一、概述
title:UNIPELT: A Unified Framework for Parameter-Efficient Language Model Tuning
论文地址:https://arxiv.org/abs/2110.07577
代码:GitHub - morningmoni/UniPELT: Code for paper "UniPELT: A Unified Framework for Parameter-Efficient Language Model Tuning", ACL 2022
1.1 Motivation
- 大模型不同的微调方法(PELT)例如LoRA,prefix-tuning,Adapter方法效果不同,在不同的任务上效果也有差异,到底选哪个方法好呢?
- parameter-efficient language model tuning (PELT) 方法能在参数量比fine-tuning小很多的情况下,perform追上fine-tuning的水平,但是不同的PELT方法在同一个任务上表现差异可能都非常大,这让针对特定任务选择合适的方法非常繁琐。
1.2 Methods
- 提出了PELT方法,将不同的PELT方法作为子模块,并学习通过门控机械激活最适合当前数据或任务的方法。
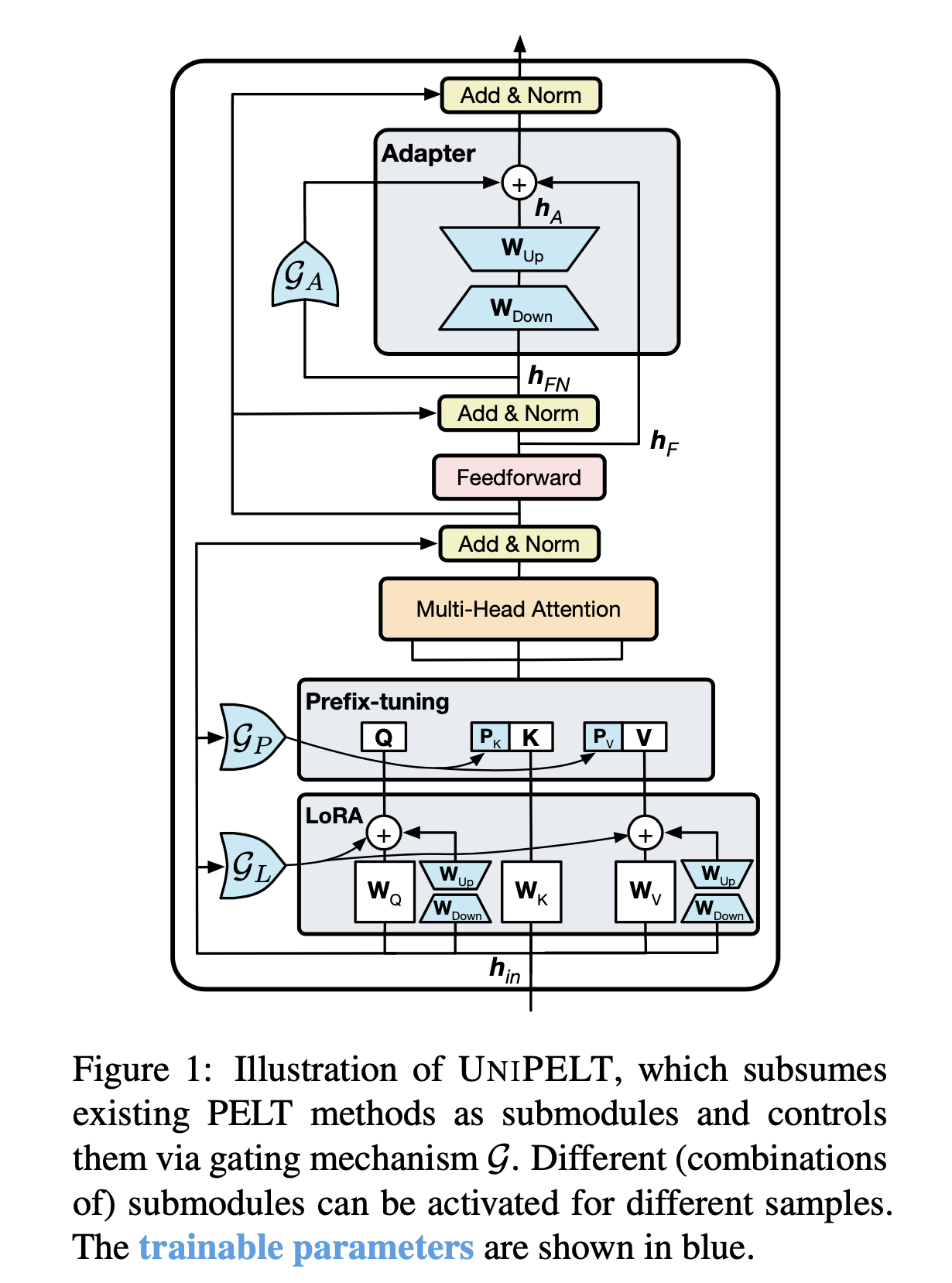
说明:
- 例如通过Gp参数控制Prefix-tuning方法的开关,GL控制LoRA方法的开关,GA控制Adapter方法的开关。
- 图中蓝颜色的参数为可学习的参数。
1.3 Conclusion
- 本文方法始终优于传统的fine-tuning方法以及它在不同子模块下的表现,并且通常超过了在每个任务上单独使用的每个子模块的最佳性能的上限 。
