文章目录
- 一、求解与搜索
- 二、盲目式搜索
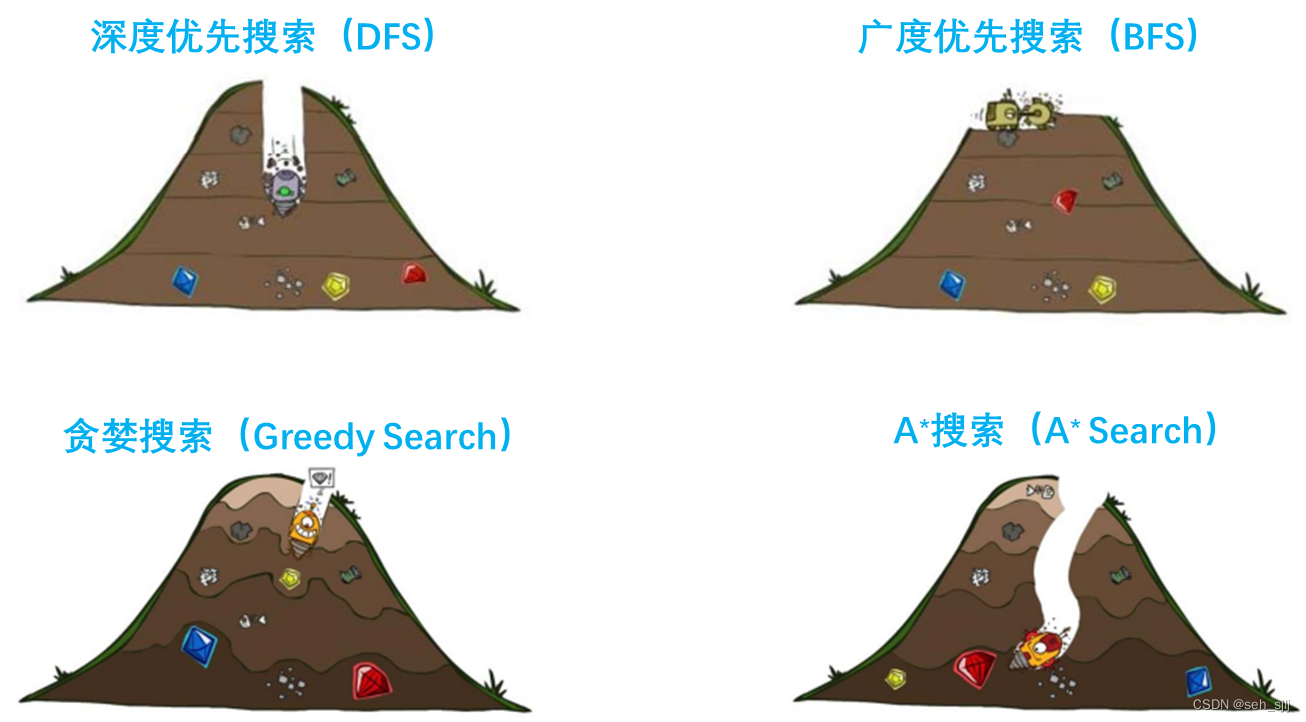
- 1. 深度优先搜索(Depth First Search, DFS)
- 回溯搜索(Backtracking Search)
- 2. 广度优先搜索(Breadth First Search, BFS)
- 一致代价搜索(Uniform-cost Search)
- 三、启发式搜索
- 1. 爬山搜索
- 启发函数(Heuristic Function)h(n)
- 评价函数(Evaluation Function)f(n)
- 2. 贪婪搜索(Greedy Search)
- 3. A算法(A Search Algorithm)
- 4. A\*算法(A\* Search Algorithm)
人工智能问题通常是在某个可能的解答空间中寻找一个解的求解过程。
一、求解与搜索
搜索:根据问题实际情况,不断寻找可利用的知识(或条件),构造一条代价最小的推理路线,寻求问题解决的过程
搜索技术的关键:2W
- What:搜索什么——搜索目标
- Where:在哪里搜索——搜索空间
搜索两个方面:
- 找到从初始事实到问题最终笞案的一条推理路径
- 找到的这条路径在时间和空间上复杂度最小
许多搜索问题都可以转化为图搜索问题
搜索类型:
- 按问题表示方法分类:
- 按是否使用启发式信息分类:
存在问题:深度问题、死循环问题
解决方法:对搜索深度加以限制、记录从初始状态到当前状态的路径
搜索算法的通常类型
图搜索包括穷举搜索和启发式搜索
状态空间法:利用状态变量和操作符好表示系统或问题的有关知识的符号体系
状态空间用四元组表示:
(
S
,
O
,
S
0
,
G
)
(S,O,S_0,G)
(S,O,S0,G)(分别为状态集合、操作算子集合、初始状态集合、目标状态集合)(
S
0
⊂
S
S_0\subset S
S0⊂S,
G
⊂
S
G\subset S
G⊂S)
状态空间图:状态=节点,边=状态之间的关系(操作算子)
图搜索策略:初始节点出发、按照问题的约束条件寻找到达目标点(状态)路径的方法
路径:一个状态序列(初始状态→目标状态)
一般是便搜索边生产图
搜索问题的描述:
- 状态
- 动作
- 状态转移
- 路径
- 代价(通过每条路径的时间)
- 目标测试(评估当前状态是否为所解的目标状态)
搜索树:
- 根节点:初始状态
- 目标节点:目标状态
- 父节点
- 子节点
- 兄弟节点
- 扩展:从父节点产生子节点
搜索空间:一系列状态的汇集
搜索算法的评价指标:
- 完备性:求解能力,可以确保一个解决方案
- 最优性:求解质量,提供最佳解决方案
- 时间复杂度:是花费的时间度量
- 空间复杂度:所需的最大存储空间
时间/空间复杂度的确定:
- 分支因子 b b b:搜索树中每个节点最大的分支数目
- 目标节点所在的最浅深度 d d d:搜索树中最早出现的目标所在层数
- 状态空间中任何路径的最大长度 m m m:字面意思
- 状态空间的大小 n n n:状态空间中状态的数目
二、盲目式搜索
特点:没有利用任何与问题有关的知识或信息
1. 深度优先搜索(Depth First Search, DFS)
基本思想:优先扩展深度最深的节点
从根节点开始,在回溯之前沿每个分支搜索至深度界限
回溯搜索(Backtracking Search)
是深度优先搜索的一种,核心思想是:发现原先选择并不优或达不到目标,就退回一步重新选择,“走不通就退回再走”
深度优先搜索和回溯法的主要区别是:
- 回溯法在求解过程中不报亏完整的树结构,而深度优先搜索则记录下完整的搜索树
- 为了减少存储空间,在深度优先搜索中,用标志的方法记录访问过的状态,这种处理方法使得深度优先搜索法与回溯法没什么区别了
