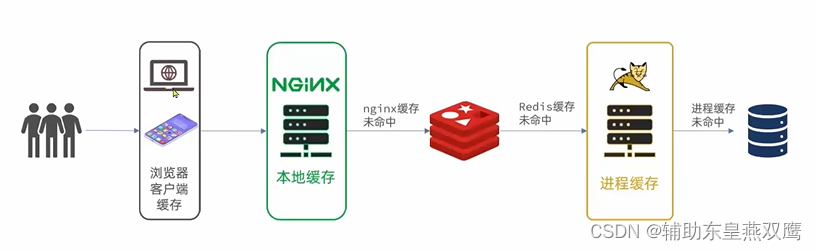
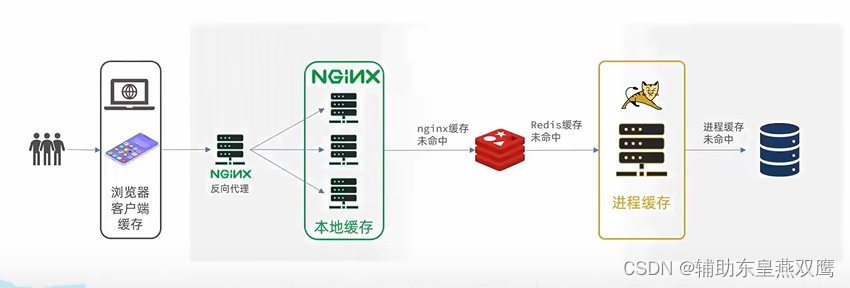
传统的缓存策略是一般请求到达Tomact之后,先进行查询Redis,如果未命中则进行查询数据库,是存在着下面的问题的:
1)请求要经过Tomact进行处理,Tomact的性能成为整个系统的瓶颈;
2)当Redis缓存失效的时候,会对数据库产生冲击;
多级缓存就是充分利用请求处理的每一个细节,分别添加缓存,减轻Tomact服务压力,提升服务器的性能;
这是用做缓存的是nginx,需要部署为集群,在有专门的nginx来做反向代理
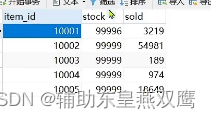
需要提前准备两张表:之所以是将库存分离出来是因为库存是更新比较频繁的信息,写操作比较多,而其它信息修改的频率非常低,还有一个原因,商品的数量是非常多的
1)一方面分表是为了数据解耦合,字段太多查询效率比较低
2)另一方面将来要给这些数据加缓存,如果说所有的数据都在一张表里面,将来进行缓存的时候,是针对一条数据做缓存的,一条数据当作商品的完整信息,那一单这条记录中的一个字段被做了修改,例如说库存被修改了,那么整个商品的缓存就全部失效了,因为你是一条数据,那么缓存失效的概率也就大大增加了,缓存经常性的未命中,这其实是不好的,所以我们要将数据进行分离,经常修改的何不经常修改的都要给他分离开,分成好几张表,最后形成不同的缓存,那么如果一部分数据做了修改了,比如说库存,那么这条带有库存的数据过期了,其他的商品信息是不受影响的
1)商品表:包含商品的基本信息;
2)商品库存表:包含商品的库存信息

本地进程缓存Caffeine:
缓存是日常开发中起到着着至关重要的作用,由于是存储在内存里面,所以数据的读取速度是非常快的,这样可以减少大量访问数据库的压力,我们把缓存分为两类:
1)分布式缓存:Redis;
分布式缓存往往用于集群的环境下,假设现在有N台Tomact,每一台Tomact都要访问这个缓存,这样就可以使用Redis缓存,Redis缓存是独立于Tomact之外的,无论是多少台Tomact,这些Tomact都是可以共享Redis缓存的;
优点:数据存储容量更大,Redis的主从集群可靠性更好,可以在集群中间共享;
缺点:访问缓存有网络开销,Tomact向Redis访问存在网络开销,存在网络延迟;
场景:缓存数据量比较大,可靠性要求比较高,需要在集群中进行共享;
2)进程本地缓存,例如HashMap;
优点:读取本地内存,没有网络开销,速度更快;
缺点:存储容量有限,存储上限取决于JVM,如果JVM的内存全部用于缓存也不行,你的程序会崩溃,可靠性比较低,服务重启就宕机,无法是实现共享,无法在多台Tomact之间共享;
场景:
性能要求比较高,缓存数据量比较小,当Redis缓存未命中的时候,再去查看Redis缓存;
Caffeine:
Caffeine是一个基于JAVA8开发的,提供了几乎命中率的高性能的本地缓存库,目前Spring官方使用的就是Caffeine
1)引入第三方缓存
<!--caffeine本地缓存--> <dependency> <groupId>com.github.ben-manes.caffeine</groupId> <artifactId>caffeine</artifactId> <version>2.7.0</version> </dependency>2)基本Caffeine的使用
import com.github.benmanes.caffeine.cache.Cache; import com.github.benmanes.caffeine.cache.Caffeine; @Test void post(){ //1.创建缓存对象 Cache<String,String> cache=Caffeine.newBuilder().build(); //2.存放缓存对象 cache.put("key1","value1"); cache.put("key2","value2"); //3.取出缓存对象,如果不存在就直接返回null String result1=cache.getIfPresent("key1"); String result2=cache.getIfPresent("key2"); //4.去除缓存对象,如果JVM进程缓存存在就直接返回,如果JVM进程缓存不存在就直接去查询数据库(需要自己在函数中写),然后再将返回的结果存储到缓存里面 String s=cache.get("key3", new UnaryOperator<String>() { @Override public String apply(String s) { return "生命在于运动"; } }); System.out.println(result1); System.out.println(result2); System.out.println(s); }3)Caffeine提供了三种缓存驱逐策略:
