索引结点的初步认识
对于整个计算机系统的资源管理,我们可以认为,OS先将这些资源的数据信息,给描述起来构成一个部分,然后再将它们组织起来,就能够实现由OS集中管理。举一个最经典的例子,进程的引入是为了实现程序的并发执行,同一时间间隔内,系统中可能存在大量的进程,OS就需要对这些进程进行管理。首先,OS将进程的各种属性信息描述起来,形成了一个叫做PCB的数据结构,Linux上的PCB叫做task_struct。然后,再将这些PCB组织起来,组织的方式多种多样,例如链接、索引等。
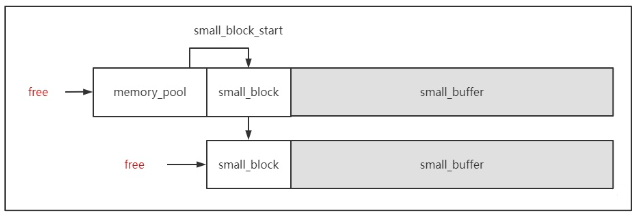
文件的原理也是如此。文件可以视为 文件名 + 文件属性 + 文件内容。OS利用文件控制块,简称FCB,对文件进行控制。文件控制块就是一个结构体,这个结构体里存放了用于控制文件所需要的各种信息。
FCB的有序集合称为文件目录,一个FCB就是一个目录文件项。
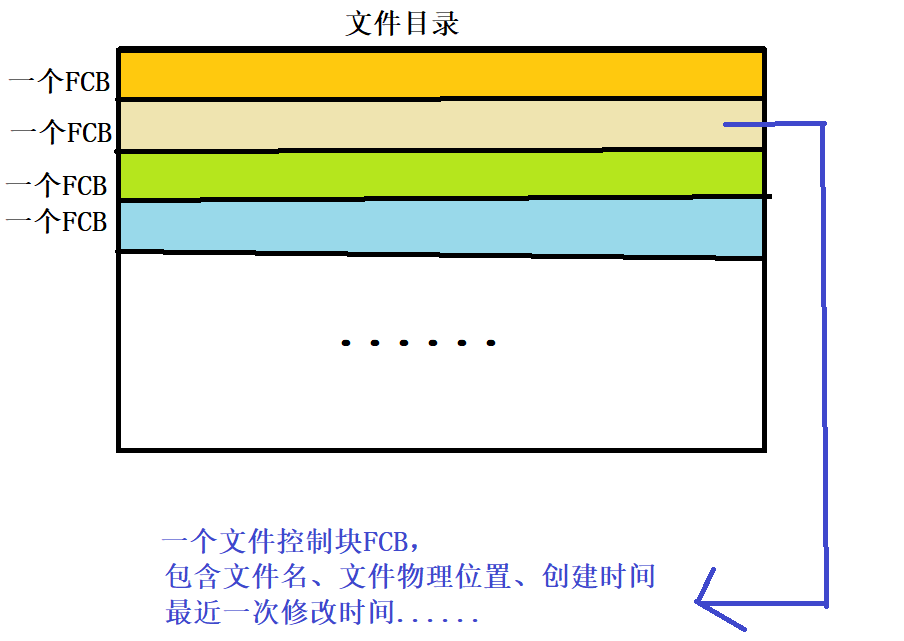
而Linux系统的文件目录采用了文件名和文件属性描述信息分离的策略。
| 文件名 | 文件属性描述信息 |
|---|---|
| file1 | … |
| file2 | … |
| file3 | … |
| … | … |
若你有一定的编程经验,猜都可以猜出,Linux系统绝对不会把一个文件的属性描述信息,直接一坨就放进文件目录中。一是不方便维护,二是不方便检索。
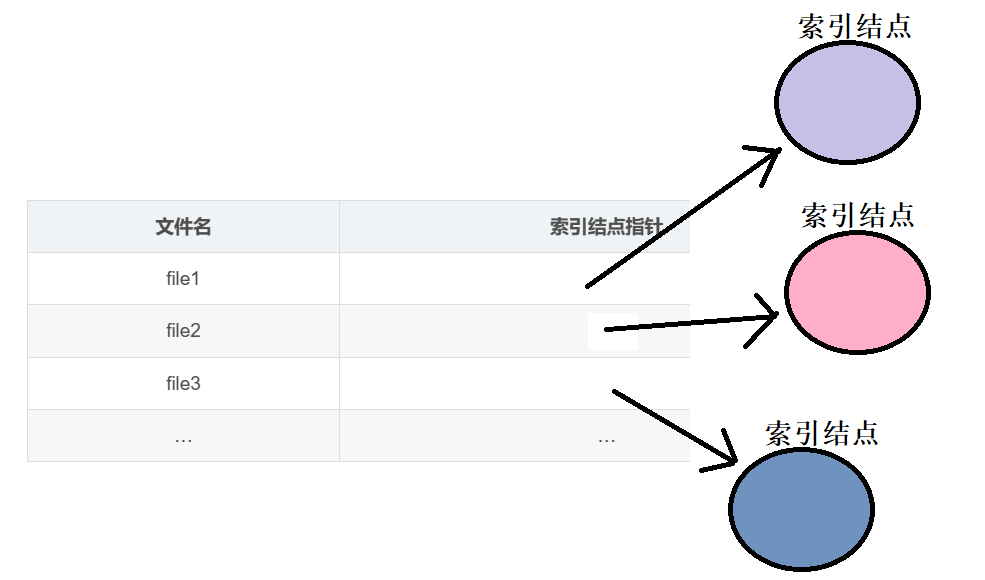
Linux系统将文件的描述信息单独封装起来,放进一个结构体中,这个结构体我们就把它叫索引结点,又可以叫做inode、i结点。Linux的文件目录中不直接存放文件属性的描述信息,而是通过存放索引结点的地址,指向索引结点,就能够找到了。综上,Linux的文件目录的每一个文件目录项由 文件名 + 索引结点指针 组成。
索引结点的深入、结合文件目录和打开文件表
磁盘上有一份索引结点,叫做磁盘索引结点。每一个文件都有唯一的磁盘索引结点与之相对应。如果文件被打开,系统会将对应的磁盘索引结点拷贝一份到内存中,内存中的索引结点叫做内存索引结点,但是内存索引结点在磁盘索引结点的基础之上增加了一些信息,例如索引结点编号。