- 回溯法花费时间较长,所以对于没有明确的动态规划(DP)和递归解法的或问题要求满足某种性质(约束条件)的所有解或最优解时,才考虑使用回溯法
深度优先搜索的特点:
- 具有通用性
- 每次选择一个深度最深的节点进行扩展
- 一般不能保证找到最优解,可能遇到“死循环”,是不完备搜索
- 可以加入深度限制——到达某深度强制进行回溯,但限制过深则影响效率,限制过浅则可能找不到解
- 占用大量的时间和空间
- 存在搜索与回溯交替出现的现象
2. 广度优先搜索(Breadth First Search, BFS)
基本思想:优先扩展同级直接相连的节点
以接近起始节点的程度依次扩展节点、逐层搜索:从根节点开始,在移动到下一个深度级别的节点之前,探索当前深度的所有邻居节点
广度优先搜索的特点:
- 优先搜索深度浅的节点
- 具有通用性
- 当问题有解时一定能找到解,是完备的搜索
- 若找到目标节点,一定是最浅的目标节点
- 如果路径是非递减函数,广度优先搜索是最优的
深度优先搜索与广度优先搜索比较:
| 算法 | 深度优先搜索(DFS) | 广度优先搜索(BFS) |
|---|---|---|
| 完备性 | 不一定(若解不在某个分支,而这个分支又是无穷分支,那就永远出不来了) | 完备(在分支因子 b b b优有限的情况下) |
| 最优性 | 不具备 | 最优(如果路径代价是节点深度的非递减函数) 不一定最优(通常情况下) |
| 时间复杂度 | O ( b m ) O(b^m) O(bm) | O ( b d ) O(b^d) O(bd) |
| 空间复杂度 | O ( b m ) O(b^m) O(bm) | O ( b d ) O(b^d) O(bd) |
注解:
- b , d , m , l b,d,m,l b,d,m,l分别为分支因子、解的深度、搜索树最大深度、深度限制。解的深度是解所在的深度,而搜索树的最大深度是DFS过程中探到的最大深度。
- 如果 m > d m>d m>d则DFS的时间复杂度会很高,但如果解决方案密集,可能比BFS快很多
- BFS最优的情况是路径代价是节点深度的非递增函数,因为BFS一定搜索到的是深度最浅的目标节点,非递减函数在深度最浅的时候值也最小
- BFS占用空间很大,DFS则是一条路走到黑
一致代价搜索(Uniform-cost Search)
策略:总是扩展路径消耗最小的节点 N N N, N N N点的路径消耗等于前一点的路径消耗+前一点到 N N N节点的路径消耗
一致代价搜索是BFS的扩展,使用优先队列而不是普通队列保存边缘中的状态;如果每一步的代价全部相等,则与BFS相同
一致代价搜索与Dijkstra算法的对比:
- 相同点:
- 求解初始节点到目标节点最短路径的时间复杂度相同,代码结构相同,每次扩展的节点相同,逻辑相同
- 不同点:
- 一致代价搜索在搜索到目标节点后就停止了,而Dijkstra需要求出图中所有节点的最短路径
- Dijkstra需要事先明确所有节点,需要在内存中存储整张图;而一致代价搜索不需要
三、启发式搜索
启发:应用特定的经验法则或从经验衍生出来的论据,提高解决复杂问题的效率
启发式搜索(Heuristic Search):利用启发方式获得的领域知识,通过限定搜索深度或者限定搜索宽度来缩小问题空间,避开没有结果的搜索路径,也称有信息搜索
- 引导搜索忽略最没有希望的路径,沿着一条最可能的路径到达解
- 不是严格按照DFS、 BFS预先确定方式或方法,“凭经验”或“试错”来确定要下一步扩展的节点(不是一次性生产所有的后续节点)
1. 爬山搜索
模拟爬山过程,随机选择一个位置(节点)爬山,每次朝着更高的方向移动,直至山顶,即每次都在临近的空间中选择最优解作为当前解,直到局部最优解
从当前的节点开始,与周围的邻居节点的值进行比较
如果当前节点是最大的,那么返回当前节点,作为最大值(即山峰最高点);反之就用最高的邻居节点来替换当前节点,实现向山峰的高处攀爬的目的,直到达到最高点
