大家好,我是微学AI,今天给大家带来人工智能(Pytorch)搭建模型7-新型的卷积神经网络RegNet模型的搭建与训练,RegNet是一种新颖的卷积神经网络架构,它的设计理念是通过稀疏网络结构和精细的正则化来实现高效的计算和更好的泛化能力。RegNet最初是用于图像分类任务,在ImageNet上实现了较好的性能,同时也受到了广泛的关注。
一、RegNet设计空间介绍
RegNet是一种用于图像分类的不同卷积神经网络模型架构组成的设计空间。RegNet的设计原则是通过正则化来平衡网络的深度和宽度,从而实现更好的性能。下面列出了RegNet模型的主要特点:
RegNet架构具有可配置的深度(层数)和宽度(每层的通道数)。
RegNet架构使用了分组卷积和跳跃连接来提高计算效率和模型性能。
RegNet架构可以通过调整参数来在不同的计算资源和性能要求之间进行权衡。
RegNet的稀疏结构是通过对网络宽度、深度和分辨率进行优化,减少了过度的冗余特征和层。同时,RegNet采用了一个特定的正则化方法,称为“网络级别L2正则化”,以帮助网络获得更好的泛化能力。此正则化方法在网络的结构定义阶段进行,为每一个层次参数引入一定的正则化强度。
改造RegNet架构后的特点:
1.高效的计算速度:该模型具有较小的参数量和计算成本,能够在移动设备等较低配置的硬件上快速运行。
2.较好的泛化能力:该模型通过使用Residual Block和L2正则化等技术来防止过拟合,从而提高了模型的泛化性能。
3.可拓展性:该模型的网络设计空间灵活,可以通过搜索算法来寻找最优的网络结构,同时也可以通过调整网络深度和宽度等参数进行适应不同任务。
4.简单易懂的结构:该模型只包含几个简单但非常重要的模块,并且模块的形式和功能就和传统的卷积神经网络非常相似。
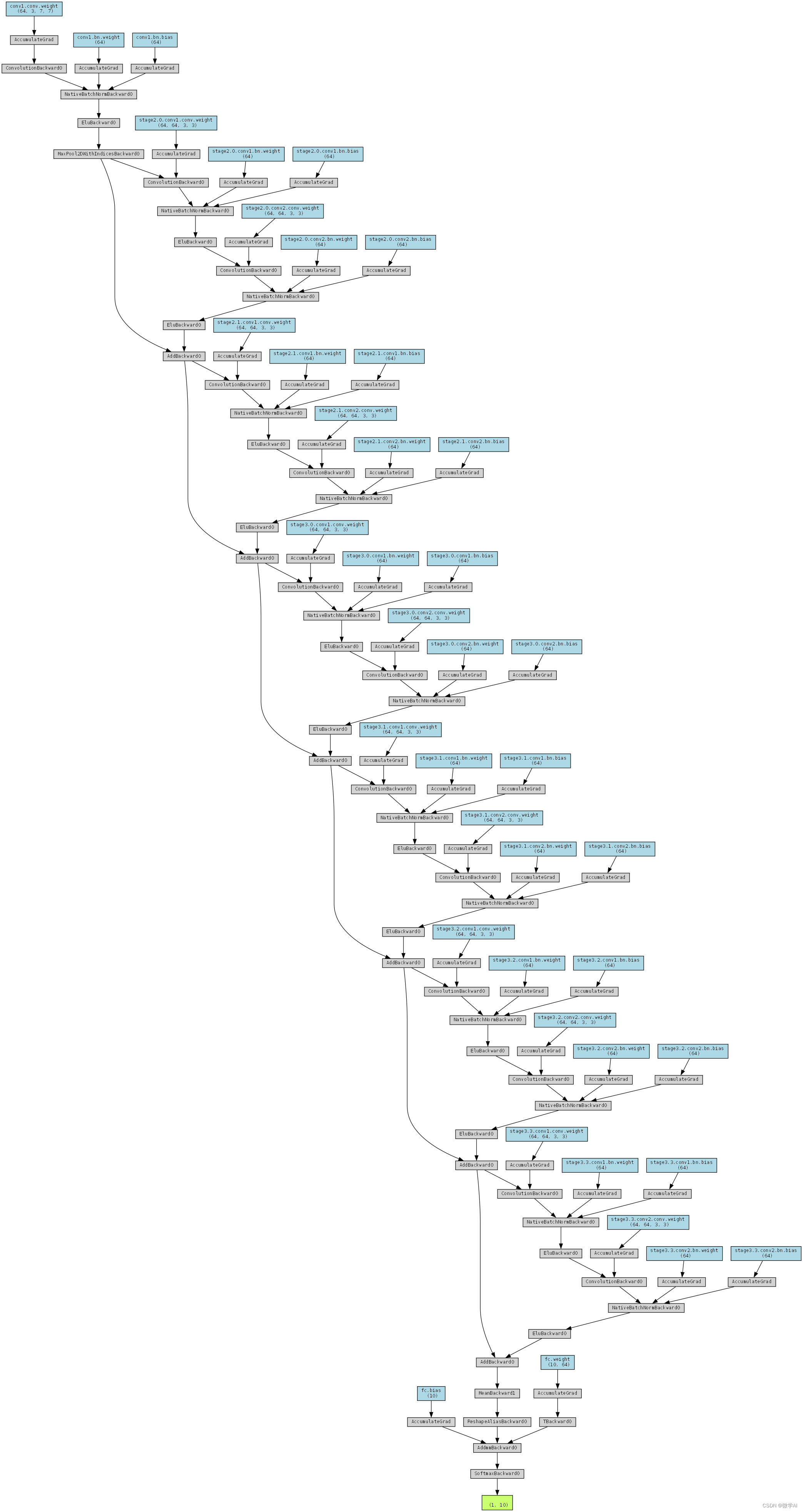
构建的模型结构图:
二、PyTorch实现
2.1 准备数据
首先,我们生成假数据以进行模型训练和测试。这里我们使用torch.randn()函数生成随机数据,模拟图像数据。为了简化问题,我们假设输入图像的尺寸为3x32x32,类别数为4。
import torch
import numpy as np
from torch.utils.data import DataLoader, TensorDataset
# 生成假数据
num_samples = 200
input_shape = (3, 32, 32)
num_classes = 4
image_data = np.random.rand(num_samples, 3, 32, 32).astype(np.float32)
labels = np.random.randint(0, 4, size=num_samples, dtype=np.int64)
# 创建数据集和数据加载器
train_data = TensorDataset(torch.from_numpy(image_data), torch.from_numpy(labels))
train_loader = DataLoader(train_data, batch_size=10, shuffle=False)2.2 构建RegNet架构
接下来,我们使用PyTorch构建RegNet模型。首先,我们定义一个基本的卷积块ConvBlock,它由一个卷积层、一个批量归一化层和一个ELU激活函数组成。然后,我们定义一个残差块ResidualBlock,它包含两个卷积块,并使用跳跃连接将输入添加到输出。
import torch.nn as nn
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding, groups=1):
super(ConvBlock, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, groups=groups, bias=False)
self.bn = nn.BatchNorm2d(out_channels)
self.ELU = nn.ELU(inplace=False)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.ELU(x)
return x
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super(ResidualBlock, self).__init__()
self.conv1 = ConvBlock(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
self.conv2 = ConvBlock(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
def forward(self, x):
identity = x
x = self.conv1(x)
x = self.conv2(x)
x += identity
return x
class RegNet(nn.Module):
def __init__(self, input_shape, num_classes, num_blocks):
