1.前言
在离线数据研发中,随着业务的快速发展以及业务复杂度的不断提高,数据量的不断增长,尤其得物这种业务的高速增长,必然带来数据逻辑复杂度的提升,数据量越大,复杂度越高,对任务的性能的要求就越高,因此,任务性能的优化就成了大家必然的话题,在离线数仓招聘中,这几乎成了必考题目。
大数据领域,为了提高超大数据量的计算性能,几代人不断在努力,不断榨取着计算机的CPU、内存、磁盘每一个模块的性能,从早期的纵向扩展(提升计算机性能,如IBM、ORACLE 早期推崇的服务器到小型机到大型机的演进)到目前的大规模横向扩展(分布式集群模式),都是旨在提升大数据的性能。
本文重点从在分布式计算模式下,如何来优化任务,大家耳熟能详的常见优化如:mapjoin skewjoin distribute by 等就不多做赘述,本文主要探索技巧、策略及方法。
2.任务优化策略
2.1 优化方向
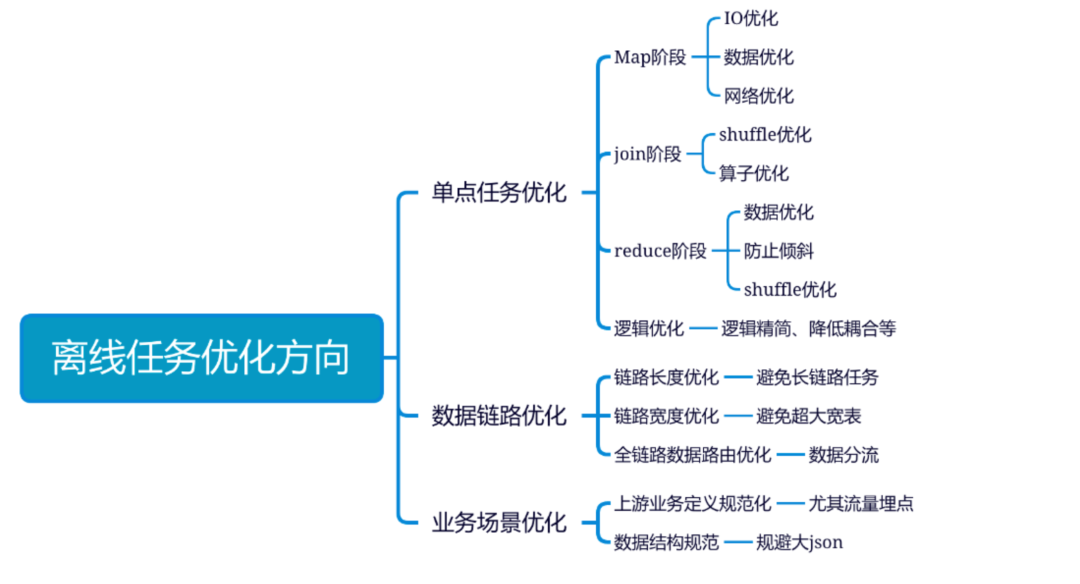
补充说明:目前得物大数据在阿里云的dataworks 环境下,集群层面做了比较多的工作,IO、网络、机架感应等暂时无需过多关注,如有自建集群时,可重点关注,我们重点关注JOIN 和REDUCE 层面,优化细节也重点基于这两个方向做细节展开。
2.2 优化手段
对于优化手段优化方法,我们大多数习惯性从技术手段出发,更多的从算子、逻辑兼容等来处理,但是在某些业务场景下,如埋点日志,数据量一般比较大,这种情况无论技术手段如何干预,都无法解决存储和计算带来的资源消耗,这时候如果要提升SLA,就得从业务场景出发,做好业务的分类分级以及核心数据分流,因此,本文的优化手段会从技术手段和业务手段两方面展开。

-
技术手段
聚焦于技术手段来处理任务,参加上述单点任务优化方向,主要是SQL 逻辑、模型规范、算子优化及可能存在的集群优化
-
业务手段
聚焦于业务特性、业务逻辑来进行处理,基于不同的业务特性及重要程度,从生产、采集、模型、数据消费全链路进行梳理和架构优化,同时形成一套数据链路上的通知及约束机制,避免上游变更带来的下游数据故障及恢复问题。
3.优化实践案例
优化策略中,定义好优化方向、优化手段,接下来,我们选取一些比较有效的沉淀出来的方案,展开讲讲如何来做任务优化。
前文讲述,目前的得物的数据平台特性(dataworks),我们在IO、网络、RPC 通信机制等暂时涉入不深,且对于面向业务的数据研发来言,大部分人不会过多关注底层的实现原理,暂不做过多深入探讨。
我们基于上面方向中的技术手段讲述几个日常常见的优化案例
3.1 数据重分发(Distribute &Rand)
3.1.1 数据重分发的要点
日常数据研发中,最常见的且使用较多的就是数据倾斜或数据量带来的数据重分发(打散或随机),对于数据的重分发,主要分以下几点:
-
优化小文件
-
数据倾斜
-
排序&随机
小文件过多带来的MAP 端资源损耗和数据倾斜是我们日常开发过程中最为常见的性能问题,而这两点大多跟rand()随机数有一定的关系,通过数据分发和打散和规避掉大部分此场景下的问题。
数据重分发一般代码操作如下所示
select c1,c2... from tablename distribute by c1[,...]
