文章目录
- List, Set, Queue, Map 四者的区别?
- 集合框架底层数据结构总结
- ArrayList 和 Vector 的区别
- ArrayList 与 LinkedList 区别
- 补充内容:RandomAccess 接⼝
- ArrayList 的扩容机制
- comparable 和 Comparator 的区别
- 比较 HashSet、LinkedHashSet 和 TreeSet 三者的异同
- HashMap 和 Hashtable 的区别
- HashMap 的底层实现
- JDK1.8 前
- JDK1.8 之后
- HashMap 的长度为什么是 2 的幂次方
- HashMap 常见的遍历方式
- ConcurrentHashMap 和 Hashtable 的区别
- ConcurrentHashMap 线程安全的具体实现⽅式/底层具体实现
- JDK1.8前
- JDK1.8后

List, Set, Queue, Map 四者的区别?
- List (对付顺序的好帮⼿): 存储的元素是有序的、可重复的。
- Set (注重独⼀⽆⼆的性质): 存储的元素是⽆序的、不可重复的。
- Queue (实现排队功能的叫号机): 按特定的排队规则来确定先后顺序,存储的元素是有序的、可重复的。
- Map (⽤ key 来搜索的专家): 使⽤键值对(key-value)存储,类似于数学上的函数 y=f(x),“x” 代表 key,“y” 代表 value,key 是⽆序的、不可重复的,value 是⽆序的、可重复的,每个键最 多映射到⼀个值。
集合框架底层数据结构总结
- List
- ArrayList : Object[] 数组
- Vector : Object[] 数组
- LinkedList : 双向链表(JDK1.6 之前为循环链表,JDK1.7 取消了循环)
- Set
- HashSet (⽆序,唯⼀): 基于 HashMap 实现的,底层采⽤ HashMap 来保存元素
- LinkedHashSet : LinkedHashSet 是 HashSet 的⼦类,并且其内部是通过 LinkedHashMap 来实 现的。有点类似于我们之前说的 LinkedHashMap 其内部是基于 HashMap 实现⼀样,不过还 是有⼀点点区别的
- TreeSet (有序,唯⼀): 红⿊树(⾃平衡的排序⼆叉树)
- Queue
- PriorityQueue : Object[] 数组来实现⼆叉堆
- ArrayQueue : Object[] 数组 + 双指针
-
Map
- HashMap : JDK1.8 之前 HashMap 由数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突⽽存在的(“拉链法”解决冲突)。
JDK1.8 以后在解决哈希冲突时有了较⼤的变化,当链表⻓度⼤于阈值(默认为 8)(将链表转换成红⿊树前会判断,如果当前数组的⻓度⼩于 64,那么会选择先进⾏数组扩容,⽽不是转换为红⿊树)时,将链表转化为红⿊树,以减少搜索时间。(数组长度大于64且该数组下的链表长度大于8 才转红黑树)
- LinkedHashMap : LinkedHashMap 继承⾃ HashMap ,所以它的底层仍然是基于拉链式散列 结构即由数组和链表或红⿊树组成。另外, LinkedHashMap 在上⾯结构的基础上,增加了⼀条 双向链表,使得上⾯的结构可以保持键值对的插⼊顺序。同时通过对链表进⾏相应的操作,实现 了访问顺序相关逻辑。
详细可以查看:LinkedHashMap 源码详细分析(JDK1.8)_慕课手记
- Hashtable : 数组+链表组成的,数组是 Hashtable 的主体,链表则是主要为了解决哈希冲突⽽存在的
- TreeMap : 红⿊树(⾃平衡的排序⼆叉树)
ArrayList 和 Vector 的区别
- ArrayList 是 List 的主要实现类,底层使⽤ Object[ ] 存储,适⽤于频繁的查找⼯作,线程不安全 ;
- Vector 是 List 的古⽼实现类,底层使⽤ Object[ ] 存储,线程安全的 。
ArrayList 与 LinkedList 区别
- 是否保证线程安全: ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
- 底层数据结构: ArrayList 底层使⽤的是 Object 数组; LinkedList 底层使⽤的是 双向链表 数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环。注意双向链表和双向循环链表的区 别,下⾯有介绍到!)
