忆如完整项目/代码详见github:https://github.com/yiru1225(转载标明出处 勿白嫖 star for projects thanks)
目录
系列文章目录
一、实验综述
1.实验工具及及内容
2.实验数据
3.实验目标
4.实验步骤
二、ML/DL任务综述与模型部署知识补充
1.ML/DL任务综述
2.模型部署知识补充
二、预训练模型知识补充与本地部署实践
1.任务与模型简介
1.1 任务简介
1.2 模型简介
2.本地部署实践
2.1 DL模型的框架选择
2.2 模型定义
2.3 模型训练
2.4 本地部署
三、其他部署方式实践
1.基于CNN的手写数字识别Web网页部署
1.1 Flask简介
1.2 Web网页部署实践
2.基于Yolo v5的多物体检测
2.1 Yolo
2.2 Yolo部署实践
2.2.1 快速开始
2.2.2 本地部署
2.2.3 Web网页部署
2.2.4 模型训练探索
2.2.5 云服务器部署
四、真实项目中的模型部署解析
1.智慧养鹅
2.电影推荐系统
五、部署方案补充
1.通过机器学习平台进行模型部署
1.1 PAI-EAS
1.2 PAI-Blade
2. 参考资料
系列文章目录
本系列博客重点在深度学习相关实践(有问题欢迎在评论区讨论指出,或直接私信联系我)。
第一章 深度学习实战——不同方式的模型部署
梗概
本篇博客主要介绍几种深度预训练模型与模型部署方式,并通过代码实践与真实项目介绍辅助解析(内附代码与数据集)。
一、实验综述
本章主要对实验思路、环境、步骤进行综述,梳理整个实验报告架构与思路,方便定位。
1.实验工具及及内容
本次实验主要使用Pycharm完成几种预训练模型的编写或git/下载调用,并分别尝试本地部署(简单部署与中间表示)、Web部署(基于Flask、采用云服务器)等不同方式。 另外,最近在腾讯实习期间调研了几种主流机器学习平台,在此尝试利用平台工具进行模型部署,还会通过几个本人的真实项目补充一些部署经历(Uni-app、Android等移动设备)。
2.实验数据
本次实验大部分数据来自预训练模型官方数据,部分测试数据来源于网络。在真实项目的介绍中,大部分数据来自实地采集与构建,版权属于团队。
3.实验目标
本次实验目标主要是了解深度学习模型部署的基本流程,通过实践完成多种不同的部署方式,并能在真实项目开发中应用。
4.实验步骤
本次实验大致流程如表1所示:
表1 实验1流程
| 1.实验思路综述 |
| 2.ML/DL任务综述与模型部署知识补充 |
| 3.预训练模型知识补充与本地部署实践 |
| 4.其他部署方式实践 |
| 5.真实项目中的模型部署解析 |
| 6.模型部署方案补充 |
二、ML/DL任务综述与模型部署知识补充
1.ML/DL任务综述
模型部署实际上是ML(机器学习)/DL(深度学习)任务链路中的一环,为本实验的研究与实践重点,在开始前先对一般ML/DL任务流程做简单补充。
随着大数据、自然语言处理、计算机视觉领域的不断发展,对多种应用场景下的分类、回归等ML/DL任务在日常生活/公司业务/高校研究中均提出了更多解决方案。对于研究者/开发者而言,有大量ML/DL框架、模型;对其他领域的用户,有大量API/无代码IDE工具与在线平台,大大提高了相关任务效率。
而在ML/DL任务中,最重要的是数据与模型,一般流程总结与简介总结于表2:
表2 ML/DL任务一般流程
| 输入: 相关数据(集) |
| 过程: |
| 1、数据处理: 针对输入数据一般要进行处理,包括但不限于数据清洗、归一化、标注,使数据适配模型输入与实际需求。 |
| 2、模型开发: 根据实际任务需求开发模型,或选择已有适配任务的框架/模型调用进行修改。 |
| 3、模型训练与评估: 将处理后数据(集)输入模型,进行训练与迭代,并不断对模型效果进行记录与评估,直至达到较优阈值(在对应任务中有较好的表现)。 |
| 4、模型部署: 将训练好的较优模型部署到指定环境中进行实际应用(常用模型推理测试)。 |
| 5、后处理: 对部署好的模型运行效果进行实际任务的数据检测与分析,并针对出现的问题与局限进行优化。 |
2.模型部署知识补充
在实际进行模型部署之前,我们先对模型部署的一些核心知识进行补充。
由表2我们知道,模型部署实际上就是将开发、训练、评估好的模型进行调用,并使其在所需任务对应环境下正常运行。不同与软件/DL框架部署,模型部署会面临更多的难题,核心的两个问题如下:
⚪ 运行模型所需的环境难以配置:深度学习模型通常是由一些框架编写,比如 PyTorch、TensorFlow。由于框架规模、依赖环境的限制,这些框架不适合在移动设备(手机)、边缘设备(开发板)等生产环境中安装。
⚪ 深度学习模型的结构通常比较庞大,需要大量的算力才能满足实时运行的需求。模型的运行效率需要优化。
因为这些难题的存在,模型部署不能靠简单的环境配置与安装完成。根据相关研究探索,一般的模型部署流程将对训练好的模型进行优化,并通过转化实现运行,如图1所示:
模型在部署后一般会以服务的形式搭载于工具中,故在模型部署中常利用各种前后端框架对功能进行可视化,并对数据进行存储与管理。
