ZooKeeper配置
解压安装
添加ZK环境变量
分发文件
启动
安装配置 Hadoop
解压安装
修改hadoop-env.sh文件
修改Hadoop配置文件core-site.xml
HDFS 配置文件hdfs-site.xml
MapReduce 配置文件 mapred-site.xml
YARN 配置文件yarn-site.xml
配置worekers
分发配置好的Hadoop
进行初始化
查看每个节点的进程
ZooKeeper配置
解压安装
解压
tar -zxvf apache-zookeeper-3.5.7-bin -C /opt改名
mv apache-zookeeper-3.5.7-bin zookeeper-3.5.7在根目录下创建两个文件夹
mkdir logs
mkdir data
配置zoo.cfg文件,在解压后的ZooKeeper目录中找到 conf 目录,复制一份 zoo_sample.cfg 并重命名为 zoo.cfg,修改 zoo.cfg 配置文件中的以下配置项:
cp zoo_sample.cfg zoo.cfgvim zoo.cfg 修改为
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/zookeeper-3.5.7/data
dataLogDir=/opt/zookeeper-3.5.7/logs
clientPort=2181
server.1=master:2888:3888
server.2=slave1:2889:3889
server.3=slave2:2890:3890

添加ZK环境变量
vim /etc/profile添加如下:
export ZK_HOME=/opt/zookeeper-3.5.7
export PATH=$PATH:$JAVA_HOME/bin:$ZK_HOME/bin
保存配置环境
source /etc/profile分发文件
scp -r /opt/zookeeper-3.5.7/ slave1:/opt/
scp -r /opt/zookeeper-3.5.7/ slave2:/opt/配置 myid:填写上面 server.x 中对应的数字 x,如:1、2、3。每个机子都不一样,
只需要填写一个数字即可。但是这个数字非常重要,必须保证它的唯一性和正确性,否则可能导致集群运行出现问题。
在分发的每个zookeeper-3.5.7/data的目录下面创建myid文件
vim myid文件内填写规则
master中填1
slave1填2
slave2填3
启动
zkServer.sh start注意:集群的每台都需要启动这个命令
所有节点上启动ZooKeeper服务,以便加入到集群中。
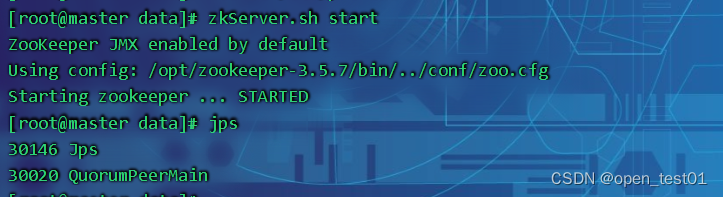
这段日志输出表示ZooKeeper服务已经成功启动,并且JMX功能也已经默认开启。
确认集群中所有节点的信息,以确保它们之间已经建立了有效的连接。可以使用如下命令查看:
zkServer.sh status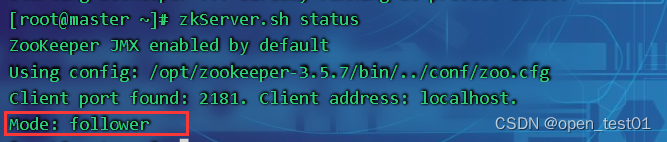
显示Mode: follower就代表已经正常启动了
安装配置 Hadoop
hadoop官方下载:Apache Hadoop
解压安装
解压安装包到opt目录下
tar -zxvf hadoop-3.1.3.tar.gz -C /opt在hadoop-3.1.3 目录下创建目录
mkdir logs
mkdir tmp
mkdir -p tmp/name
mkdir -p tmp/data
添加hadoop环境变量
vim /etc/profile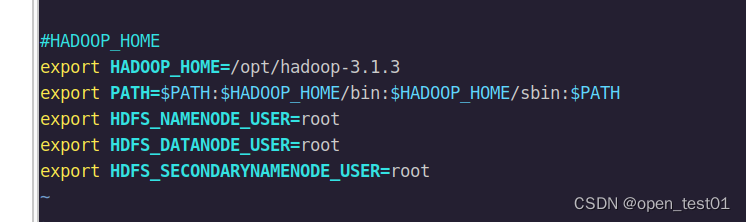
export HADOOP_HOME=/opt/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root注意:另外两台主机也要进行相应的环境变量设置
保存配置环境
source /etc/profile测试安装成功
hadoop version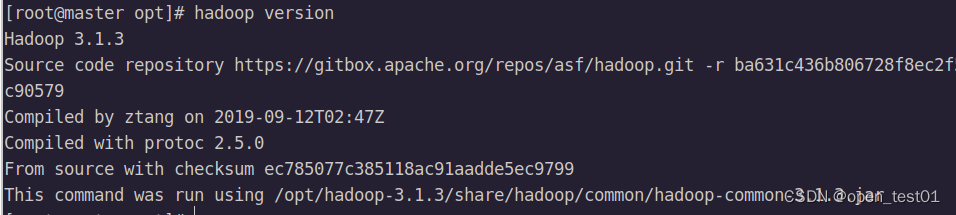
修改hadoop-env.sh文件
cd $HADOOP_HOME/etc/hadoopvim hadoop-env.sh
写入如下:
export JAVA_HOME=/opt/jdk1.8
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
修改Hadoop配置文件core-site.xml
vim core-site.xml<configuration>
<!--用来指定hdfs的老大-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!--用来指定hadoop运行时产生文件的存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.1.3/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,salva2:2181</value>