- 插⼊和删除是否受元素位置的影响:
- ArrayList 采⽤数组存储,所以插⼊和删除元素的时间复杂度受元素位置的影响。 ⽐如: 执⾏ add(E e) ⽅法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种 情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插⼊和删除元素的话( add(int index, E element) )时间复杂度就为 O(n-i)。因为在进⾏上述操作的时候集合中第 i 和第 i 个元素之 后的(n-i)个元素都要执⾏向后位/向前移⼀位的操作。
- LinkedList 采⽤链表存储,所以,如果是在头尾插⼊或者删除元素不受元素位置的影响 ( add(E e) 、 addFirst(E e) 、 addLast(E e) 、 removeFirst() 、 removeLast() ),时间复杂 度为 O(1),如果是要在指定位置 i 插⼊和删除元素的话( add(int index, E element) , remove(Object o) ), 时间复杂度为 O(n) ,因为需要先移动到指定位置再插⼊。
- 是否⽀持快速随机访问: LinkedList 不⽀持⾼效的随机元素访问,⽽ ArrayList ⽀持。快速随 机访问就是通过元素的序号快速获取元素对象(对应于 get(int index) ⽅法)。
- 内存空间占⽤: ArrayList 的空 间浪费主要体现在在 list 列表的结尾会预留⼀定的容量空间, ⽽ LinkedList 的空间花费则体现在它的每⼀个元素都需要消耗⽐ ArrayList 更多的空间(因为要 存放直接后继和直接前驱以及数据)。
我们在项⽬中⼀般是不会使⽤到 LinkedList 的,需要⽤到 LinkedList 的场景⼏乎都可以使⽤ ArrayList 来代替,并且,性能通常会更好!就连 LinkedList 的作者约书亚 · 布洛克(Josh Bloch)⾃⼰都说从来不会使⽤ LinkedList 。
补充内容:RandomAccess 接⼝
public interface RandomAccess {
}
查看源码我们发现实际上 RandomAccess 接⼝中什么都没有定义。所以,在我看来 RandomAccess 接⼝不过是⼀个标识罢了。标识什么? 标识实现这个接⼝的类具有随机访问功能。
在 binarySearch() ⽅法中,它要判断传⼊的 list 是否 RandomAccess 的实例,如果是,调⽤ indexedBinarySearch() ⽅法,如果不是,那么调⽤ iteratorBinarySearch() ⽅法
public static <T>
int binarySearch(List<? extends Comparable<? super T>> list, T key) {
if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD)
return Collections.indexedBinarySearch(list, key);
else
return Collections.iteratorBinarySearch(list, key);
}
ArrayList 实现了 RandomAccess 接⼝, ⽽ LinkedList 没有实现。为什么呢?
我觉得还是和底层数据结构有关! ArrayList 底层是数组,⽽ LinkedList 底层是链表。数组天然⽀持随机访问,时间 复杂度为 O(1),所以称为快速随机访问。链表需要遍历到特定位置才能访问特定位置的元素,时间 复杂度为 O(n),所以不⽀持快速随机访问。, ArrayList 实现了 RandomAccess 接⼝,就表明了他 具有快速随机访问功能。 RandomAccess 接⼝只是标识,并不是说 ArrayList 实现 RandomAccess 接⼝才具有快速随机访问功能的!
ArrayList 的扩容机制
ArrayList源码&扩容机制分析
comparable 和 Comparator 的区别
- comparable 接⼝实际上是出⾃ java.lang 包 它有⼀个 compareTo(Object obj) ⽅法⽤来排序
- comparator 接⼝实际上是出⾃ java.util 包它有⼀个 compare(Object obj1, Object obj2) ⽅法⽤来排序
比较 HashSet、LinkedHashSet 和 TreeSet 三者的异同
- HashSet 、 LinkedHashSet 和 TreeSet 都是 Set 接⼝的实现类,都能保证元素唯⼀,并且都 不是线程安全的。
- HashSet 、 LinkedHashSet 和 TreeSet 的主要区别在于底层数据结构不同。 HashSet 的底层数 据结构是哈希表(基于 HashMap 实现)。 LinkedHashSet 的底层数据结构是链表和哈希表, 元素的插⼊和取出顺序满⾜ FIFO。 TreeSet 底层数据结构是红⿊树,元素是有序的,排序的⽅ 式有⾃然排序和定制排序。
- 底层数据结构不同⼜导致这三者的应⽤场景不同。 HashSet ⽤于不需要保证元素插⼊和取出顺 序的场景, LinkedHashSet ⽤于保证元素的插⼊和取出顺序满⾜ FIFO 的场景, TreeSet ⽤于 ⽀持对元素⾃定义排序规则的场景。
HashMap 和 Hashtable 的区别
-
线程是否安全: HashMap 是⾮线程安全的, Hashtable 是线程安全的,因为 Hashtable 内部的 ⽅法基本都经过 synchronized 修饰。(如果你要保证线程安全的话就使⽤ ConcurrentHashMap 吧!)
-
效率: 因为线程安全的问题, HashMap 要⽐ Hashtable 效率⾼⼀点。另外, Hashtable 基本 被淘汰,不要在代码中使⽤它;
-
对 Null key 和 Null value 的⽀持: HashMap 可以存储 null 的 key 和 value,但 null 作为键只 能有⼀个,null 作为值可以有多个;Hashtable 不允许有 null 键和 null 值,否则会抛出 NullPointerException 。
-
初始容量⼤⼩和每次扩充容量⼤⼩的不同 : ① 创建时如果不指定容量初始值, Hashtable 默认 的初始⼤⼩为 11,之后每次扩充,容量变为原来的 2n+1。 HashMap 默认的初始化⼤⼩为 16。之后每次扩充,容量变为原来的 2 倍。② 创建时如果给定了容量初始值,那么 Hashtable 会直接使⽤你给定的⼤⼩,⽽ HashMap 会将其扩充为 2 的幂次⽅⼤⼩( HashMap 中的 tableSizeFor() ⽅法保证,下⾯给出了源代码)。也就是说 HashMap 总是使⽤ 2 的幂作为哈希 表的⼤⼩,后⾯会介绍到为什么是 2 的幂次⽅。
-
底层数据结构: JDK1.8 以后的 HashMap 在解决哈希冲突时有了⼤的变化,当链表⻓度⼤ 于阈值(默认为 8)时,将链表转化为红⿊树(将链表转换成红⿊树前会判断,如果当前数组的 ⻓度⼩于 64,那么会选择先进⾏数组扩容,⽽不是转换为红⿊树),以减少搜索时间(后⽂中 我会结合源码对这⼀过程进⾏分析)。 Hashtable 没有这样的机制。
HashMap 的底层实现
JDK1.8 前
JDK1.8 之前 HashMap 底层是 数组和链表 结合在⼀起使⽤也就是链表散列。
HashMap 通过 key 的 hashcode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位 置(这⾥的 n 指的是数组的⻓度),如果当前位置存在元素的话,就判断该元素与要存⼊的元素的hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
所谓扰动函数指的就是 HashMap 的 hash ⽅法。使⽤ hash ⽅法也就是扰动函数是为了防⽌⼀些 实现比较差的 hashCode() ⽅法 换句话说使⽤扰动函数之后可以减少碰撞。
JDK1.7 的 HashMap 的 hash ⽅法源码.
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
JDK 1.8 的 hash ⽅法 相⽐于 JDK 1.7 hash ⽅法更加简化,但是原理不变。
static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
// ^ :按位异或
// >>>:⽆符号右移,忽略符号位,空位都以0补⻬
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
相⽐于 JDK1.8 的 hash ⽅法 ,JDK 1.7 的 hash ⽅法的性能会稍差⼀点点,因为毕竟扰动了 4 次。
所谓 “拉链法” 就是:将链表和数组相结合。也就是说创建⼀个链表数组,数组中每⼀格就是⼀个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
JDK1.8 之后
相⽐于之前的版本, JDK1.8 之后在解决哈希冲突时有了较⼤的变化,当链表⻓度⼤于阈值(默认为 8)(将链表转换成红⿊树前会判断,如果当前数组的⻓度⼩于 64,那么会选择先进⾏数组扩容,⽽ 不是转换为红⿊树)时,将链表转化为红⿊树,以减少搜索时间。
TreeMap、TreeSet 以及 JDK1.8 之后的 HashMap 底层都⽤到了红⿊树。红⿊树就是为了解决 ⼆叉查找树的缺陷,因为⼆叉查找树在某些情况下会退化成⼀个线性结构。
结合源码分析⼀下 HashMap 链表到红⿊树的转换
- putVal ⽅法中执⾏链表转红⿊树的判断逻辑。
链表的⻓度⼤于 8 的时候,就执⾏ treeifyBin (转换红⿊树)的逻辑。
// 遍历链表
for (int binCount = 0; ; ++binCount) {
// 遍历到链表最后⼀个节点
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 如果链表元素个数⼤于等于TREEIFY_THRESHOLD(8)
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 红⿊树转换(并不会直接转换成红⿊树)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
- treeifyBin ⽅法中判断是否真的转换为红⿊树。
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
// 判断当前数组的⻓度是否⼩于 64
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
// 如果当前数组的⻓度⼩于 64,那么会选择先进⾏数组扩容
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
// 否则才将列表转换为红⿊树
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
将链表转换成红⿊树前会判断,如果当前数组的⻓度⼩于 64,那么会选择先进⾏数组扩容,⽽不是 转换为红⿊树。
HashMap 的长度为什么是 2 的幂次方
为了能让 HashMap 存取⾼效,尽量较少碰撞,也就是要尽量把数据分配均匀。我们上⾯也讲到了过了,Hash 值的范围值-2147483648 到 2147483647,前后加起来⼤概 40 亿的映射空间,只要哈希 函数映射得⽐较均匀松散,⼀般应⽤是很难出现碰撞的。
但问题是⼀个 40 亿⻓度的数组,内存是放不下的。所以这个散列值是不能直接拿来⽤的。⽤之前还要先做对数组的⻓度取模运算,得到的余数 才能⽤来要存放的位置也就是对应的数组下标。这个数组下标的计算⽅法是“ (n - 1) & hash ”。(n 代表数组⻓度)。这也就解释了 HashMap 的⻓度为什么是 2 的幂次⽅。
这个算法应该如何设计呢?
