线程池学习_alutimo的博客-CSDN博客尚硅谷java并发包JUC线程池部分学习总结https://blog.csdn.net/qq_41228145/article/details/125650075老生常谈
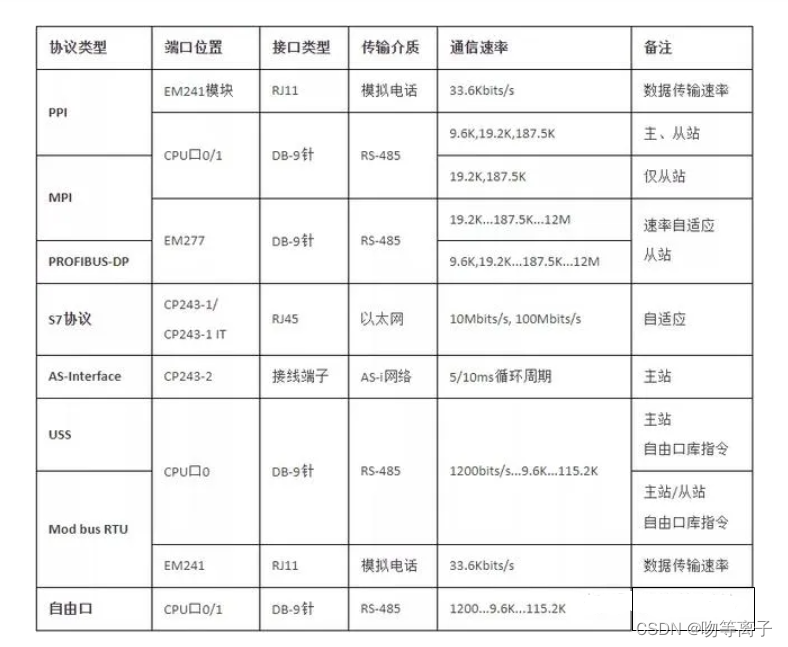
线程池的参数ThreadPoolExecutor.java 的构造器
/**
* Creates a new {@code ThreadPoolExecutor} with the given initial
* parameters.
*
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
* @param maximumPoolSize the maximum number of threads to allow in the
* pool
* @param keepAliveTime when the number of threads is greater than
* the core, this is the maximum time that excess idle threads
* will wait for new tasks before terminating.
* @param unit the time unit for the {@code keepAliveTime} argument
* @param workQueue the queue to use for holding tasks before they are
* executed. This queue will hold only the {@code Runnable}
* tasks submitted by the {@code execute} method.
* @param threadFactory the factory to use when the executor
* creates a new thread
* @param handler the handler to use when execution is blocked
* because the thread bounds and queue capacities are reached
* @throws IllegalArgumentException if one of the following holds:<br>
* {@code corePoolSize < 0}<br>
* {@code keepAliveTime < 0}<br>
* {@code maximumPoolSize <= 0}<br>
* {@code maximumPoolSize < corePoolSize}
* @throws NullPointerException if {@code workQueue}
* or {@code threadFactory} or {@code handler} is null
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
corePoolSize : 核心池的大小,一直再线程池里,即使没活干。
在创建线程池后,默认情况下线程池中没有一个线程,而是等待任务来后,才会创建线程去执行任务。除非调用了 prestartCoreThread()/prestartAllCoreThreads()
即预创建线程(创建所有corepollsize个线程或者一个线程)。当线程数达到了corepoolsize再有任务过来时,就会把任务放入缓存队列中。
核心线程数会被回收吗?需要什么设置?
