前言
哈喽,各位小伙伴大家好,本章内容为大家介绍计算机当中为了提高数据相互传输时的效率而引进的一种重要设计结构叫做LRU Cache,下面将为大家详细介绍什么是LRU Cache,以及它是如何是实现的,如何提升效率的。

1.什么是LRU Cache?
LRU是Least Recently Used的缩写,意思是最近最少使用,它是一种Cache替换算法。 什么是
Cache?狭义的Cache指的是位于CPU和主存间的快速RAM, 通常它不像系统主存那样使DRAM技术,而使用昂贵但较快速的SRAM技术。 广义上的Cache指的是位于速度相差较大的两种硬件之间, 用于协调两者数据传输速度差异的结构。除了CPU与主存之间有Cache, 内存与硬盘之间也有Cache,乃至在硬盘与网络之间也有某种意义上的Cache── 称为Internet临时文件夹或网络内容缓存等。

Cache的容量有限,因此当Cache的容量用完后,而又有新的内容需要添加进来时, 就需要挑选
并舍弃原有的部分内容,从而腾出空间来放新内容。LRU Cache 的替换原则就是将最近最少使用
的内容替换掉。其实,LRU译成最久未使用会更形象, 因为该算法每次替换掉的就是一段时间内
最久没有使用过的内容。
2.LRU Cache的实现
下面将通过leetcode上的一道设计LRU Cache的oj题讲解如何实现LRU Cache:
LRU Cache
题目要求:

题目解析:
1.初始化容量大小为capacity
2.get:根据关键字key获取value值
3.put:
a.key存在,则修改value
b.key不存在,插入key-value结点
c.插入结点关键字超过capacity就移除最久未使用的关键字
要求:get和put必须以O(1)的平均时间复杂度运行

要保持高效实现O(1)的put和get,那么使用双向链表和哈希表的搭配是最高效和经典的。使用双向链表是因为双向链表可以实现任意位置O(1)的插入和删除,使用哈希表是因为哈希表的增删查改也是O(1)。
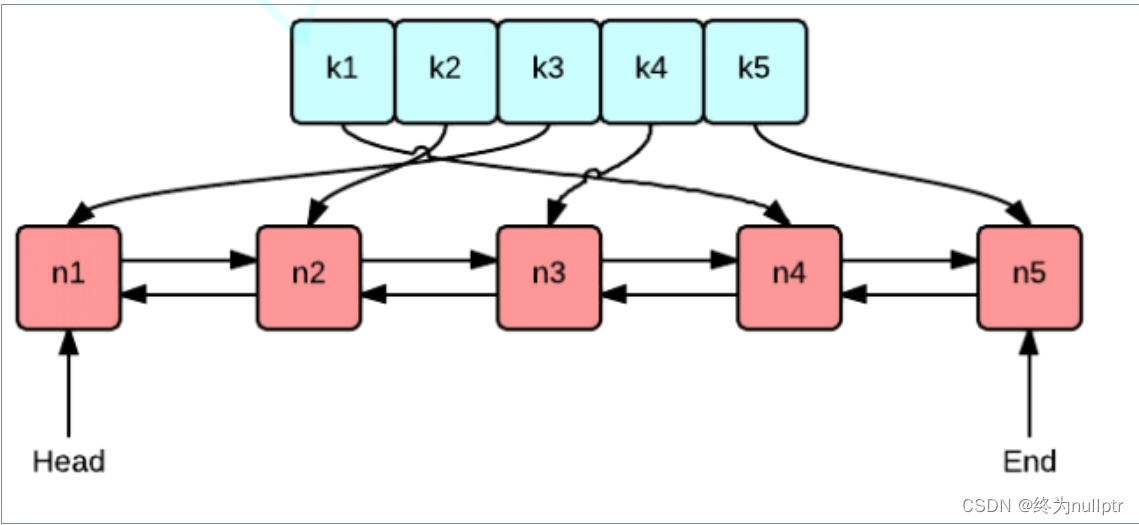
代码实现:
class LRUCache {
public:
LRUCache(int capacity)
:_capacity(capacity)
{}
int get(int key) {
unordered_map<int,Liter>::iterator it = _hashMap.find(key);
if(it != _hashMap.end())
{
//更新key位置对应的位置
//splice:转移结点
_LRUList.splice(_LRUList.begin(),_LRUList,it->second);
return it->second->second;
}
return -1;
}
void put(int key, int value) {
unordered_map<int,Liter>::iterator it = _hashMap.find(key);
if(it == _hashMap.end())
{
//数据满了,先删除尾部的数据:
if(_capacity == _hashMap.size())
{
pair<int,int> back = _LRUList.back();
_hashMap.erase(back.first);
_LRUList.pop_back();
}
_LRUList.push_front(make_pair(key,value));
_hashMap[key] = _LRUList.begin();
}
else
{
it->second->second = value;
_LRUList.splice(_LRUList.begin(),_LRUList,it->second);
}
}
private:
typedef list<pair<int,int>>::iterator Liter;
//保证查找和插入时O(1),second保存迭代器保证更新也是O(1)
unordered_map<int,Liter> _hashMap;
//假设尾部数据是最近最少用,修改的时候数据插入到头部
list<pair<int,int>> _LRUList;
size_t _capacity;
};