在我想学习算法的时候,我看某些大佬特别喜欢上来就讲论文,给我搞的贼难受,毕竟本人太辣鸡了,上来这么搞看不懂,经过诸多算法的这样折磨。我打算根据自己的亲身经历和学习过程中遇到的问题出一期,先讲算法整体流程和思想,再讲论文公式代码的博客,让大家轻松的学习一下yolo或者其他类的目标检测算法。
好的,废话少说,这期我们学习一下yolov1,即最开始的快速目标检测算法是如何实现的,这样方便我们学习后续更复杂的yolov3等等!
跟R-CNN系列不同,没看过R-CNN的可以先看看我写的这篇R-CNN的博客。RCNN算法思想简单讲解概述————(究极简单的讲述和理解)_小馨馨的小翟的博客-CSDN博客
R-CNN是采用滑动窗口进行目标检测的,在yolo的作者看来这是非常低效的,一个一个滑检测出来到啥时候了?还浪费算力和时间,因此YOLO横空出世,我个人非常喜欢yolo的检测方法,我也认为这才是未来主流的方法。当然在速度上yolo虽然完胜R-CNN系列,但是精确度上R-CNN更强一点,但是在飞速发展的时代,我认为yolo精度的问题一定会得到妥善的解决,yolo也才是未来的发展方向。好吧让我们开始欣赏yolo系列的处女作,yolov1。
对了强调一下,yolov1刚开始只能检测一个目标,但是也不影响,学会了这个你会发现多目标检测也很简单,至少在思想上很简单,可能具体数学算法公式比较难。
yolo如何检测到图像中车辆的位置,并且识别他的种类呢?

跟R-CNN的滑动窗口不同的(不懂R-CNN滑动窗口的,可以看看我博客的有关R-CNN的)是,yolo将整个图片一下子分成3*3=9份,至于为什么要分成9份呢?请听我慢慢讲。(当然这里也可以分的更精细,比如说yolov3常用的分成19*19=361份,这里为了方便讲解,我们少分一点)

我们首先需要确定我们要检测的目标,我们要在当下场景中检测三个目标。1、行人 2、汽车 3、摩托车 4、背景
我们最开始使用卷积神经网络(无目标检测的时候)对图像进行分类的时候,我们的神经网络一般来说是经过全连接层或者softmax层输出4个结果。即输出(行人的概率C1、汽车的概率C2、摩托车的概率C3、背景的概率C4),y =(C1、C2、C3、C4),即输出一个四维向量。我们仔细看看这个输出啊,标准的卷积神经网络的输出,没有位置信息,这显然就表达了一点,之前的卷积神经网络只能确定类别信息,无法确定位置信息。
所以接下来我们就要分析一下yolo的输出了。好的,别急,在讲yolo的网格检测原理之前,我们先简单分析一下yolo的输出,至少我认为这样方便咱们理解网格的检测原理。经过上面我们知道CNN的输出只有种类信息,即我们想要识别的四个种类的信息,yolo加入了坐标信息这样我们的算法不仅可以获取目标的类别信息,还能获取目标的位置信息,这样就达到了目标检测的目的,如下:
y = (Pc、bx、by,bw,bh,C1、C2、C3),一个8维向量
Pc表示图像中是否出现 行人,汽车,摩托车这三个目标,如果出现这三个中的一个,PC = 1
然后bx、by,bw,bh为目标的中心点的坐标信息。bx为横坐标,by为纵坐标,bw为中心点相对于网格的横向偏移量,bh为相对于目标中心点的纵向偏移量。然后C1、C2、C3这三个,是那个目标那个就为1,剩下的两个就为0
例如当图像中出现行人的时候 y = (1、bx、by,bw,bh,1、0、0)
那么当图像中没有目标的时候,Pc = 0,那么其他值将毫无意义。
y = (0、?、?、?、?、?、?、?、?)

