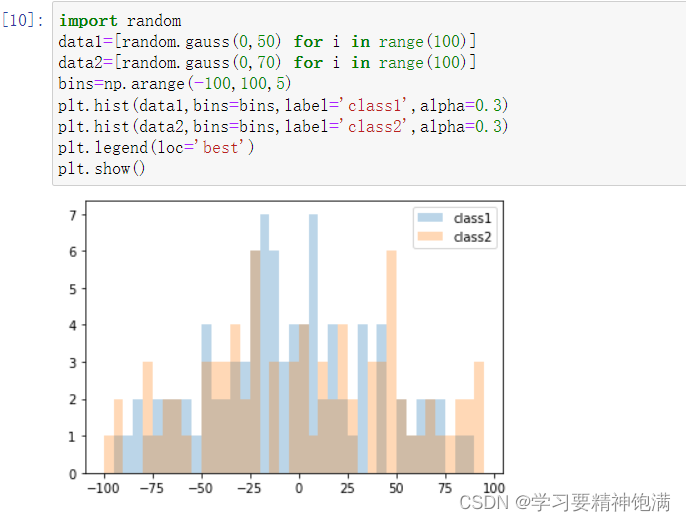
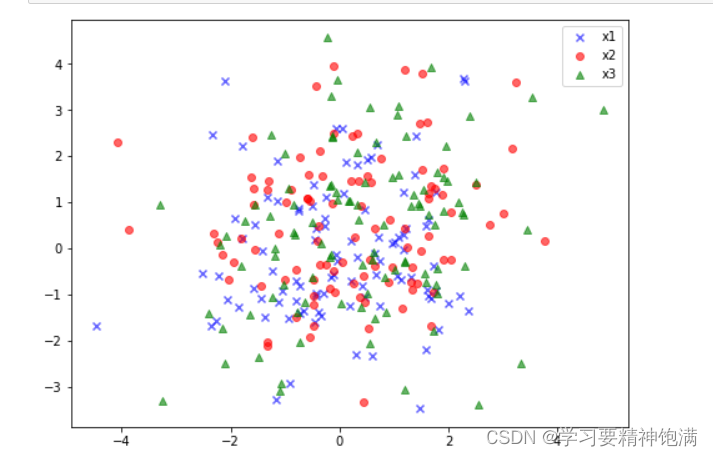
numpy.random.multivariate_normal() 函数返回一个二维的数组,
每一行表示一个二维多元正态分布随机数。如果参数 size 被指定了,则返回的数组维度为 (size, 2),其中第一列表示随机数在第一个维度上的取值,第二列表示随机数在第二个维度上的取值。