默认是不会被回收的。但是可以通过下面的方法进行修改。allowCoreThreadTimeOut()
maximumPoolSize:线程池中的最大线程数。
keepAliveTime:如果当前线程池中的线程数超过了corePoolSize,那么如果在keepAliveTime时间内都没有新的任务需要处理,那么超过corePoolSize的这部分线程就会被销毁。默认情况下是不会回收core线程的,可以通过设置allowCoreThreadTimeOut改变这一行为。
Unit:表示KeepAliveTime的时间单位,有7种取值。
workQueue:一个阻塞队列,用来存储等待执行的任务(任务缓存队列)。一般的阻塞队列会有以下几种选择:
ArrayBlockingQueue,需要指定大小 还是指定公平策略
LinkedBlockingQueue,-- 注意这个队列默认大小是 Integer.MAX_VALUE,所以尽量指定
SynchronousQueue
三种形式一般采用 LinkedBlockingQueue 和 SynchronousQueue。
ThreadFactory: 线程工厂,主要用来创建线程。
Handler:表示拒绝处理任务的策略。主要是当线程数量达到了上线,同时任务已经达到了队列的边界也就是上限
线程池的参数ThreadPoolExecutor.java 的构造器的 execute执行方法
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps: --这里直接就告诉你了运行任务分三步来
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
如果当前运行的线程数小于指定核心线程数量,来一个task就创建一个核心线程数
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
如果
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
生活中的例子。比如超市购物
超市今天所有商品打五折,我就拿了一瓶水想去结账,此时超市只有一个收银小妹,结果排在我前面的家伙拿了满满两大车商品结账,由于周围大爷大妈全来买东西,排队也排的贼长,都排到购物区了
我怎么办呢?我就一瓶水啊,我不太想等,此时我有几个选择,
1.跟前面的家伙说,我就一瓶水,让我排你前面去吧
2.我认识超市老板,要老板再开两个结账窗口
3.老老实实排队
假设 我选择了1 会有什么后果,1.别人不同意,给我两个大耳刮子 2我后面的家伙也只拿了一包辣条,看到我插队了,也想插队,后面拿了一包薯片的也想插队
我选择了2,开了两个新结账窗口,因为马上就到我前面的了,他留在原地,我跑到新窗口了,
但是此时排队人太多了,怎么办
1.关闭超市入口
2.限制排队人数或者不管 或者让排在后面的滚蛋
3.开通同城派送服务,你网上下单,购物直接留下
到了网上十一点顾客也差不多买完了,没什么人了,新开的窗口也关闭了,只有最开始的小妹了。
这个故事中
核心线程=最开始的收银小妹
最大线程数=能开的所有结账窗口
队列=限制排队人数 我插队=公平锁 非公平锁
保留时间=十一点了 其他临时窗口关闭了
oom=关闭超市入口
拒绝策略=让排队后面的滚蛋, 不允许排队 和同城派送
这个很多地方不太准确,只是为了让大家理解下
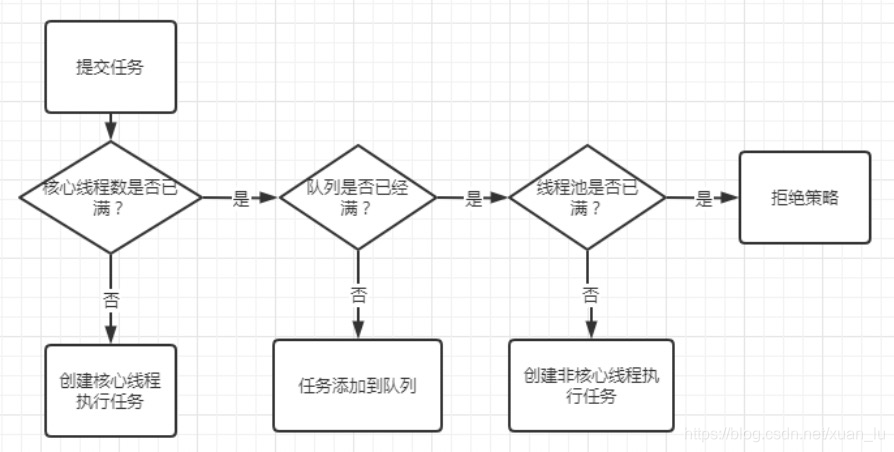
借用图片来说,
1.提交任务 先看核心线程数是否已经满了。
没有满就创建核心线程或者复用核心线程数量->执行任务
满了,就去检查队列还能不能放
2. 检查队列还不能放,有的队列无界 随便放,有的队列有界
能放进去,就把任务放进去,等着前面核心线程完成了再完成队列里的任务
满了放不进去,就去创建非核心线程
3.核心线程全在干活,队列又排满了,活还在不断的发放,创建非核心线程,让非核心线程去干活
非核心线程数量没有满,就开始创建非核心线程干活
活实在是太多了,非核心线程也满了,就开始使用拒绝策略。
4.拒绝策略。
这里有个关键点注意了,就是第2和第3的顺序。
假设任务一个个来,task1 task2 task3...task100 任务的执行顺序不一定是 1 2 3 4 5 6这样的!!!