此外,随着数据爆炸与云技术的发展,诸多企业提供了带计算与存储资源的云服务器供模型部署、应用上线,以及一站式机器学习平台(Amazon Sage maker、Alibaba PAI、Baidu PaddlePaddle等),其中一般均包含了在线部署工具或部署框架及项目供使用。
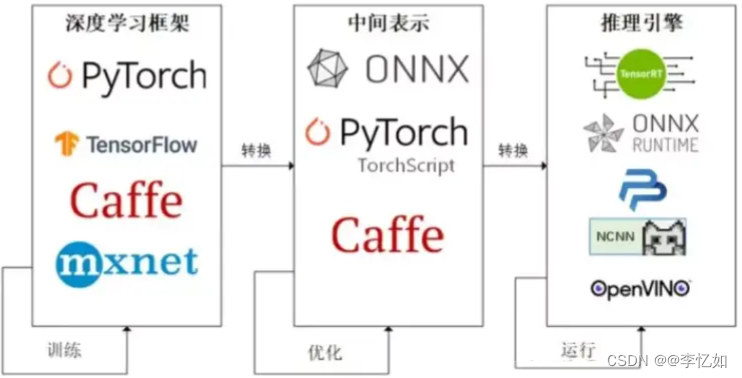
图1 模型训练->部署一般流程
Tips:关于其他部署方案与优化在后文详述。
二、预训练模型知识补充与本地部署实践
在上一章中对ML/DL任务及模型部署的基本知识进行了梳理,自本章开始将正式进行不同方式模型部署的实践,并对使用到的预训练模型进行核心原理的补充。
首先先进行模型本地部署的实践,本章基于CNN的手写数字识别为例。
1.任务与模型简介
在进行模型本地部署前,对本样例的任务与模型进行一定简介。
1.1 任务简介
本章样例选取任务为MNIST数据集上的手写数字识别,MNIST是一个著名的计算机视觉数据集,其包含各种手写数字图片,部分数据可视化如图2所示,本任务即通过设计一个分类模型并使用MNIST数据对其进行训练,得到一个用于识别输入图片中数字的推理模型。

图2 MNIST数据可视化(部分)
1.2 模型简介
本样例以CNN(卷积神经网络)作为分类模型样例,完成手写数字识别的任务。CNN是一种经典的深度学习模型,传统CNN通过输入、卷积、池化、全连接四层高效地完成各种ML/DL任务,实现特征的高效采集与分析。基于CNN的手写数字识别架构如图3所示:
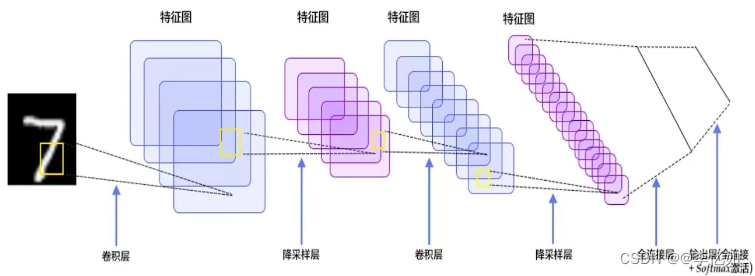
图3 基于CNN的手写数字识别架构
2.本地部署实践
根据第一章第2节补充我们知道,模型部署之前需要定义与训练,即我们要先得到这个模型。根据表2,获取模型的方式一般有调用/下载模型,或自定义模型两种。在本次实践中我们自定义模型并完成本地部署。
2.1 DL模型的框架选择
根据图1我么知道ML/DL任务中常使用框架帮助开发,而在DL模型中,目前最主流的是Tensorflow与Pytorch两种,本样例选择使用TensorFlow框架,但为方便后续Web部署(不需使用Docker),因此选择了是架于TensorFlow、CNTK之上的API,Keras。
主要开发环境:Pycharm2020、Tensorflow2.10
2.2 模型定义
根据第一节中的任务与模型简介,定义基于CNN,用MNIST数据集进行训练的分类模型,核心步骤(即模型开发)如表3所示:
表3 基于CNN,用MNIST数据集进行训练的分类模型定义步骤
| 输入: MNIST数据集(或在代码部分加载) |
| 过程: |
| 1、库导入与参数定义: 在开头对需要用到的函数与框架进行导入,并对模型的(超)参数进行定义。 |
| 2、数据读取与处理: 对数据集进行下载或导入,并进行图像reshape、数据类型改变(float32)、标准化。 |
| 3、模型结构定义: 对模型结构与损失函数定义。 |
| 4、训练与评估: 将处理后数据输入定义好模型,进行训练与评估。 |
| 输出:模型loss、acc,以及通过评估的模型 |
在此过程中,代码部分比较重要的是参数与模型的定义,代码如Code1与Code2:
Tips:本处仅做核心代码展示与解析,完整代码与注释详见文件“CNN MNIST Define.py”。
| Code1 CNN模型参数 |
|
| Code2 CNN模型结构 |
|
2.3 模型训练
在定义好模型后,运行相关代码文件进行训练,过程与结果如图4所示:
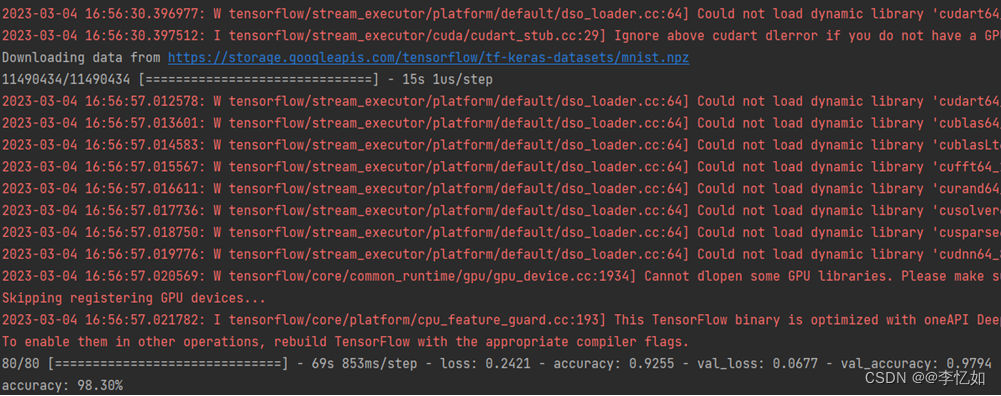
图4 模型训练过程与结果
分析:根据图4,我们可以看到基于CNN,用MNIST数据集进行训练的分类模型在80轮epoch训练后,正确率98.3%,在本样例中通过评估,保存模型model.h5,用于本地部署。
2.4 本地部署
本地部署:将模型部署到本地机器中,以离线的方式进行推理。
一般来说,本地部署有两种方式:
⚪ 模型直接save和load:调用简单,但未对模型处理,不同机器间可能存在适配问题
⚪ TorchScript/ONNX模型导出:以通用的中间表示导出模型,便于部署到不同机器
对于第一种方式,命令如Code3(本样例),Pytorch命令如Code4所示:
| Code3 本样例的模型简单本地部署 |
|
| Code4 Pytorch的模型简单本地部署 |
|
而对于第二种方式,TorchScipt方法主要针对基于Pytorch的模型,故在本部分仅作简单介绍,一般来说,TorchScript提供tracing和scripting两种方式,简介如下:
⚪ Tracing方法:生成一个“伪变量”,跟踪模型对输入变量进行的操作。
⚪ Scripting方法:直接检测模型代码,无需伪变量。
两种方法代码类似,以Tracing方法为例,核心代码如Code5所示:
| Code5 Tracing方法核心代码 |
|