如果 size 没有被指定,则返回一个长度为 2 的一维数组,第一个元素为第一个维度上的取值,第二个元素为第二个维度上的取值。


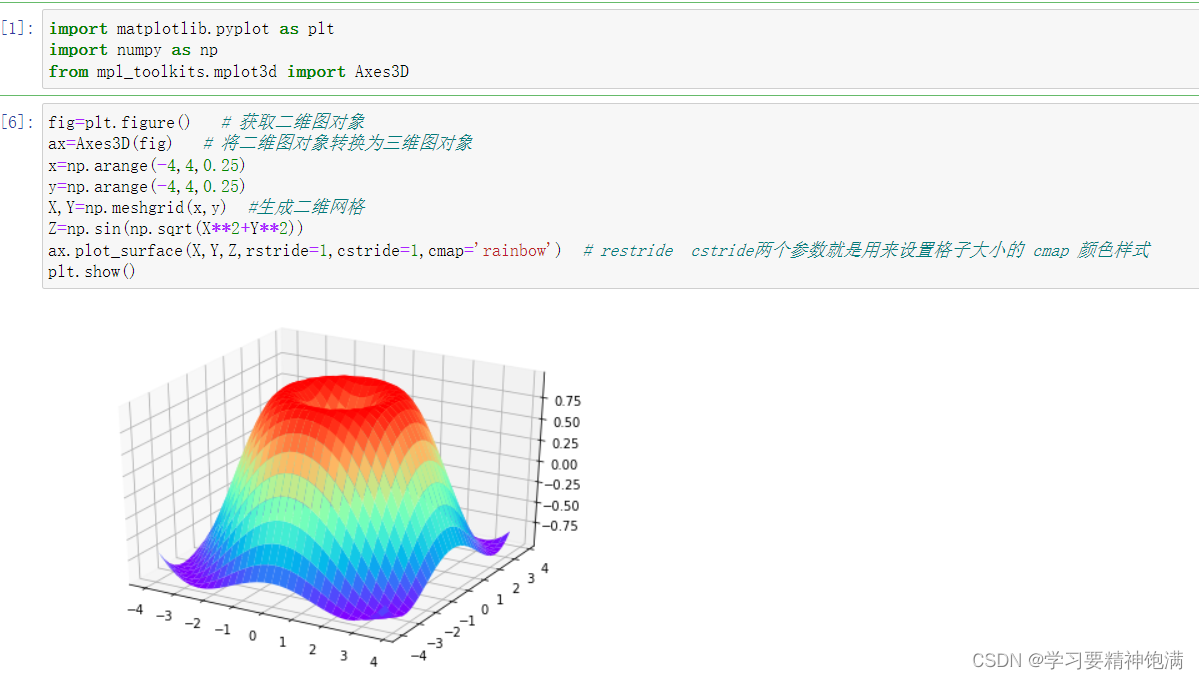
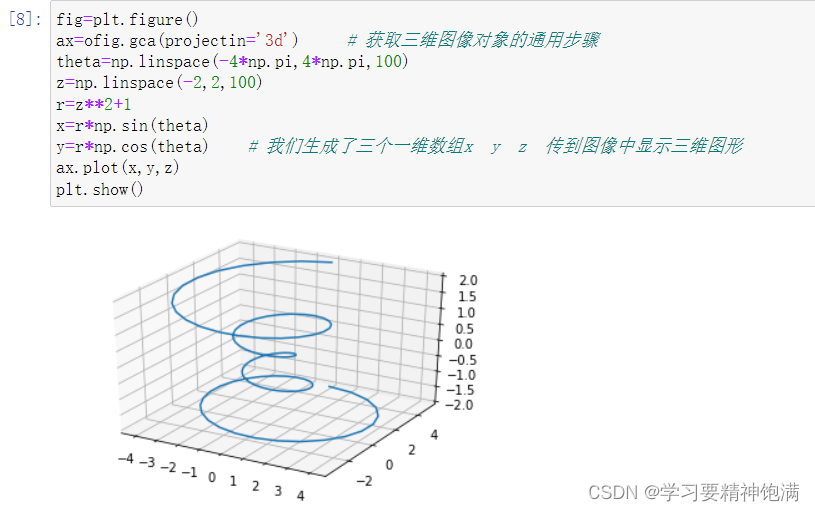
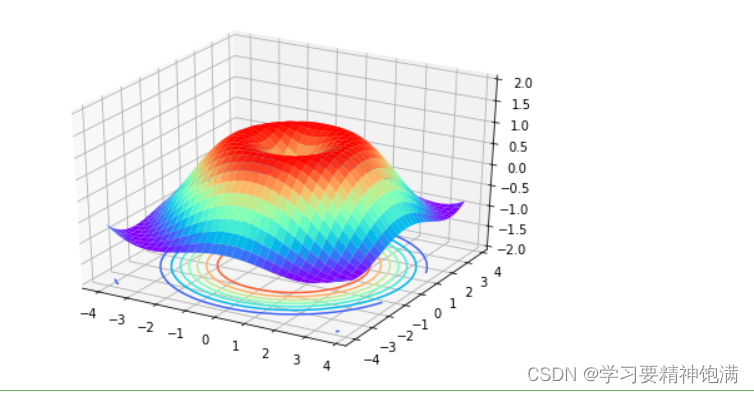
6.3D图
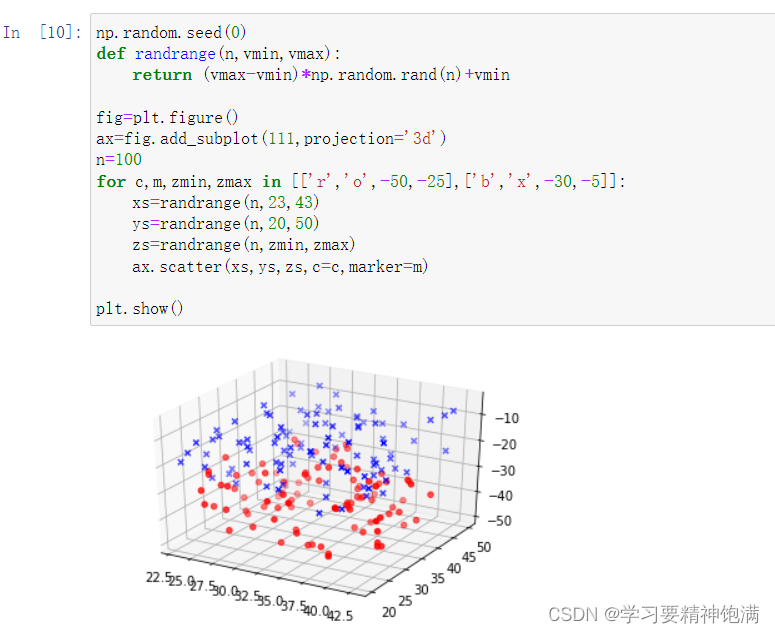
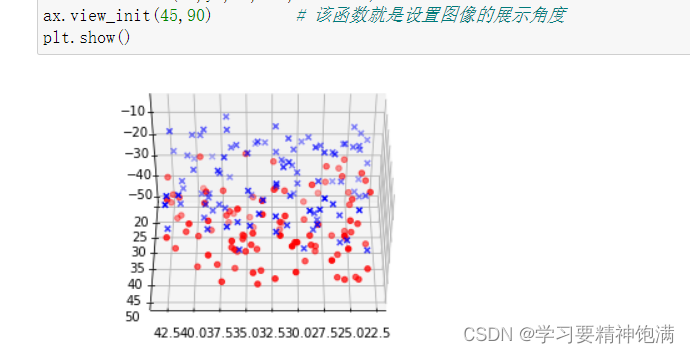
