目录
- 01 初识 Kafka
- 02 topic & partition
- 03 Kafka 分布式
最近在学习 Kafka(别问,问就是公司在用 ),将学习过程中的笔记整理出来分享给大家,就当是入入门
01 初识 Kafka
Kafka 最早是由 LinkedIn 公司开发的,作为其自身业务消息处理的基础,后 LinkedIn 公司将Kafka 捐赠给 Apache,现在已经成为 Apache 的一个顶级项目了
Kafka 作为一个高吞吐的分布式的消息系统,目前已经被很多公司应用在实际的业务中了,并且与许多数据处理框架相结合,比如 Hadoop,Spark 等
与传统的消息队列相比(RaabitMQ、RocketMQ等)除了异步、消峰、解耦三大经典场景之外,Kafka 有着更多的适用场景:
- Kafka 被设计为一个分布式系统,便于向外拓展
- Kafka 支持高吞吐量
- Kafka 可以将消息持久化到磁盘,因此可以用于批量消费
Kafka 角色
- 生产者(producer):也叫发布者,负责创建消息
- 消费者(consumer):也叫订阅者,负责消费(读取)消息
- Kafka server(broker):producer 和 consumer 都是 Kafka 的 客户端,Kafka 服务端通常被称作 broker
02 topic & partition
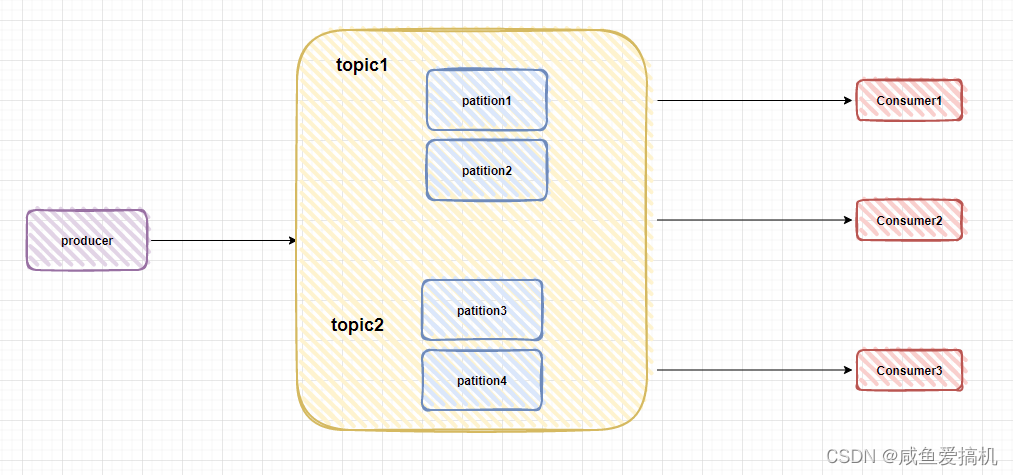
Kafka 是发布/订阅模型,消息以 topic 来分类,每一个 topic 都对应一个消息队列,订阅这个 topic 的 consumer 都会能够消费到对应的消息
为了提高吞吐量,实现 topic 的负载均衡,Kafka 在 topic 下又引用了分区(partition)的概念,能够大大提高消费速率
例如某个 topic 下有 n 个队列,那么这个 topic 的并发度就提高 n,同时可以支持 n 个 consumer 并行消费该 topic 中的消息