类似TorchScipt,ONNX也是一种便于部署的模型中间表示,不过适用于多种框架。对于Pytorch而言,ONNX采用Tracing的方式记录模型,故需要“伪输入”,转化核心代码如Code6所示:
| Code6 ONNX导出核心代码(Pytorch) |
|
Tips:ONNX同时提供了prepare()方法将ONNX模型转换为Tensorflow并执行推理,样例代码如Code7所示:
| Code7 ONNX转Tf推理样例 |
|
而对于Tensorflow转化到ONNX,tensorflow-onnx有几个条目用于转换不同的tensorflow格式的tensorflow模型,本节只讨论“saved_model”,核心代码如Code8,样例输出如图5:
| Code8 ONNX导出核心代码(Tensorflow) |
|

图5 模型转化中间表示输出样例
分析:如图5所示,样例中Tensorflow模型成功转化为ONNX并导出,便于在不同机器上部署、解析与使用。
Tips:ONXX同样适用于其他框架的转化,且除了本地部署方法提出的两种中间表示,实际上还有其他很多中间表示,在此不做详述。
至此,完成了本样例任务的模型定义与训练,并使用两种方式进行本地部署。
三、其他部署方式实践
除了本地部署外,还有Web部署、移动应用部署、边缘设备部署等方式,在本章对上一章的样例进行Web网页部署,并对其他预训练模型进行不同方式的部署实践。
1.基于CNN的手写数字识别Web网页部署
Web部署:将模型部署到Web架构中,在服务端完成推理,常见的有以下几种方式:
- Flask
- Streamlit
- Gradio
- 厂商Cloud平台(API)
1.1 Flask简介
本节以Flask为例作为架构搭建样例的Web部署,故在此对Flask做一定补充。
Flask是一个由Python编写的轻量级Web框架。通过Flask,我们可以将模型推理部署到服务端,以向服务器发送请求的方式执行推理。
服务端部署与本地部署的最大差别在于执行推理的入口不同。对于本地部署,我们只需在本地环境中编写推理脚本并执行即可。Flask服务部署将在我们已经实现的本地部署的基础上完成服务端的架设(对于本样例而言即已经得到了模型文件model.h5)。
一个Flask的最简单样例代码见Code9,效果如图5所示:
| Code9 Flask的简单样例 |
|

图5 Flask简单样例效果
1.2 Web网页部署实践
了解Flask之后,将基于样例模型(基于CNN,MNIST训练的手写数字识别分类模型)在Flask框架下进行网页部署实践。最终效果如图6所示(数字是进入Web页面后用户绘制):
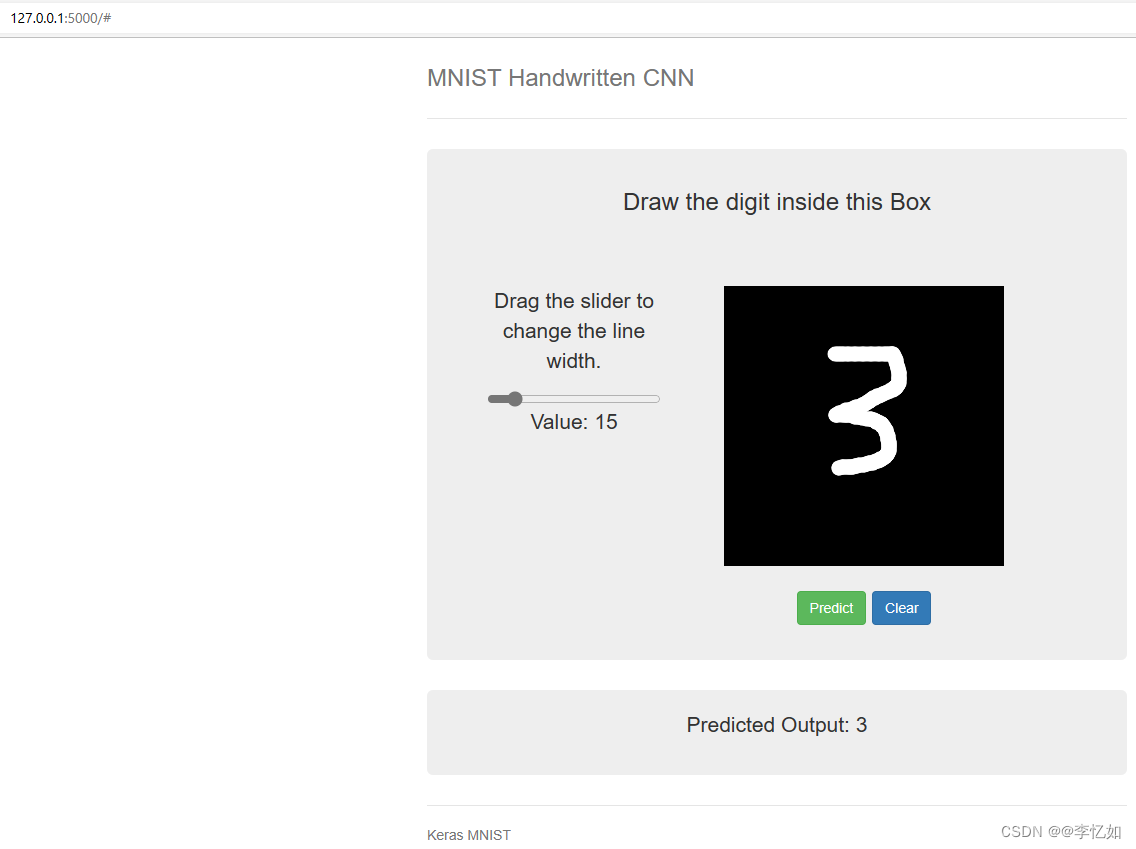
图6 基于CNN的手写数字识别Web网页部署最终效果
接下来开始项目的架构与代码解析,项目整体架构如表4所示
| 表4 CNN MNIST Web项目架构 |
| .CNN ├── static └── index.js # 页面按钮的交互 └── style.css # 页面的样式 ├── templates └── index.html # 页面的框架结构/组件定义 ├── CNN MNIST Define.py # 模型定义 ├── flask_CNN.py # 模型的Web部署主项目 ├── model.h5 # 训练评估后模型 |
Tips:完整代码与注释详见项目代码,在此只做关键代码解析。
(1)推理请求
前端三大件(Html、Css、js)的知识与编写并非本实验的重点,在此不做展开。其中部署相关的是推理/预测请求与按钮逻辑的连接,在本部分做一定解析。
本样例中通过Html定义Predict按钮并调用flask_CNN.py中的predict函数完成请求发送与数据接收,其中前端部分相关核心代码如Code10所示:
| Code10 前端请求发送与数据接收核心代码 |
|
(2)基于Flask的Web部署
本样例中基于Flask的Web部署代码基本编写在flask_CNN.py,部署流程总结于表5:
表5 基于Flask的CNN Web部署流程
| 1、初始化 初始化flask app与与全局变量,并将用户在Web页面画的图生成output.png。 |
| 2、搭建前端框架: 根据Html搭建前端,根据Css设计样式,根据js定义逻辑。 |
| 3、预测: 定义预测函数,并通过调用模型对处理好图像进行预测,返回结果。 |
| 4、输出并展示: 根据预测结果返回数据,展示在前端。 |
| 终端输出:供测试,可运行Web端口 |
根据表5,本样例Web部署核心步骤为预测函数的定义,核心代码如Code11所示(即调用模型预测,在此之前要对用户绘制的图像进行尺度处理,符合模型输入规格):
| Code11 Web部署预测 |
|
至此,基于CNN的手写数字识别分类模型在基于Flask的Web部署流程已完成,根据图6可以看到可以较好地对用户绘制图像进行预测,并在Web网页进行展示。
Tips:将项目导入后直接运行flask_CNN.py即可进入Web页面,开箱即用!