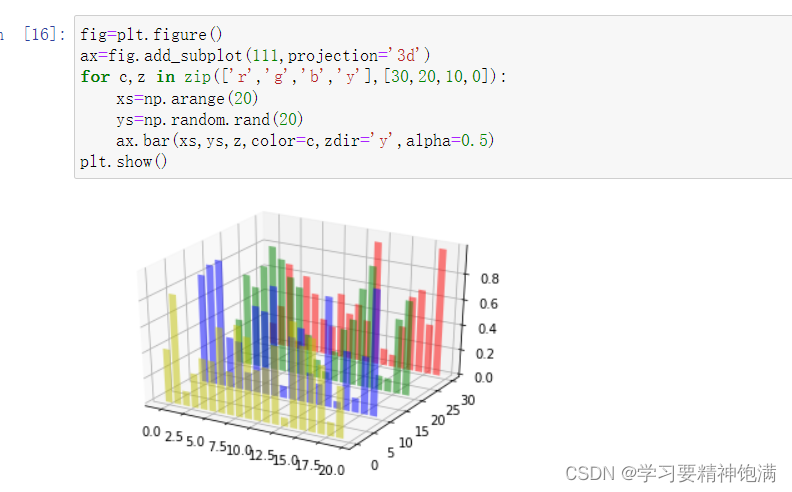
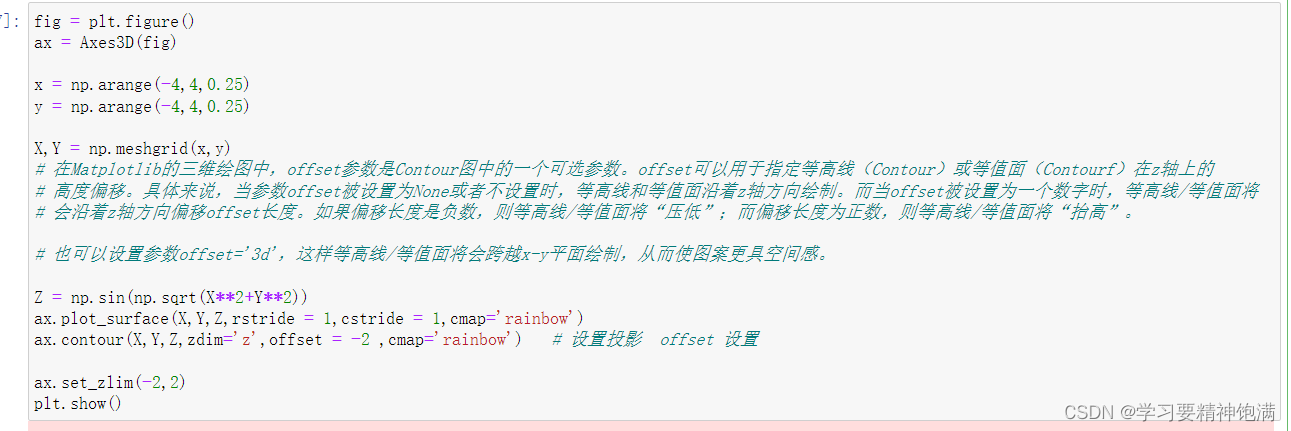
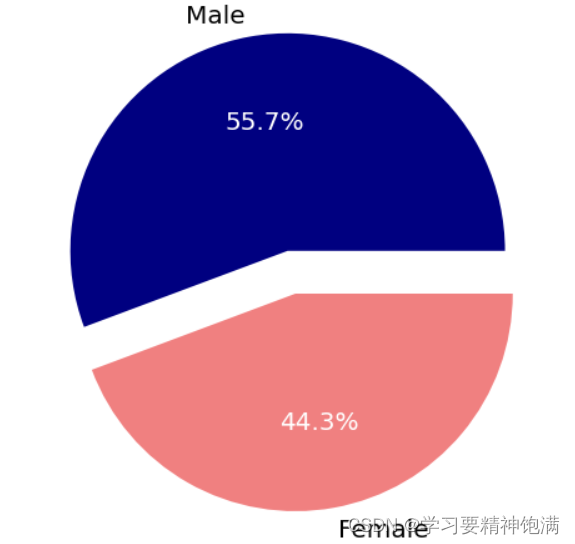
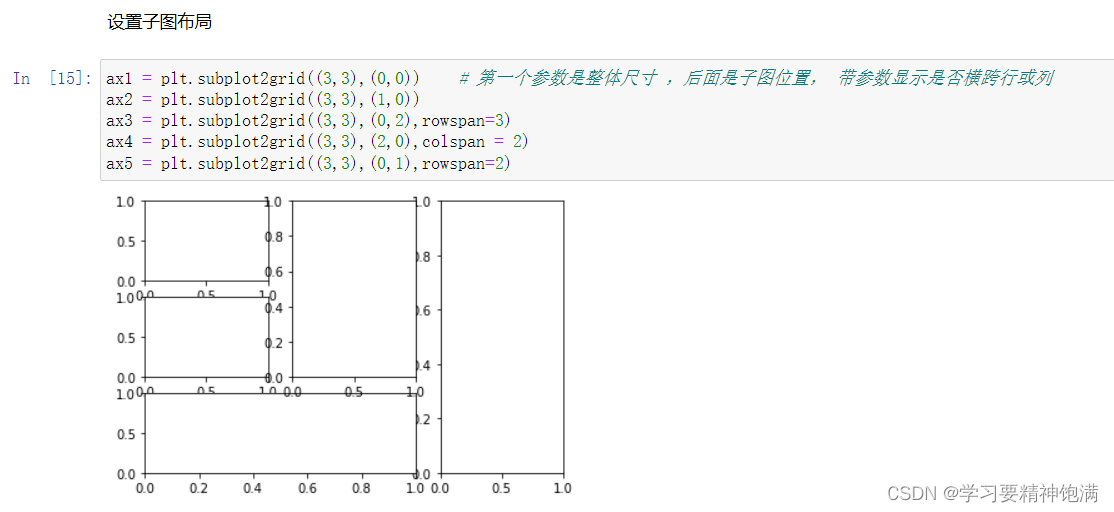
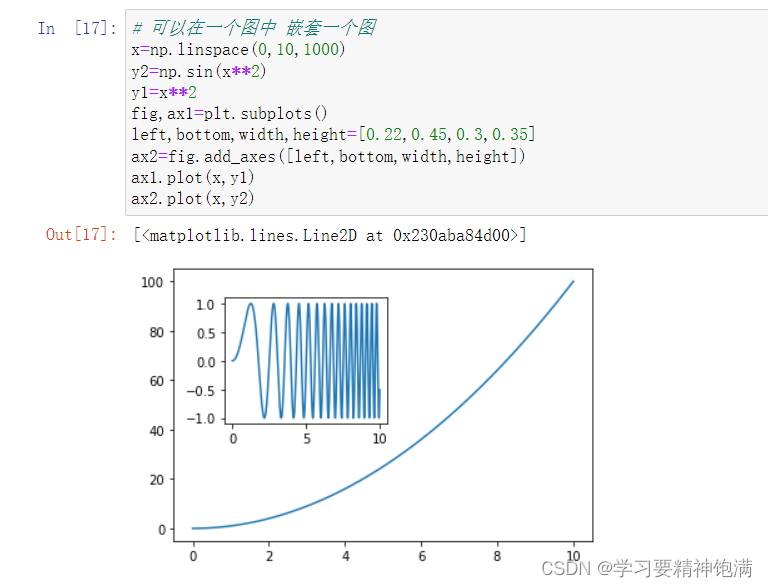
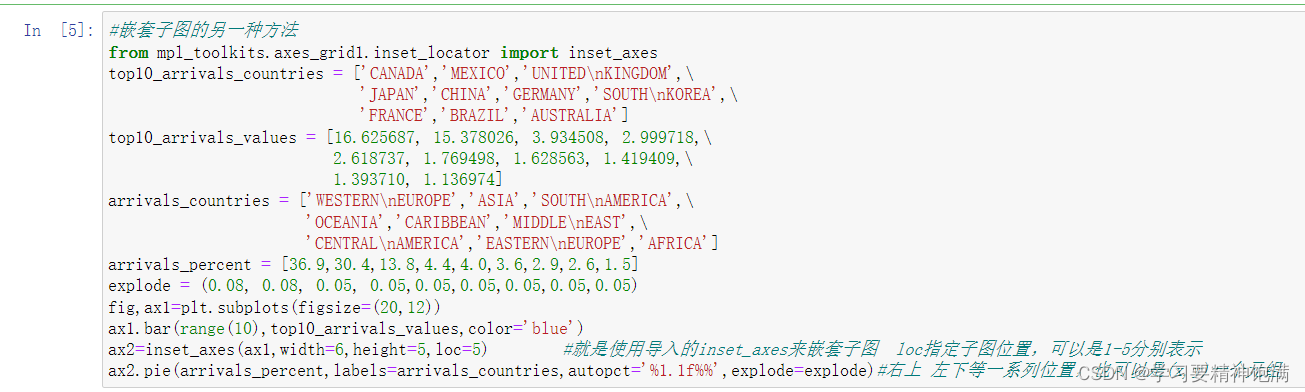
7.pie图和布局