下面开始进行实验。
一个线程工厂 主要是每个线程命名
一个线程任务 模拟每个线程工作 每个任务工作1s
class MyThreadFactory implements ThreadFactory {
private final String name = "thread-cclovezbf-%s";
private final AtomicInteger nextId = new AtomicInteger(1);
// 定义线程组名称,在利用 jstack 来排查问题时,非常有帮助
public MyThreadFactory(String whatFeatureOfGroup) {
}
@Override
public Thread newThread(Runnable task) {
String threadName = String.format(name, nextId.toString());
System.out.println("线程" + threadName + "已经被创建--");
Thread thread = new Thread(task);
thread.setName(threadName);
nextId.addAndGet(1);
return thread;
}
}
class Task extends Thread {
private final int num;
public Task(int num) {
this.num = num;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " task" + num + "--start--");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " task" + num + "--end--");
}
}测试1 任务被执行的顺序
@Test
public void testCorePoolSize() throws InterruptedException {ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
2,
4,
20, TimeUnit.SECONDS,
new ArrayBlockingQueue<Runnable>(2),
new MyThreadFactory("cclovezbf")
//注意我这里核心2 最大是4
);
for (int i = 1; i < 6; i++) {
System.out.println("开始提交任务"+i);
threadPoolExecutor.execute(new Task(i));
Thread.sleep(1);--
}
threadPoolExecutor.shutdown();
Thread.sleep(300000);
}

提交任务1和2 都创建了线程 ,此时就是核心线程 cclovezbf1 cclovezbf2
提交任务3和4 都是放到队列里了 我设置的队列长度2 此时任务3和任务4 等待被执行
提交任务5,此时队列已满,开始创建非核心线程cclovezbf3
然后线程cclovezbf1 cclovezbf2干完了任务1和任务2,开始从队列找活 找到了任务3和任务4
和上述图顺序一致。
测试2 非核心线程回收
@Test
public void testKeepAlive() throws InterruptedException {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
1,
3,
5, TimeUnit.SECONDS, //只保留5s
new ArrayBlockingQueue<Runnable>(1),
new MyThreadFactory("cclovezbf")
);
for (int i = 1; i < 5; i++) {
System.out.println("开始提交任务"+i);
threadPoolExecutor.execute(new Task(i));
Thread.sleep(1); //这里sleep 1 是为了让打印的更加直观
}
Thread.sleep(6000);
System.out.println("=====休息一会=====");
for (int i = 5; i < 9; i++) {
System.out.println("开始提交任务"+i);
threadPoolExecutor.execute(new Task(i));
Thread.sleep(1); //这里sleep 1 是为了让打印的更加直观
}
Thread.sleep(20000);
threadPoolExecutor.shutdown();
}
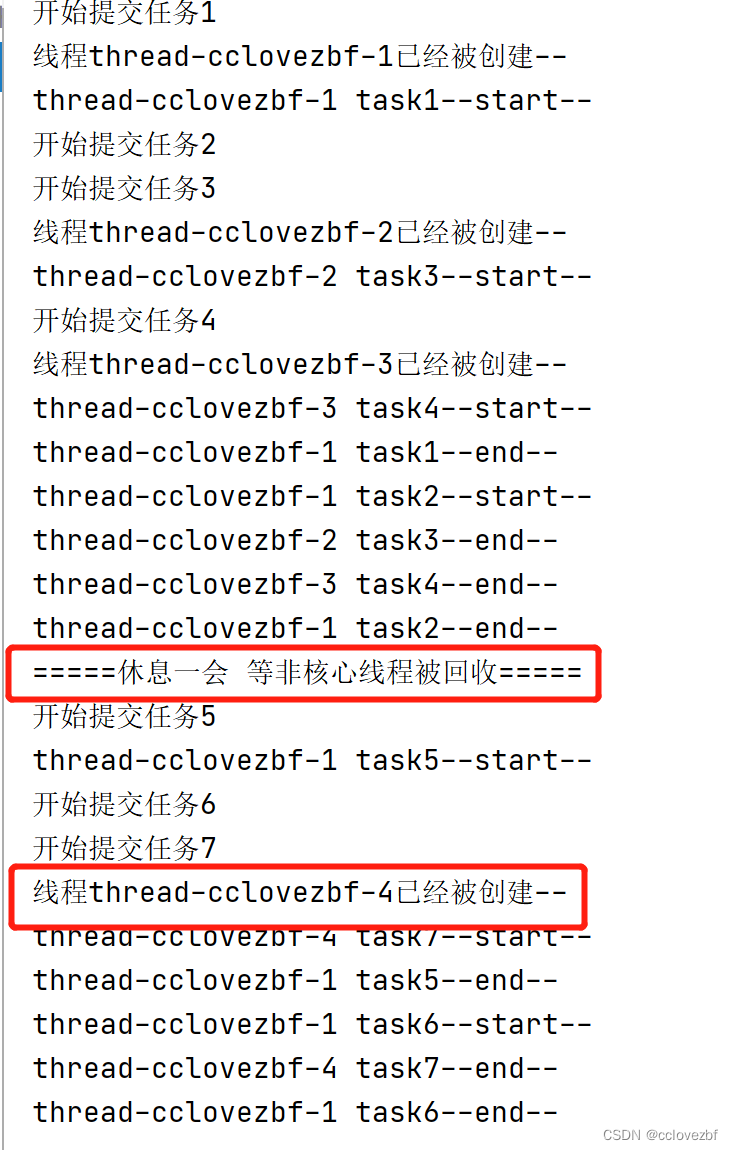
可以看到在sleep6s后,再重新提交任务的时候 cclovezbf1还在,cclovezbf2和3已经不在了,取而代之的是重新创建了cc4。
测试3 队列
队列分为三种
ArrayBlockingQueue, 需要指定大小 还是指定公平策略
LinkedBlockingQueue,-- 注意这个队列默认大小是 Integer.MAX_VALUE,所以尽量指定
SynchronousQueue
首先我们要清楚公平和非公平的策略。
public class FairLockDemo {
static ReentrantLock noFairLock = new ReentrantLock(false);//默认 非公平锁
static ReentrantLock fairLock = new ReentrantLock(true); //公平锁
public static void main(String[] args) throws InterruptedException {
System.out.println("========公平锁===========");
testLock(fairLock);
Thread.sleep(1000);
System.out.println("========非公平锁===========");
testLock(noFairLock);
}
private static void testLock(ReentrantLock lock){
for (int i = 0; i < 3; i++) {
new Thread(() -> {
for (int j = 0; j < 2; j++) {
lock.lock();
System.out.println("当前线程:" + Thread.currentThread().getName()+"获取锁");
try {
Thread.sleep(1);
//这里我故意sleep了1ms 是为了防止 线程1都执行第二次for循环了 线程2和3还没启动
} catch (InterruptedException e) {
e.printStackTrace();
}
lock.unlock();
}
}).start();
}
}
}
参考文章面试突击:公平锁和非公平锁有什么区别?-公平锁和非公平锁区别

这里举个例子,高速路上单行道,1 2 3 开车去从深圳到湖南
公平锁 简单的来说就是排队,在深圳的时候1在前2在中3在后,那么在湖南的时候还是这样,
非公平锁就是有人插队,1时速开80,这谁受得了啊,2很生气直接应急车道超车超到1前面去了,
为什么有这两种锁?个人理解
公平锁 保证了公平,先来先到,比如123 按顺序开车迟早都会开到湖南的,没有问题
非公平锁保证了效率,比如2 3 应急车道超车,后面的4 5 6 7 8....100w都超了1的车,这1啥时候才能开到湖南去啊,但是这种情况就大大的提高了通行效率。
使用场景,比如我们向线程池提交很多任务,
我们希望任务尽量按照先提交先完成的顺序来,比如页面点击一下就是提交一个任务,有的提交了任务肯定是希望尽可能快的获取结果,这种时候用公平锁,(虽然这样会使得完成时间平均增加一点,比如10个任务 每个增加1s 大家也不会有意见),如果使用非公平锁,有的人提交的任务抢不到线程工作,直接增加了10s,那不得贼气。
公平锁执行流程
获取锁时,先将线程自己添加到等待队列的队尾并休眠,当某线程用完锁之后,会去唤醒等待队列中队首的线程尝试去获取锁,锁的使用顺序也就是队列中的先后顺序,在整个过程中,线程会从运行状态切换到休眠状态,再从休眠状态恢复成运行状态,但线程每次休眠和恢复都需要从用户态转换成内核态,而这个状态的转换是比较慢的,所以公平锁的执行速度会比较慢。
