文章目录
- 1. 使用
- 1. unordered_set的使用
- 2. unordered_map的使用
- 2. 封装
- 修改结构定义
- 针对insert参数 data的两种情况
- 复用 哈希桶的insert
- KeyOfT模板参数的作用
- 迭代器
- operator++()
- begin
- end
- unordered_set对于 begin和end的复用
- unordered_map对于 begin和end的复用
- unordered_map中operator[]的实现
- unordered_set修改迭代器数据 问题
- 完整代码
- HashTable.h
- unordered_set.h
- unordered_map.h
1. 使用
unordered_map官方文档
unordered_set 官方文档
set / map与unordered_set / unordered_map 使用功能基本相同,但是两者的底层结构不同
set/map底层是红黑树
unordered_map/unordered_set 底层是 哈希表
红黑树是一种搜索二叉树,搜索二叉树又称为排序二叉树,所以迭代器遍历是有序的
而哈希表对应的迭代器遍历是无序的

在map中存在rbegin以及rend的反向迭代器

在unordered_map中不存在rbegin以及rend的反向迭代器
1. unordered_set的使用
大部分功能与set基本相同,要注意的是使用unordered_set是无序的

插入数据,并使用迭代器打印,会按照插入的顺序输出,但若插入的数据已经存在,则会插入失败
2. unordered_map的使用
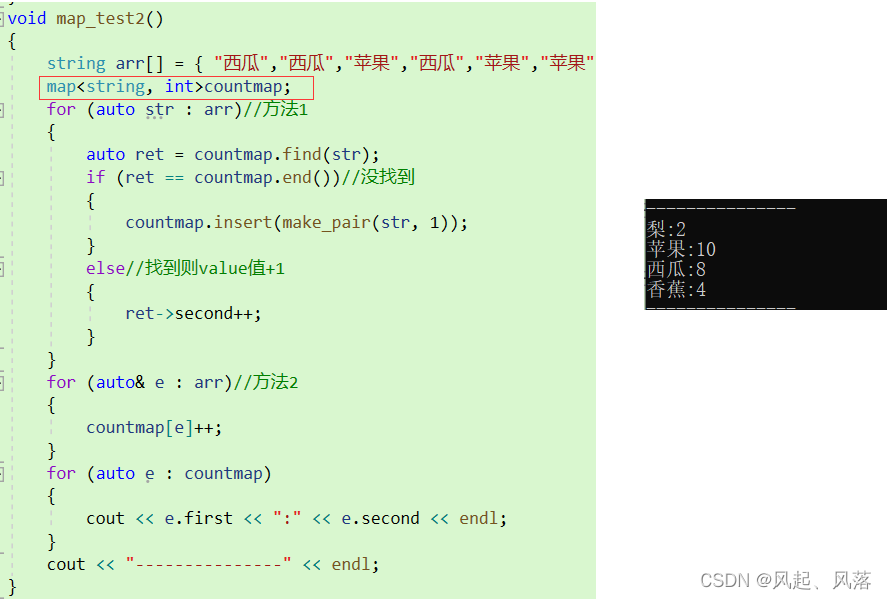
map统计时,会按照ASCII值排序

而unordered_map 中 元素是无序的
2. 封装
对于 unordered_set 和 unordered_map 的封装 是针对于 哈希桶HashBucket进行的,
即 在哈希开散列 的基础上修改
点击查看:哈希 开散列具体实现
修改结构定义
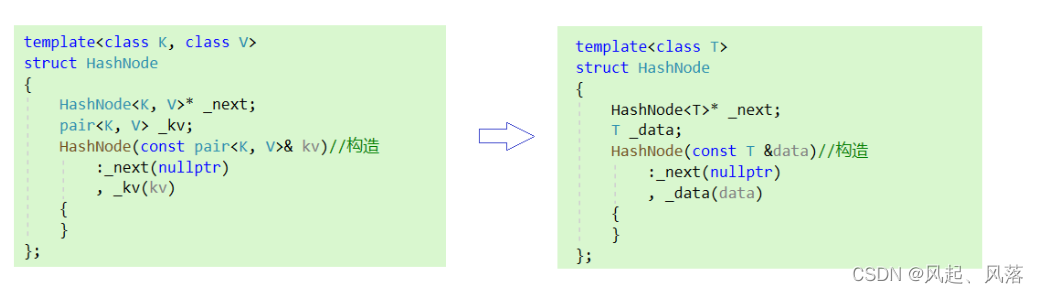
哈希桶HashBucket中
需要将其内部的HashNode 的参数进行修改
将原来的模板参数 K,V 改为 T
同样由于不知道传入数据的是K还是K V类型的 ,所以 使用 T 类型的data代替

