文章目录
- 集成Flink
- 编程示例
- 打包运行
- CDC入湖
- 概述
- MySQL 启用 binlog
- 初始化MySQL 源数据表
- 准备Jar包依赖
- flink读取mysql binlog写入kafka
- flink读取kafka数据并写入hudi数据湖
- 调优
- Memory
- Parallelism
- Compaction
- 集成Hive
- 集成步骤
- Flink同步Hive
- Hive Catalog
集成Flink
编程示例
本节通过一个简单Flink写入Hudi表的编程示例,后续可结合自身业务拓展,先创建一个Maven项目,这次就使用Java来编写Flink程序。
由于中央仓库没有scala2.12版本的资源,前面文章已经编译好相关jar,那这里就将hudi-flink1.15-bundle-0.12.1.jar手动安装到本地maven仓库
mvn install:install-file -DgroupId=org.apache.hudi -DartifactId=hudi-flink_2.12 -Dversion=0.12.1 -Dpackaging=jar -Dfile=./hudi-flink1.15-bundle-0.12.1.jar
Pom文件内容添加如下内容:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.itxs</groupId>
<artifactId>hudi-flink-demo</artifactId>
<version>1.0</version>
<name>hudi-flink-demo</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<scala.version>2.12.10</scala.version>
<scala.binary.version>2.12</scala.binary.version>
<hoodie.version>0.12.1</hoodie.version>
<hadoop.version>3.3.4</hadoop.version>
<flink.version>1.15.1</flink.version>
<slf4j.version>2.0.5</slf4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-flink_${scala.binary.version}</artifactId>
<version>${hoodie.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.10.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>${project.build.sourceEncoding}</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.4.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
创建一个HudiDemo的Java文件实现一个简单写入hudi表流程