对于每一个 topic ,Kafka 会维护其 partition 下的 log,如下图所示
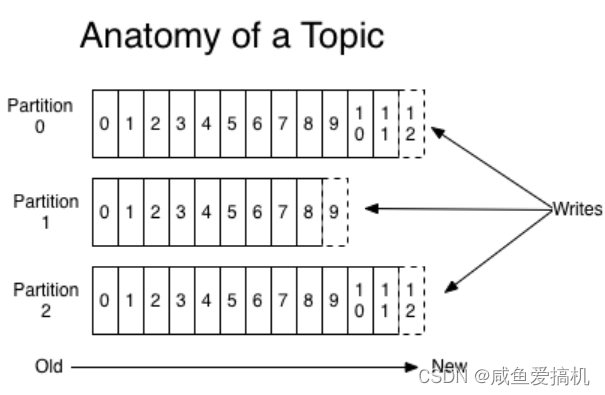
每一个 patition 都是一个顺序的、不可变的消息队列,并且可以持续地添加。patition 中的消息都被分配了一个唯一的序列号,也叫做偏移量(offset)
这就会导致 Kafka 是没有办法删除消息的,Kafka 会保持所有的消息,无论消息是否被消费,保持到它们过期
实际上 consumer 只是拥有 offset,正常情况当 consumer 消费消息的时候,offset 也线性的的增加,consumer 可以将 offset 重置为更老的一个 offset,重新读取消息
因为每一个 consumer 对应一个 partition,所以不会影响其他 consumer 的操作
PS:topic 是逻辑上的概念,消息真正是存储到 partition 中去的
03 Kafka 分布式
Kafka 一开始就被设计成了分布式的架构,有集群(cluster)的概念
一个 Kafka 服务器被称为 broker,broker 接收 producer 的消息并存入磁盘,consumer 连接 broker 消费消息
若干个 broker 组成一个 cluster,集群内某个 broker 会成为集群控制器(cluster controller),负责管理集群,包括分配分区给 broker,监控 broker 等
在 cluster 中,一个分区由一个 broker 负责,这个 broker 是这个分区中的 leader,当然一个分区可以被复制到多个 broker 上实现冗余
当broker出现故障时还可以将其分区重新分配到其他的broker上,保证高可用性
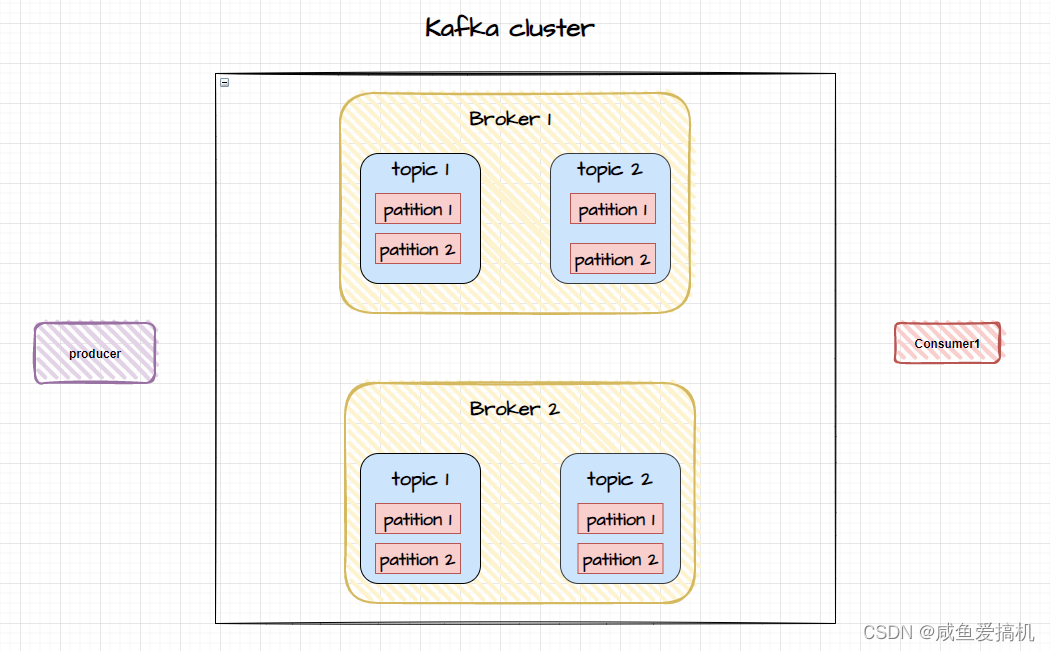
Kafka是如何实现数据冗余的呢?
