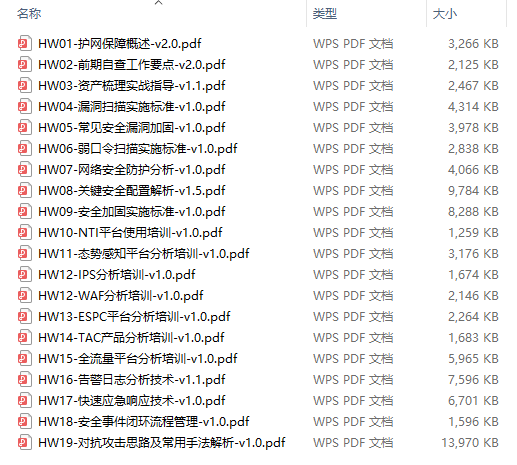
目录
- 前言
- 本次知识点:
- 开发环境:
- 代码展示
- 括展小知识
- 尾语 💝
前言
嗨喽~大家好呀,这里是魔王呐 ❤ ~!

本次知识点:
-
爬虫基本流程
-
requests的使用
-
正则表达式的使用
开发环境:
-
解释器: python 3.8
-
编辑器: pycharm 2022.3 专业版
第三方模块使用
- requests >>> 发送请求的模块
第三方模块安装:
-
win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
-
在pycharm中点击Terminal(终端) 输入安装命令
如果出现爆红, 可能是因为 网络连接超时, 可切换国内镜像源,命令如下:
pip install -i https://pypi.doubanio.com/simple/ requests
python资料、源码、教程\福利皆: 点击此处跳转文末名片获取
代码展示
导入模块
import requests
import re
模拟伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'
}
请求链接
url = 'https://*****/discover/toplist'
发送请求
response = requests.get(url, headers=headers)
获取数据
html_data = response.text
解析数据
info_list = re.findall('<li><a href="/song\?id=(.*?)">(.*?)</a></li>', html_data)
print(info_list)
# 将每一首歌曲的id和名称 挨个取出来
for info in info_list:
music_id = info[0]
music_name = info[1]
print(music_id, music_name)
music_url = 'http://****/song/media/outer/url?id=' + music_id
源码、解答、教程+V:pytho8987获取
music_info_url = 'https://music.163.com/song?id='+music_id
text = requests.get(music_info_url, headers=headers).text
img_url = re.findall('<meta property="og:image" content="(.*?)" />', text)[0]
print(img_url)
img_data = requests.get(img_url).content
f = open(rf'C:\Users\Administrator\Desktop\music\{music_name}-{music_id}.jpg', mode='wb')
f.write(img_data)
保存数据
# music_data = requests.get(music_url).content
# # 创建一个音乐文件
# # mode='wb': 以二进制的方式写入数据
# f = open(rf'C:\Users\Administrator\Desktop\music\{music_name}-{music_id}.mp3', mode='wb')
# # 写入数据
# f.write(music_data)
括展小知识
一、什么是正则?
搜索功能的一种 不是普通的搜索功能
.: 替代一个字符
*: 匹配前面表达式 多次
.*: 匹配任意字符多次
?: 非贪婪匹配符
(): 我只需要()里面的内容
正则 我们知道数据的开头 和结尾 我们就能匹配到数据内容
<li><a href="/song?id="></a></li>
<li><a href="/song?id="></a></li>
<li><a href="/song\?id=.*?">.*?</a></li>
二、<Response [200]>
正常 没有问题的情况 仅仅代表请求成功
不能代表你一定能拿到数据
尾语 💝
要成功,先发疯,下定决心往前冲!
学习是需要长期坚持的,一步一个脚印地走向未来!
未来的你一定会感谢今天学习的你。
—— 心灵鸡汤
本文章到这里就结束啦~感兴趣的小伙伴可以复制代码去试试哦 😝