之前实现的模板参数 K ,V分别代表 key 与value
修改后 , 第一个参数 拿到单独的K类型,是为了 使用 Find erase接口函数的参数为K
第二个参数 T 决定了 拿到的是K类型 还是 K V 类型
针对insert参数 data的两种情况

创建 unordered_set.h头文件,在其中创建命名空间unordered_set
在unordered_set中实现一个仿函数,
unordered_set 的第二个参数 为 K
unordered_set作为 K 模型 ,所以 T应传入K

创建 unordered_map.h头文件,在其中创建命名空间unordered_map
unordered_map 的第二个参数 为 pair<cosnt K,V> 类型
K加入const ,是为了防止修改key
unordered_map 作为 KV 模型 ,所以 T应传入 pair<K,V>
复用 哈希桶的insert

在unordered_set中insert 是 复用HashTable中的insert
但实际上直接运行就会出现一大堆错误,哈希桶的insert 原本参数从kv变为 data,
由于data的类型为T,也就不知道 到底是unoreder_set 的K还是 unoreder_map 的KV类型的K
所以 insert中的 hashi的 key 不能够直接求出
KeyOfT模板参数的作用

假设为unordered_set,则使用kot对象调用operator(),返回的是key

假设为unordered_map,则使用kot对象调用operator(),返回的是KV模型中的key
迭代器
在迭代器内存存储 节点的指针 以及 哈希表
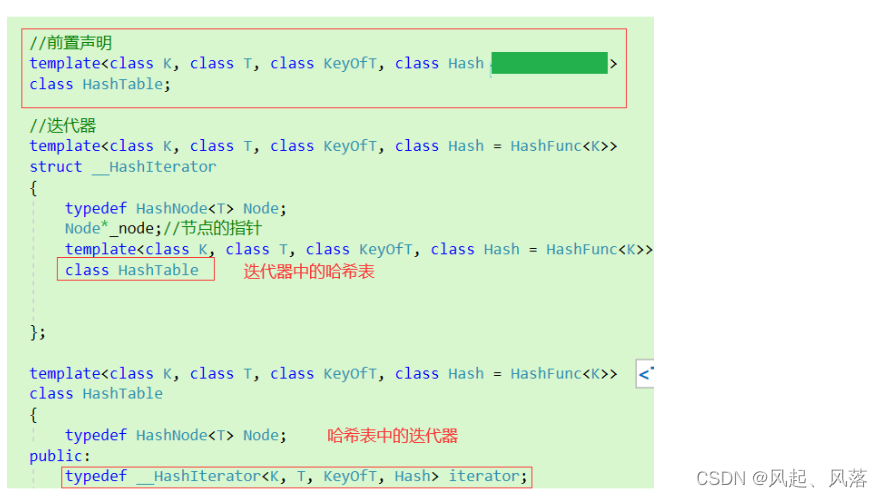
在迭代器中使用哈希表,在哈希表中使用迭代器 ,存在互相引用,需要使用前置声明

对于 operator * / operator-> / operator!= 跟 list 模拟实现基本类似
详细点击查看:list模拟实现
在自己实现的迭代器__HashIterator中,添加参数 Ref 和 Ptr

