正则表达式的所有内容:(每一个解释下面都带一个样例)
1.元字符
\:忽略后面一个字符的特殊含义

[a-b]:对a到b之间的任何字符进行匹配

^:在每行的开始进行匹配

$ :在每行的末尾进行匹配
 .
.
.:对任何单个字符进行匹配

*:对前一项进行0次或多次重复匹配

[str] :对str中的任何单个字符进行匹配

[^str]:对任何不在str中的单个字符进行匹配

<:词首定位符

>:词尾定位符
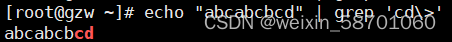
(…):匹配稍后使用的字符的标签

+:匹配一个或多个前导字符

?:匹配零个或一个前导字符

a|b :匹配a或b

():组字符

x{m}:字符x重复m次

[[:alnum:]]:匹配任意一个字母或者数字,等价于[A-Za-z0-9]
[[:alpha:]] :匹配任意一个字母,等价于[A-Za-z]
 [[:digit:]]:匹配任意一个数字,等价于0-9
[[:digit:]]:匹配任意一个数字,等价于0-9

[[:lower:]] :匹配任意一个小写字母,等价于a-z

[[:upper:]] :匹配任意一个大写字母,等价于A-Z

[[:space:]] :匹配任意一个空白符,包括空格、制表符、换行符以及分页符

[[:blank:]]:匹配空格和制表符

[[:graph:]] :匹配任意一个看得见的可打印字符,不包括空白字符

[[:print:]]:匹配任何一个可以打印的字符,包括空白字符,但是不包括控制字符、字符串
结束符‘\0’、EOF文件结束符(-1)

[[:punct:]]:匹配任何一个标点符号,例如“[]”、“{}”或者“,”等
 [[:xdigit:]] :匹配十六进制数字,即0-9、a-f以及A-F
[[:xdigit:]] :匹配十六进制数字,即0-9、a-f以及A-F

(s|t) :匹配s项或t项中的一项

2.量词:贪婪和非贪婪
贪婪和非贪婪:
贪婪模式常用的量词有:
{m,n}
{m,}
?
*
+
如果改成非贪婪模式,只需这样:
{m,n}?
{m,}?
??
*?
+?
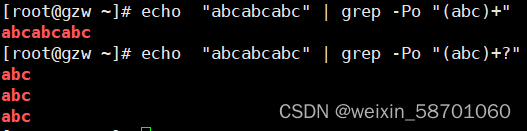
3.转义符: \s: 记得使用-z --null-data: 使用ascii码中空字符来替换新行
\s: 匹配空格,制表符,换行

4.分组:“”,和’’
():

(?:…):非捕获版本,分组不能被引用

(?P…)分组命名

(?#…)注释,不参加匹配

(?=…)正向预搜索,即判定条件, 它不消耗我们的分组: 只做判定条件不返回

(?!…) 对正向预搜索的取非

(?<=…)反向预搜索

![[附源码]计算机毕业设计springboot小区物业管理系统](https://img-blog.csdnimg.cn/9570f70337d2473db5a780bd511b2753.png)






![[附源码]Python计算机毕业设计SSM开放实验室管理系统(程序+LW)](https://img-blog.csdnimg.cn/20a1bea7b797436eb9f79ce29483f688.png)