- 融合多种PELT方法可能会有利于预训练语言模型PLM的有效性和鲁棒性
二、详细内容
1 GLUE实验结果
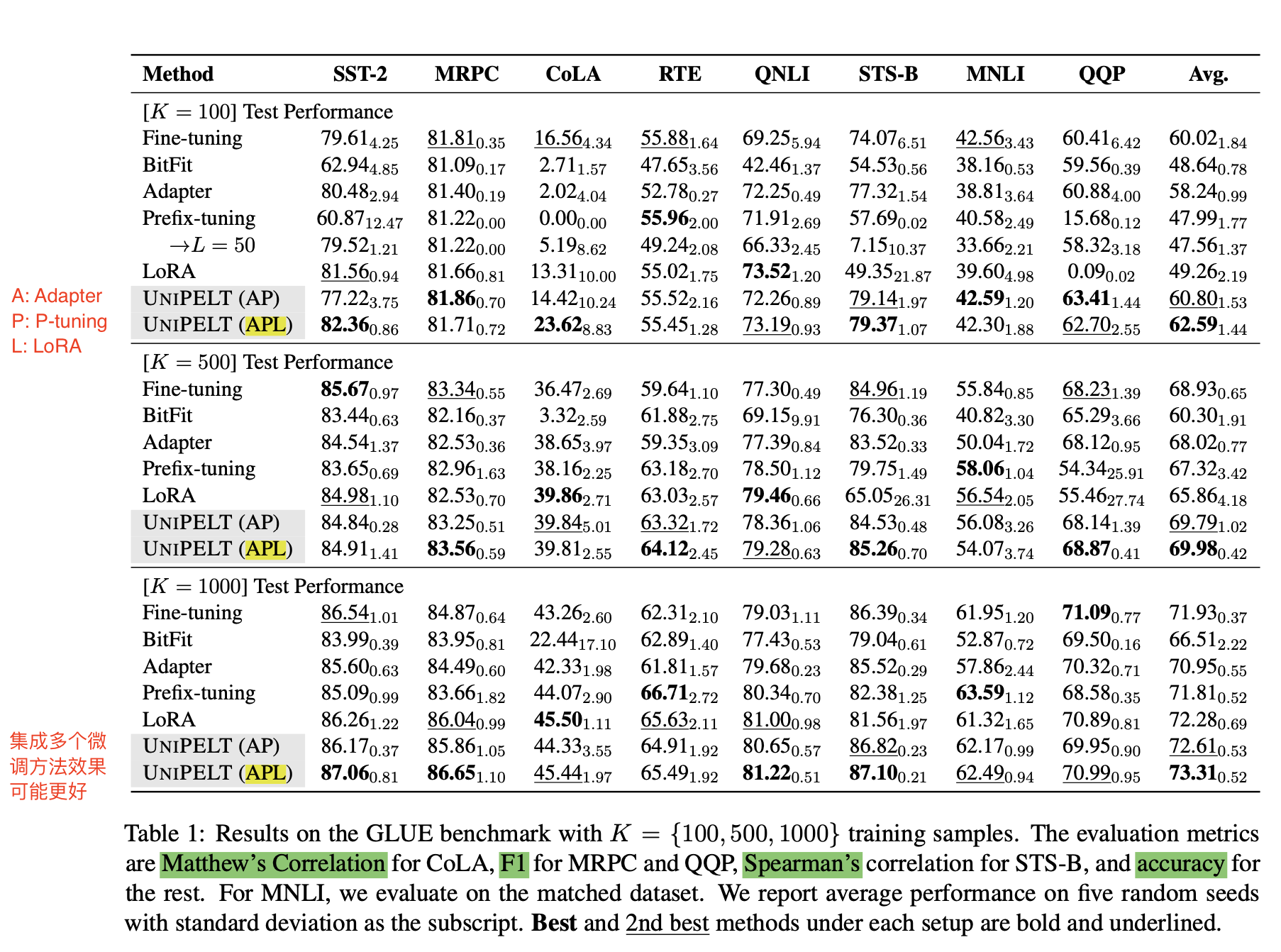
- UniPELT(AP)和UniPELT(APL)区别
-
- A: Adapter
- P: P-tuning
- L: LoRA
- 结论
-
- 在样本K=100,500,1000的实验上,UniPELT集成了多个微调方法的效果更好
2 Adapter方法分析:bottleneck大小对该方法效果的影响
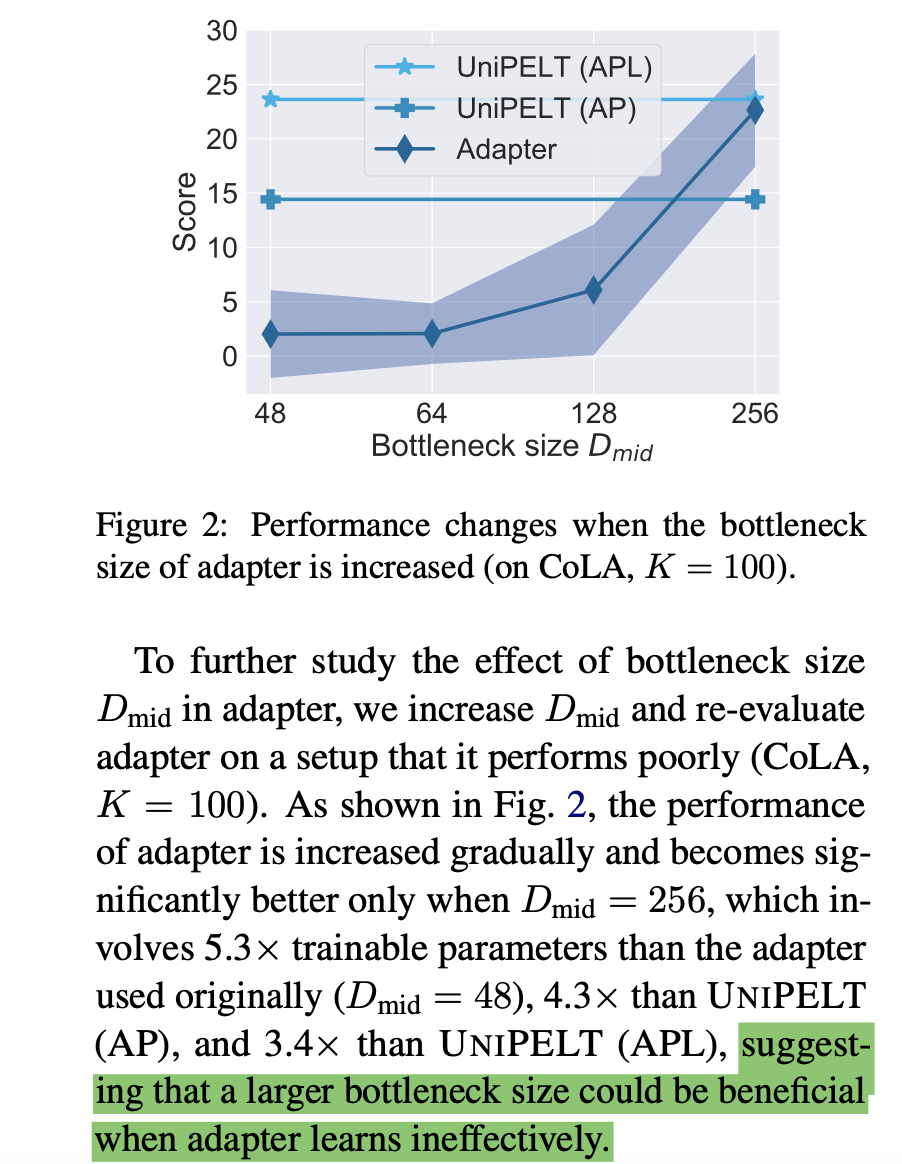
- bootleneck size越大,可训练的参数越多,效果也就更好,size=48的时候,可能学的还不太充分
3 LoRA方法对参数的敏感性