为了实现数据冗余,保证业务的高可用性,Kafka 引入了副本的概念
在 Kafka 集群里,副本有两种角色:
1、对外提供读写服务的称之为 leader;
2、不对外提供读写服务的称之为 follower,follower 会去同步 leader 的数据以此来保证数据一致性
Kafka 会尽量的把 partition 的副本均分在不同的 broker 上,并从中挑选一个作为 leader 副本
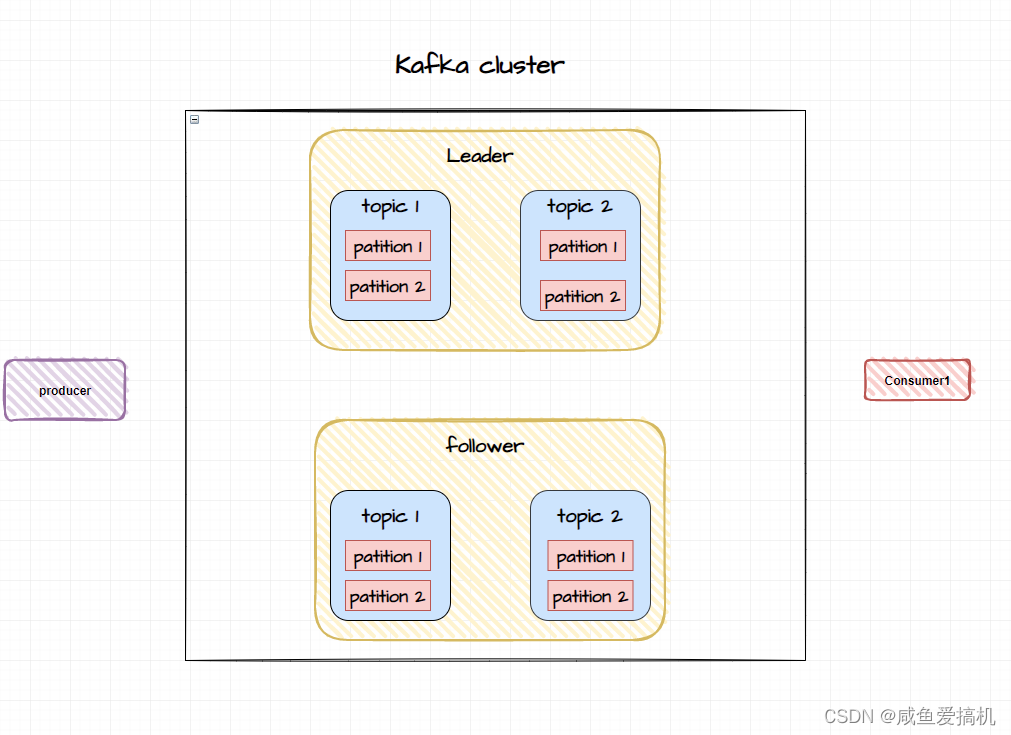
如上图所示:每个 broker 有两个主题,每个主题有两个分区,每个分区有一个副本,分别在不同的 broker 上
只要还存在一个副本,那么 producer 提交的数据就不会丢失,如果某些副本落后于 leader 副本,那么落后的副本就会被移出
如果 leader 副本所在的主机宕机,那么集群就会从剩余的 follower 副本中重新挑选一个副本作为新的 leader 副本,但不是所有的 follower 都有资格去竞选 leader 的(有些数据落后于 leader 太多的 follower 是不能参加竞选的)
为了能够更好地管理副本,Kafka 引入了 ISR——Kafka 动态维护的一组同步副本集合
每个 topic 下的 partition 都有自己的 ISR 列表,ISR 中所有的 follower 都与 leader 保持同步状态,而且 leader 也在 ISR 列表中,只有在自己 ISR 列表中的副本才能参与 leader 竞选
ISR 中的副本是如何保持同步的呢?
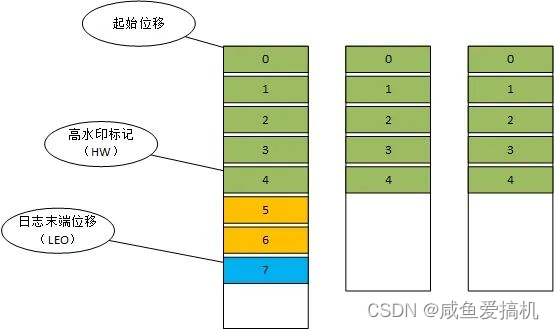
每个 partition 的副本中都会维护三个位移量:
- 起始位移:副本中第一条消息的位置
- 高水印标记(HW):表示副本最新一条被提交的消息的位置,这个值决定了 consumer 可以读到的消息最大范围,超过 HW 的消息(图中超过5,6)属于未提交消息,consumer 是读取不到的
- 日志末端位移(LEO),表示下一条代写入消息的位移,也就是说 LEO 指向的位置是没有消息的,当写入一条消息时 LEO 会加1
leader 和 follower 都具有这三个位移量,partition 的 HW 值就是 leader 的 HW 值,并且 leader 所在的 broker 上还保存了 follwer 的 HW 和 LEO 值
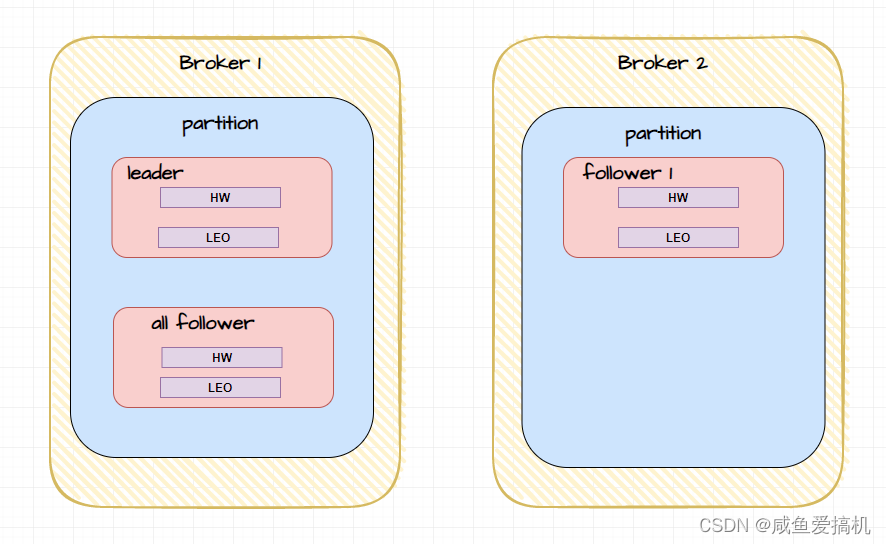
什么时候更新 LEO 值
我们知道,leader 所在的 broker 上保存了所有 follower 的 HW 和 LEO 值,同时 follower 所在的 broker 也保存了自己的 HW 和 LEO
producer 向 leader 写入数据,那么 leader 的 LEO 就会增加,follower 向 leader 同步数据并写入自己的日志文件时 follower 的 LEO 也会增加