</property>
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>30000</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>HDFS 配置文件hdfs-site.xml
vim hdfs-site.xml<configuration>
<property>
<name>dfs.qjournal.start-segment.timeout.mx</name>
<value>60000</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>master,slave1</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.master</name>
<value>master:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.slave1</name>
<value>slave1:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.master</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.slave1</name>
<value>slave1:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/mycluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha/CofiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.pricate-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop-3.1.3/tmp/namenode</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>/opt/hadoop-3.1.3/tmp/datanode</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop-3.1.3/tmp/jnode</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timout</name>
<value>30000</value>
</property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.ms</name>
<value>60000</value>
</property>
</configuration>MapReduce 配置文件 mapred-site.xml
vim mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>YARN 配置文件yarn-site.xml
vim yarn-site.xml<configuration>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave1</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
</configuration>配置worekers
vim workersmaster
slave1
slave2分发配置好的Hadoop
scp -r $HADOOP_HOME root@slave1:/opt
scp -r $HADOOP_HOME root@slave2:/opt每个节点需要先启动journalnode
hadoop-daemon.sh start journalnode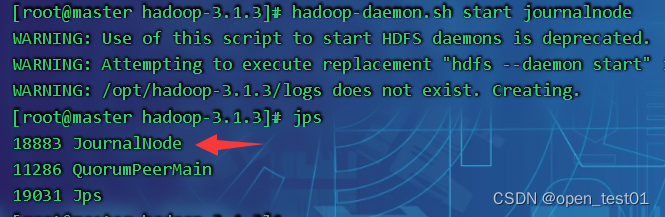
进行初始化
hdfs namenode -format
格式化zkfc
hdfs zkfc -formatZK
将已格式化的namenodetmp目录传给另一个namenode
scp -r /opt/hadoop-3.1.3/tmp/namenode/* root@slave1:/opt/hadoop-3.1.3/tmp/namenode/启动hadoop集群
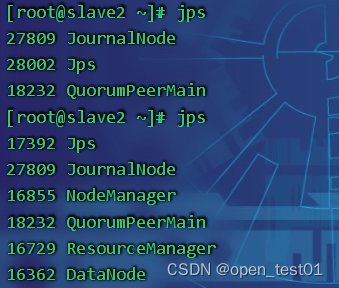
start-all.sh查看每个节点的进程
master:

slave1:
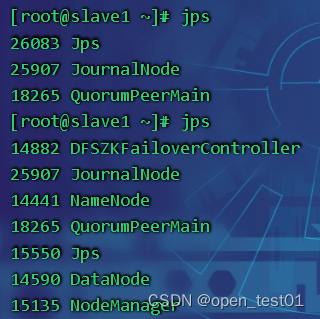
slave2: