目录
Apache Hadoop生态-目录汇总-持续更新
1:Interceptor拦截器的使用场景
2:Interceptor拦截器在采集流程中的位置
3:自定义Interceptor拦截器
pom.xml
拦截器java代码
打包上传
4:使用自定义的拦截器
方式一:把jar包放到flume-1.9.0/lib下
方式二:把jar包放到项目下
Apache Hadoop生态-目录汇总-持续更新
系统环境:centos7
Java环境:Java8
官方文档:http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#flume-interceptors
1:Interceptor拦截器的使用场景
1)对source端的数据进行(简单)清洗,去除无用,不符合要求的数据
2) 对source端的数据校正,比如使用数据时间 代替 采集时间
3) 对source端的数据分类,不同类型的日志可能发送到不同的分析系统。

2:Interceptor拦截器在采集流程中的位置

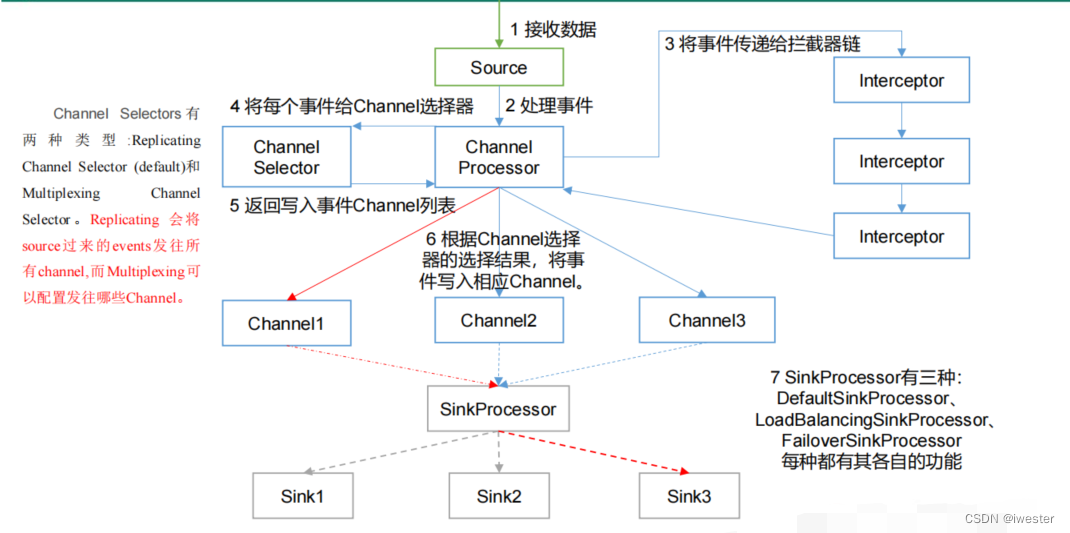
Multiplexing 结构根据 event 中 Header 的某个 key 的值,将不同的 event 发送到不同的 Channel,需要自定义一个 Interceptor,为不同类型的 event 的 Header 中的 key 赋予不同的值
3:自定义Interceptor拦截器
pom.xml
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<flume.version>1.9.0</flume.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>${flume.version}</version>
<scope>provided</scope> <!--provided 不打入jar包, 服务器上有-->
</dependency>
<!--fastjson用于解析json的-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>拦截器java代码
实现功能:ETL数据清洗,判断数据是否完整, 解决零点漂移的问题
package com.wester.flume.interceptor2;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.wester.flume.interceptor.JSONUtils;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
/**
* ETL数据清洗,判断数据是否完整, 解决零点漂移的问题
* @author wester
* @create 2022-12-05 14:26
*/
public class ETLInterceptor implements Interceptor {
@Override
public void initialize() {
}
/**
* 处理flume单条数据
* 取数据,进行校验,是否是json, 是否缺少数据
* @param event
* @return
*/
@Override
public Event intercept(Event event) {
// 获取头信息
Map<String, String> headers = event.getHeaders();
// 获取内容信息
byte[] body = event.getBody();
String log = new String(body, StandardCharsets.UTF_8);
// 判断内容是否是标准json
if (JSONUtils.isJSONValidate(log)){
// 解决零点漂移的问题,用数据里的时间覆盖headers里的timestamp, 主要是sink hdfs
JSONObject jsonObject = JSON.parseObject(log);
String ts = jsonObject.getString("ts");
// 将ts付给headers里的timestamp
headers.put("timestamp", ts);
return event;
}
return null;
}
// 处理flume多条数据
@Override
public List<Event> intercept(List<Event> list) {
// 循环每一条,如果发现不合格的数据就删掉
Iterator<Event> iterator = list.iterator();
while (iterator.hasNext()){
Event next = iterator.next();
if (intercept(next) == null){
// 发现不合格的数据就删掉
iterator.remove();
}
}
return list;
}
@Override
public void close() {}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new ETLInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
打包上传
打包得到jar包:project_v4_flume.jar
4:使用自定义的拦截器
方式一:把jar包放到flume-1.9.0/lib下
1)打包放到/usr/local/flume-1.9.0/lib目录下
2)复制拦截器全类名
com.wester.flume.interceptor2.ETLInterceptor
3)定义flume采集job时直接使用
# 定义source
file_flume_kafka.sources.r1.type = TAILDIR
....
file_flume_kafka.sources.r1.interceptors = i1
# 配置拦截器,全类名+$Builder
file_flume_kafka.sources.r1.interceptors.i1.type = com.wester.flume.interceptor2.ETLInterceptor$Builder
4) 启动flume-ng采集
因为把jar包上传到flume的lib下,所以flume-ng启动时不需要指定
flume-ng agent --name file_flume_kafka --conf-file /flume2.conf -Dflume.root.logger=INFO,console方式二:把jar包放到项目下
1)打包放到项目flume_job/jar目录下
2)复制拦截器全类名
com.wester.flume.interceptor2.ETLInterceptor
3)定义flume采集job时直接使用
# 定义source
file_flume_kafka.sources.r1.type = TAILDIR
....
file_flume_kafka.sources.r1.interceptors = i1
# 配置拦截器,全类名+$Builder
file_flume_kafka.sources.r1.interceptors.i1.type = com.wester.flume.interceptor2.ETLInterceptor$Builder
4) 启动flume-ng采集
jar不在flume的lib下,所以flume-ng启动时需要手动指定
flume-ng agent --name file_flume_kafka --conf-file /flume2.conf -C flume_jobs/jar/project_v4_flume.jar -Dflume.root.logger=INFO,console