当为普通迭代器时,Ref作为T& ,Ptr作为T*
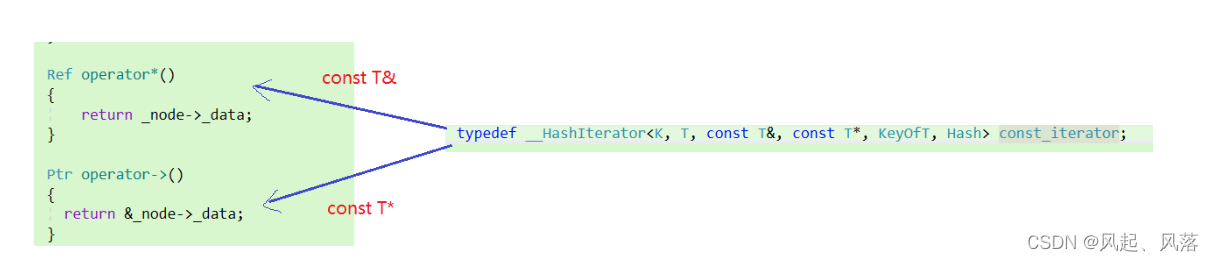
当为const 迭代器时,Ref作为const T& ,Ptr作为const T*
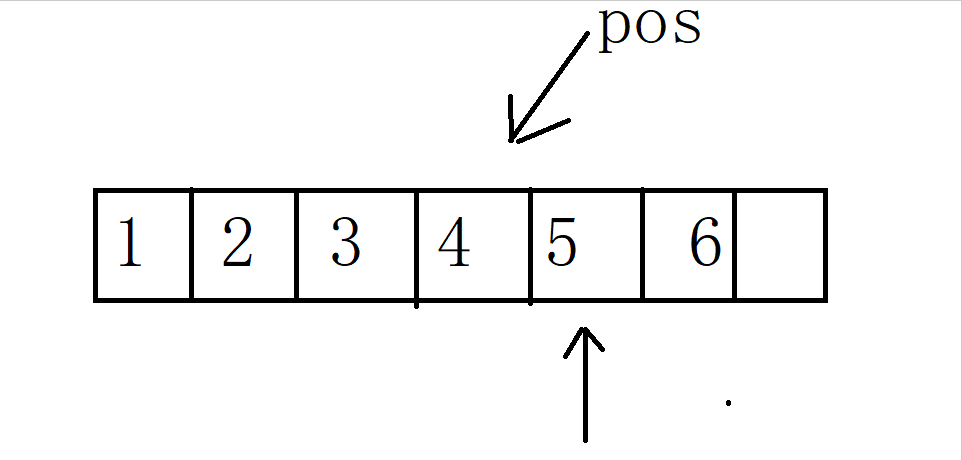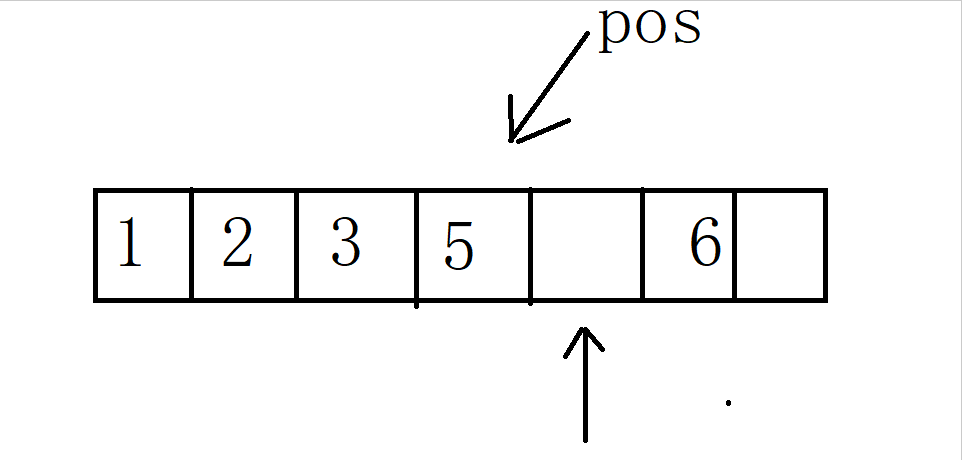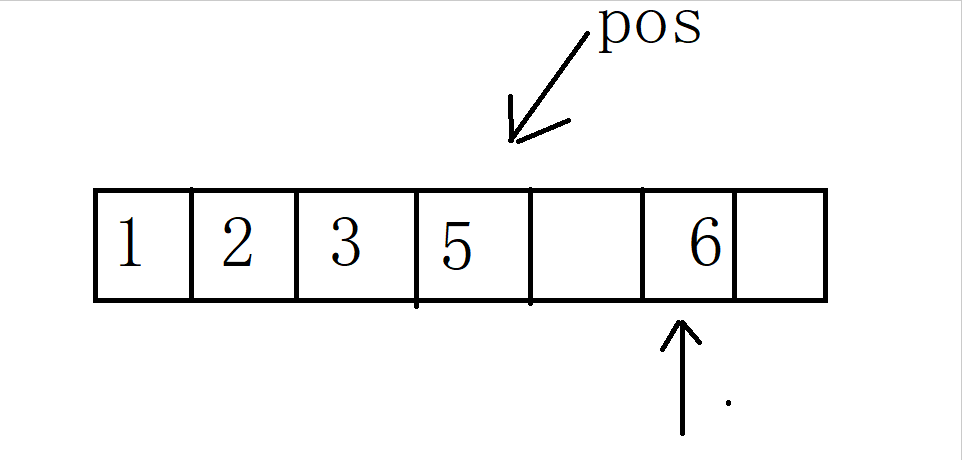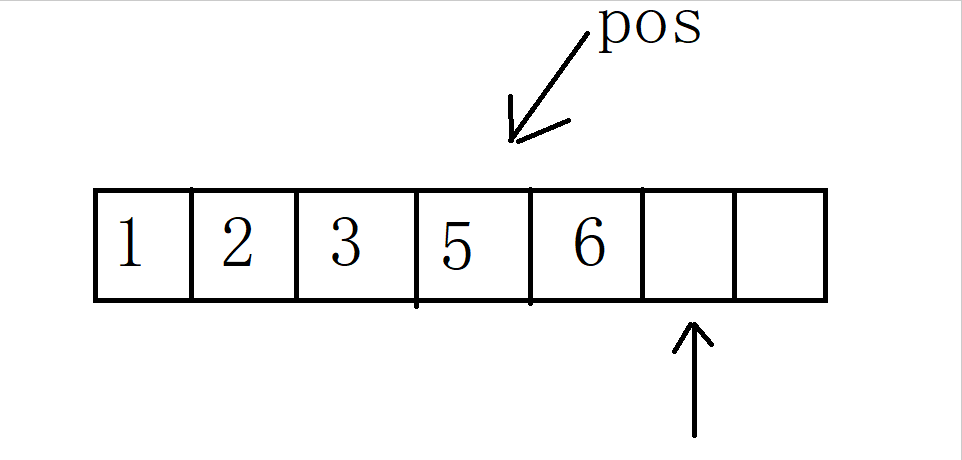
operator++()