2.基于Yolo v5的多物体检测
除了CNN外,在本节我们尝试使用一些其他的深度模型,也实践一些不同的部署方式,本节样例以基于Yolo v5的多物体检测与识别为例。
2.1 Yolo
在样例实践前,在此简单介绍一下Yolo算法(尤其是Yolo v5),Yolo是一系列模型,从v1到v8,包含经典与前沿的目标检测算法,适配多种追踪、识别算法。经典的Yolo v1实现核心是图像分割与分块预测(每个网格要预测B个bounding box),如图7所示:

图7 Yolo v1核心原理
而对于Yolo v5,是在Yolo v4上微调的模型(相对灵活),网络架构如图8所示:

图8 Yolo v5网络架构
Tips:Yolo不同版本原理相对复杂,本实验主要做实践探究,在此不做展开。
2.2 Yolo部署实践
Yolo v5官方项目及文档可见:
- Github:ultralytics/yolov5: YOLOv5
- Pytorch:YOLOv5 | PyTorch
- 模型:https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s.pt(直接下载)
- 模型选择:Releases · ultralytics/yolov5 (github.com)
补充:模型默认有yolov5s、m、l、x四种,参数量从小到大。
本地环境(Windows):Pycharm2021、torch1.11.0、torchvision0.12.0(推荐使用Ubuntu)
由于本地部署与Web部署定义与原理在上一章节已详述,故本节只做Yolo模型部署的流程梳理与效果展示,部署流程如表6所示:
表6 Yolo 本地及Web部署流程
| 1、环境配置: Yolo一般基于Pytorch框架,故需先配置Pytorch框架,最好加上CUDA配置,注意框架版本与Pytorch版本的适配性,建议使用Conda管理开发环境。 |
| 2、项目与模型下载: 若只是简单使用、部署Yolo模型,可直接下载对应模型;若要基于Yolo优化或基于自己的数据集训练模型需要下载项目导入。 |
| 3、使用模型: 对于简单使用,根据上一章节本地部署与Web部署的方法使用yolov5s.pt文件推理;若需要实际开发或优化,根据需求导入文件与数据集训练模型。 |
| 4、输出、保存并展示: 若是简单使用,根据预测结果返回图像,保存在本地或展示在前端;若是实际开发或优化,保存训练好通过评估的模型。 |
| 输出:本地结果图像/供测试,可运行Web端口/新模型 |
代码项目架构如图9,简单使用主要关注detect.py即可(推理模块),开发与优化需要使用train.py与test.py进行训练与评估测试。另外,coco是官方提供了检测数据集(Yolo v5在此数据集上表现优秀),requirement.txt为项目配置文件。
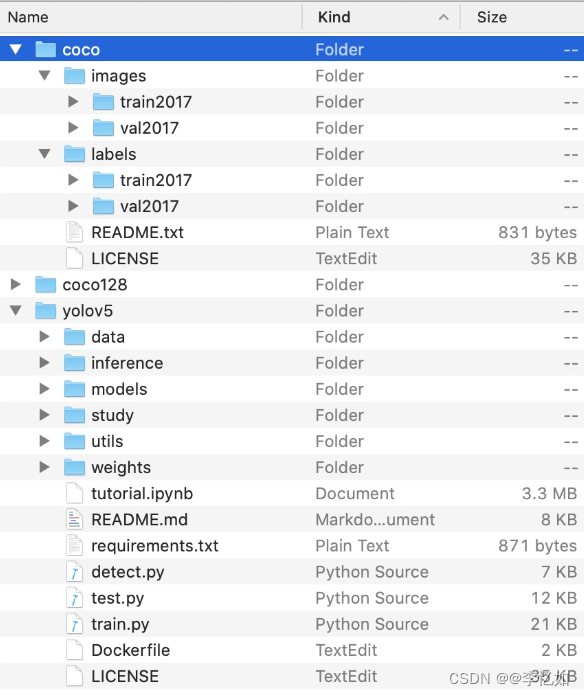
图9 Yolo v5项目核心架构
2.2.1 快速开始
若想最快使用Yolo v5完成实际检测任务(不做配置与模型部署),首先可以考虑Pytorch工具箱的在线服务(需要科学上网):