用户想要对文件进行操作了,首先要使用open系统调用打开文件
//打开一个文件,写入内容,关闭文件
1 #include <stdio.h>
2 #include <string.h>
3 #include <stdlib.h>
4 #include <unistd.h>
5 #include <sys/types.h>
6 #include <sys/stat.h>
7 #include <fcntl.h>
8
9 int main(void)
10 {
11 //打开文件
12 int fd = open("./log.txt", O_CREAT | O_WRONLY, 0644);
13 if(fd < 0){
14 perror("open");
15 exit(-1);
16 }
17 //对文件写入
18 const char* str = "hello Donyan Yang.\n";
19 ssize_t word = write(fd, str, strlen(str));
20 if(word < 0){
21 //写入失败
22 printf("Write Failed!\n");
23 }
24
25 //关闭文件
26 close(fd);
27 return 0;
28 }
也许你没有自己显式地去调用过open系统调用,但只要涉及文件打开,它的底层都会去调用open,C语言里的库函数fopen本质上也是封装了系统调用open。调用open,系统会根据文件名去磁盘上的文件目录里检索,找到该文件对应的inode,然后把它的inode复制到内存里。操作系统会在内存维护一张表,叫做打开文件表,这个表里存放着所有已经打开文件的信息,可以加快搜索文件的效率。inode就是复制到这个打开文件表里(其实也就是一个数组),按照顺序依次存放在表内,并且返回当前inode在打开文件表内的下标,这个下标就是所谓的文件描述符, Windows下叫做文件句柄。open系统调用,返回对应打开文件的文件描述符,通过文件描述符就可以找到该文件对应的inode,控制了文件的inode,这不就把它拿捏了吗?