调用 hash调用对应的仿函数HashFunc,若为普通类型(int)则输出对应key
若为 string类型,则调用特化,输出对应的各个字符累加的ASCII值
调用 KeyOfT ,主要区分unordered_map 与unordered_set ,
若为unordered_set ,则输出 K类型的K
若为unordered_map ,则输出 KV类型的K
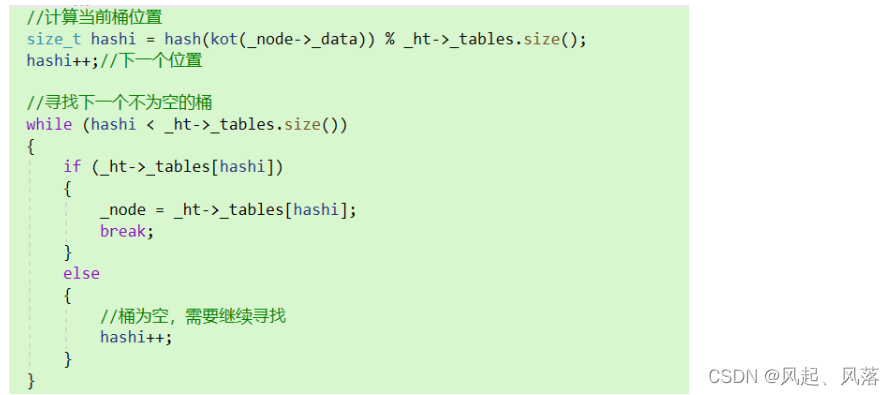
hashi++,计算下一个桶的位置,判断是否为空,若不为空则将其作为_node
若为空,需要继续寻找不为空的桶