- https://colab.research.google.com/github/pytorch/pytorch.github.io/blob/master/assets/hub/ultralytics_yolov5.ipynb(Colab在线编译使用)
- YOLOv5 - a Hugging Face Space by pytorch(small Demo)
2.2.2 本地部署
本地使用有在线导入部署(在代码中下载模型)与项目导入部署(下好模型与源码在本地终端或IDE使用)两种。
在线导入部署代码相对简单(需要科学上网),如Code12所示:
| Code12 在线导入部署Yolo v5 |
|
至此,在线导入部署成功。
而对于项目导入部署相对复杂,但可调参数较多(且对国内用户友好),导入与配置代码如Code13所示:
| Code13 Yolo v5导入与配置(本地) |
|
Tips:导入与配置后,还需导入下载的Pt模型文件(若科学上网在项目内会自动下载),或根据model的yaml文件(困难)。
在环境搭建、项目导入配置、模型文件导入后,便可以轻松开始本地部署/使用,简单样例如Code14所示:
| Code14 Yolo v5本地配置/使用(带数据类型) |
|
根据Code14在本地对样例图像进行测试,终端运行如图10所示,结果如图11所示:

图10 Yolo v5本地部署测试终端输出

图11 Yolo v5本地部署测试前后对比样例
分析:根据图10与图11,可以看到在本地可以正常调用Yolo v5模型并输出保存检测后图像,验证了本地部署流程的正确性与合理性。
2.2.3 Web网页部署
和上节样例流程类似,本样例的Web部署同样是基于Flask,相关架构与知识不做赘述。
值得一提的是,Yolo v5项目本就自带flask相关api用于Web网页部署的搭建,详见文件夹flask_rest_api。核心用法是通过restapi.py初始化并配置前后端框架,并基于example_request.py的结果启动服务。
最终部署效果如图12所示:

图12 对于Yolo v5基于Flask的Web部署
分析:如图12,可以看到在Web网页可以正常调用Yolo v5模型并输出保存检测后图像,验证了Web网页部署流程的正确性与合理性。
2.2.4 模型训练探索
在前文中我们知道项目导入后可根据具体需求可在源码项目上训练自己的分类模型,一般流程与表2保持一致。本节我们尝试使用官方数据集coco(带标注多物体数据集)实践训练过程(未修改代码),样例代码如Code15所示:
| Code15 Yolo v5训练 |
|
Tips:参数为自定义,为深度模型基本参数与图像数量,可按需修改。
补充:yolov5可以配置wandb,一个动态展示训练状态的web portal,用以观察loss和设备情况,如图13所示:
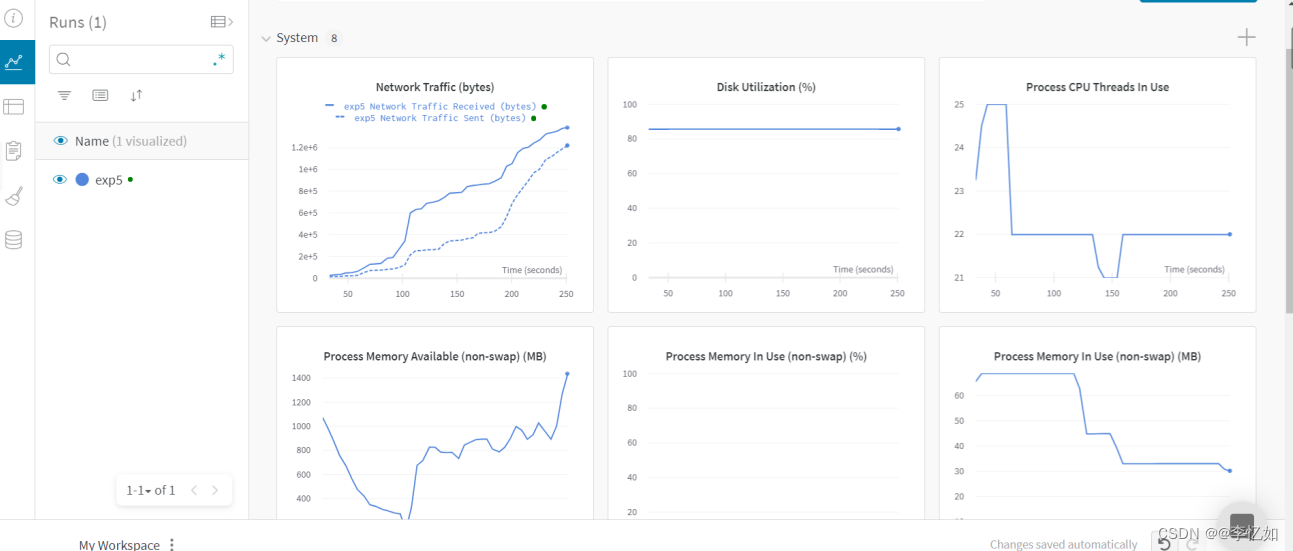
图13 Yolo v5训练过程可视化
而对训练好的模型测试/评估代码样例可见Code16:
| Code16 Yolo v5测试/评估 |
|
本实验的重点为模型部署,模型训练仅作简单尝试,优化部分不做展开。
2.2.5 云服务器部署
根据前文Web部署的定义,我们知道除了Flask等前端框架中,Web部署还常用厂商Cloud平台(API),在本章做简单介绍,以阿里云为例。
Tips:云服务器一般为付费服务,本实验并未实践,仅做理论与流程的简介。
云服务器:带有算力资源,可供在线存储、训练、推理等任务的服务。
为什么要进行云服务器部署:一般是深度模型的训练需要使用云服务器的算力资源,或数据需要使用云服务器的存储资源。
部署前提:本地部署完成,或模型代码未存在重大适配问题。
传输方案样例:如何将文件上传到轻量应用服务器 (aliyun.com)
一般来说,深度模型的云服务器部署流程如表7所示:
表7 深度模型的云服务器部署流程
| 1、服务器配置与购买: 根据实际任务需求配置服务器(算力、内存等资源)进行购买,并设置对应镜像与创建实例。 |
| 2、服务器连接: 通过工具(eg.Xshell)进行云服务器的连接(SSH协议为主)。 |
| 3、环境安装或模型传输: 若对于新任务(无模型需要部署),则与本地开发类似,先进行环境的安装与配置;在已有模型/明确任务的前提下,可以使用模型传输快速开始。 |
| 4、开启服务: 在云服务器上开启服务,进行所需任务。 |
根据资料查阅,对上一样例(基于Yolo v5的多物体检测)进行云服务器部署的代码进行简单介绍。
本节以云服务器已搭建好为前提,前后端部署分别为nginx部署与gunicorn部署,代码分别见Code17与Code18:
| Code17 基于gunicorn的后端部署 |
| sudo apt-get install pip pip install gunicorn gunicorn -w 2 -b 0.0.0.0:5000 flask_app:app #后端部署 |
| Code18 基于nginx的前端部署 |
| sudo apt-get install nginx cd /etc/nginx/conf.d/ # 新建配置文件 vim index.conf # # 配置文件编写 server { listen 80; server_name 139.196.186.165; # 修改成自己的IP地址 location / { root /home/lzq/yolov5-3.1; # 修改成自己的用户名 index index.html index.htm; try_files $uri $uri/ /index.html; } } # 将算法部署到80端口,这样可以通过http://www.lzqlab.xyz或者http://lzqlab.xyz域名进行访问 server { listen 80; server_name www.lzqlab.xyz; # 修改成自己的IP地址 location / { root /home/lzq/yolov5-3.1; # 修改成自己的用户名 index index.html index.htm; try_files $uri $uri/ /index.html; } } server { listen 80; server_name lzqlab.xyz; # 修改成自己的IP地址 location / { root /home/lzq/yolov5-3.1; # 修改成自己的用户名 index index.html index.htm; try_files $uri $uri/ /index.html; } } sudo nginx -s reload # 更新配置文件 sudo service nginx restart # 重启前端部署 |
至此,Yolo v5的云服务器部署与Web展示就成功完成。
四、真实项目中的模型部署解析
在前三章分别引入了模型部署的基本知识,实现了两个样例的本地部署与不同Web部署,在本章通过本人做过的真实项目对移动设备模型部署做一定补充。
1.智慧养鹅
项目简介:本项目为腾班-腾讯云合作项目,旨在通过计算机视觉技术助农,以解决解决传统养殖中鹅群存活率过低问题为主要需求,通过硬件、前端、后端、算法四个组共同完成,最终产品为“智慧养鹅”小程序(已上线),主要实现查看鹅群、疾病预警、数据分析三大功能,项目架构如图14所示:

图14 智慧养鹅项目架构
技术框架:硬件采用部署在鹅厂的服务器以及视觉所的服务器,后端采用Python构建数据库搭配云服务器,前端采用Vue框架,算法部分主要是Yolo v5自训练分类模型(数据库由项目团队采集标注)检测+DeepStream加速推理(原TensorRT)+DeepSort追踪+自定义算法识别病鹅,算法框架如图15所示:
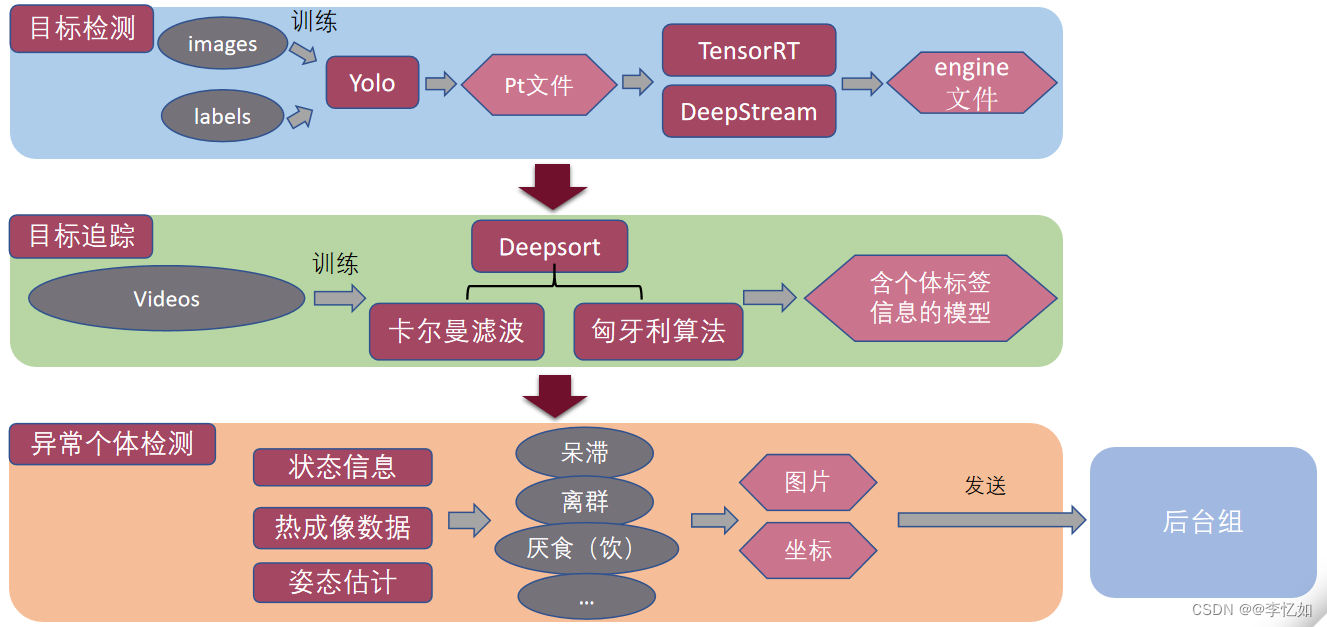
图15 智慧养鹅算法部分架构
由于本次实验重点为模型部署,故我们主要介绍本项目中的模型部署,与前文第二个样例类似,本项目检测模型同样部署在服务器,而整个算法部分是集成为API供后台调用并发送数据给前端,最终效果如图16所示:

图16 “智慧养鹅”小程序展示效果
分析:如图16所示,小程序(移动设备)中可以正常调用算法部分提供的模型对应功能,间接验证了模型部署的正确性。
2.电影推荐系统
项目简介:本项目为云计算领域本人构建的真实项目,顾名思义,旨在通过推荐算法给不同用户提供适合的电影。最终产品为“Yiru recommend for you”(APP,暂未上线),架构如图17所示:

图17 电影推荐系统项目架构
技术框架:开发软件为Android Studio,开发语言为JAVA,推荐算法方面分别使用了基于MapReduce与Spark的几种协同过滤算法(基于用户、模型、物品),同时使用了基于TextCNN的推荐算法,部署时采用Android+Flask进行部署,最终效果如图18:
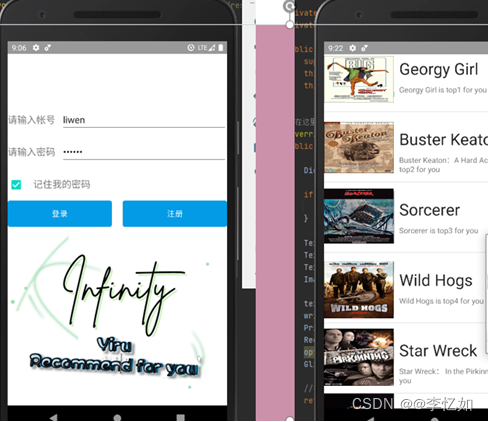
图18 “Yiru recommend for you”APP展示效果
分析:如图18所示,APP(移动设备)中可以正常调用推荐算法部分提供的模型对应功能,间接验证了模型部署的正确性。
五、部署方案补充