3.1)基于容量:设置缓存的数量上限
@Test void post() throws InterruptedException { //1.创建缓存对象 Cache<String,String> cache=Caffeine.newBuilder() .maximumSize(1) .build(); //2.存放缓存对象 cache.put("key1","value1"); cache.put("key2","value2"); cache.put("key3","value3"); //如果这里不加上对应的休眠时间,那么JVM会没有时间清理缓存 Thread.sleep(1000); //3.取出缓存对象,如果不存在就直接返回null String result1=cache.getIfPresent("key1"); String result2=cache.getIfPresent("key2"); String result3=cache.getIfPresent("key3"); System.out.println(result1); System.out.println(result2); System.out.println(result3); }3.2)设置缓存的有效时间,如果缓存一定时间内没有人来进行访问,那么缓存失效
@Test void get() throws InterruptedException { Cache<String,String> cache=Caffeine.newBuilder() .expireAfterWrite(Duration.ofSeconds(1)) .build(); //存放数据 cache.put("key","value"); //休眠1.2s让key过期 TimeUnit.SECONDS.sleep(2); //查看key是否还存在 System.out.println(cache.getIfPresent("key")); }3)基于引用:设置缓存为软引用或者弱引用,利用GC进行回收缓存数据,性能比较差,不建议使用
在默认情况下,当一个缓存元素过期的时候,Caffeine不会立即清理和驱逐,而是一次读或者写操作后,或者在空闲时间内完成对失效数据的驱逐
实现用户查询缓存:127.0.0.1:8081/Java100?userID=1
@Configuration public class CaffeineConfig{ @Bean(name="cache") public Cache<Integer,User> UserCache(){ return Caffeine.newBuilder() .initialCapacity(100) .maximumSize(10000) .build(); } }@Controller public class UserController { @Autowired private DemoMapper mapper; @Autowired @Qualifier(value = "cache") private Cache<Integer,User> cache; @RequestMapping("/Java100") @ResponseBody public User get(Integer userID) { User user=cache.get(userID, new Function<Integer, User>() { @Override public User apply(Integer userID) { return mapper.SelectUser(userID); } }); return user; } }
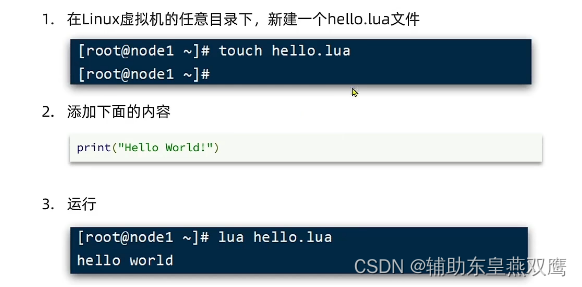
初始lua语言:
lua是一种轻量小巧的脚本语言,用标准的C编写,其设计目的就是为了嵌入到应用程序中,从而为程序提供灵活的扩展功能和定制功能
编写lua脚本:
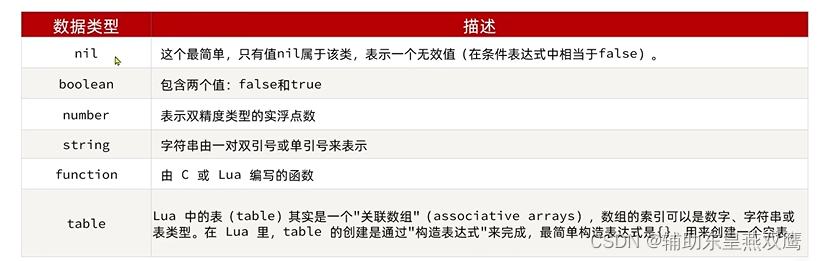
数据类型:
1)nil在lua中可以代表false
2)函数也是一种类型
3)lua中的table类似于JAVA中的HashMap,既可以表示Map也可以表示数组,当key是数字的时候,Table就是一个数组,当Key是字符串的时候,那么Table就是一个Map
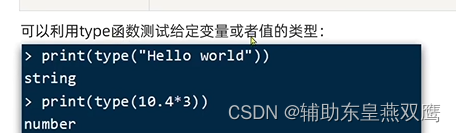