begin

在HashTable内部实现 begin,使用自己实现的_hashiterator 作为迭代器
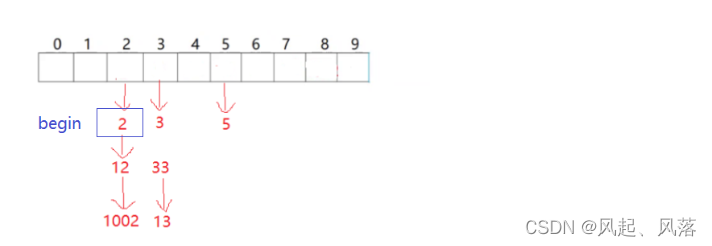
返回第一个不为空的桶的第一个数据
c
end
在HashTable内部实现 end
返回最后一个桶的下一个位置 即nullptr

unordered_set对于 begin和end的复用
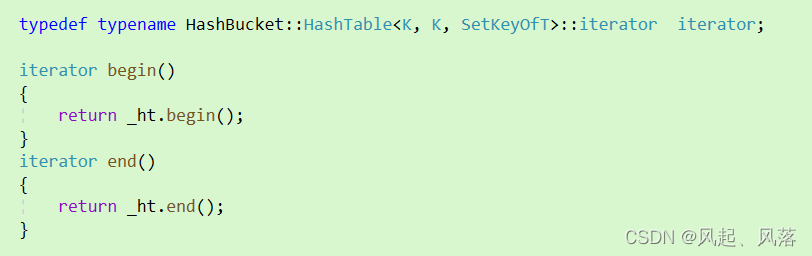
在unordered_set中,使用哈希桶中的HashTable的迭代器 来实现unordered_set的迭代器
加入typename 是因为编译器无法识别HashBucket::HashTable<K, K, SetKeyOfT>是静态变量还是类型
_ht作为哈希表,使其调用哈希表中的begin和end 来实现 unordered_set的begin 和end
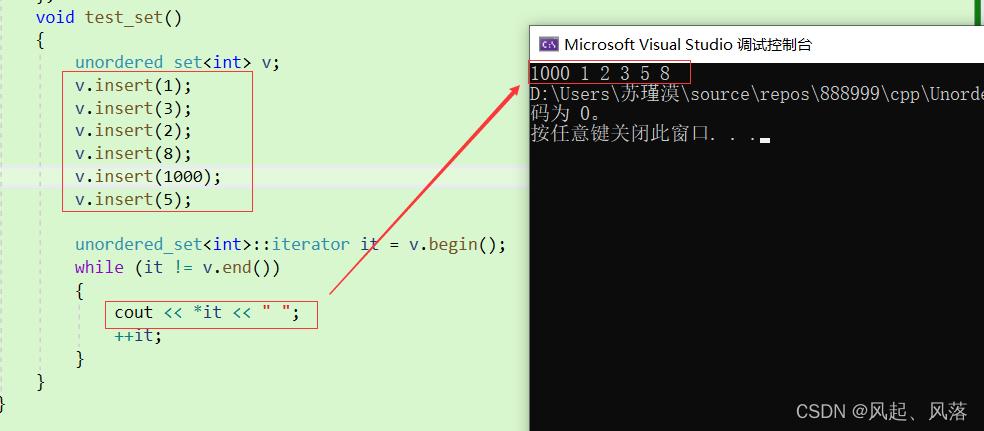
unordered_map对于 begin和end的复用
在 unordered_map中使用哈希桶中的HashTable的迭代器 来实现unordered_map的迭代器