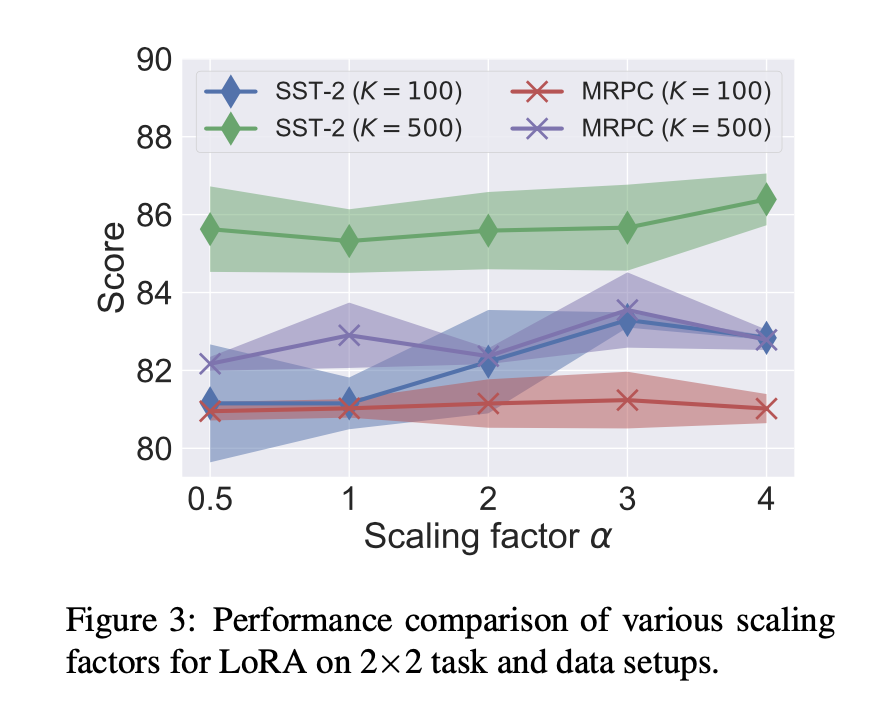
正对两个任务SST和MRPC,和不同的参数a来做实验,结果如下:
- 没有一个有效的a在任何task上都是效果比较好的,说明了本文方法让他自己来学习这些参数的重要性
4 其他方法分析:
- Prefix-tuning
-
- 增加训练参数效果不一定好
- BitFit和LoRA
-
- LoRA训练参数比较小的情况下,效果好像也还可以
5 UniPELT和原始微调方法的上限对比
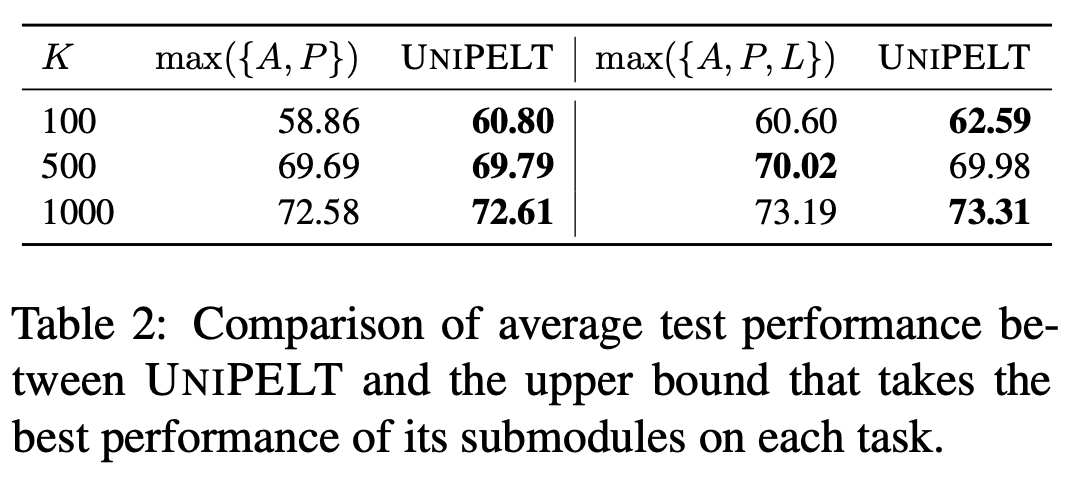
- 6个实验有5个都超过了单独方法的上限
6 全量数据的训练效果
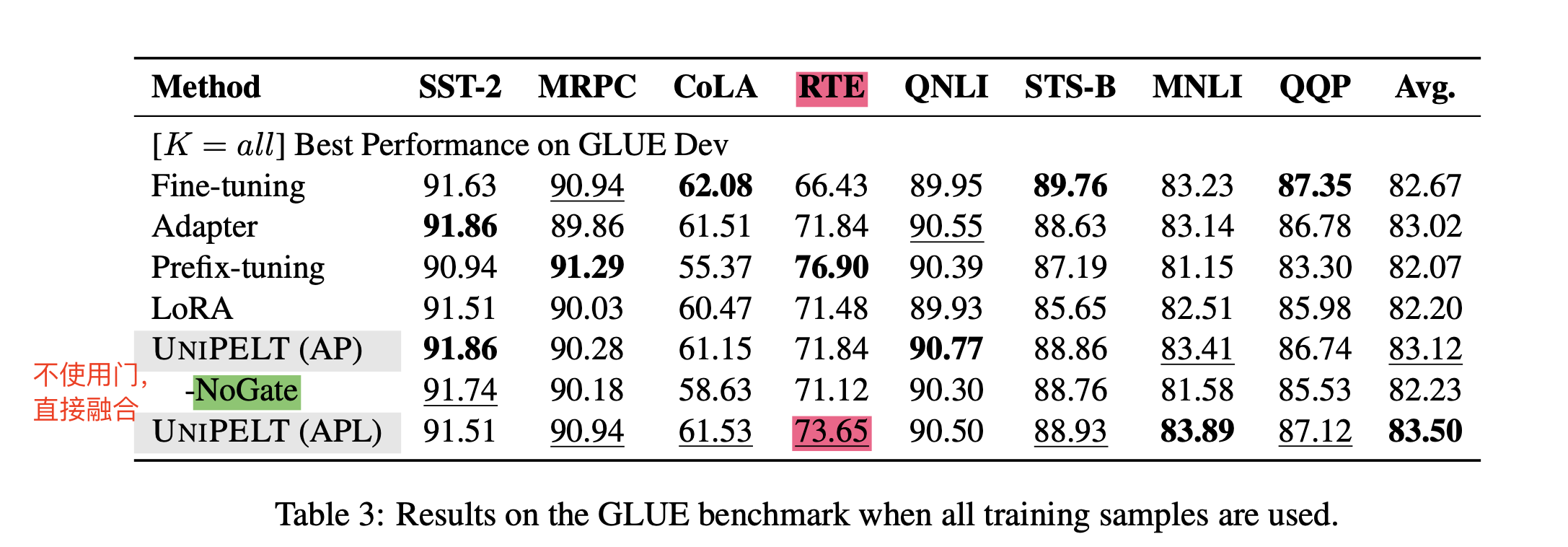
- 使用全量的数据PELT还是取得了最好的结果
- 不使用门,简单的融合,效果也没有本文PELT效果好,说明了本文方法的有用性