非公平锁执行流程
当线程获取锁时,会先通过 CAS 尝试获取锁,如果获取成功就直接拥有锁,如果获取锁失败才会进入等待队列,等待下次尝试获取锁。这样做的好处是,获取锁不用遵循先到先得的规则,从而避免了线程休眠和恢复的操作,这样就加速了程序的执行效率。
还有一个就是队列长度,队列长度过长,等待任务过多会导致oom就不说了。
测试 拒绝策略
private void testRejectHandler(RejectedExecutionHandler policy) throws InterruptedException {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
1,
1,
5, TimeUnit.SECONDS, //只保留5s
new ArrayBlockingQueue<Runnable>(1,false),
new MyThreadFactory("cclovezbf")
);
threadPoolExecutor.setRejectedExecutionHandler(policy);
for (int i = 0; i < 3; i++) {
threadPoolExecutor.execute(new Task(i));
}
threadPoolExecutor.shutdown();
Thread.sleep(10000);
}
@Test
public void testCallerRunsPolicyy() throws InterruptedException {
ThreadPoolExecutor.CallerRunsPolicy callerRunsPolicy = new ThreadPoolExecutor.CallerRunsPolicy();
testRejectHandler(callerRunsPolicy);
}
@Test
public void testAbortPolicy() throws InterruptedException {
ThreadPoolExecutor.AbortPolicy abortPolicy = new ThreadPoolExecutor.AbortPolicy();
testRejectHandler(abortPolicy);
}
@Test
public void testDiscardPolicy() throws InterruptedException {
ThreadPoolExecutor.DiscardPolicy discardPolicy = new ThreadPoolExecutor.DiscardPolicy();
testRejectHandler(discardPolicy);
}
// 8号任务直接不见了
@Test
public void testDiscardOldestPolicy() throws InterruptedException {
ThreadPoolExecutor.DiscardOldestPolicy discardOldestPolicy = new ThreadPoolExecutor.DiscardOldestPolicy();
testRejectHandler(discardOldestPolicy);
}//当触发拒绝策略时,如果线程池未关闭,则直接使用调用者线程,执行任务
ThreadPoolExecutor.CallerRunsPolicy callerRunsPolicy = new ThreadPoolExecutor.CallerRunsPolicy();
//丢弃任务,并抛出异常信息。必须处理好异常,否则会打断当前执行的流程
ThreadPoolExecutor.AbortPolicy abortPolicy = new ThreadPoolExecutor.AbortPolicy();
//从源码中应该能看出来,此拒绝策略是对于当前任务不做任何操作,简单言之:直接丢弃。
ThreadPoolExecutor.DiscardPolicy discardPolicy = new ThreadPoolExecutor.DiscardPolicy();
//当触发拒绝策略时,如果线程池未关闭,则丢弃阻塞队列中最老的一个任务,并将新任务加入.