super(RegNet, self).__init__()
self.in_channels = 64
self.conv1 = ConvBlock(input_shape[0], self.in_channels, kernel_size=7, stride=2, padding=3)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.stage2 = self._make_stage(num_blocks[0], self.in_channels * 1)
self.stage3 = self._make_stage(num_blocks[1], self.in_channels * 1)
#self.stage4 = self._make_stage(num_blocks[2], self.in_channels * 1)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(self.in_channels * 1, num_classes)
self.softmax = nn.Softmax(dim=1)
def _make_stage(self, num_blocks, out_channels):
layers = []
for _ in range(num_blocks):
layers.append(ResidualBlock(self.in_channels, out_channels))
self.in_channels = out_channels
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool(x)
x = self.stage2(x)
x = self.stage3(x)
#x = self.stage4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
x = self.softmax(x)
return x2.3 训练和测试
现在我们已经构建好RegNet模型,接下来我们使用随机生成的数据进行训练和测试。我们使用交叉熵损失函数和随机梯度下降优化器。
# 设置超参数
num_epochs = 200
learning_rate = 0.001
momentum = 0.8
#weight_decay = 0.0001
# 初始化模型、损失函数和优化器
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = RegNet(input_shape, num_classes, num_blocks=[2, 2, 2]).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum)
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch [{epoch + 1}/{num_epochs}], Loss: {running_loss / (i + 1)}")
# 测试模型
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in train_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
#print(f"Train Accuracy: {100 * correct / total}%")
print(f"Accuracy of the model on the {total} test images: {100 * correct / total}%")
运行结果:
Epoch [188/200], Loss: 0.7604680061340332
Epoch [189/200], Loss: 0.7604513049125672
Epoch [190/200], Loss: 0.7604348838329316
Epoch [191/200], Loss: 0.7604187309741974
Epoch [192/200], Loss: 0.7604028165340424
Epoch [193/200], Loss: 0.760387197136879
Epoch [194/200], Loss: 0.760371795296669
Epoch [195/200], Loss: 0.7603566676378251
Epoch [196/200], Loss: 0.7603417694568634
Epoch [197/200], Loss: 0.7603270918130874
Epoch [198/200], Loss: 0.7603126436471939
Epoch [199/200], Loss: 0.7602984338998795
Epoch [200/200], Loss: 0.7602844357490539
Accuracy of the model on the 200 test images: 98.0%
大家可以自己放入图片数据进行训练哦。