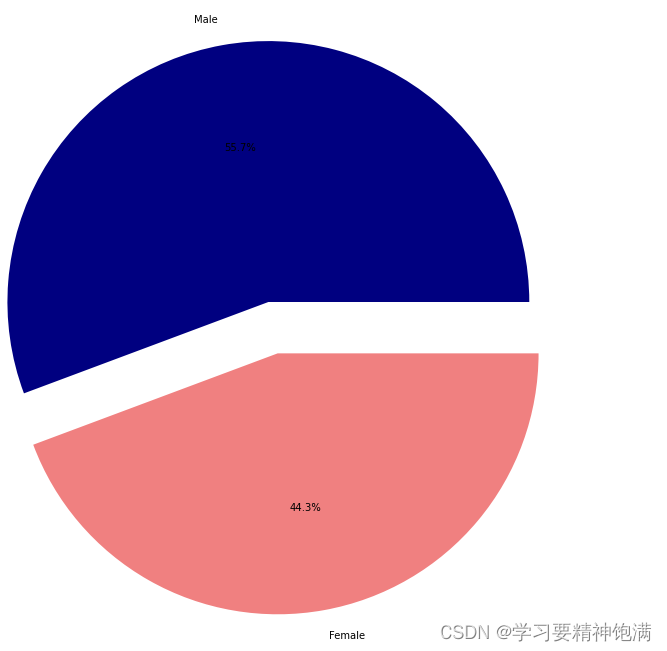
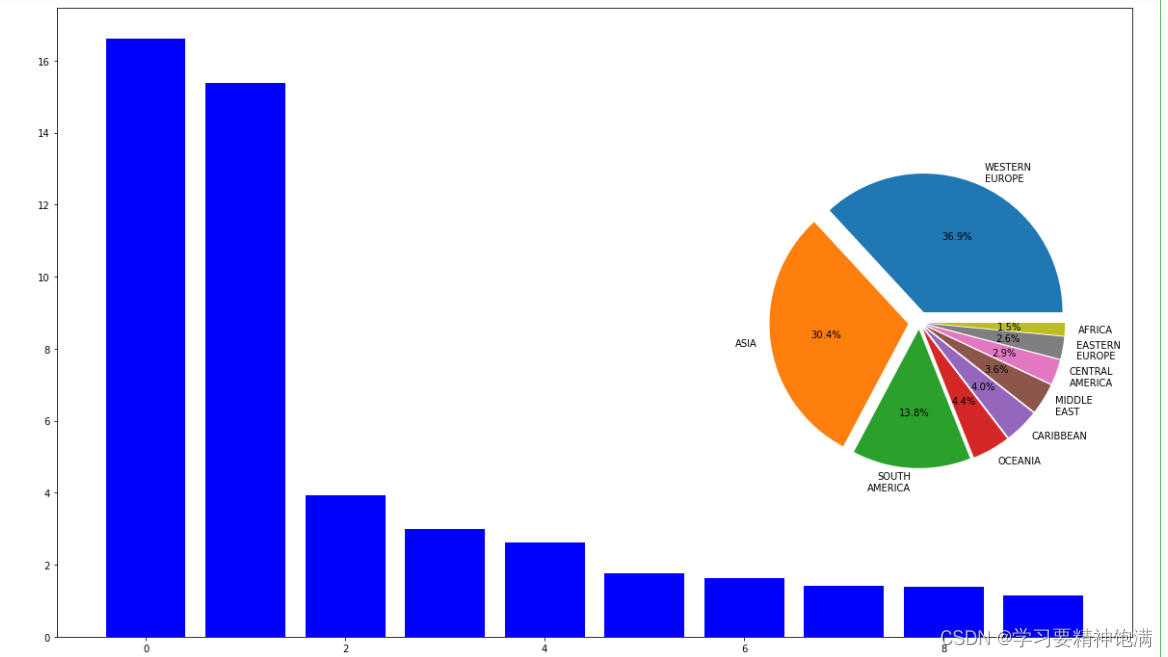
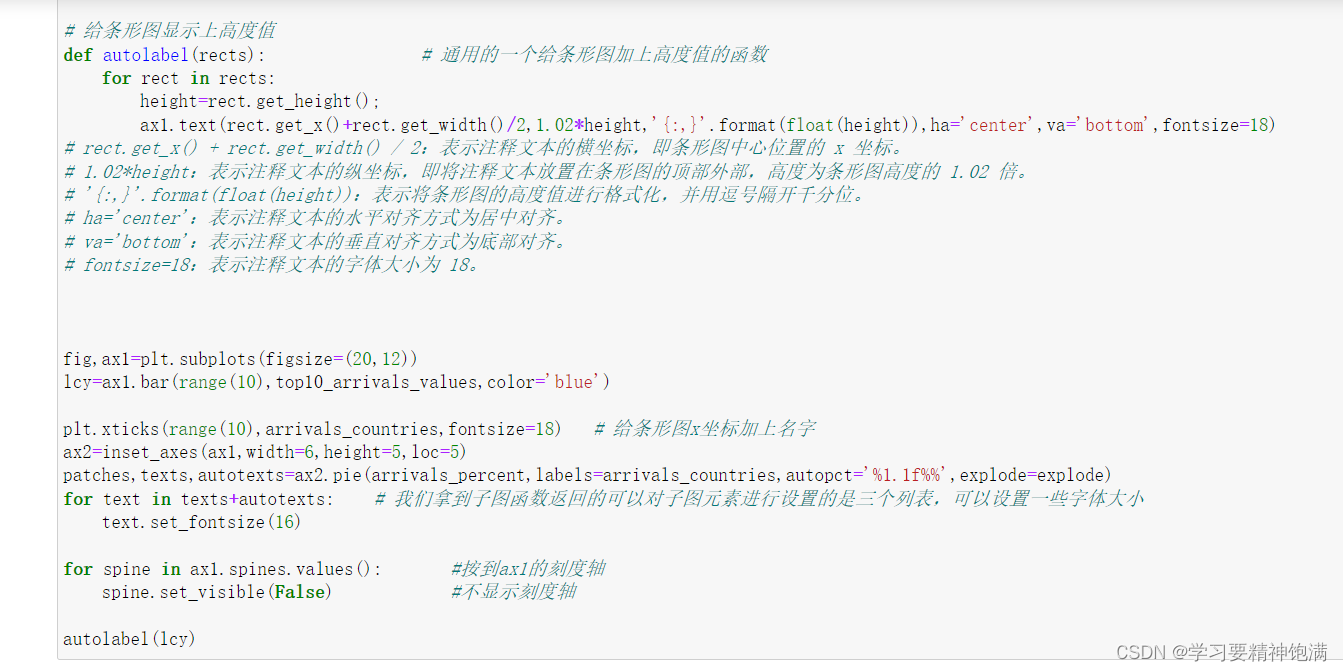
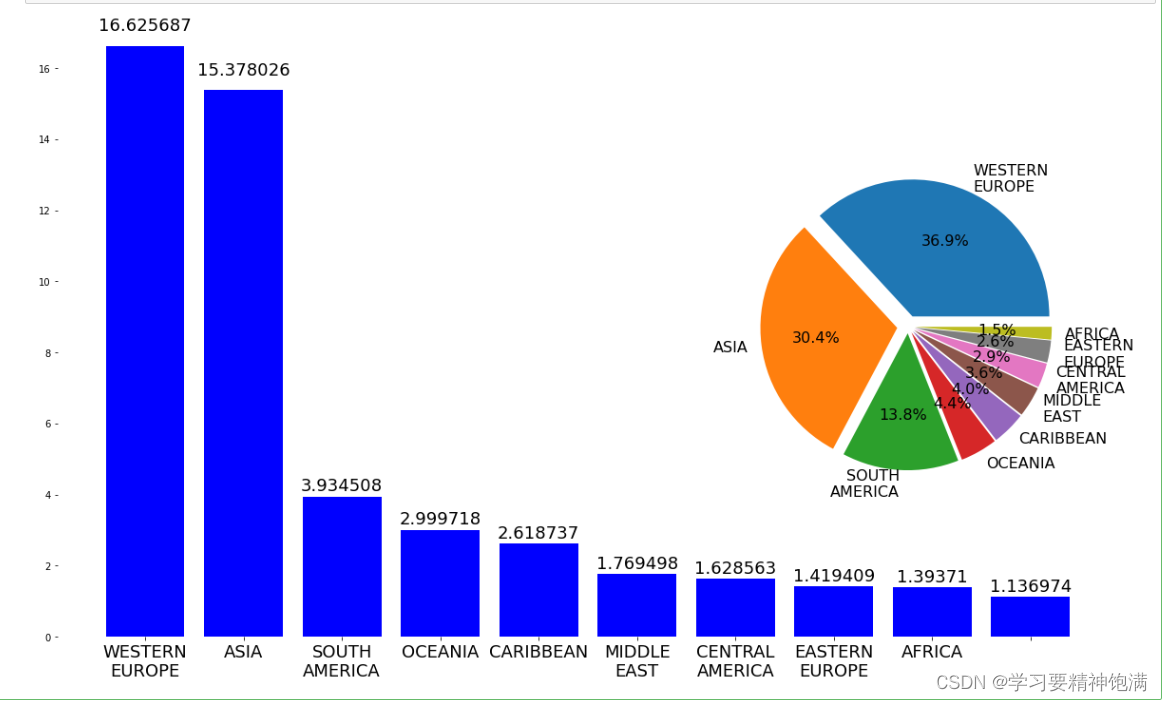
8.Pandas与sklearn结合实例
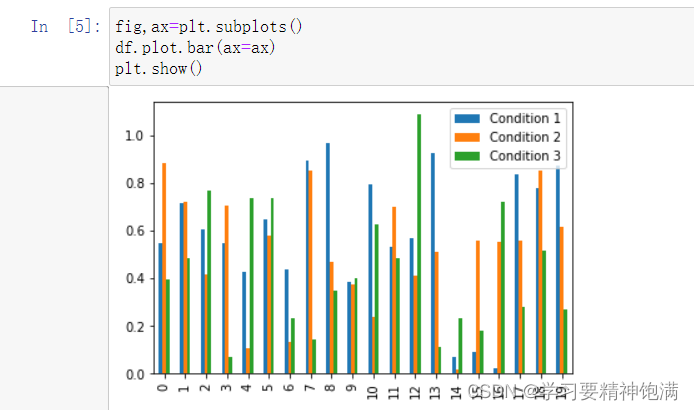