package cn.itxs;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.contrib.streaming.state.EmbeddedRocksDBStateBackend;
import org.apache.flink.contrib.streaming.state.PredefinedOptions;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.util.concurrent.TimeUnit;
public class HudiDemo
{
public static void main( String[] args )
{
//StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 本地启动flink的web页面
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
EmbeddedRocksDBStateBackend embeddedRocksDBStateBackend = new EmbeddedRocksDBStateBackend(true);
embeddedRocksDBStateBackend.setDbStoragePath("file:///D:/rocksdb");
embeddedRocksDBStateBackend.setPredefinedOptions(PredefinedOptions.SPINNING_DISK_OPTIMIZED_HIGH_MEM);
env.setStateBackend(embeddedRocksDBStateBackend);
env.enableCheckpointing(TimeUnit.SECONDS.toMillis(5), CheckpointingMode.EXACTLY_ONCE);
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
checkpointConfig.setCheckpointStorage("hdfs://hadoop1:9000/checkpoints/flink");
checkpointConfig.setMinPauseBetweenCheckpoints(TimeUnit.SECONDS.toMillis(2));
checkpointConfig.setTolerableCheckpointFailureNumber(5);
checkpointConfig.setCheckpointTimeout(TimeUnit.MINUTES.toMillis(1));
checkpointConfig.setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
tableEnv.executeSql("CREATE TABLE source_a2 (\n" +
" uuid varchar(20),\n" +
" name varchar(10),\n" +
" age int,\n" +
" ts timestamp(3),\n" +
" `partition` varchar(20),\n" +
" PRIMARY KEY(uuid) NOT ENFORCED\n" +
" ) WITH (\n" +