select c1,c2... from tablename distribute by rand([,seed])[,...]
对于rand() 我们要注意几点,可让我们在优化任务时,知其然,更知其所以然。
- rand() 随机数的生成规律跟数学概率有莫大的关系,尤其在算法中,会被经常性问到,给定随机生成的N个数,构造等概率事件的发生器,跑题了,继续说回在hive 或odps 场景下,rand() 函数是随机生成的0-1 的double 类型的数字。
- rand(int seed) 函数可以根据种子参数,构造一个稳定的随机值,加上种子参数,得到的结果是相对稳定的,尤其在处理小文件过程中,这一步很重要。
- Hive 和odps 场景中,随机函数多与pmod()、mod()、floor()、ceil() 等函数结合使用,可以根据不同的业务场景,来构造任意范围内的随机整数,比如在处理数据重分发解决数据倾斜的问题时,同时担心影响这种重分发带来过多的小文件,随机数可以这样来取 floor(rand())*N/ceil(rand())+1,取1-N 之间的整数
比如在流量数据里面,因为大量空值时,结合rand函数,解决数据倾斜问题:
select *
from a
left join b on a.order_id = nvl(b.order_id ,concat('hive',rand()))
--b中的order_id 存在大量空值 的时候3.1.2 数据重分发的作用
对于数据重分发,我们主要是用来对处理数据结果进行小文件合并以及对数据处理中的倾斜问题进行优化。在大多数的处理中,我们习惯于使用Distribute by Rand() *N 的方式,其实这个方式可能存在问题,在处理类似问题时候,我们可以选择基于seed种子的Rand函数,来维持随机数的稳定性。这里需要知晓,distribute by 实际上做了一次shuffle的分发,默认是按照给定key进行的hash操作(可以理解为一次repartion重新分区),这里面是可以进行定制分区逻辑的,可以通过重写hive当中partition的接口,实现不同策略的重分发。
- 处理小文件合并
使用方式一:指定固定分发列,做一次shuffle的merge操作,DEMO如下:
SELECT column1, column2,column.... FROM TABLEX WHERE ds = '${bizdate}'DISTRIBUTE BY '${bizdate}',columns1....使用方式二:指定给定的文件数,这里要用到rand()函数了,一般有两种写法:
第一种写法(上文讨论过,这种写法在一定情况下会出现数据问题):
SELECT column1, column2,column.... FROM TABLEX WHERE ds = '${bizdate}'DISTRIBUTE BY FLOOR(RAND()*N)/CEIL(RAND()*N)第二种写法(加随机种子,产生稳定的随机序列):
SELECT column1,column2,column.... FROM ( SELECT column1, column2,column...., FLOOR(RAND(seed)*N) AS rep_partion FROM TABLEX WHERE ds = '${bizdate}')DISTRIBUTE BY rep_partion-
处理JOIN中的倾斜:与上述逻辑同理,主要是借助一次分发,使得需要shuffle的数据能在一个节点进行数据处理。
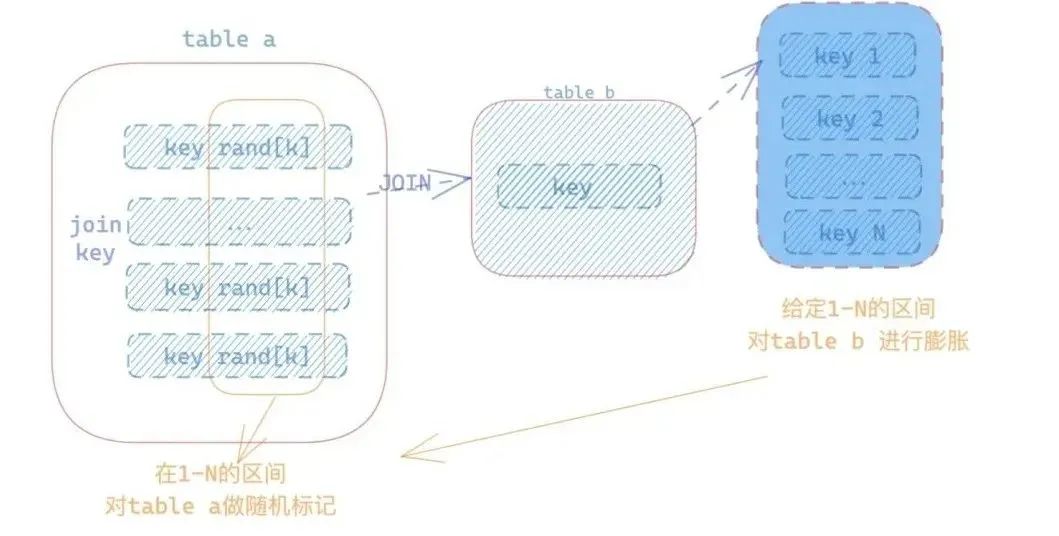
3.2 数据膨胀(Explode)