前四章对不同经典的部署方案做了定义与不同模型的实践,且搭配真实项目做理论补充,但实际上,除了本地部署、Web部署、移动设备部署等方案,还有一些部署方案与一些模型部署优化理论可以介绍,在本章做简单介绍。
1.通过机器学习平台进行模型部署
在工业界实际上还有其他多种针对特定需求的部署方案,在此不做展开。将匹配度放大,以机器学习平台进行模型部署为例进行部署方案的补充,主流的机器学习平台调研报告详情可见:主流机器学习平台调研与对比分析_@李忆如的博客-CSDN博客。
以Alibaba的平台PAI为例,PAI在模型部署阶段提供了两种服务:PAI-EAS与PAI-Blade
- PAI-EAS :在模型部署阶段,提供模型在线预测服务(弹性推理)
- PAI-Blade:在模型部署阶段,提供推理的通用加速,使其高效到达最优性能
1.1 PAI-EAS
根据简介,我们知道PAI-EAS是PAI平台的模型在线预测服务,有以下几个优势:
①灵活易用:模型部署与服务调用方式灵活,与PAI-Designer、PAI-DSW无缝对接
②异构资源:针对ML、DL模型不同特点,一键部署模型到CPU、GPU
③弹性高可用:高并发高吞吐,服务响应时长短,资源弹性收缩
产品使用方面,PAI-EAS提供了四种模型部署方式与三种服务调用路径,如图19所示:
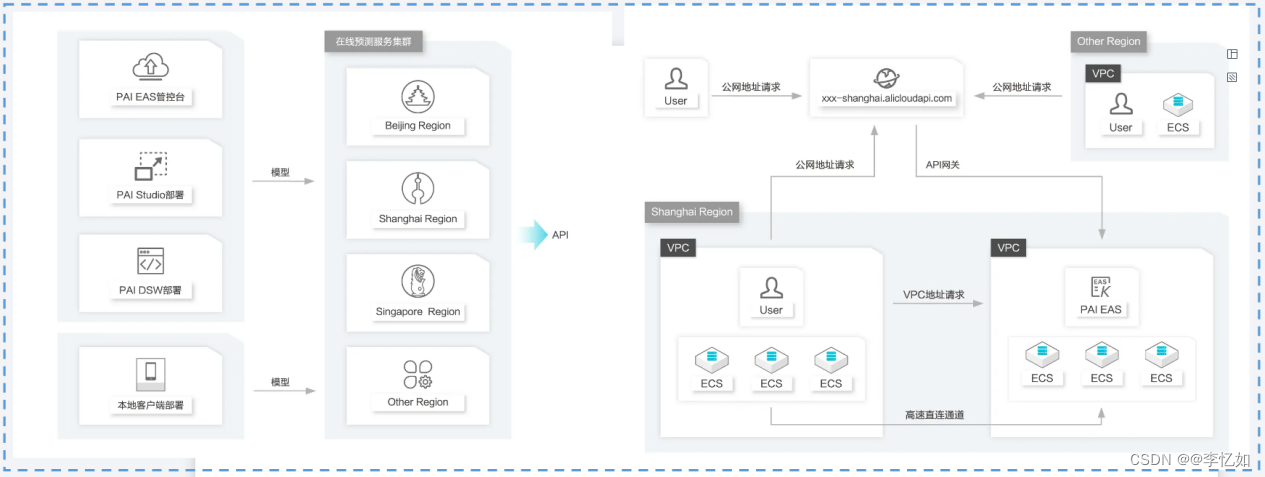
图19 PAI-EAS产品使用:左为模型部署方式、右为服务调用路径
解决方案/应用场景:官网并未明确给出,但在大量ML/DL任务的模型部署中均适用。
产品实践:在产品控制台根据需求定义即可,创建部署样例如图20,结果如图21所示:
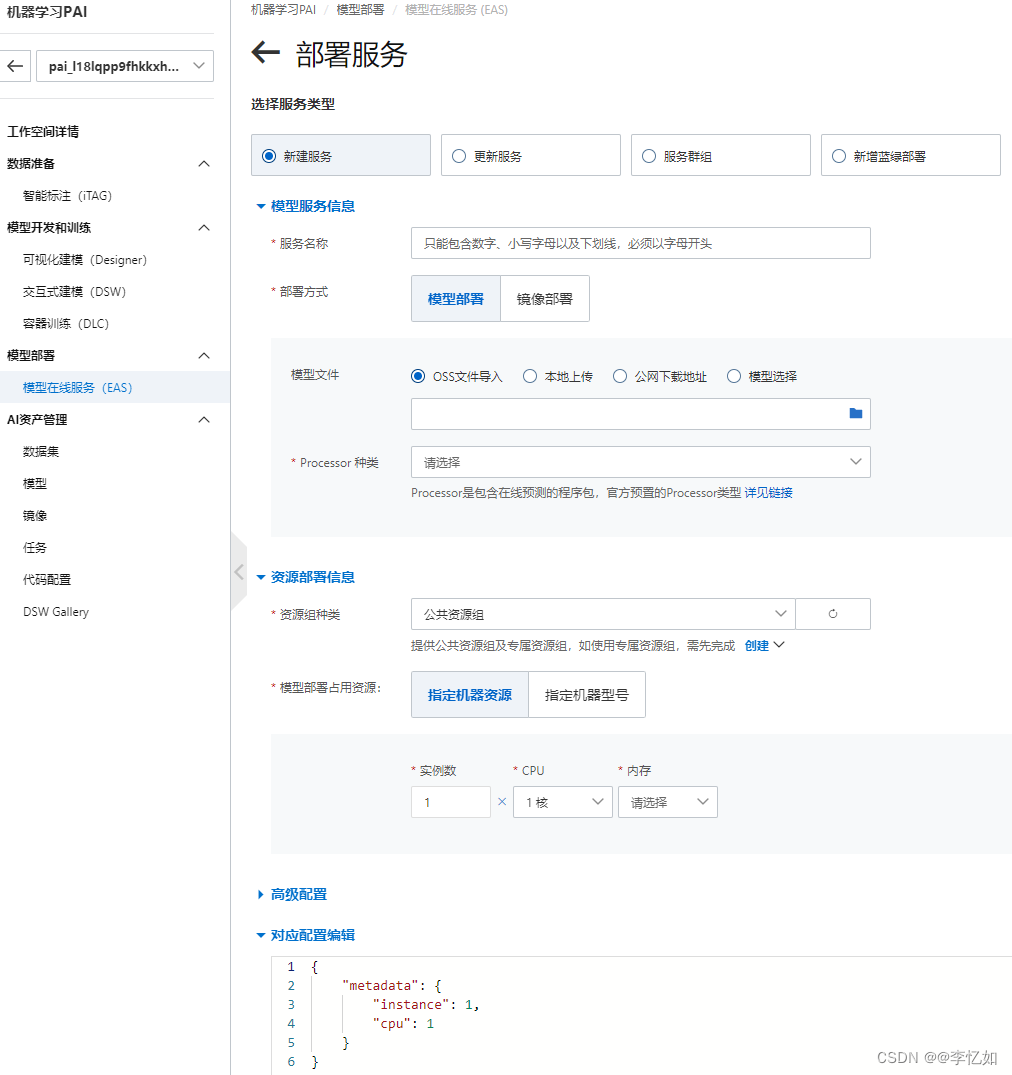
图20 PAI-EAS部署服务创建
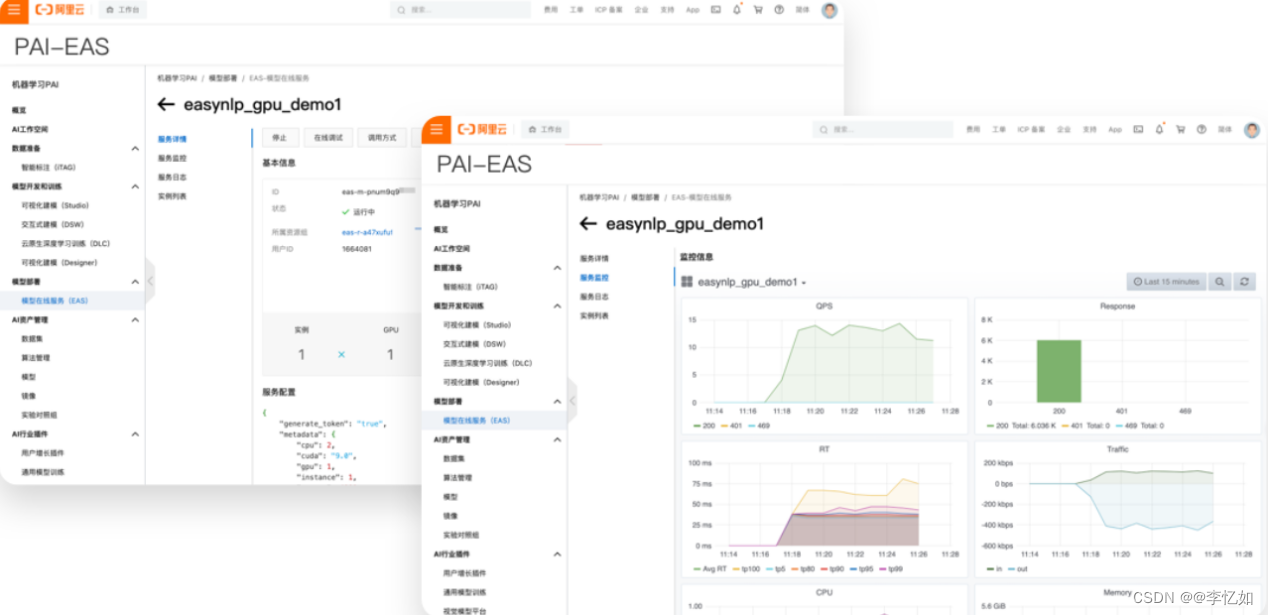
图21 PAI-EAS结果样例
分析:如图20、21所示,PAI-EAS提供用户在线的预测工具,及完整的运维监控体系。
1.2 PAI-Blade
根据定义,我们知道PAI-Blade是一个通用推理加速器,通过模型系统联合优化,有多框架、多设备(GPU、CPU、端)、能力强(支持多种优化技术)、易使用四个特点。技术架构如图22所示:
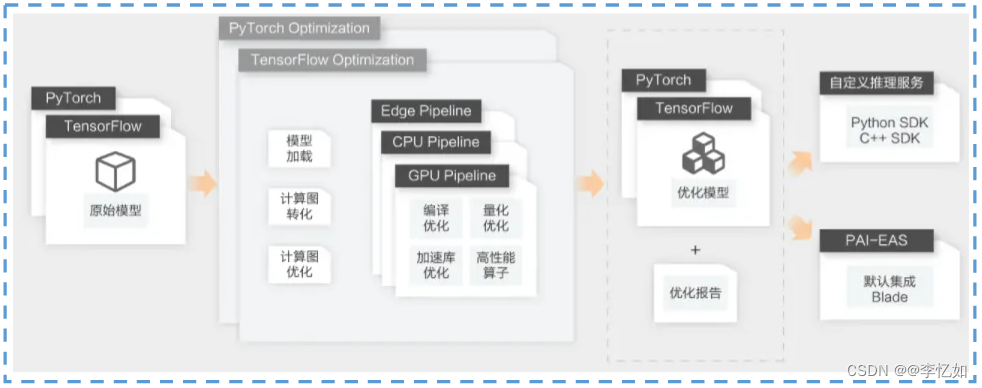
图22 PAI-Blade技术架构
使用步骤:PAI-Blade并不是一个在线服务,而是SDK,安装并使用即可,安装命令根据框架、版本、设备、语言有所不同,详见:模型推理优化Blade (aliyun.com)
Tips:其他主流机器学习平台一般均带有模型部署相关工具,在此不做展开,详见对应官网或调研报告。
2. 参考资料
1.模型部署1/3-构建MNIST手写字深度学习模型 - 知乎 (zhihu.com)
2.模型部署3/3-手把手实现利用flask深度学习模型部署 - 知乎 (zhihu.com)
3.yolov5深度剖析+源码debug级讲解系列(一) yolov5的架构和源码debug准备
4.##如何在阿里云服务器上部署yolov5模型##_yolo部署到服务器_博客菌_lzq的博客-CSDN博客