打开文件后,使用write、read、close等对文件进行操作的系统调用,使用的都是文件描述符,通过文件描述符就可以拿捏住文件,所以打开文件表内没有必要像文件目录一样把文件名也保存起来。
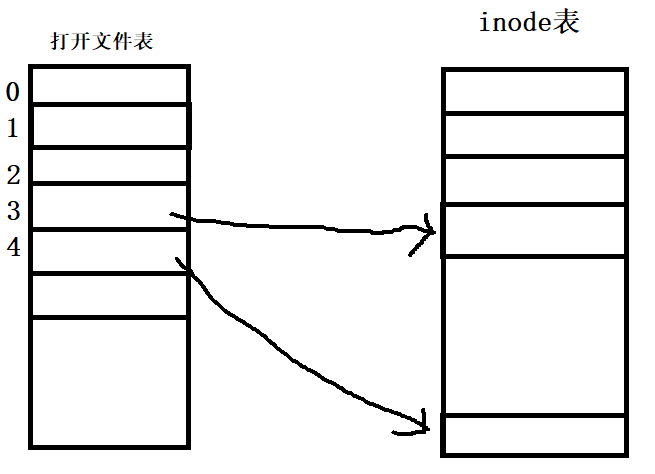
这里的重点不是文件打开表和文件描述符,所以点到为止。
文件共享方式
Windows和Linux系统下,采用了树形结构的目录。
在树形结构目录下,我们如何在两个不同目录下,访问到同一份文件呢?也许你会直接使用cp命令,将这份文件拷贝到另一个目录下,但这并不是最优的办法。拷贝文件到另一个目录下,实际上就是多了一个文件名、文件内容、部分文件属性信息和原来文件相同的文件。虽然看上去这两个文件是一样的,但它们属于不同的两个文件!!!两者之间不存在关联,一个文件的修改并不会影响另外一文件。既然属于不同的文件,系统会为多出来的文件分配空间、建立FCB、为了维护它而消耗资源。 很多情况下,用户可能不需要一份新的文件,例如只是想读取到它的数据、文件修改的时候另一个目录下的这个文件也能跟着被修改…等等,这个时候可以采用文件共享。文件共享不仅可以达成我们的目的,而且在很大程度上减轻了资源的消耗。
文件共享常用的两种方式:硬链接、软链接
硬链接
硬链接的思想建立在索引结点上。其思想如图所示:
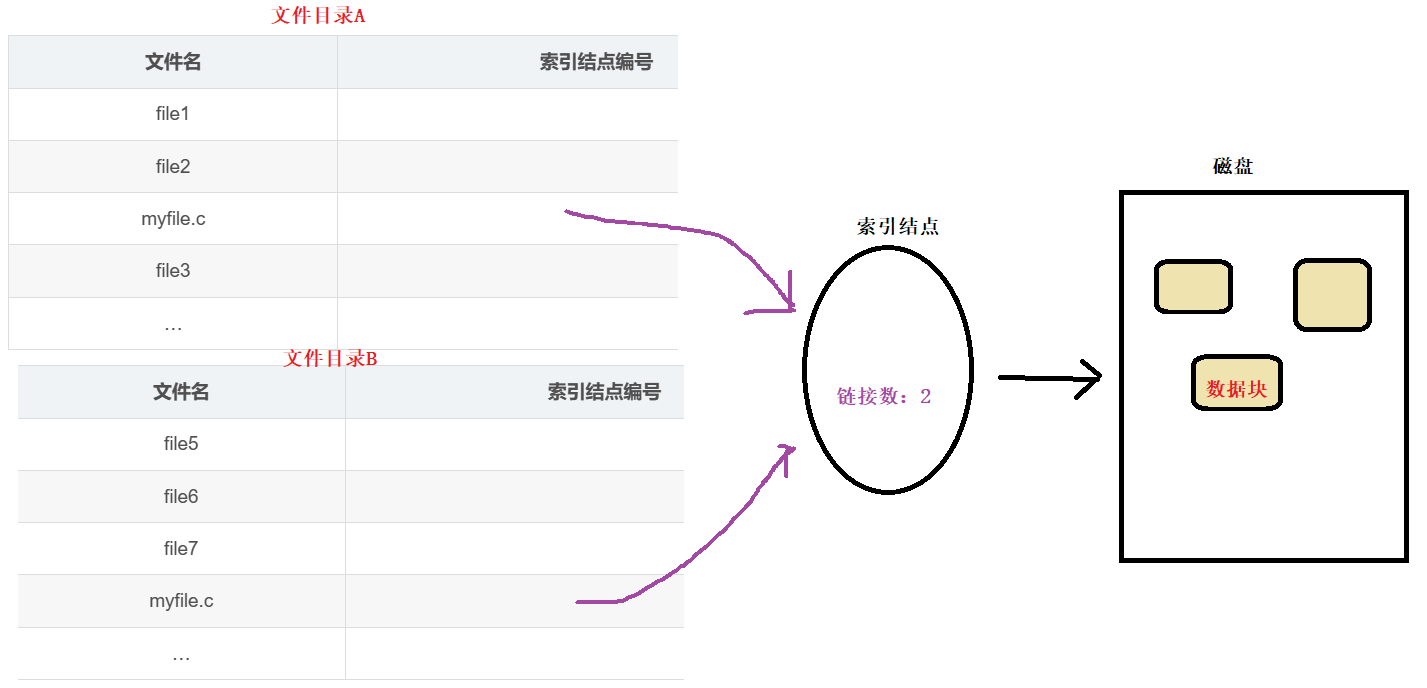