在join过程中,我们之前提到了一种基于BLOOMFILTER算法的优化方法。在某些情况下,当join的表中出现一个表的量级很大,另外一个表无法mapjoin切热键key在概率分布上呈现随机性,这个时候就可以在一定程度上,对较小表中的join key进行一定程度的膨胀,由于join的发生是在reduce阶段,因此可以构造出稳定的多条主键,在不同的reduce中对数据进行jion操作,进而一定程度上解决join倾斜带来的问题。基本原理如下图所示:
一个小例子,当研发使用数组形式存储数据(sku_ids)时,数仓想要拿到数组中每一个sku_id,使用 lateral view EXPLODE。代码如下:
select order_id
from a
lateral view explode(split(order_ids,',')) v1 as order_id
group by order_id 结果展示:
order_ids order_id
101,102,103 101
101,102,103 102
101,102,103 103
104,105 104
104,105 105目前,膨胀函数已经有开发出来有现成的UDTF函数来支持,可以支撑任意膨胀量级的数据进行膨胀。只需要构造膨胀区间对应的随机函数即可,还是需要用到Rand()函数来实现。
数据膨胀方式带来的问题:
在解决了数据倾斜重新打散的问题之后,在计算层面会增加一定的数据计算量。此外,如果能基于分桶进行二次索引分片,也可以在引擎侧考虑基于该方向的自适应倾斜优化。
3.3 数据分桶(Bucket)
在数据量比较大的情况下,单表数据做分区会存在下游使用效率上的限制,而数据在某些列上(或者构造业务列)存在高度聚集,或者存在可以优化提升的巨大空间,在此时,我们就可以对列进行散列分桶,在分区的基础上进行桶表的设计,桶上可以对应索引向量,将极大的提升数据使用上的效率。
在数据随机抽样、JOIN场景中,也会极大的提升整个数据的计算性能和效率。在hive中,该功能默认是关闭的,需要set hive.enforce.bucketing=true打开支持,odps 下可能无需特别关注,需要注意一般而言,桶的个数将与一次作业中对应的reduce数量一致。
其实,基于分桶的逻辑,在引擎侧可以做更多的优化(比如引擎侧可以优化分桶存储的策略)。在join中,根据索引进行join层面的动态优化,在超大数据join过程中,基于桶进行单位数据的本地优化等等都是可以做非常多的优化操作的,由于在目前的业务场景中,较少用到数据分桶,因此这里不做更深入的拓展,详细的可以自行百度,查看关于桶表的使用,更进一步,合理分桶,加上排序后的索引,能高效优化单表查询使用的效率。
3.4 并发与并行控制
在计算机入门的时候,我们就经常听到并发与并行,线程与进程等概念。而在数据研发中,我们发现,其实对于整个作业来说,同样遵循类似的调优规则。一般的,一个作业最大的map数是9999,reduce数最大是1000。虽然可以提高单个任务吞吐量,但是会消耗更长的时间和资源调度上的等待。另一方面,当完成一个同类作业,往往需要多个任务进行,如果任务下面可以多个作业并行处理,单个作业也能够并发执行,那么就能够更大程度地榨取整个集群的资源,从而达到突破计算瓶颈和上线的目的。目前在开源HADOOP体系中,我们没有脚本模式来支持灵活的任务自动分配和调度,但是可以采用SHELL/PYTHON脚本+SQL的方式来实现这一目的,其实借助猛犸调度在一定范围内也能达到同样的效果。
3.5 多路输出与物化(Read Once Output More)
这个部分我们主要谈谈HIVE(spark)的CTE写法(WITH...AS...)以及From语法的应用。这两个语法,在日常开发稍微复杂的任务时候,可以大大清晰整个复杂SQL的逻辑,同时,在多路读写中,通过物化的方式还能在一定程度上加速作业的运行。
-
CTE(with.... as ...)使用
-
基本使用非常简单,cte的语法主要是为了提高代码的可读性,虽然在整个性能的优化上未必达到很好的效果,但是在一定程度上,能大大提高任务的逻辑清晰度。很多时候,我们在多个逻辑过程中,通过临时表的方式进行任务的串行,使用with...as...能达到类似的效果。同时with...as...可以深层嵌套,因此是比较好的一种选择方式。无论是线上任务还是视图,都可以使用CTE的写法——目前比较遗憾的是HIVE的CTE目前不支持递归。