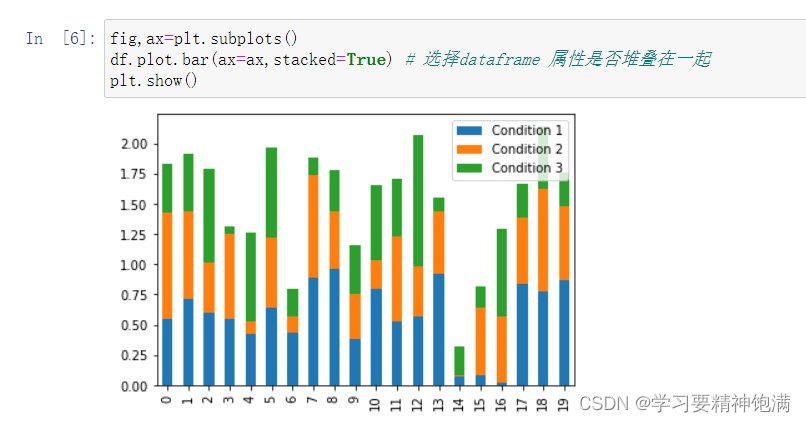
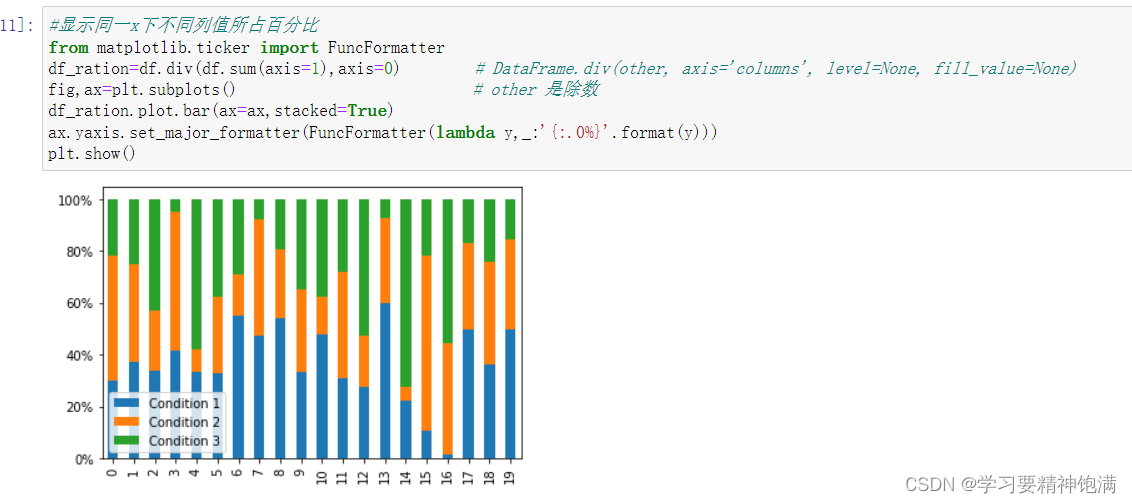
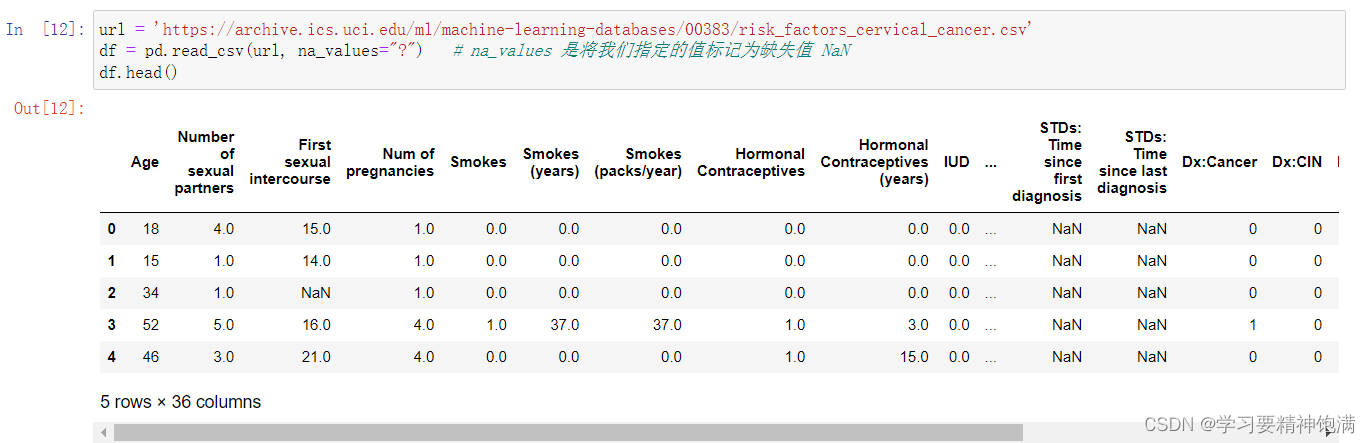
-
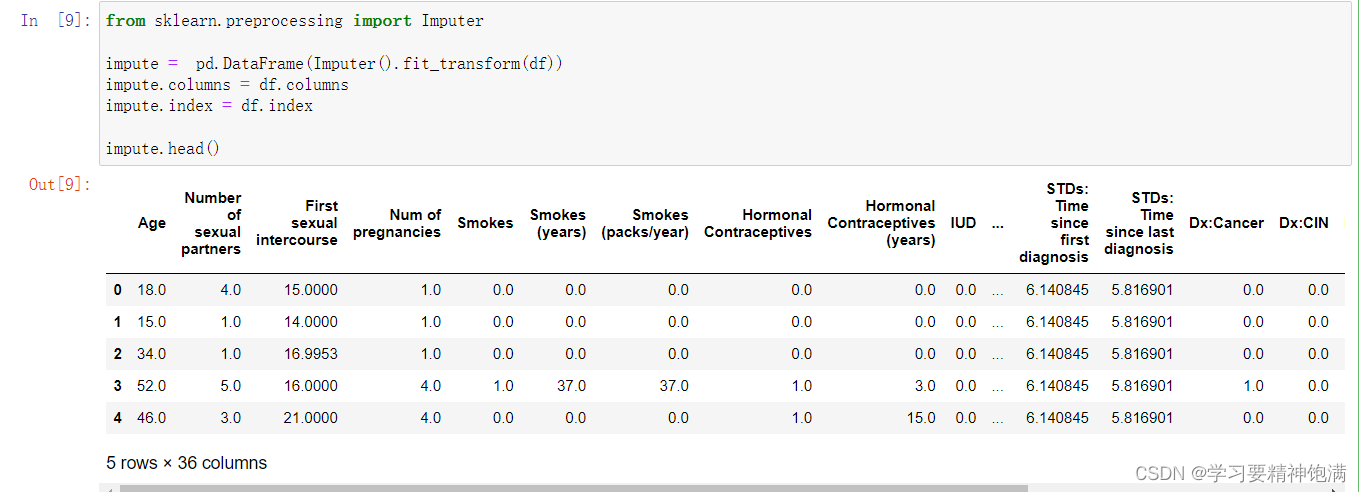
首先,通过 pd.read_csv() 函数从 url 中读取 csv 文件,并将其中的 “?” 值转换为 NaN 缺失值,得到一个名为 df 的数据框。