7 训练时间和推理时间分析
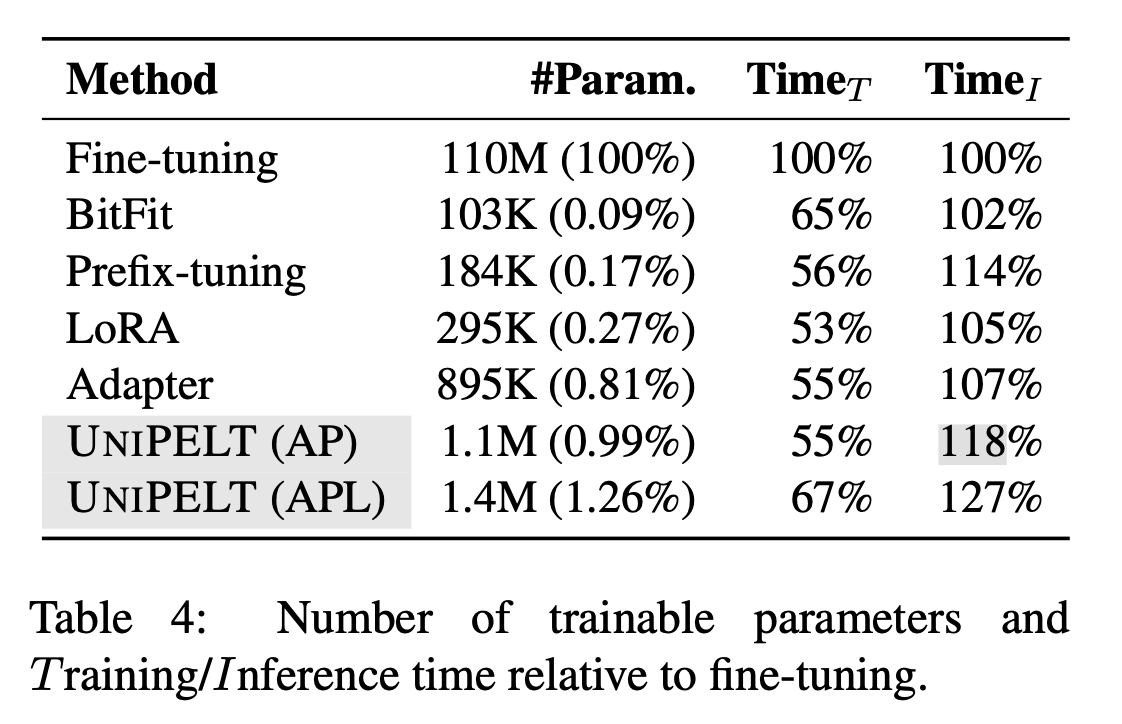
- 训练速度UniPELT比之前微调的方法多一些,但是也还好,推理时间BitFit增加的最少,本文方法时间增加27%
- 训练参数量LoRA,BitFit,Prefix-tuning都比较小,UniPELT多了一些
三、Adaptor、Prefix-tuning、LoRA背景知识
参考原文:从统一视角看各类高效finetune方法:从统一视角看各类高效finetune方法
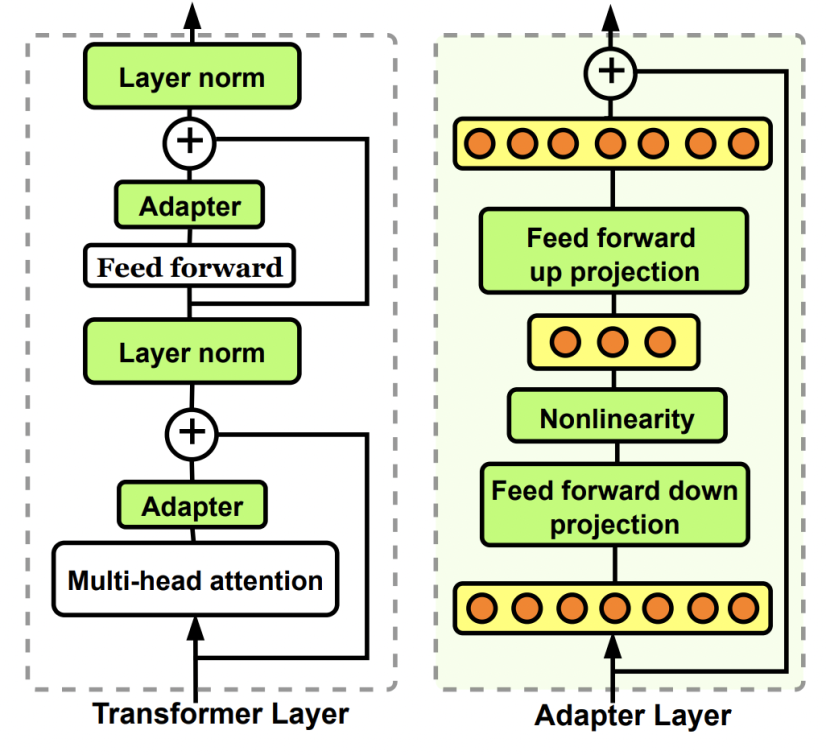
1 Adaptor方法介绍
Adaptor核心是在原Bert中增加参数量更小的子网络,finetune时固定其他参数不变,只更新这个子网络的参数。