我们⾸先可能会想到采⽤%取余的操作来实现。但是,重点来了:“取余(%)操作中如果除数是 2 的 幂次则等价于与其除数减⼀的与(&)操作(也就是说 hash%length==hash&(length-1) 的前提是 length 是 2 的 n 次⽅;)。” 并且采⽤⼆进制位操作 &,相对于%能够提⾼运算效率,这就解释了 HashMap 的⻓度为什么是 2 的幂次⽅。
HashMap 常见的遍历方式
HashMap 的 7 种遍历方式与性能分析!「修正篇」
ConcurrentHashMap 和 Hashtable 的区别
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的⽅式上不同。
-
底层数据结构: JDK1.7 的 ConcurrentHashMap 底层采⽤ 分段的数组+链表 实现,JDK1.8 采⽤ 的数据结构跟 HashMap1.8 的结构⼀样,数组+链表/红⿊⼆叉树。 Hashtable 和 JDK1.8 之前 的 HashMap 的底层数据结构类似都是采⽤ 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突⽽存在的;
-
实现线程安全的⽅式(重要)
- 在 JDK1.7 的时候, ConcurrentHashMap 对整个桶数组进⾏了分割分段( Segment ,分段锁),每⼀把锁只锁容器其中⼀部分数据(下⾯有示意图),多线程访问容器⾥不同数据段 的数据,就不会存在锁竞争,提⾼并发访问率。
- 到了 JDK1.8 的时候, ConcurrentHashMap 已经摒弃了 Segment 的概念,⽽是直接⽤ Node 数组+链表+红⿊树的数据结构来实现,并发控制使⽤ synchronized 和 CAS 来操 作。(JDK1.6 以后 synchronized 锁做了很多优化) 整个看起来就像是优化过且线程安全 的 HashMap ,虽然在 JDK1.8 中还能看到 Segment 的数据结构,但是已经简化了属性, 只是为了兼容旧版本;
- Hashtable (同⼀把锁) :使⽤ synchronized 来保证线程安全,效率⾮常低下。当⼀个线程访 问同步⽅法时,其他线程也访问同步⽅法,可能会进⼊阻塞或轮询状态,如使⽤ put 添加元 素,另⼀个线程不能使⽤ put 添加元素,也不能使⽤ get,竞争会越来越激烈效率越低。
ConcurrentHashMap 线程安全的具体实现⽅式/底层具体实现
JDK1.8前
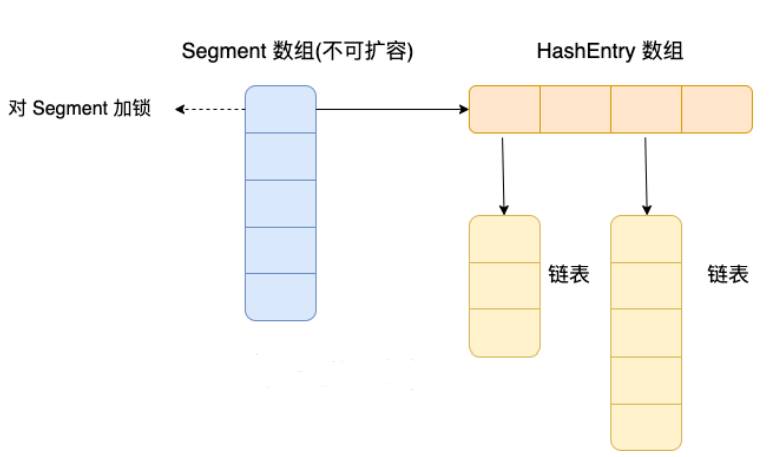
