大家好,我是千与千寻,也可以叫我千寻哥,说起来,自从ChatGPT发布之后,我就开始焦虑,担心自己程序员的饭碗会不会哪天就被AIGC取代了。
有人说我是过度焦虑了,但是我总觉有点危机感肯定没有坏处。(结尾反转,hhh,希望你看下去!)
不过好家伙,还没等AIGC大模型完全替代程序员,我发现AIGC大模型又开始抢三维建模行业从业者的饭碗了…
OpenAI公司有整新活了,发布了模型应用shape-E,这个模型能干什么呢?千寻先卖个关子!先给大家介绍一种职业,3D建模师。
3D建模师,这个职业的工作内容是什么呢?
3D建模师,在工业界和游戏界里面的需求最多。通俗来说,就是将二维平面的人物形象进行三维建模的转换。啊这?说人话!我们直接用一个例子说明:
《哆啦A梦》人员合照2D版本

《哆啦A梦》人员合照3D版本

将平面的2D的动漫形象,转化为3D立体的手办,用于制作3D动漫大电影,这是在游戏与动漫里面的3D建模应用。
其实3D建模技术,更多的应用在工业届多一些,在前几年3D打印技术十分火爆的时候,就类似现在的ChatGPT的风口,在三维建模软件里面画好三维模型,直接通过3D打印机打印出来零件。3D建模技术的最佳应用之处就是3D打印。
3D的齿轮模型建模

通过以上的三维建模仿真,然后再接入3D打印机就可以实现齿轮零件的实际打印需求。而且现在3D打印技术已经飞入寻常百姓家了,所以有条件的,真的可以尝试一下,很有意思。
讲解完了2D转换为3D建模的实际效果,下面我们进入本文章的正题,OpenAI发布的这个shape-E算法模型。
这个模型的话,它能实现的功能的话包括两种。
一、输入文字描述来输出指定的三维模型图
我们先来看一下官方的生成例子
- 一个生日蛋糕

- 一个像树一样的椅子

- 一个正在跑步中的人

以下是官方提供生成的三维模型的合集图片。可以看到官方生成的模型效果还是很不错的。
千寻自己也测试了一些,给大家看看效果
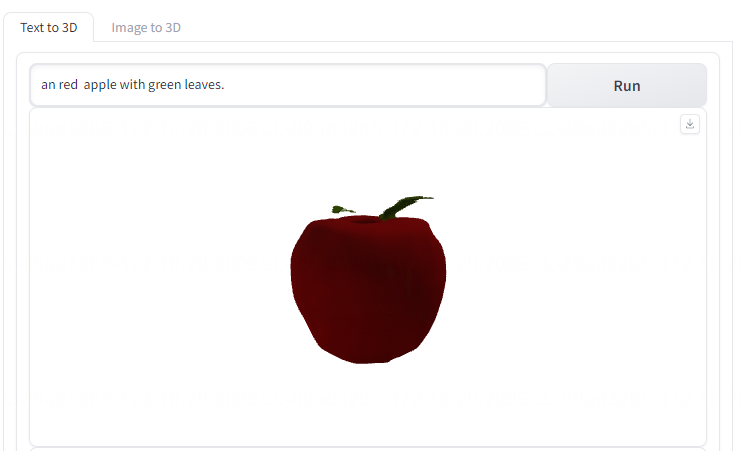
- a red apple with green leaves
(一个带绿叶的苹果)
- a desk
(一张桌子)