爬山搜索的特点:
-
局部最优方法,不是全面搜索,结果可能不是最佳
-
一般存在以下问题:
- 局部最大:某个节点比周围任何一个邻居都高,却不是整个问题的最高点;
- 高地(平顶):搜索一旦到达高地,就无法确定搜索最佳方向,会产生随机走动,使得搜索效率降低;
- 山脊:搜索可能会在山脊的两面来回震荡,前进步伐很小
-
算法会陷入局部最优解,能否得到全局最优解取决于初始点的位置
启发函数(Heuristic Function)h(n)
启发函数:一个关于节点的函数 h ( n ) h(n) h(n),用于评估当前状态与目标状态接近的程度(例如用曼哈顿距离、欧几里得距离等)
h ( n ) ≥ 0 h(n)\ge 0 h(n)≥0
h
(
n
)
h(n)
h(n)越小,表示当前状态
n
n
n越接近目标状态
h
(
n
)
=
0
h(n)=0
h(n)=0表示已达到目标
启发搜索利用启发函数的值将问题状态的描述转化为问题解决程度的描述
评价函数(Evaluation Function)f(n)
评价函数:用于评价节点重要程度的函数,其主要任务是确定节点的优先级程度
评价函数
f
(
n
)
f(n)
f(n)的一般形式:
f
(
n
)
=
g
(
n
)
+
h
(
n
)
f(n)=g(n)+h(n)
f(n)=g(n)+h(n)
其中
g
(
n
)
g(n)
g(n)是从初始状态到当前状态已经付出的代价,
h
(
n
)
h(n)
h(n)是启发函数(从当前状态到目标状态的代价的评估)
f
(
n
)
=
g
(
n
)
f(n)=g(n)
f(n)=g(n):等代价搜索,按照已付出的代价进行搜索(如广度优先搜索),具有完备性
f
(
n
)
=
h
(
n
)
f(n)=h(n)
f(n)=h(n):按照启发函数向最靠近目标的状态(节点)搜索(如贪婪搜索),不具有完备性
2. 贪婪搜索(Greedy Search)
贪婪最佳优先搜索:试图扩展离目标最近的节点以便尽快找到问题的解
评价函数 f ( n ) f(n) f(n)仅使用启发式信息: f ( n ) = h ( n ) f(n)=h(n) f(n)=h(n),仅依赖从当前状态到目标状态间的剩余距离
局部择优选取,其自的不是为了找到全部解,而只是找出一种可行解(当前条件下的最优)含当然找不出全局最优解,但具有高效性
大部分的贪婪算法都是基于图的方式寻找最优路径
核心:每一步试图找离目标最近的节点
贪婪最佳优先搜索的特点:
- 不是最优搜索
- 对错误的起点比较敏感(可能有死循环)
- 是不完备搜索
- 最坏情况下的时间、空间复杂度: O ( b m ) O(b^m) O(bm),其中 b b b为节点的分支因子数目, m m m为搜索空间的最大深度
- 贪婪算法总是做出当前最好的选择
- 贪婪选择的依据是当前的状态,而不是问题的目标
- 贪婪选择是不计后果的
- 贪婪算法通常以自顶向下的方法简化子问题
- 贪婪算法求解的问题具备以下性质:
- 贪婪选择性质:问题的最优解可以通过贪婪选择实现
- 最优子结构性质:问题的最优解包含子问题的最优解
- 贪婪选择性质的证明(数学归纳法)
- 证明问题的最优解可以由贪婪选择开始(即第一步可贪心)
- 证明贪心选择后得到的子问题满足最优子结构(即步步可贪心)
例 (洛谷P3817 小A的糖果) 小A有 n n n个糖果盒,第 i i i盒有 a i a_i ai个糖果。小 A A A每次可以从其中一盒糖果中吃掉一颗,他想知道,要让任意两个相邻的盒子中糖的个数之和都不大于 x x x,至少得吃掉几颗糖。