建立硬链接,简而言之,就是在特定的目录下,增加一对文件名和inode的映射关系。
索引结点内部有一个数据,叫做链接数,记录了此时这个inode所关联的文件个数,建立一个硬链接,链接数就会+1。当删除某一个文件时,系统并不会立刻删掉inode,而是去检查它的链接数。如果链接数大于0,说明还有其他文件和这个inode相关联,那么只会删除这个文件目录对应的目录项;如果链接数等于0, 说明没有文件和该inode关联,删除所有对应的信息即可。上面这个例子,文件名允许两个myfile.c同时存在,这是因为它们处于不同的目录下,所以文件名可以相同。如果你想在同一个目录下建立硬链接,原理是一样的,但是文件名不可以重复。
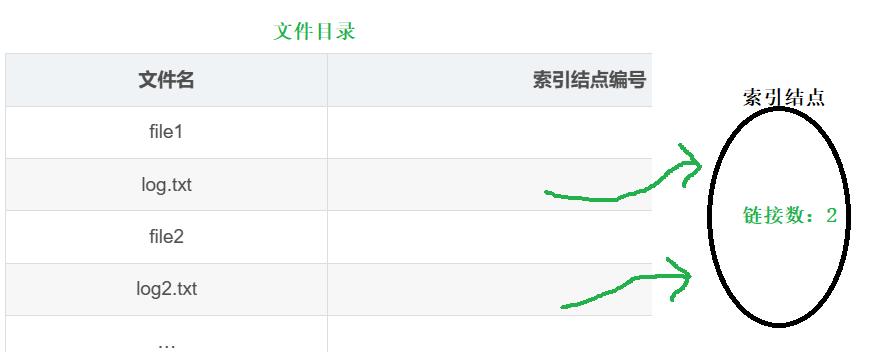
在分析的时候,我们需要使用要命令ls -l -i -a命令,可以查看目录下,各个文件的硬链接数和inode编号。
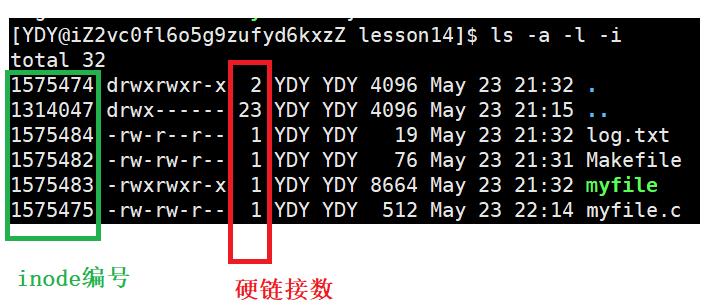
Linux上创建硬链接,使用命令ln 已存在文件 增加文件
例1:在同一个目录下创建硬链接。
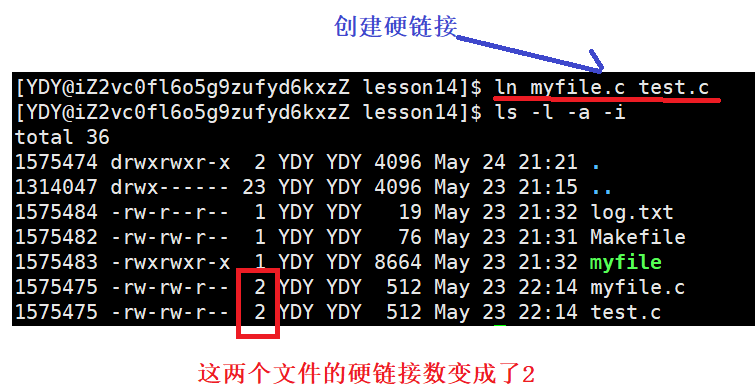
现象,硬链接数变成了2,并且这两个文件所对应的inode是一样的,因为它们的inode编号相同。共享同一个inode,说明这两个文件现在是共享的,唯一的区别只是文件名不同, 如果不放心,还可以用stat查看这两个文件的属性信息。