ThreadPoolExecutor.DiscardOldestPolicy discardOldestPolicy = new ThreadPoolExecutor.DiscardOldestPolicy();
核心线程=最大线程=队列=1 所以能接受2个任务,我提交了4个任务
callerRunsPolicy,直接开启主线程和核心线程去处理任务,多余的任务继续运行

abortPolicy 核心线程满,队列满,直接抛异常

discardPolicy 多余的任务直接丢了,不管了 假装没看到。

discardOldestPolicy,丢最老的任务 处理最新的任务。 上面的丢最新的任务,处理先来的任务

测试 线程创建多少合理
https://www.cnblogs.com/MrLiuZF/p/15188349.html 这篇文章有理有据。
IO密集型=2Ncpu(可以测试后自己控制大小,2Ncpu一般没问题)(常出现于线程中:数据库数据交互、文件上传下载、网络数据传输等等)
计算密集型=Ncpu(常出现于线程中:复杂算法)
线程池如何确定线程数量 这篇文章好像是搜索的主流答案
在高并发的情况下采用线程池,有效的降低了线程创建释放的时间花销及资源开销,如不使用线程池,有可能造成系统创建大量线程而导致消耗完系统内存以及”过度切换”。(在JVM中采用的处理机制为时间片轮转,减少了线程间的相互切换)
那么在高并发的情况下,我们怎么选择最优的线程数量呢?选择原则又是什么呢?这个问题去哪网的技术总监问过我,这里总结一下。
如果是CPU密集型应用,则线程池大小设置为N+1;
对于计算密集型的任务,在拥有N个处理器的系统上,当线程池的大小为N+1时,通常能实现最优的效率。(即使当计算密集型的线程偶尔由于缺失故障或者其他原因而暂停时,这个额外的线程也能确保CPU的时钟周期不会被浪费。- 摘自《Java Concurrency In Practise》
如果是IO密集型应用,则线程池大小设置为2N+1。
任务一般可分为:CPU密集型、IO密集型、混合型,对于不同类型的任务需要分配不同大小的线程池。
CPU密集型任务 尽量使用较小的线程池,一般为CPU核心数+1。 因为CPU密集型任务使得CPU使用率很高,若开过多的线程数,只能增加上下文切换的次数,因此会带来额外的开销。
IO密集型任务 可以使用稍大的线程池,一般为2*CPU核心数。 IO密集型任务CPU使用率并不高,因此可以让CPU在等待IO的时候去处理别的任务,充分利用CPU时间。
混合型任务可以将任务分成IO密集型和CPU密集型任务,然后分别用不同的线程池去处理。 只要分完之后两个任务的执行时间相差不大,那么就会比串行执行来的高效。 因为如果划分之后两个任务执行时间相差甚远,那么先执行完的任务就要等后执行完的任务,最终的时间仍然取决于后执行完的任务,而且还要加上任务拆分与合并的开销,得不偿失。
其实这个用自己做例子来说。你觉得我们能够一心几用?
我们就一个大脑,
io密集任务,可以看作不怎么用大脑的任务,只需要又简单的回应的
如果让你当保安,你是不是可以一下可以看七八个监控画面,
让你和美女聊微信,是不是可以一下和七八个同时聊天
cpu密集任务,可以看做要脑子的任务,
让你写高考题,你能最后一个大题 一个点,这样轮流来么,
让你打游戏,你能同时打王者和lol么。
甚至如果你又平板或者电脑分屏,你看你能不能同时看两篇小说,我试过 脑子根本转不过来,
所以像这种复杂任务还是一个线程干一个活最好。
----------------------------------------------------------------------------------------------------------------------
最后来学习下源码
/**
* Executes the given task sometime in the future. The task
* may execute in a new thread or in an existing pooled thread.
*
* If the task cannot be submitted for execution, either because this
* executor has been shutdown or because its capacity has been reached,
* the task is handled by the current {@code RejectedExecutionHandler}.
*
* @param command the task to execute
* @throws RejectedExecutionException at discretion of
* {@code RejectedExecutionHandler}, if the task
* cannot be accepted for execution
* @throws NullPointerException if {@code command} is null
*/
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
如果正在运行的核心线程数小于指定的核心线程数,让接到任务时候,开启一个新的核心线程让它干活
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*如果队列里面能够塞下,就塞
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.如果队列里面塞不下 就开新线程 非核心线程。
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) { --创建核心线程
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) { --放到队列
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command)) --队列满了
reject(command);
else if (workerCountOf(recheck) == 0) --创建非核心线程
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);