Adaptor是最早的一类高效finetune方法的代表,在Parameter-Efficient Transfer Learning for NLP(ICML 2019)这篇文章中被提出。在原来的Bert模型的每层中间加入两个adapter。Adapter通过全连接对原输入进行降维进一步缩小参数量,经过内部的NN后再将维度还原,形成一种bottleneck的结构。在finetune过程中,原预训练Bert模型的参数freeze住不更新,只更新adapter的参数,大大减少了finetune阶段需要更新和保存的参数量。
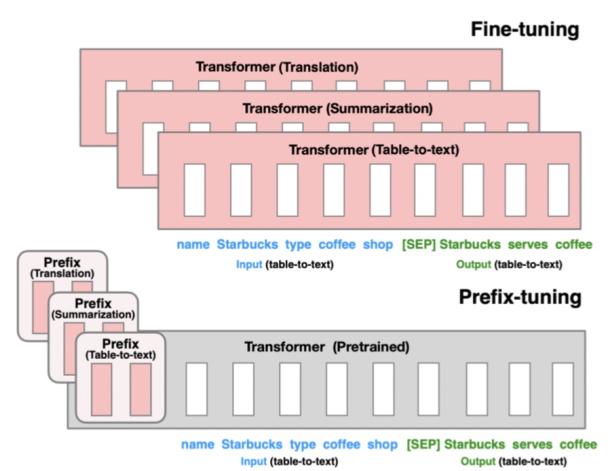
2 Prefix-tuning方法介绍
Prefix-tuning的核心是为每个下游任务增加一个prefix embedding,只finetune这些embedding,其他参数freeze。