有时候使用es查询出的结果包含多个字段,如果数据中仅仅包含几个字段时,我们是很容易挑出自己需要的字段值,但是如果数据中包含几十或者几百甚至更多时,尤其是数据中嵌套好多层时,不容易直接挑取出需要的值,这时候可以借助程序直接查找出来。或者针对性的直接查询时就限定条件查询某些字段的值。
直接从es中查询出的示例数据:
{
"took": 918,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1.0,
"hits": [{
"_index": "test",
"_type": "user",
"_id": "QHi1UoIBpyNh4YQ4T1Sq",
"_score": 1.0,
"_source": {
"id": 1001,
"name": "张三",
"age": 20,
"sex": "男",
"grade": {
"Chinese": 99,
"Math": 98,
"English": 96
}
}
},
{
"_index": "test",
"_type": "user",
"_id": "1002",
"_score": 1.0,
"_source": {
"id": 1002,
"name": "李四",
"age": 23,
"sex": "女",
"grade": {
"Chinese": 98,
"Math": 99,
"English": 97
}
}
},
{
"_index": "test",
"_type": "user",
"_id": "1003",
"_score": 1.0,
"_source": {
"id": 1003,
"name": "王五",
"age": 27,
"sex": "男",
"grade": {
"Chinese": 93,
"Math": 90,
"English": 99
}
}
},
{
"_index": "test",
"_type": "user",
"_id": "1004",
"_score": 1.0,
"_source": {
"id": 1004,
"name": "赵六",
"age": 29,
"sex": "女",
"grade": {
"Chinese": 100,
"Math": 95,
"English": 94
}
}
}
]
}
}使用python打印出需要的字段值:
import json
import jmespath
with open('text.txt', 'r', encoding='utf-8') as f:
data = f.read()
json_data = json.loads(data)
# print(json_data)
sources = json_data.get('hits').get('hits')
# print(sources)
for source in sources:
# print(source)
data = source.get('_source')
print(data)
valid_fields = '{name: name, Chinese_grade: grade.Chinese}'
ret = jmespath.search(valid_fields, data)
print(ret)
运行结果:
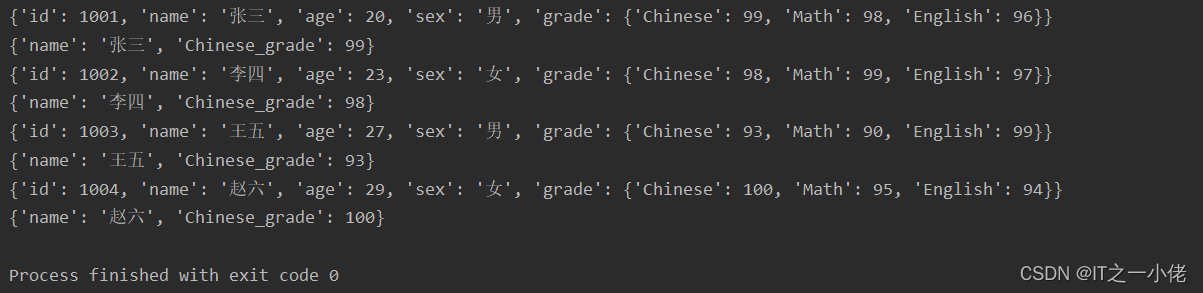
注意:使用json.load()时,会把文本中的fase、true直接变为False、True
参考博文:
python中jmespath库用法详解_IT之一小佬的博客-CSDN博客_jmespath python


![[附源码]JAVA毕业设计教材管理(系统+LW)](https://img-blog.csdnimg.cn/0988b73cec8e44a48259db82a9906fc2.png)
![[附源码]JAVA毕业设计技术的游戏交易平台(系统+LW)](https://img-blog.csdnimg.cn/c26aa470f0db4da0b0ef67935e53e2ce.png)






![[附源码]Python计算机毕业设计Django基于协同过滤的资讯推送平台](https://img-blog.csdnimg.cn/d21b9b073bcc47f6a85870b42cebaaa8.png)