坐标信息的获取组成:
对了,关于yolov1,这个坐标信息的获取,我感觉的简单讲解一下,复杂的公式推理咱们不去讲,就简单说一下 如何确定目标中心点的坐标。类似如图右边汽车中心点所在的的网格,网格最上角的点坐标设置为(0,0),右下角的坐标为(1,1)。黄色的为中心点的坐标就是相对于这个点产生的,bx,by都是在(0-1)之前的横纵坐标,bw,bh这是红色检测框的长度相对于网格长度产生的相对值,相对值怎么说呢,假如说0.5倍的网格长度这个样子。这个坐标信息就是这么来的,具体的计算过程等咱们讲述论文的时候再说!
好了,我们这里讲完了 yolo的输出向量,那我们就要讲一个yolo的网格划分的作用了。
bounding box预测:
我们使用图像分类和定位算法,将其应用到图中的九个格子上,每个格子都会输出相应的向量,
y = (Pc、bx、by,bw,bh,C1、C2、C3),一个8维向量,相当于我们把一个网格分为9部分,输出9个向量,当然在实际检测中我们可能会将图像更细分,比如说19*19=361个网格。当然也会输出更多个向量(每个网格对应一个向量)。

具体车辆目标应该分给那个网格,yolo的做法根据目标中点所处的位置决定,如下图所示,左边那辆车的重点在最左边中间那个网格中,所以左边那辆车就被分配给左边那个网格,右边的车同理。

对于左边绿色网格内输出的向量即为:

右边黄色网格输出的向量如下:
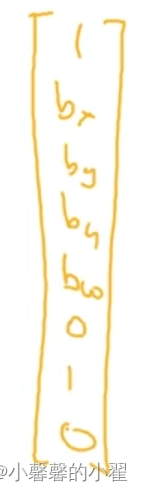
因此对于9个网格,每个网格都会输出一个8维的向量。一共9个网格则会输出3*3*8尺寸的向量。
如果为19*19的网格,则会输出19*19*8尺寸的向量。网格划分的越多越细,这同一个网格中存在多个对象的概率就越低。我们只需要关注检测对象中心所在的网格即可,因此即使对象横跨多个网格,我们也可以精确的确定其位置。
划分网格的目的可以使得算法更加高效,R-CNN系列需要滑动窗口,使得算法运行3*3=9次,而yolo一次性划分好网格就可以输出结果向量。这就是yolo,你只需要看一次的算法。
针对一个中存在多个目标的时候,我们就需要用到Anchor Boxes
Anchor Boxes原理:
yolo系列的目标检测算法,在一个网格中只能检测一个对象,但是我们在实验中发现,一个网格中很多时候存在不仅一个目标,可能存在多个目标,类似如下图所示,下面中间的网格中就存在人和车辆两个目标的中心点,因此如何检测出一个网格中存在的多个目标就成了我们需要研究的问题。Anchor Boxes的出现帮我们解决了这个问题。

对于如上图的情况我们输出向量的时候C1 C2 C3种类这块没法输出,因为里面有两个,人和车。

因此 Anchor Boxes的做法是我们建立两个Anchor Box,如下图所示:

当然目标更多的时候,你也可以建立更多,我们这里为了方便讲解,只构建两个,同时因为左边的那个更适合我们图片上的人的形状,因此左边的anchor box用来检测人,右边更适合汽车的形状,因此右边的anchor box用来检测汽车。(具体这个anchor box跟目标的适配过程是根据交并比的计算决定的,那个对象跟相应的anchor box的交并比更高就使用那个)。然后针对我们之前的输出向量只能表示一个目标,而导致检测不准确的情况,我们可以将两个向量堆叠到一起。如下图所示:

完成的Anchor Box输出过程:
在使用anchor box之前,3*3的网格,每个网格输出一个向量(即检测一个目标),每个向量有8个参数(这是因为我们设置的有3个对象,所以每个向量都是8维),即使一共要输出3*3*8个参数。
上述向量参数分别为 Pc:网格里是否存在目标对象,存在为1,不存在为0
bx为目标中心点的横坐标,by为目标中心点的纵坐标,bh为相对网格的纵向偏移程度,bw为横向偏移程度。
C1为行人 、C2为车辆、C3为摩托。
y = (Pc、bx、by、bw、bh、C1、C2、C3)
两个目标的y = (Pc、bx、by、bw、bh、C1、C2、C3,Pc、bx、by、bw、bh、C1、C2、C3)
如上所讲的那样,如果一个网格里有两个目标了,那输出即为3*3*16,或者也为3*3*2*8。
当然这个2就是代表目标的个数,这说明如果一个网格里存在的目标更多,那你输出向量的维度则会更大。
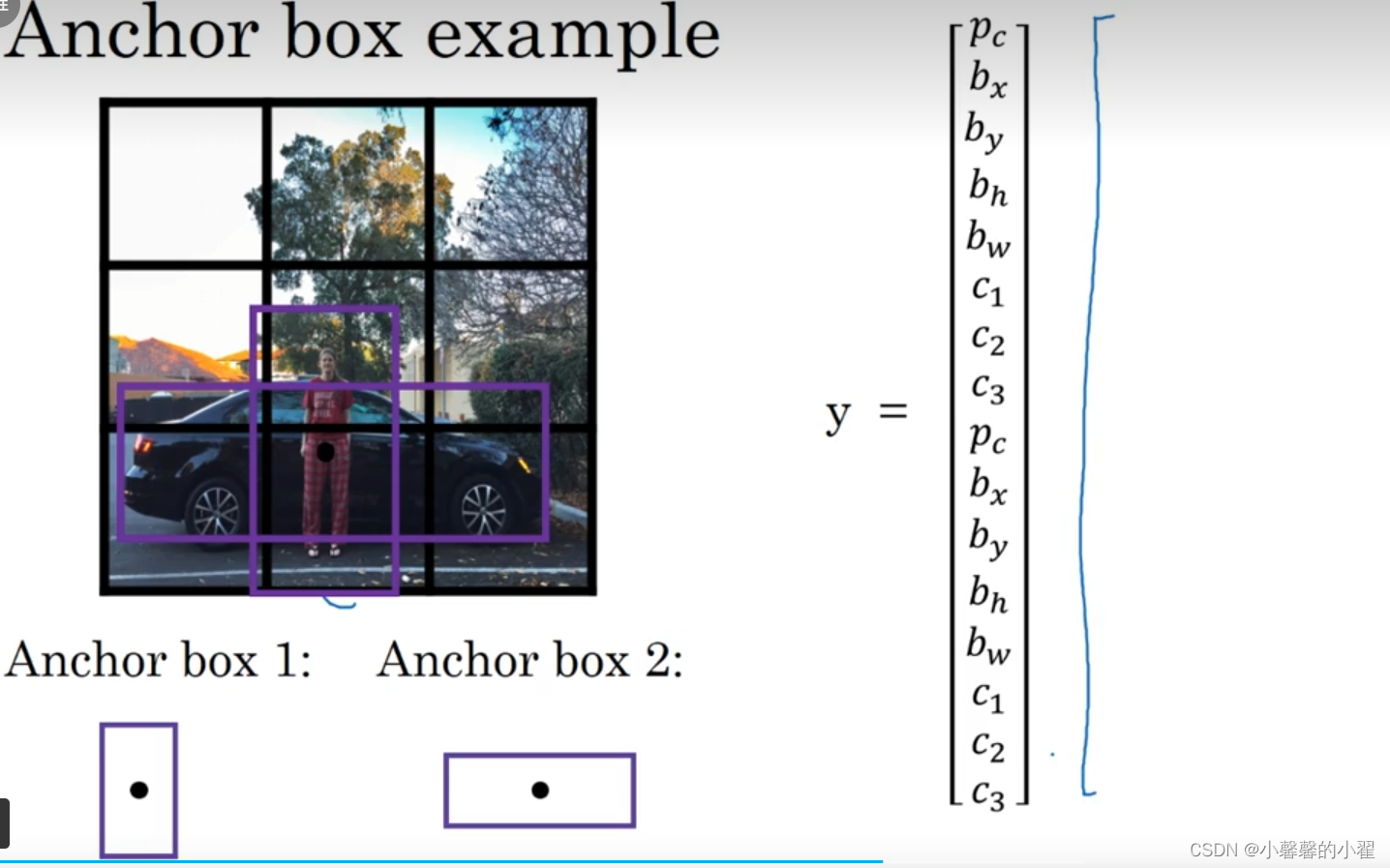

向量的上半部分是行人,下半部分是汽车。只有汽车没有行人的向量如下所示:

总结:
有的同学可能想问,那如果一个网格中存在的的目标数量大于两个呢,甚至更多呢,那我们要预设更多的anchor box吗?答案是否定的。事实上当我们按照19*19,或者30*30或者更大更密集划分网格的时候,一个网格中存在多个目标的可能性已经变得非常小,因此这种情况出现的概率非常低,因此这个问题并不会过于影响我们算法的性能。
一般来说需要人工根据自己目标的形状特性,手动设置5个左右的anchor box,比如说,我知道我要检测的目标里面存在瘦高的目标我就设置瘦高的长方形的anchor box,我要检测目标里面有胖的目标,我就设置矮宽的正方形等等。但是人工设置总归不是最好的办法,在后面的yolo算法中我们将会学习到,K-means方法,使用K聚类的方法,我们可以自适应的选择最合适的anchor box,这才是更智能更好的方法。
NMS非极大值抑制原理:
在我们使用anchor boxes之后,一个目标可能会出现多个检测框,如何删除多余的检测框,只留下效果最好,交并比最高的一个检测框就是NMS解决的问题。
首先我们简单看一下NMS使用的这个背景

按照yolo目标检测算法的初步思想来说,把图片分成19*19网格之后,理论上这个19*19个网格里面包含汽车一部分的都会检测到汽车的存在,那么带来的问题就是,很多个网格都能检测到汽车如下图所示,显然这并不是我们想要的效果,我们只想一个网格里检测到车(一辆车),图像上两辆车应该是两个网格。

因为我们在检测的时候,可能对一个目标做重复多次检测,这个时候NMS的使用,就是为了删除那些无用的目标检测框,留下一个最佳的目标检测框。

下面我们介绍NMS的工作思想:
如上图所示,每个边框都有他的概率,我们选出概率最高的边框进行高亮显示,然后NMS对剩下的矩形进行逐一扫描对比,所有跟这个高亮边框有很高的的交并比,高度重叠的其他预测框都会被抑制。比如右边那个车辆,我们得到0.9的高亮框,因为0.6和0.7的两个高亮框跟0.9的这个IOU最高,因此我们要一直0.6和0.7的这两个高亮框使其变暗。左边汽车的处理方法同。然后经过NMS的处理,我们可以得到如下图所示的效果,即每个车辆身上只有一个预测框。

这就达到了非极大值抑制的效果,所谓非极大值抑制,即只输出概率最大的分类结果。
下面我们来具体分析一下NMS这个有意思的算法:
一开始,我们需要设定一个阈值为Pc,例如Pc=0.6,我们删除掉所有概率小于0.6的目标边界框,然后对剩下的进行的NMS处理。如上诉。高亮概率最大的进行显示,其他的进行删除。往复如此,一直这样进行循环,直到只剩下一个边界框为止。
在Yolo程序里面是构造了一个while进行循环不停的处理的,直到只剩下一个边界框,即跳出while。
总结:
当然上述只是针对一种目标进行检测时候所进行的非极大值抑制,多个目标,假如你是三个目标进行非极大值抑制的时候,你就需要进行三次独立的非极大值抑制,然后作用于输出结果即可。
好了,这就是yolov1检测的全部流程了,首先进行网格划分,然后获取目标中心点位置所在的网格,输出该网格的向量(对于有目标的生成相应的检测框),针对不同形状,或者网格中多个目标的存在使用anchor box,最后使用NMS删除多余检测框,获取最终的检测框。




![[附源码]计算机毕业设计学生疫情防控信息填报系统Springboot程序](https://img-blog.csdnimg.cn/f826243a9bad4b7ea497fb04306e1586.png)
![[附源码]计算机毕业设计JAVA校园摄影爱好者交流网站](https://img-blog.csdnimg.cn/2715e03f732a40c4a33233c50239148a.png)




![[附源码]Python计算机毕业设计Django面包连锁店管理系统](https://img-blog.csdnimg.cn/49ffb26f9ea34915a7370264d320e4c9.png)




![[附源码]计算机毕业设计学习互助辅助系统Springboot程序](https://img-blog.csdnimg.cn/a10517cd85c14ea09b6ef73a9776c7c4.png)