" 'connector' = 'datagen',\n" +
" 'rows-per-second' = '1'\n" +
")"
);
tableEnv.executeSql("CREATE TABLE a2 (\n" +
" uuid varchar(20),\n" +
" name varchar(10),\n" +
" age int,\n" +
" ts timestamp(3),\n" +
" `partition` varchar(20),\n" +
"PRIMARY KEY(uuid) NOT ENFORCED\n" +
" ) WITH (\n" +
" 'connector' = 'hudi',\n" +
" 'path' = 'hdfs://hadoop1:9000/tmp/hudi_flink/a2',\n" +
" 'table.type' = 'MERGE_ON_READ'\n" +
")"
);
tableEnv.executeSql("insert into a2 select * from source_a2");
}
}
通过使用createLocalEnvironmentWithWebUI开启动FlinkWebUI,也即是可以在本地上查看flink的web页面
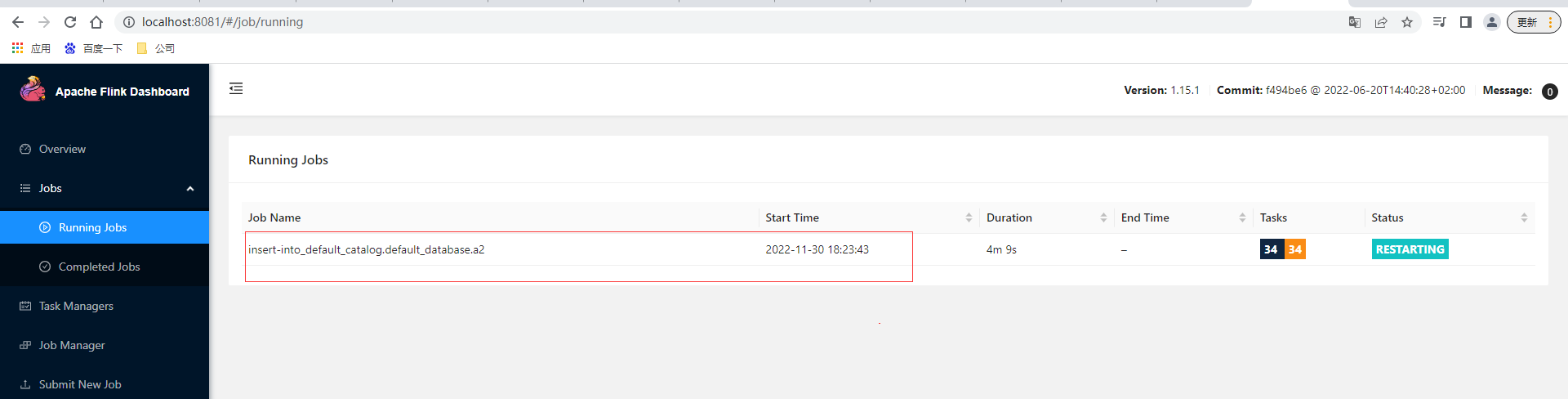
本地rocksdb状态后端也有对应的存储数据
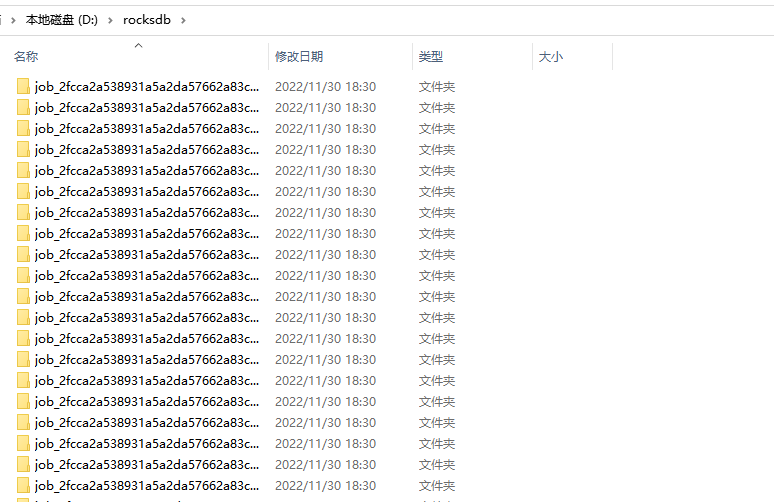
HDFS上也可以查看到刚刚创建的hudi表信息
打包运行
对上面小修改一下代码,将最前面的环境中注释createLocalEnvironmentWithWebUI和setDbStoragePath,放开getExecutionEnvironment;将表名改为a3,执行mvn package编译打包,将打包的文件上传
flink run -t yarn-per-job -c cn.itxs.HudiDemo /home/commons/flink-1.15.1/otherjars/hudi-flink-demo-1.0.jar
运行日志如下
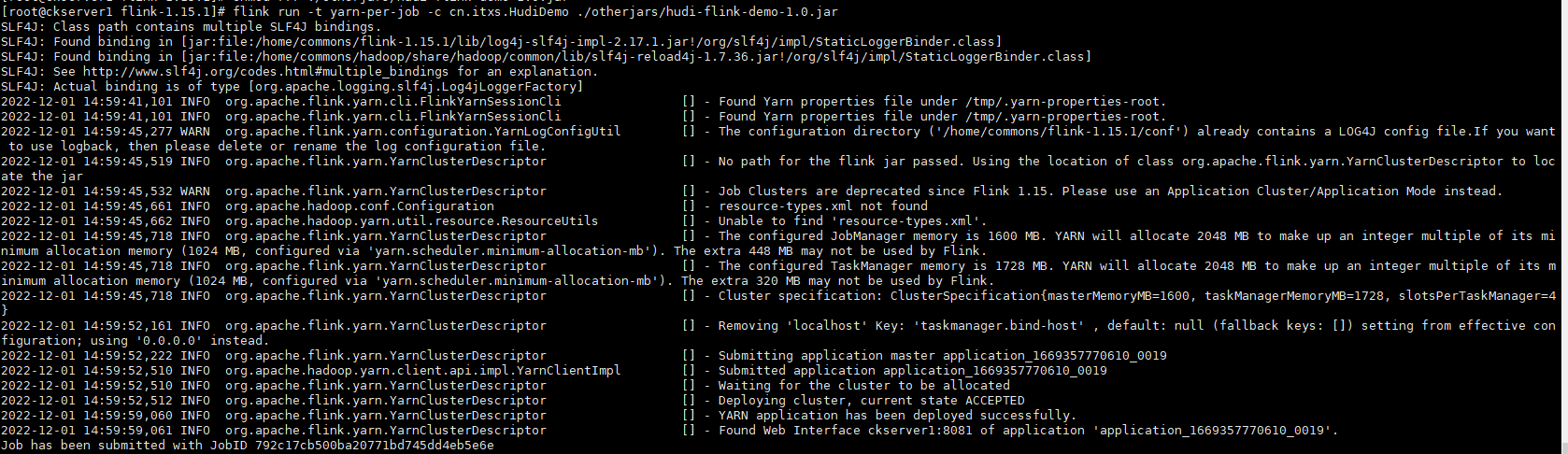
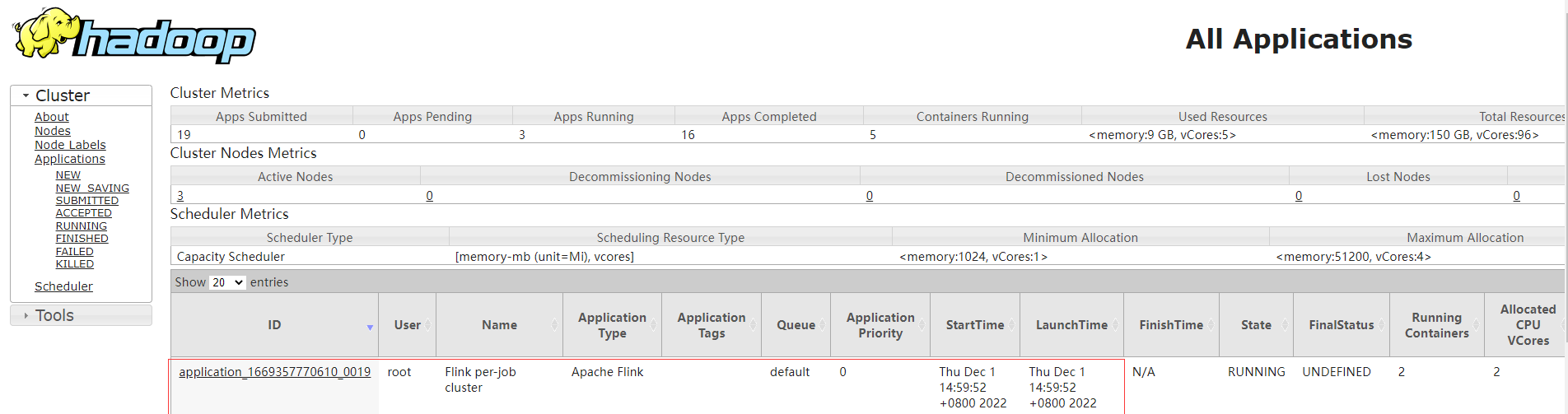
查看Yarn的application_1669357770610_0019
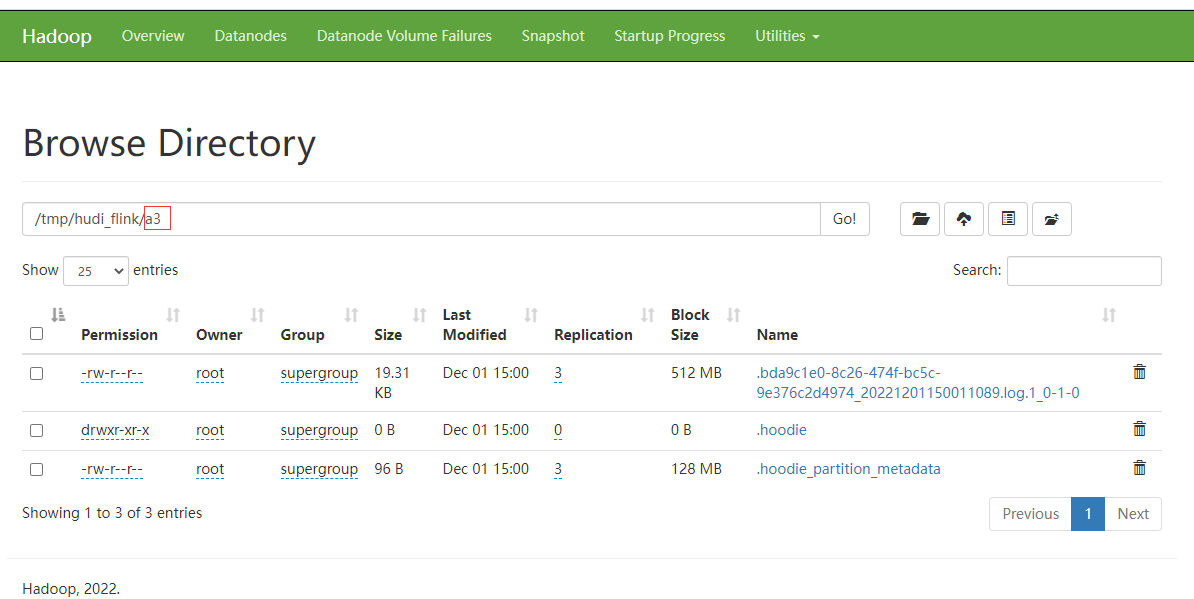
查看HDFS也可以查看到刚刚创建的hudi表信息
CDC入湖
概述
CDC 即 Change Data Capture 变更数据捕获,可以通过 CDC 得知数据源表的更新内容(包含Insert Update 和 Delete),并将这些更新内容作为数据流发送到下游系统。捕获到的数据操作具有一个标识符,分别对应数据的增加,修改和删除。
- +I:新增数据。
- -U:一条数据的修改会产生两个U标识符数据。其中-U含义为修改前数据。
- +U:修改之后的数据。
- -D:删除的数据。
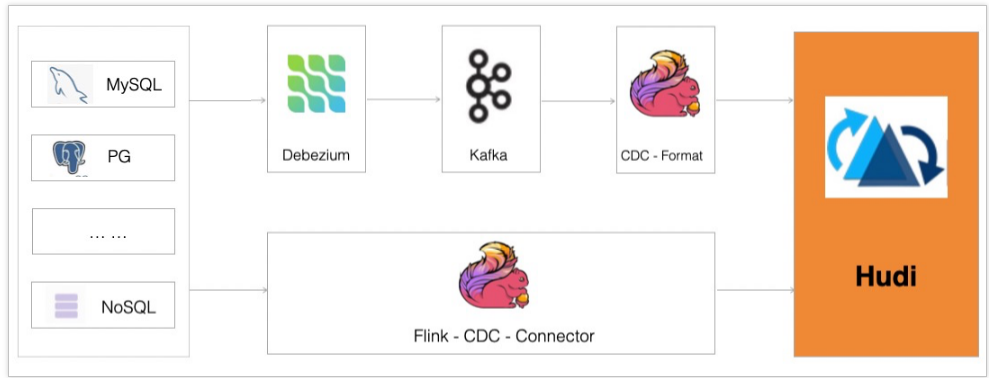
CDC数据保存了完整的数据库变更,可以通过以下任意一种方式将数据导入Hudi:
- 对接CDC Format,消费Kafka数据的同时导入Hudi。支持debezium-json、canal-json和maxwell-json三种格式,该方式优点是可扩展性强,缺点是需要依赖Kafka和Debezium数据同步工具。
- 通过Flink-CDC-Connector直接对接DB的Binlog,将数据导入Hudi。该方式优点是轻量化组件依赖少。
说明
- 如果无法保证上游数据顺序,则需要指定write.precombine.field字段。
- 在CDC场景下,需要开启changelog模式,即changelog.enabled设为true。
下面则演示上面第一种方式方式的使用
MySQL 启用 binlog
下面以 MySQL 5.7 版本为例说明。修改my.cnf文件,增加:
server_id=1
log_bin=mysql-bin
binlog_format=ROW
expire_logs_days=30
初始化MySQL 源数据表
先创建演示数据库 test和一张 student 表
create database test;
use test;
CREATE TABLE `student` (
`id` INT NOT NULL AUTO_INCREMENT,
`name` varchar(10) NOT NULL,
`age` int NOT NULL,
`class` varchar(10) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE = InnoDB CHARSET = utf8;
准备Jar包依赖
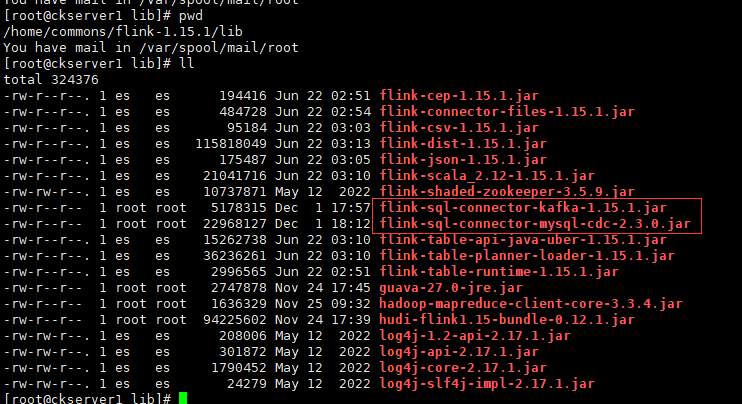
将flink-sql-connector-mysql-cdc-2.3.0.jar和flink-sql-connector-kafka-1.15.1.jar上传到flink的lib目录下
flink-sql-connector-mysql-cdc-2.3.0.jar可以从github上下载 https://github.com/ververica/flink-cdc-connectors
flink-sql-connector-kafka-1.15.1.jar直接在maven仓库下
flink读取mysql binlog写入kafka
- 创建mysql表
CREATE TABLE student_binlog (
id INT NOT NULL,
name STRING,
age INT,
class STRING,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'mysqlserver',
'port' = '3308',
'username' = 'root',
'password' = '123456',
'database-name' = 'test',
'table-name' = 'student'
);
- 创建kafka表
create table student_binlog_sink_kafka(
id INT NOT NULL,
name STRING,
age INT,
class STRING,
PRIMARY KEY (`id`) NOT ENFORCED
) with (
'connector'='upsert-kafka',
'topic'='data_test',
'properties.bootstrap.servers' = 'kafka1:9092',