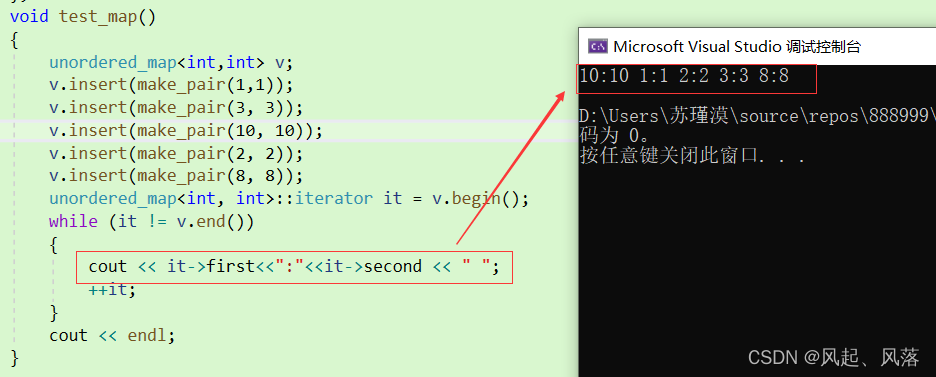
unordered_map中operator[]的实现

将insert的返回值 变为pair类型,第一个参数为迭代器 ,第二个参数为布尔值
若返回成功,则调用新插入位置的迭代器

通过寻找哈希桶中是否有相同的数据,若有则返回该迭代器以及false
在unordered_map中实现operator[]

详细查看:operaor[]本质理解
unordered_set修改迭代器数据 问题

在unordered_set中,借助 哈希桶中的普通迭代器 实现 unordered_set的普通迭代器
在unordered_set中,借助 哈希桶中的const迭代器 实现 unordered_set的const迭代器
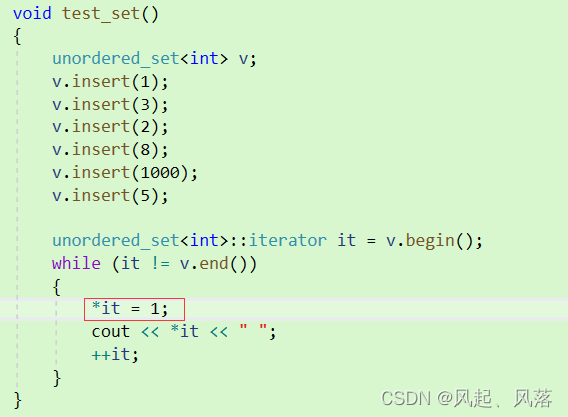
在STL中,是不允许 unordered_set去 *it 修改数据的 ,但是在自己实现的迭代器中却可以通过

在STL中将 unordered_set的普通迭代器也为哈希桶的const 迭代器

调用begin时,虽然看似返回普通迭代器,但是当前普通迭代器是作为哈希桶的const迭代器存在的
而返回值依旧是 哈希桶的普通迭代器
在哈希桶自己实现的迭代器__HashIterator中