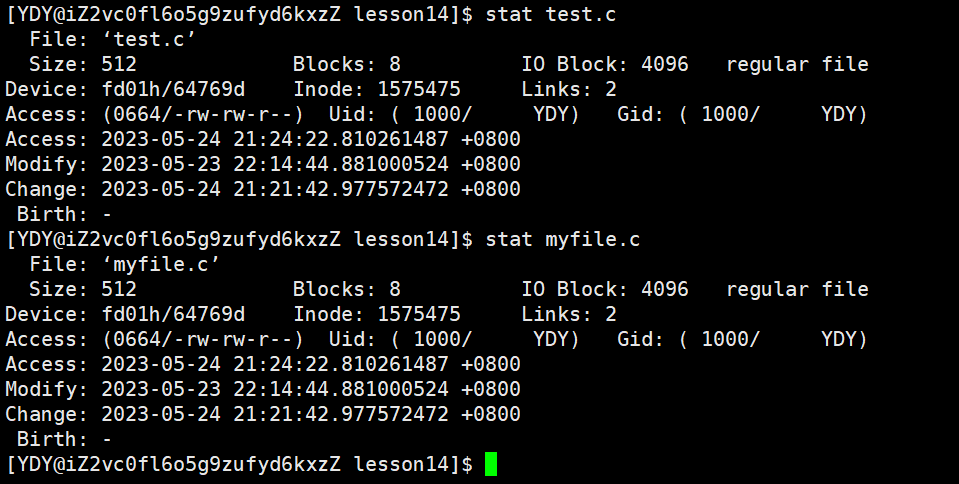
有一个点值得注意,如果你在此之前没有建立过硬链接,现在去查看链接数,会发现.这个文件的硬链接数是2。.表示的是当前目录,当前目录也是一个文件。它上一级所属的文件目录内已经包含了当前文件lesson14与对应inode的映射关系,而系统又自动为lesson14所属的文件目录内建立了文件名为.的文件和那个inode的映射关系。因此,.文件对应的链接数是2。
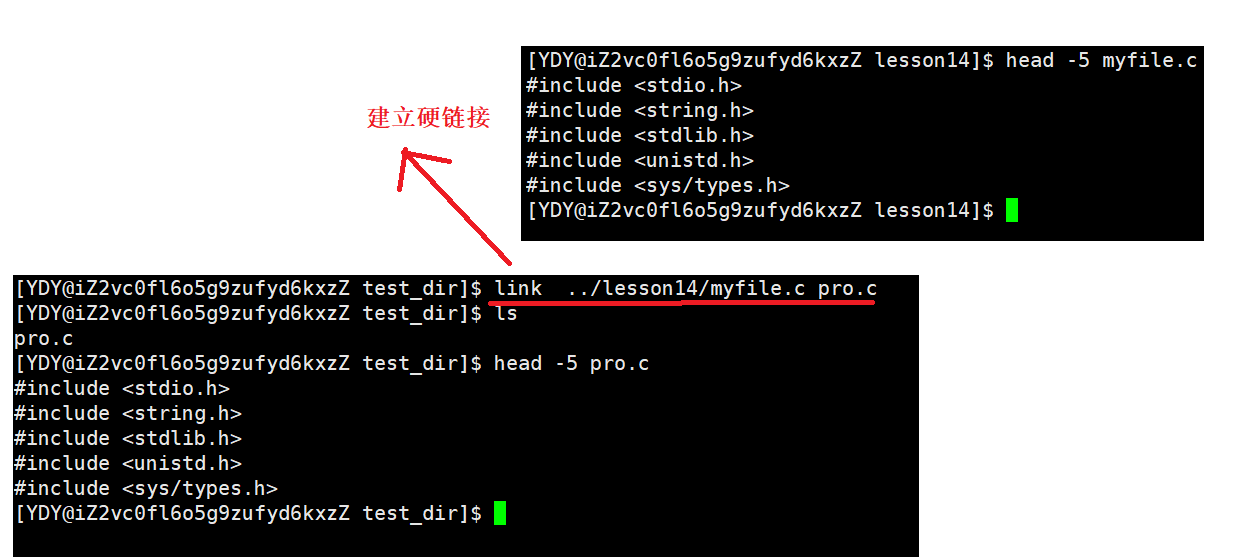
例1:在不同的目录下创建硬链接。
Linux上创建硬链接还可以使用link命令,具体使用方法link 已存在文件 新增文件
软链接
软链接和硬链接的思想是完全不同的, 软链接又叫做符号链接。
Linux上建立软链接的方法:在硬链接原来的命令内加-s即可,也就是ln -s 已存在文件 增加文件。
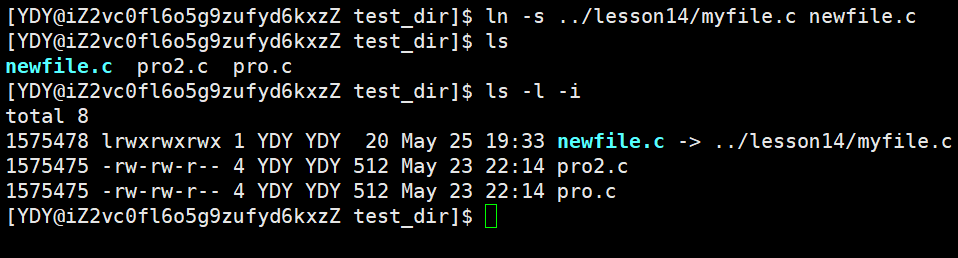
软链接的思想,是利用原来的文件,建立一个叫做LINK类型的新文件。这个LINK类型文件我们可以把它想象成是一个空壳子,它真正拥有的只有文件名,并且目录下这个文件会包含这个LINK类型文件对应的路径。当用户要去访问newfile.c这个文件时,OS发现这个文件是LINK类型的文件,就会根据路径去找到真正的文件源。