'properties.group.id' = 'testGroup',
'key.format'='json',
'value.format'='json'
);
- 将mysql binlog日志写入kafka
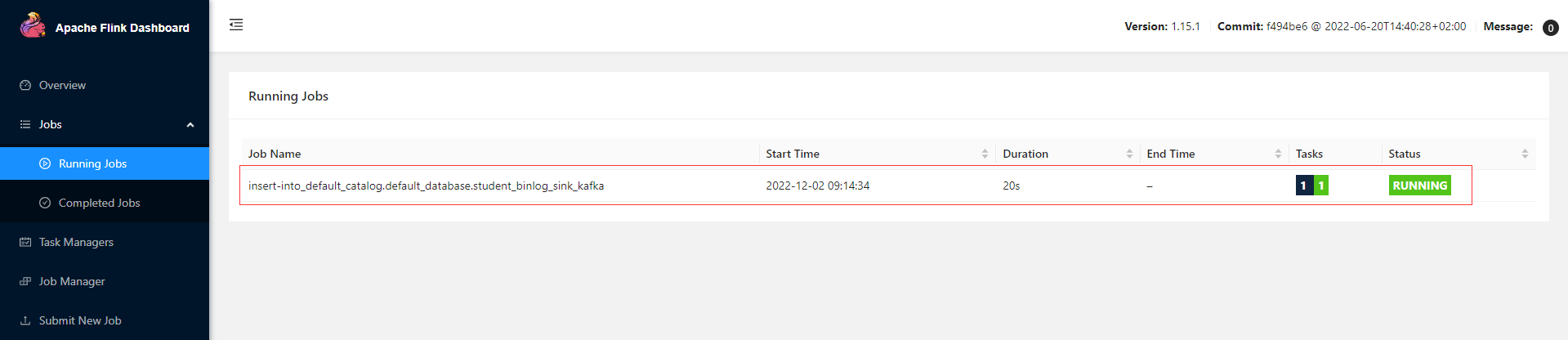
insert into student_binlog_sink_kafka select * from student_binlog;

查看Flink的Web UI,可以看到刚才提交的job
开启tableau方式查询表
set 'sql-client.execution.result-mode' = 'tableau';select * from student_binlog_sink_kafka;
往mysql的student表插入和更新数据测试下
INSERT INTO student VALUES(1,'张三',16,'高一3班');
COMMIT;
INSERT INTO student VALUES(2,'李四',18,'高三3班');
COMMIT;
UPDATE student SET NAME='李四四' WHERE id = 2;
COMMIT;

flink读取kafka数据并写入hudi数据湖
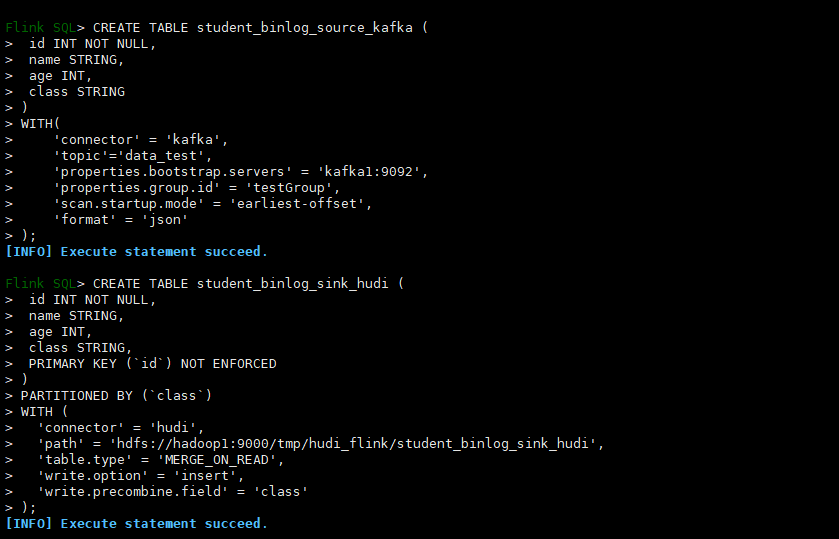
- 创建Kafka源表
CREATE TABLE student_binlog_source_kafka (
id INT NOT NULL,
name STRING,
age INT,
class STRING
)
WITH(
'connector' = 'kafka',
'topic'='data_test',
'properties.bootstrap.servers' = 'kafka1:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);
- 创建hudi目标表
CREATE TABLE student_binlog_sink_hudi (
id INT NOT NULL,
name STRING,
age INT,
class STRING,
PRIMARY KEY (`id`) NOT ENFORCED
)
PARTITIONED BY (`class`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://hadoop1:9000/tmp/hudi_flink/student_binlog_sink_hudi',
'table.type' = 'MERGE_ON_READ',
'write.option' = 'insert',
'write.precombine.field' = 'class'
);
- 将kafka数据写入hudi表
insert into student_binlog_sink_hudi select * from student_binlog_source_kafka;
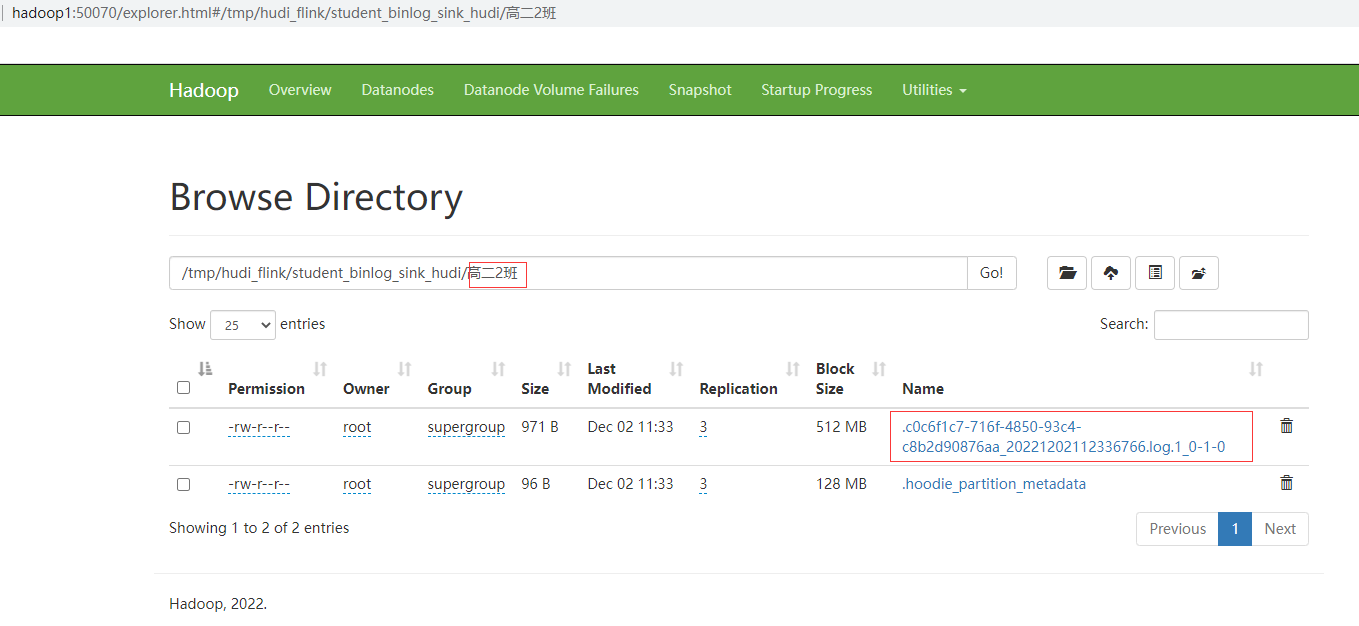
mysql中student表新增加2条数据
INSERT INTO student VALUES(3,'韩梅梅',16,'高二2班');