4)可以通过type函数来观察变量的类型,还可以直接通过输入lua命令来进行执行脚本
print(type(print))---->function
5)声明变量:当使用命令行进行操作lua语句的时候,local仅仅是一个局部变量,在下一行就不能访问了,要想变成全局变量,就不要使用local
local array1={"java","C++","python"}; local array2={100,200,300,400,500,600}; local array3={name="jack",age=19,school="口琴小学"}; print(array1[1]) print(array1[2]) print(array3['name']) print(array3.name)循环:
local array1={"java","C++","python"}; local array2={100,200,300,400,500,600}; local array3={name="jack",age=19,school="口琴小学"}; for index,value in ipairs(array1) do print(index,value) end for index,value in pairs(array3) do print(index,value) end 注意:遍历数组使用的是ipairs,其他的遍历map使用的是pairs函数:
local array1={"java","C++","python"}; local array2={100,200,300,400,500,600}; local array3={name="jack",age=19,school="口琴小学"}; local function printArray(array1) do if(!array1) print("数组不能为空"); return nil; for key,value in ipairs(array1) do print(key,value) end end条件控制:






冷启动:当服务刚刚启动的时候,Redis中并不存在着缓存,如果所有的商品都是在第一次查询的时候增加缓存,可能会给数据库带来巨大的压力
缓存预热:在实际开发中,可以使用大数据统计用户访问的热点数据,在项目启动的时候就可以见这些热点数据提前查询并保存到redis中,因为此时的数据量比较少,我们就可以把所有的数据存入到缓存中
缓存同步策略:
1)设置有效期:给缓存设置有效期,到期以后自动删除,再来进行查询数据的时候进行更新
优势:简单方便
缺点:失效性比较差,缓存过期之前可能不一致,数据库和缓存之间会存在误差
场景:更新频率比较低,时效性要求比较低的业务,比如商品里面有商品的基本信息,库存信息,价格信息,描述信息,规格信息等等,将来我们把这些数据全部进行分离,像主页这种不经常发生变更的就可以使用过期的方式来完成同步;
2)同步双写:再修改数据库的时候,同步更新缓存,要么执行成功,要么全部执行失败,存在线程安全问题
优势:时效性强,缓存和数据库强一致性
缺点:有代码侵入,耦合性比较强,比如说进行增删改查的时候,不用去新增商品的时候要去更新缓存;
场景:对一致性,时效性比较强的缓存数据
3)先删除缓存,再更新数据库:存在线程安全问题
4)异步通知:修改数据库的时候发送事件通知,相关服务监听之后修改缓存数据,当修改数据库中的数据的时候直接告诉缓存,你们全部给我修改,至于你什么时候修改我不关心,通知到位就可以了;
优点:
1)代码的耦合性比较低,进行更新数据库的时候不需要再写更新缓存的逻辑了,这个通知可以被多个缓存服务接收到;
2)缺点:时效性比较差,可能存在中间不一致的情况,什么时候收到通知?什么时候进行修改?这都是未知的;
3)场景:时效性一般,有多个服务需要同步;

初始Canal:
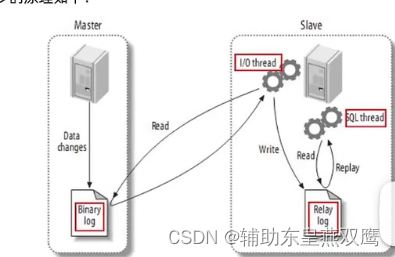
1)canal是基于MYSQL的主从同步来实现的,master主节点针对于数据进行增删改查的时候,就会记录一个日志到Binary log里面,日志里面就是执行的业务SQL,MYSQL的见数据变更写到二进制日志里面,其中记录的日志就是binary log events;
2)slave从节点就会开启一个线程不断地去读取Binarylog中的日志文件写道Relay log里面,这个日志也被称之为是中继日志
3)从节点又会开启一个线程去读取Relay log中的日志去进行执行
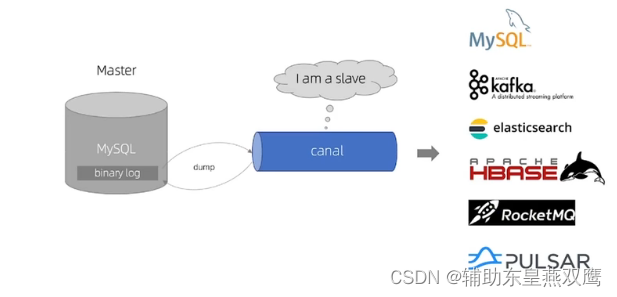
4)Canal就是把自己伪装成MYSQL的一个从节点,从而监听MYSQL中的binarylog中的变化,再把变化的信息通知给Canal的客户端,进而去完成其他数据库的同步