来看一个小故事:
注意看,这个女人叫小美,他的搭档叫小帅,小帅拥有一个五百平米的停车库,地址在 麻瓜市麻瓜村开心街道1号 , 它取名为帅帅牌仓库, 放着很多炫酷的机车。小美想要和小帅共享这个仓库,小帅同意了,然后小美自己又对它取了个名字叫做美美牌仓库,并且小美对外称自己拥有一个叫做美美牌的仓库,地址在麻瓜市苦瓜区咕噜街道8号。当她要用仓库里的东西的时候,她就去所谓美美牌仓库找,而实际上是跑去了帅帅牌仓库里找。
这个故事里的行为,和软链接的原理是一样的。
软链接行为里,只有真正的文件源才有inode。就像故事里只有帅帅牌仓库才真正拥有机车,而美美牌仓库并没有。当用户访问LINK类型文件时,表面上看OS根据这个文件进行了检索和一系列的操作,实际上OS根据它提供的文件路径,转变为对该路径上的文件的访问。
软链接可以直接删除主文件,其他软链接产生的文件不会限制主文件。主文件删除了以后,其他相关的LINK类型文件就类似于悬空指针一样(我还指向你, 但是你已经消失了)。用户要去访问LINK类型文件时, OS根据路径去找,没有找到,就访问失败了。









![Java并发体系-锁与同步-[1]](https://img-blog.csdnimg.cn/8d410fe9f73248489e96496cebed2d2d.png)