INSERT INTO student VALUES(4,'李雷',16,'高二2班');
COMMIT;
查看HDFS中已经有相应的分区和数据了
调优
Memory
| 参数名称 | 描述 | 默认值 | 备注 |
|---|---|---|---|
| write.task.max.size | 每个write task使用的最大内存,超过则对数据进行flush | 1024MB | write buffer使用的内存 = write.task.max.size - compaction.max_memory,当write buffer总共使用的内存超过限制,则将最大的buffer进行flush |
| write.batch.size | 数据写入batch的大小 | 64MB | 推荐使用默认配置 |
| write.log_block.size | Hudi的log writer将数据进行缓存,等达到该参数限制,才将数据flush到disk形成LogBlock | 128MB | 推荐使用默认配置 |
| write.merge.max_memory | COW类型的表,进行incremental data和data file能使用的最大heap size | 100MB | 推荐使用默认配置 |
| compaction.max_memory | 每个write task进行compaction能使用的最大heap size | 100MB | 如果是online compaction,且资源充足,可以调大该值,如1024MB |
Parallelism
| 参数名称 | 描述 | 默认值 | 备注 |
|---|---|---|---|
| write.tasks | write task的并行度,每一个write task写入1~N个顺序buckets | 4 | 增加该值,对小文件的数据没有影响 |
| write.bucket_assign.tasks | bucket assigner operators的并行度 | Flink的parallelism.default参数 | 增加该值,会增加bucket的数量,所以也会增加小文件的数量 |
| write.index_boostrap.tasks | index bootstrap的并行度 | Flink的parallelism.default参数 | |
| read.tasks | read operators的并行度 | 4 | |
| compaction.tasks | online compaction的并行度 | 4 | 推荐使用offline compaction |
Compaction
只适用于online compaction
| 参数名称 | 描述 | 默认值 | 备注 |
|---|---|---|---|
| compaction.schedule.enabled | 是否定期生成compaction plan | true | 即使compaction.async.enabled = false,也推荐开启该值 |
| compaction.async.enabled | MOR类型表默认开启Async Compaction | true | false表示关闭online compaction |