分析 假设从第 i i i盒吃 c i c_i ci个,求 min y = ∑ i = 1 n c i s . t . ( a i − c i ) + ( a i + 1 − c i + 1 ) ≤ x , 1 ≤ i ≤ n − 1 0 ≤ c i ≤ a i , 1 ≤ i ≤ n \min y=\sum\limits_{i=1}^n c_i\\s.t.\ (a_i-c_i)+(a_{i+1}-c_{i+1})\le x,\ 1\le i\le n-1\\ 0\le c_i\le a_i,\ 1\le i\le n miny=i=1∑ncis.t. (ai−ci)+(ai+1−ci+1)≤x, 1≤i≤n−10≤ci≤ai, 1≤i≤n这个问题中,每个状态即为当前各盒的糖果数,目标状态满足相邻两盒糖果数之和小于等于 x x x,初始状态为 s 0 = ( a 1 , a 2 , ⋯ , a n ) s_0=(a_1,a_2,\cdots,a_n) s0=(a1,a2,⋯,an),状态转移为从某盒吃掉一个糖果。
设当前状态为 s s s, s s s状态下第 i i i盒剩余的糖果数为 b i ( s ) b_i^{(s)} bi(s), b i ( s 0 ) = a i b_i^{(s_0)}=a_i bi(s0)=ai。定义启发函数 h ( s ) = ∑ i = 1 n − 1 max ( 0 , b i ( s ) + b i + 1 ( s ) − x ) h(s)=\sum\limits_{i=1}^{n-1}\max\left(0,b_i^{(s)}+b_{i+1}^{(s)}-x\right) h(s)=i=1∑n−1max(0,bi(s)+bi+1(s)−x),目标状态 t t t的启发函数值 h ( t ) = 0 h(t)=0 h(t)=0。对于任何当前状态 s s s,设下一状态为 u u u,如果吃两端(第 1 1 1盒或第 n n n盒)最多只能使 h ( u ) ≥ h ( s ) − 1 h(u)\ge h(s)-1 h(u)≥h(s)−1,而吃中间的(第 2 , 3 , ⋯ , n − 1 2,3,\cdots,n-1 2,3,⋯,n−1盒)至多使 h ( u ) ≥ h ( s ) − 2 h(u)\ge h(s)-2 h(u)≥h(s)−2,所以吃任何中间的都是最优的。同时,如果 a i − 1 + a i > x a_{i-1}+a_i>x ai−1+ai>x且 a i + a i + 1 > x a_{i}+a_{i+1}>x ai+ai+1>x,那么吃第 i i i盒能使 h ( u ) = h ( s ) − 2 h(u)=h(s)-2 h(u)=h(s)−2,最划算。综上,对于 a i ( 2 ≤ i ≤ n ) a_i(2\le i\le n) ai(2≤i≤n),若 b i − 1 + a i > x b_{i-1}+a_i>x bi−1+ai>x,则令 c i = a i + 1 + a i − x c_i=a_{i+1}+a_i-x ci=ai+1+ai−x,使得 b i = a i − c i − 1 b_i=a_i-c_{i-1} bi=ai−ci−1。(即 c i = max ( 0 , b i − 1 + a i − x ) c_i=\max(0,b_{i-1}+a_i-x) ci=max(0,bi−1+ai−x)。)代码如下:
#include <iostream>
using namespace std;
const int MAXN = 1e5 + 5;
int n, x, a[MAXN], b[MAXN];
int main()
{
cin >> n >> x;
for(int i = 1; i <= n; ++i) cin >> a[i];
long long y = 0;
b[1] = a[1];
for(int i = 2; i <= n; ++i)
{
if(b[i - 1] + a[i] > x)
{
int c = b[i - 1] + a[i] - x;
y += c;
b[i] = a[i] - c;
}
else
{
b[i] = a[i];