-
代码示例(可以使用多个with,抽出代码片段):
with a as (
select * from test1
where xxx = xxx
)
,
b as (
select * from a
)
select * from b limit 100;
-
物化设置
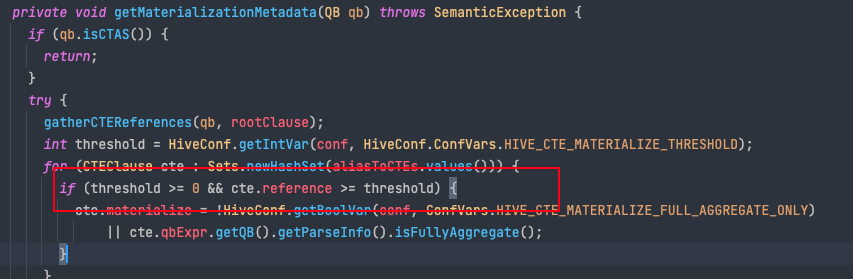
由于with...as...等同于一个SQL片段,下文中会多次引用该片段的别名,相当于视图的味道。所以,这里面使用是一个虚拟的概念,实际上只是逻辑生效,实际运行是则是翻译成实际的MR逻辑去执行,如果下游引用该SQL片段较多,这时候MR执行会多次扫描原始数据,执行多次相同的MR操作逻辑,此时,就可以在第一次执行中来物化CTE写法中定义的SQL片段,从而达到优化的目的。在hive之前的版本中,该功能是默认关闭的,可以通过下面参数来开启,在新的hive版本中,该功能是默认开启,但是默认引用次数是3次。
社区版hive 如下所示,我们的ODPS 下,大家无需太多关注,这部分做技术扩展和了解即可。

-
FROM使用(一读多写)
-
FROM也是本人在实际研发中遇到多路输出时采用比较多的一种手段之一。当有多个不同的分区,或者多个不同的目标输出,或者有多个不同的子逻辑的过程中,可以将主逻辑全部开发完成,然后再进行多路输出。多路输出操作的使用限制如下:
-
单条 multi insert语句中最多可以写255路输出。超过255路,会上报语法错误。
-
单条 multi insert语句中,对于分区表,同一个目标分区不允许出现多次。
-
单条 multi insert语句中,对于非分区表,该表不能出现多次。
-
比如在流量业务场景时,需要写动态分区,就可以使用from,一个代码小例子:
from (
select aa,bb,pt,sec_pt from test
)
insert OVERWRITE table du_temp.temp_01 partition (pt = 'xx',sec_pt = 'test1' )
select aa,bb where sec_pt = 'test1'
insert OVERWRITE table du_temp.temp_01 partition (pt = 'xx',sec_pt = 'test2' )
select aa,bb where sec_pt = 'test2'4.思考&总结
在数据研发领域,数据的技术手段无论多么丰富,平台发展何等完善,都不能说能解决业务的所有问题。一定是先有业务,才会有对应的问题。在面对大数据量,高时效性,高复杂计算的场景,我们需要结合业务的特性,模型的改造,链路的设计,甚至打破常规等方式来产出不同的方案。在另一个方面,数据研发的工作也远远不是单点问题的解决和兜底,相反需要各方的配合与共同的智慧。
线下活动推荐:
时间:2023年6月10日(周六) 14:00-18:00
主题:得物技术沙龙总第18期-无线技术第4期
地点:杭州·西湖区学院路77号得物杭州研发中心12楼培训教室(地铁10号线&19号线文三路站G口出)
活动亮点:本次无线沙龙聚焦于最新的技术趋势和实践,将在杭州/线上为你带来四个令人期待的演讲话题,包括:《抖音创作工具-iOS功耗监控与优化》、《得物隐私合规平台建设实践》、《网易云音乐-客户端大流量活动的日常化保障方案实践》、《得物Android编译优化》。相信这些话题将对你的工作和学习有所帮助,我们期待着与你共同探讨这些令人兴奋的技术内容!
点击报名:得物无线技术沙龙第4期(总第18期) 预约报名-得物技术沙龙活动-活动行
本文属得物技术原创,来源于:得物技术官网
未经得物技术许可严禁转载,否则依法追究法律责任!