然后,创建一个 Imputer 对象,并将其应用于 df 中,即 Imputer().fit_transform(df)。这个操作将会使用指定的方法对 df 中的缺失值进行填充,默认是使用平均值 mean。
-
这里的 fit_transform() 方法将会自动地修改缺失值,并返回填充好的数据。接着,将填充好的结果转换成一个新的数据框,并将其列名、索引与原来的 df 对齐。
-
Imputer 类只能对数值型数据进行填充。如果数据中包含其他类型的数据,在使用 Imputer 之前需要先使用相应的方法进行数据转换。
-
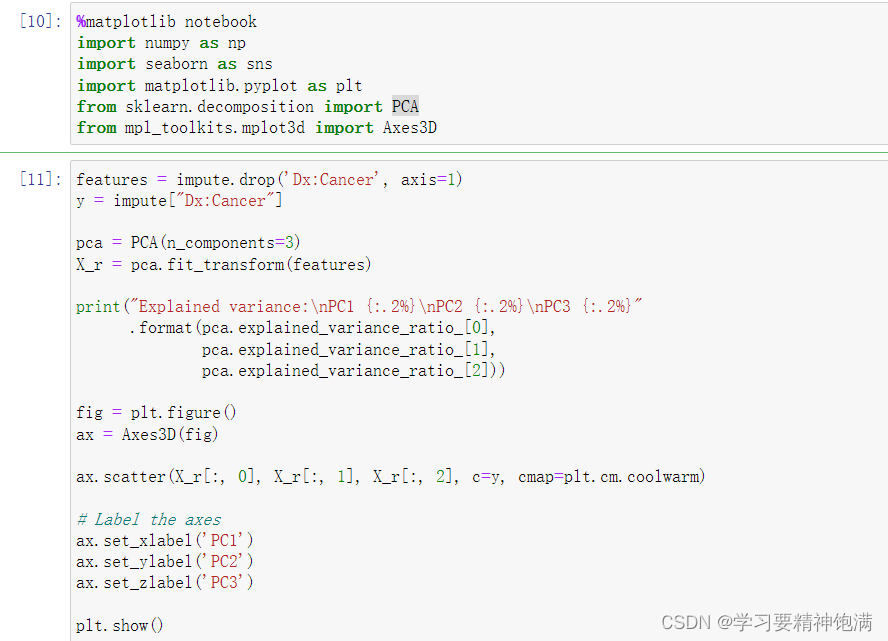
首先,从填充好缺失值的 impute 数据框中删除了名为 “Dx:Cancer” 的列,得到一个新的数据框 features,用来存储所有特征。此外,还将原数据框中的名为 “Dx:Cancer” 的列单独拿出来,存储在变量 y 中,用来存储分类目标变量。接着,使用 PCA 主成分分析将 features 数据框中的所有特征降维到了三维空间,得到降维后的数据 X_r。
-
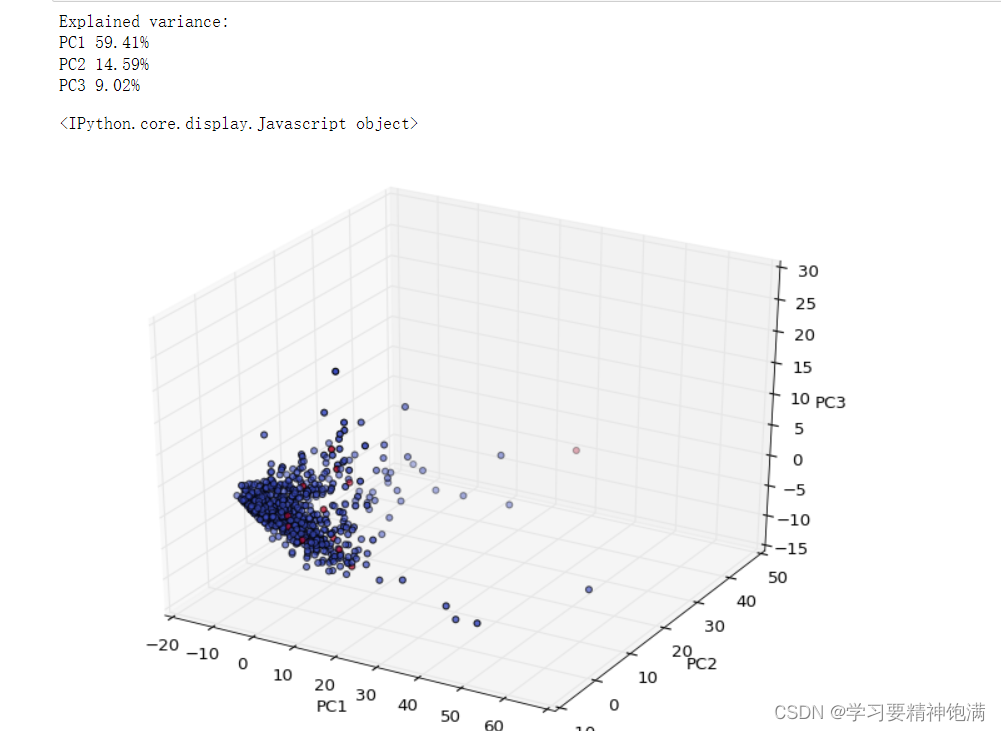
然后,使用 pca.explained_variance_ratio_ 查看了每个主成分所能解释的方差比例,分别对应第一、第二、第三个主成分。结果显示第一个主成分可以解释数据集的 38% 的方差,第二个主成分可以解释 23% 的方差,第三个主成分可以解释 14% 的方差,共计解释了 75% 的方差。
-
最后,使用 Axes3D() 函数创建了一个三维坐标系对象,并通过 ax.scatter() 函数以 X_r 中的三个主成分为坐标,使用分类目标变量 y 来为点着色,并将结果可视化展示出来。