创建一个普通迭代器 ,当传入普通迭代器时,为拷贝构造
当传入 const 迭代器时,就 发生隐式类型转换,讲普通迭代器转换为const 迭代器

此时在unordered_set中 的普通迭代器无法被修改
完整代码
HashTable.h
#include<iostream>
#include<vector>
using namespace std;
template<class K>
struct HashFunc //仿函数
{
size_t operator()(const K& key)
{
return key;
}
};
//特化
template<>
struct HashFunc<string> //仿函数
{
//将字符串转化为整形
size_t operator()(const string& s)
{
size_t hash = 0;
for (auto ch : s)
{
hash += ch;
hash *= 31;//用上次的结果乘以31
}
return hash;
}
};
namespace HashBucket //哈希桶
{
template<class T>
struct HashNode
{
HashNode<T>* _next;
T _data;
HashNode(const T& data)
:_next(nullptr)
, _data(data)
{}
};
//前置声明
template<class K, class T, class KeyOfT, class Hash>
class HashTable;
//迭代器
template<class K, class T, class Ref,class Ptr,class KeyOfT, class Hash >
struct __HashIterator
{
typedef HashNode<T> Node;
Node* _node;//节点的指针
typedef HashTable<K, T, KeyOfT, Hash> HT; //哈希表 typedef HT
HT* _ht; //哈希表
typedef __HashIterator<K, T, Ref,Ptr,KeyOfT, Hash> Self;
//定义一个普通迭代器
typedef __HashIterator<K, T, T&, T*, KeyOfT, Hash> Iterator;
__HashIterator(Node* node, HT* ht)
:_node(node),_ht(ht)
{
}
__HashIterator(const Iterator &it)
:_node(it._node),_ht(it._ht)
{
}
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &_node->_data;
}
bool operator!=(const Self &s)
{
//使用节点的指针进行比较
return _node != s._node;
}
//前置++
Self& operator++()
{
//若不处于当前桶的尾位置,则寻找桶的下一个位置
if (_node->_next != nullptr)
{
_node = _node->_next;
}
else
{
//若为空,则说明处于当前桶的尾位置,则需寻找下一个不为空的桶
KeyOfT kot;
Hash hash;
//计算当前桶位置
size_t hashi = hash(kot(_node->_data)) % _ht->_tables.size();
hashi++;//下一个位置
//寻找下一个不为空的桶
while (hashi < _ht->_tables.size())
{
if (_ht->_tables[hashi])
{
_node = _ht->_tables[hashi];
break;
}
else
{
//桶为空,需要继续寻找
hashi++;
}
}
//没有找到不为空的桶
if (hashi == _ht->_tables.size())
{
_node = nullptr;
}
}
return *this;
}
};
template<class K, class T, class KeyOfT, class Hash>
class HashTable
{
template<class K, class T,class Ref,class Ptr, class KeyOfT, class Hash >
friend struct __HashIterator;//友元 使 __HashIterator中可以调用HashTable的私有
typedef HashNode<T> Node;
public:
typedef __HashIterator<K, T,T&,T*, KeyOfT, Hash> iterator;
typedef __HashIterator<K, T, const T&, const T*, KeyOfT, Hash> const_iterator;
iterator begin()
{
Node* cur = nullptr;
size_t i = 0;
//找到第一个不为空的桶
for (i = 0; i < _tables.size(); i++)
{
cur = _tables[i];
if (cur)
{
break;
}
}
//迭代器返回 第一个桶 和哈希表
//this 作为哈希表本身
return iterator(cur,this);
}
iterator end()
{
return iterator(nullptr, this);
}
const_iterator begin()const
{
Node* cur = nullptr;
size_t i = 0;
//找到第一个不为空的桶
for (i = 0; i < _tables.size(); i++)
{
cur = _tables[i];
if (cur)
{
break;
}
}
//迭代器返回 第一个桶 和哈希表
//this 作为哈希表本身
return const_iterator(cur, this);
}
const_iterator end() const
{
return const_iterator(nullptr, this);
}
~HashTable()//析构
{
for (auto& cur : _tables)
{
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
cur = nullptr;
}
}
iterator Find(const K& key)//查找
{
Hash hash;
KeyOfT kot;
//若表刚开始为空
if (_tables.size() == 0)
{
return end();
}
size_t hashi = hash(key) % _tables.size();
Node* cur = _tables[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
return iterator(cur,this);
}
cur = cur->_next;
}
return end();
}
bool Erase(const K& key)//删除
{
Hash hash;
KeyOfT kot;
size_t hashi = hash(key) % _tables.size();
Node* prev = nullptr;//用于记录前一个节点