}
}
cout << y << endl;
return 0;
}
算法的最优性证明如下:若该策略不是最优,假设有比我们的答案 y y y更小的 y ′ y' y′,不妨设 y ′ = y − 1 y'=y-1 y′=y−1,则必 ∃ j ( 2 ≤ j ≤ n ) \exists j(2\le j\le n) ∃j(2≤j≤n)使得 c i ′ = c i − 1 c_i'=c_i-1 ci′=ci−1。我们知道, c i = max ( 0 , b i − 1 + a i − x ) ( 2 ≤ i ≤ n ) c_i=\max(0,b_{i-1}+a_i-x)(2\le i\le n) ci=max(0,bi−1+ai−x)(2≤i≤n),当 b i − 1 + a i − x > 0 b_{i-1}+a_i-x>0 bi−1+ai−x>0时, b i − 1 + b i = x b_{i-1}+b_{i}=x bi−1+bi=x。但 c i ′ = c i − 1 c_i'=c_i-1 ci′=ci−1,使得 b i ′ = b i + 1 b_i'=b_i+1 bi′=bi+1,此时 b i − 1 + b i = x + 1 > x b_{i-1}+b_i=x+1>x bi−1+bi=x+1>x,所以条件不满足,矛盾。因此我们的策略是最优策略。
3. A算法(A Search Algorithm)
A算法的评价函数 f ( n ) = g ( n ) + h ( n ) f(n)=g(n)+h(n) f(n)=g(n)+h(n),其中:
- g ( n ) g(n) g(n)为从初始状态到当前状态的实际路径代价(并不一定最优,例如可以是当前状态在搜索树中的深度,但不一定是最小深度)
- h ( n ) h(n) h(n)是启发函数,代表从当前状态到目标状态估计的最低代价路径的代价
- f ( n ) f(n) f(n)是从初始状态经过节点 n n n到目标状态的最低代价路径的估计总代价值
优先扩展 f ( n ) f(n) f(n)最小的节点进行扩展
4. A*算法(A* Search Algorithm)
A*搜索:最小化总的解决方案代价估计值的最佳优先搜索
A算法对评价函数中的启发函数未做任何规定,不能评价搜索结果的优劣
A*算法的评估函数 f ∗ ( n ) = g ∗ ( n ) + h ∗ ( n ) f^*(n)=g^*(n)+h^*(n) f∗(n)=g∗(n)+h∗(n),其中:
- g ∗ ( n ) g^*(n) g∗(n):从起始点到节点 n n n的路径最低代价
- h ∗ ( n ) h^*(n) h∗(n):从节点 n n n到目标节点的最低代价路径的代价
- f ∗ ( n ) f^*(n) f∗(n):从起始点出发、经过节点 n n n、到达目标节点的最佳路径的估计总代价
与A算法相比(参考Stackexchange):
- g ( n ) g(n) g(n)是从初始节点到当前节点的(在当前搜索树上的)路径长度,而 g ∗ ( n ) g^*(n) g∗(n)是从初始节点到当前节点的最短路径长度,故 g ( n ) ≥ g ∗ ( n ) > 0 g(n)\ge g^*(n)>0 g(n)≥g∗(n)>0
- h ( n ) h(n) h(n)是从当前节点到目标节点的估计的代价,而 h ∗ ( n ) h^*(n) h∗(n)是从当前节点到目标节点的真实的代价,一般 h ∗ ( n ) h^*(n) h∗(n)是无法计算的,用 h ( n ) h(n) h(n)代替; h ( n ) ≤ h ∗ ( n ) h(n)\le h^*(n) h(n)≤h∗(n)
保证A*搜索最优化的条件:
A*搜索使用到当前的路径代价
g
(
n
)
g(n)
g(n)+到目标的最低路径代价
h
(
n
)
h(n)
h(n)。若启发函数
h