| compaction.trigger.strategy | 触发compaction的Strategy | num_commits | 可选参数值:1. num_commits:delta commits数量达到多少;2. time_elapsed:上次compaction过后多少秒;3. num_and_time:同时满足num_commits和time_elapsed;4. num_or_time:满足num_commits或time_elapsed |
| compaction.delta_commits | 5 | ||
| compaction.delta_seconds | 3600 | ||
| compaction.target_io | 每个compaction读写合计的目标IO,默认500GB | 512000 |
集成Hive
hudi源表对应一份hdfs数据,可以通过spark,flink 组件或者hudi客户端将hudi表的数据映射为hive外部表,基于该外部表, hive可以方便的进行实时视图,读优化视图以及增量视图的查询。
集成步骤
这里以hive3.1.3(关于hive可以详细查看前面的文章)、 hudi 0.12.1为例, 其他版本类似
将hudi-hadoop-mr-bundle-0.9.0xxx.jar , hudi-hive-sync-bundle-0.9.0xx.jar 放到hiveserver 节点的lib目录下
cd /home/commons/apache-hive-3.1.3-bin
cp -rf /home/commons/hudi-release-0.12.1/packaging/hudi-hadoop-mr-bundle/target/hudi-hadoop-mr-bundle-0.12.1.jar lib/
cp -rf /home/commons/hudi-release-0.12.1/packaging/hudi-hive-sync-bundle/target/hudi-hive-sync-bundle-0.12.1.jar lib/
按照需求选择合适的方式并重启hive
nohup hive --service metastore &
nohup hive --service hiveserver2 &

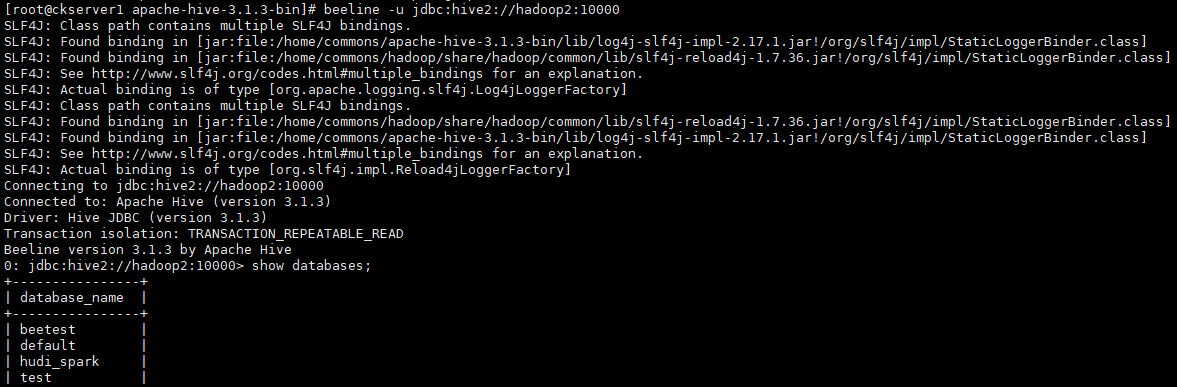
连接jdbc hive2测试,显示所有数据库
Flink同步Hive
Flink hive sync 现在支持两种 hive sync mode, 分别是 hms 和 jdbc 模式。 其中 hms 只需要配置 metastore uris;而 jdbc 模式需要同时配置 jdbc 属性 和 metastore uris,具体配置示例如下
CREATE TABLE t7(
id int,
num int,
ts int,
primary key (id) not enforced
)
PARTITIONED BY (num)
with(
'connector'='hudi',
'path' = 'hdfs://hadoop1:9000/tmp/hudi_flink/t7',
'table.type'='COPY_ON_WRITE',
'hive_sync.enable'='true',
'hive_sync.table'='h7',
'hive_sync.db'='default',
'hive_sync.mode' = 'hms',