Node* cur = _tables[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
if (prev == nullptr)//要删除节点为头节点时
{
_tables[hashi] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
delete cur;
return true;
}
else
{
prev = cur;
cur = cur->_next;
}
}
return false;
}
pair<iterator,bool> insert(const T& data )//插入
{
KeyOfT kot;
//若对应的数据已经存在,则插入失败
iterator it = Find(kot(data));
if (it != end())
{
return make_pair(it, false);
}
Hash hash;
//负载因子==1时扩容
if (_n == _tables.size())
{
size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;
vector<Node*>newtables(newsize, nullptr);//创建 newsize个数据,每个数据都为空
for (auto& cur : _tables)
{
while (cur)
{
Node* next = cur->_next;//保存下一个旧表节点
size_t hashi = hash(kot(cur->_data)) % newtables.size();
//将旧表节点头插到新表节点中
cur->_next = newtables[hashi];
newtables[hashi] = cur;
cur = next;
}
}
_tables.swap(newtables);
}
size_t hashi = hash(kot(data)) % _tables.size();
//头插
Node* newnode = new Node(data);//新建节点
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_n;
return make_pair(iterator(newnode,this), true);
}
private:
vector<Node*> _tables; //指针数组
size_t _n=0;//存储数据有效个数
};
}
unordered_set.h
#include"HashTable.h"
namespace yzq
{
template<class K,class Hash=HashFunc<K>>
class unordered_set
{
public:
struct SetKeyOfT//仿函数
{
const K& operator()(const K&key)
{
return key;
}
};
public:
typedef typename HashBucket::HashTable<K, K, SetKeyOfT, Hash>::const_iterator iterator;
typedef typename HashBucket::HashTable<K, K, SetKeyOfT, Hash>::const_iterator const_iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
const_iterator begin()const
{
return _ht.begin();
}
const_iterator end()const
{
return _ht.end();
}
pair<iterator,bool> insert(const K&key)
{
return _ht.insert(key);
}
iterator find(const K&key)
{
return _ht.Find();
}
bool erase(const K& key)
{
return _ht.Erase(key);
}
private:
HashBucket::HashTable<K,K, SetKeyOfT, Hash> _ht;
};
void test_set()
{
unordered_set<int> v;
v.insert(1);
v.insert(3);
v.insert(2);
v.insert(8);
v.insert(1000);
v.insert(5);
unordered_set<int>::iterator it = v.begin();
while (it != v.end())
{
//*it = 1;
cout << *it << " ";
++it;
}
}
}
unordered_map.h
#include"HashTable.h"
namespace yzq
{
template<class K,class V,class Hash=HashFunc<K>>
class unordered_map
{
public:
struct MapKeyOfT//仿函数
{
const K& operator()(const pair<K,V>& kv)
{
return kv.first;
}
};
public:
typedef typename HashBucket::HashTable<K,
pair<const K, V>, MapKeyOfT,Hash>::iterator iterator;
typedef typename HashBucket::HashTable<K,
pair<const K, V>, MapKeyOfT, Hash>::constiterator const_iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
V& operator[](const K& key)
{
pair<iterator, bool> ret = insert(make_pair(key,V()));
return ret->first->second;
}
pair<iterator, bool> insert(const pair<K, V>& kv)
{
return _ht.insert(kv);
}
iterator find(const K& key)
{
return _ht.Find();
}
bool erase(const K& key)
{
return _ht.Erase(key);
}
private:
HashBucket::HashTable<K, pair<const K ,V>, MapKeyOfT,Hash> _ht;
};
void test_map()
{
unordered_map<int,int> v;
v.insert(make_pair(1,1));
v.insert(make_pair(3, 3));
v.insert(make_pair(10, 10));
v.insert(make_pair(2, 2));
v.insert(make_pair(8, 8));
unordered_map<int, int>::iterator it = v.begin();
while (it != v.end())
{
cout << it->first<<":"<<it->second << " ";
++it;
}
cout << endl;
}
}





](https://img-blog.csdnimg.cn/421c5ca48d5c49c68661e95966ff84c3.png)