(
n
)
h(n)
h(n)满足下列条件,则A*算法既完备又最优:
- 采纳性:启发函数 h ( n ) h(n) h(n)是一个可接受的启发,即不高估到目标的代价( h ( n ) ≤ h ∗ ( n ) h(n)\le h^*(n) h(n)≤h∗(n)),则总代价 f ( n ) f(n) f(n)也不会高估节点 n n n的求解的代价
- 一致性:启发函数 h ( n ) h(n) h(n)是一致的,即通过节点 n n n达到目标的代价不高于从节点 n n n经过其他节点 n ′ n' n′达到目标的代价(类似于三角不等式)
启发式搜索的特点:
- 优点:
- 与盲目搜索不同,利用搜索过程中所得到的问题本身的一些特征信息,可缩小搜索范围,减少盲自性,有效提高搜索效率,更容易解决复杂的问题
- 关键:
- 具有启发函数
- 具有评价函数
- 启发信息(利用额外信息,例如利用曼哈顿距离、切比雪夫距离)
- 缺点:
- 可能不会始终提供最佳解决方案,但肯定会在合理的时间内提供良好的解决方案
- 在不同的启发搜索算法中,使用不同的启发式方法
启发式搜索(以及一致代价搜索)总结:
| 算法 | 种类 | 估价函数 | 完备性 | 最优性 | 最坏情况下的时间、空间复杂度 |
|---|---|---|---|---|---|
| 一致代价搜索 | 盲目式搜索 | f ( n ) = g ( n ) f(n)=g(n) f(n)=g(n) | 完备 | 最优(如果路径代价是节点深度的非递减函数) 不一定最优(通常情况下 | O ( b d ) O(b^d) O(bd)( b b b为分支因子, d d d为解的深度) |
| 爬山搜索 | 启发式搜索 | - | 不完备 | 非最优(仅局部最优) | - |
| 贪婪搜索 | 启发式搜索 | f ( n ) = h ( n ) f(n)=h(n) f(n)=h(n) | 不完备 | 非最优 | O ( b m ) O(b^m) O(bm)( b b b为分支因子, m m m为搜索空间最大深度) |
| A算法 | 启发式搜索 | f ( n ) = g ( n ) + h ( n ) f(n)=g(n)+h(n) f(n)=g(n)+h(n) | - | 不一定 | - |
| A*算法 | 启发式搜索 | f ∗ ( n ) = g ∗ ( n ) + h ∗ ( n ) f^*(n)=g^*(n)+h^*(n) f∗(n)=g∗(n)+h∗(n)(可用 h ( n ) h(n) h(n)代替 h ∗ ( n ) h*(n) h∗(n)) | 启发函数满足条件则完备 | 启发函数满足条件则最优 | - |
盲目搜索与启发式搜索的对比:
- 盲目搜索(非启发式搜索):
- 只按照预定的控制策略进行搜索,搜索过程中获得的信息并不改变策略
- 搜索总按照预定路线进行,没有考虑问题本身的特性,缺乏对问题求解的针对性
- 需求全方位的搜索,没有选择最优的搜索途径,具有盲目性,效率不高
- 启发式搜索(有信息搜索):
- 根据问题本身的特性或搜索过程中产生的一些信息改变或调整搜索方向,向最有希望的方向搜索,加速问题求解并找到最优解


![[附源码]JAVA毕业设计教材管理(系统+LW)](https://img-blog.csdnimg.cn/0988b73cec8e44a48259db82a9906fc2.png)
![[附源码]JAVA毕业设计技术的游戏交易平台(系统+LW)](https://img-blog.csdnimg.cn/c26aa470f0db4da0b0ef67935e53e2ce.png)






![[附源码]Python计算机毕业设计Django基于协同过滤的资讯推送平台](https://img-blog.csdnimg.cn/d21b9b073bcc47f6a85870b42cebaaa8.png)