Prefix-tuning对应的论文是Prefix-Tuning: Optimizing Continuous Prompts for Generation(2021),这类方法的思想来源于prefix prompt,prefix embedding相当于一个上下文信息,对模型最终产出的结果造成影响,进而只finetune这个embedding实现下游任务的迁移。
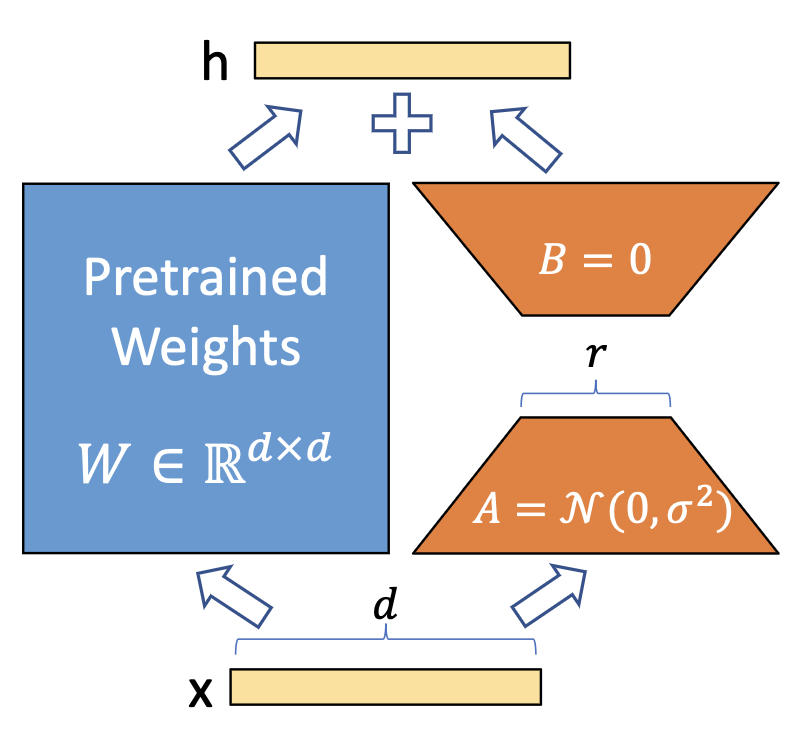
2 LoRA方法介绍
LoRA的核心是通过引入参数量远小于原模型的可分解的两小矩阵建立一个旁路,通过finetune这个旁路来影响预训练模型。LoRA于LoRA: Low-rank adaptation of large language models(2021)论文中被提出,利用低秩矩阵替代原来全量参数的训练,提升finetune效率。