⾸先将数据分为⼀段⼀段(这个“段”就是 Segment )的存储,然后给每⼀段数据配⼀把锁,当⼀个 线程占⽤锁访问其中⼀个段数据时,其他段的数据也能被其他线程访问。
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。
Segment 继承了 ReentrantLock ,所以 Segment 是⼀种可重⼊锁,扮演锁的⻆⾊。 HashEntry ⽤于 存储键值对数据。
⼀个 ConcurrentHashMap ⾥包含⼀个 Segment 数组, Segment 的个数⼀旦初始化就不能改变。 Segment 数组的⼤⼩默认是 16,也就是说默认可以同时⽀持 16 个线程并发写。
Segment 的结构和 HashMap 类似,是⼀种数组和链表结构,⼀个 Segment 包含⼀个 HashEntry 数组,每个 HashEntry 是⼀个链表结构的元素,每个 Segment 守护着⼀个 HashEntry 数组⾥的元 素,当对 HashEntry 数组的数据进⾏修改时,必须⾸先获得对应的 Segment 的锁。也就是说,对 同⼀ Segment 的并发写⼊会被阻塞,不同 Segment 的写⼊是可以并发执⾏的。
JDK1.8后
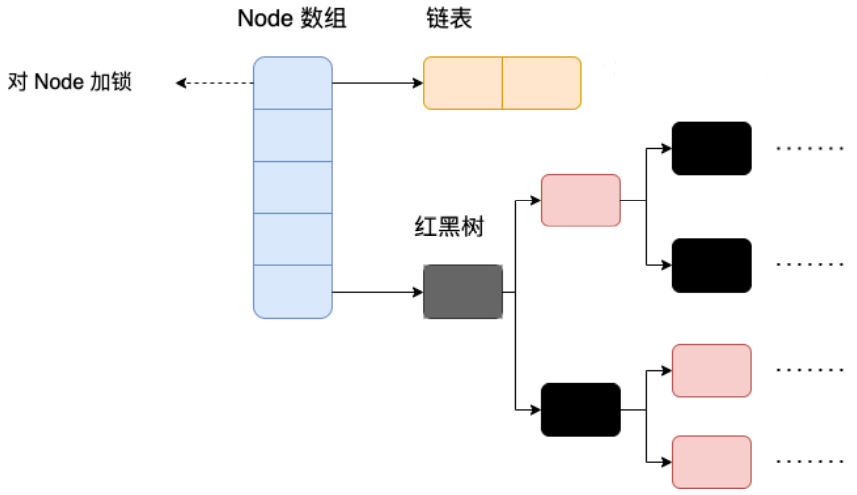
ConcurrentHashMap 取消了 Segment 分段锁,采⽤ Node + CAS + synchronized 来保证并发安全。 数据结构跟 HashMap 1.8 的结构类似,数组+链表/红⿊⼆叉树。Java 8 在链表⻓度超过⼀定阈值 (8)时将链表(寻址时间复杂度为 O(N))转换为红⿊树(寻址时间复杂度为 O(log(N)))。
Java 8 中,锁粒度更细, synchronized 只锁定当前链表或红⿊⼆叉树的⾸节点,这样只要 hash 不 冲突,就不会产⽣并发,就不会影响其他 Node 的读写,效率⼤幅提升。
1.7 和 1.8 实现的不同总结
- 线程安全实现⽅式 :JDK 1.7 采⽤ Segment 分段锁来保证安全, Segment 是继承⾃ ReentrantLock 。JDK1.8 放弃了 Segment 分段锁的设计,采⽤ Node + CAS + synchronized 保 证线程安全,锁粒度更细, synchronized 只锁定当前链表或红⿊⼆叉树的⾸节点。
- Hash 碰撞解决⽅法 : JDK 1.7 采⽤拉链法,JDK1.8 采⽤拉链法结合红⿊树(链表⻓度超过⼀定 阈值时,将链表转换为红⿊树)。
- 并发度 :JDK 1.7 最⼤并发度是 Segment 的个数,默认是 16。JDK 1.8 最⼤并发度是 Node 数 组的⼤⼩,并发度更⼤。