leader 所在的 broker 保存的 follower 的 LEO 值是在 leader 收到 follower 的同步数据请求后和真正发送数据给 follower 之前进行更新的,而且发送同步数据请求的时候 follower 会发送自己的 HW 值,leader 所在的 broker 上保存的 follower 的 LEO 值就是 follower 同步数据是时发送的 HW 值
什么时候更新 HW 值
- follower
follower 收到数据后需要写入日志里,然后就会更新自己的 LEO 值,更新完之后再去更新自己的 HW 值:leader 发送给 follower 的数据中包含 leader 自己的 HW,foloower 在更新完自己的 LEO 之后会将自己的 LEO 值和 leader 的 HW 值进行比较,取最小值来设置自己的 HW 值
- leader
leader 更新 HW 有两个场景:
1、producer 写入新的消息后,leader 更新自己的 LEO 并尝试更新 HW
2、leader 从日志中读取了数据并发送给 follower后尝试更新 HW
以上两个场景都是尝试更新,而不是一定更新,因为更新原则是比较 leader 的 LEO 和其保存的所有 follower 的 LEO 值,小的那个就是 leader 的 HW 值
例如初始状态下(leader LEO 和 HW 分别为 0,follower 的 LEO 和 HW 也为0)如果写入了一条消息,那么 leader 的 LEO 进行了更新变成了1,但此时 follower 的 LEO 为 0(因为消息还没同步)比较 leader 的 LEO 和其保存的所有 follower 的 LEO 值,取最小值是 0,所以 leader 的 HW 也是 0,故不需要更新
(上述机制由于有时间差问题导致Follower需要进行两轮拉取才能完成HW的更新,所以会出现数据丢失情况,所以在0.11版本中引入了Leader Epoch机制来解决)
如何知道 leader 和 follower 之间数据不同步?
0.9版本之前是按照消息个数来做的,0.9之后是时间,默认是10秒,如果一个 Follower 落后Leader 的时间持续超过 10 秒则该 Follower 被认为不是同步的
这篇文章主要是Kafka入门,由于Kafka 的知识体系有点庞大,还涉及到了别的概念,后面我会逐步跟大家分享
![计算机系统基础实验——数据的机器级表示(计算浮点数 f 的绝对值[f])](https://img-blog.csdnimg.cn/301f8f3d414a4b5195bbeed611cbb3ce.png)








![计算机毕业论文Java项目源码下载S2SH智慧社区管理系统[包运行成功]](https://img-blog.csdnimg.cn/e7acd83e159b4a80b23ffee0102f71fb.png)

![[附源码]计算机毕业设计springboot右脑开发教育课程管理系统](https://img-blog.csdnimg.cn/79802d599433464ab401b0b8a5588e8a.png)