'hive_sync.metastore.uris' = 'thrift://hadoop2:9083'
);
insert into t7 values(1,1,1);
Hive Catalog
Flink官网的找到对应文档版本找到connector-hive,下载flink-sql-connector-hive-3.1.2_2.12-1.15.1.jar,上传到flink的lib目录下,建表示例
CREATE CATALOG hive_catalog WITH (
'type' = 'hive',
'default-database' = 'default',
'hive-conf-dir' = '/home/commons/apache-hive-3.1.3-bin/conf/'
);
use catalog hive_catalog;
CREATE TABLE t8(
id int,
num int,
ts int,
primary key (id) not enforced
)
PARTITIONED BY (num)
with(
'connector'='hudi',
'path' = 'hdfs://hadoop1:9000/tmp/hudi_flink/t8',
'table.type'='COPY_ON_WRITE',
'hive_sync.enable'='true',
'hive_sync.table'='h8',
'hive_sync.db'='default',
'hive_sync.mode' = 'hms',
'hive_sync.metastore.uris' = 'thrift://hadoop2:9083'
);
本人博客网站IT小神 www.itxiaoshen.com
![[附源码]计算机毕业设计springboot右脑开发教育课程管理系统](https://img-blog.csdnimg.cn/79802d599433464ab401b0b8a5588e8a.png)

![[附源码]计算机毕业设计springboot在线票务系统](https://img-blog.csdnimg.cn/d905ffb4767b489ca59d362c405d196a.png)


![[附源码]计算机毕业设计学生在线考试系统Springboot程序](https://img-blog.csdnimg.cn/1479dbe3f3e647c5a95dbacaae94cedc.png)
![[附源码]计算机毕业设计颐养天年辅助平台Springboot程序](https://img-blog.csdnimg.cn/e45f0e7b4ac64fc48d380ea1a3f31e33.png)
![[附源码]JAVA毕业设计健康生活网站(系统+LW)](https://img-blog.csdnimg.cn/ce41462a6e3e46d4b29545590a4a8a1f.png)


![[附源码]计算机毕业设计医学图像管理平台Springboot程序](https://img-blog.csdnimg.cn/514aa1ff70e8426fb0fa680dffeca99b.png)

![[附源码]计算机毕业设计springboot在线项目管理](https://img-blog.csdnimg.cn/338aef8c718c42a7940d52db96767bca.png)