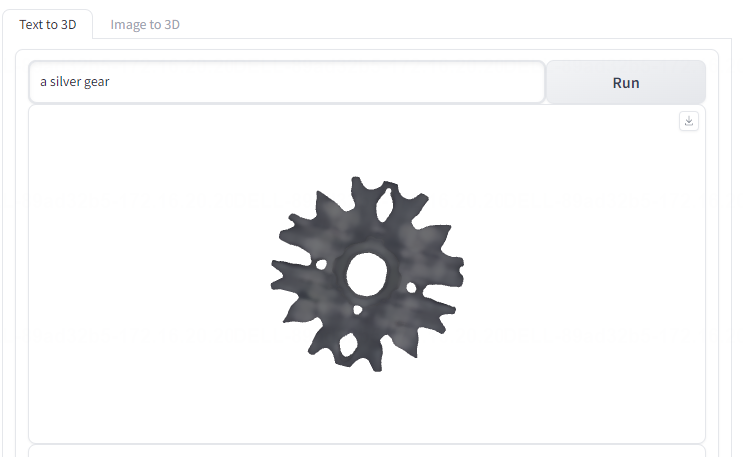
- a silver gear
(一个银色的齿轮)
千寻测试的这几个“文字转3D模型”的测试用例都是相对简单一些的。
而且千寻发现,还是输入的text文字描述,最好还是英文句子,借助一下谷歌翻译,可以保证3D模型生成的效果更加漂亮、准确。
二、输入二维平面图输出指定的三维模型图
除了实现输出文字描述可以生成三维模型的图片,我们也可以通过输入3D模型的平面视角图片,生成3D模型,以下是一些简单的生成效果,供大家参考。
- 二维齿轮图片转三维模型
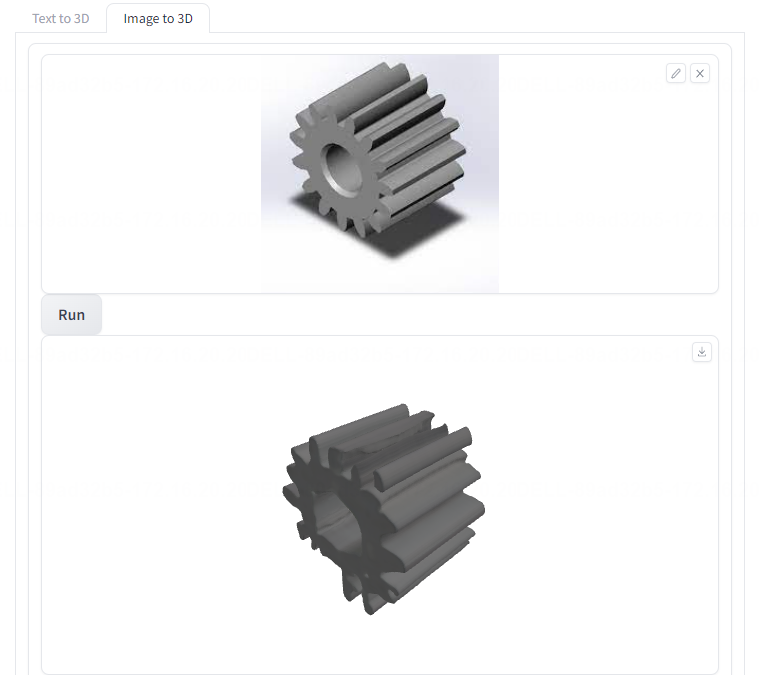
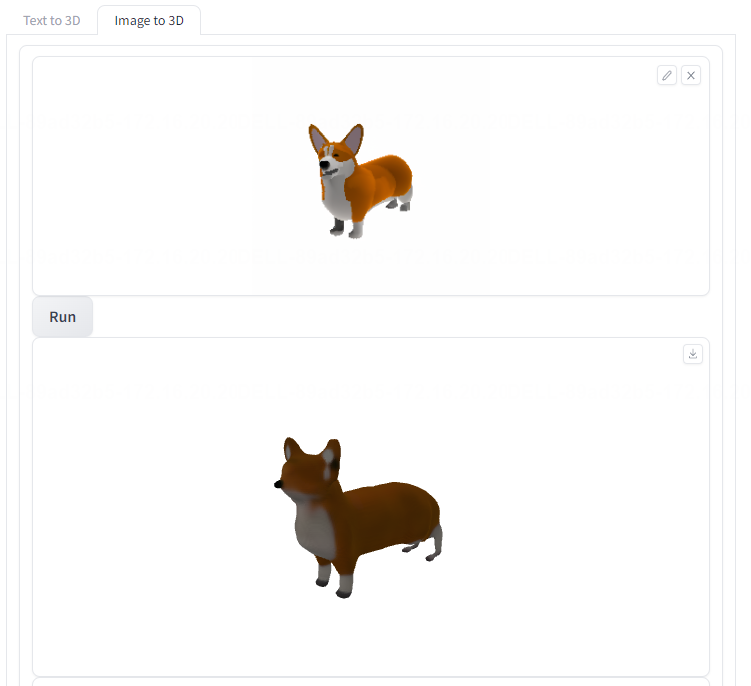
- 二维小狗图片转三维模型
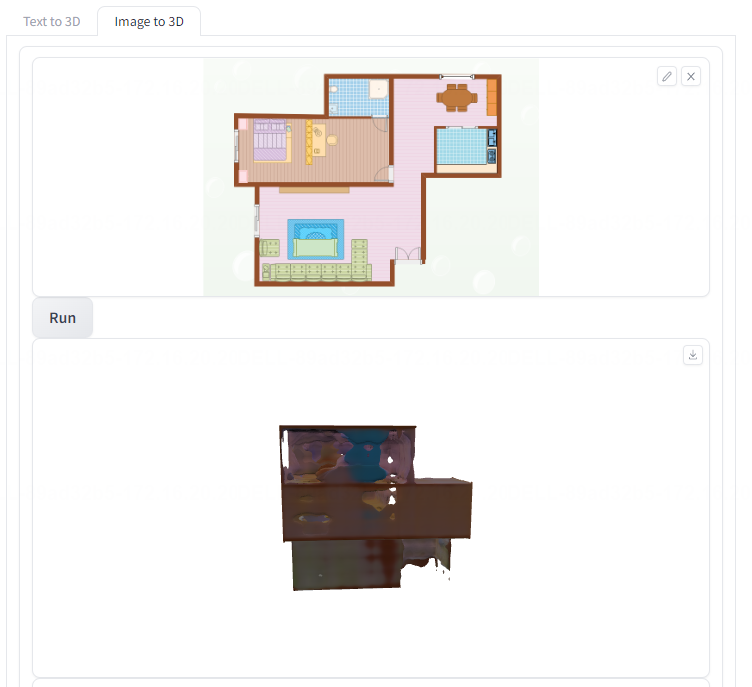
- 二维建筑平面图片转三维模型
不仅如此,除了在Hugging Face社区可以进行直接的三维模型。
生成的三维模型的图片也是支持本地查看的,将三维模型的图片进行下载。
使用windows系统自带的3D画图就可以查看了,效果更好!

以上是shape-E的模型实现的最终效果,我们下面分析一下shape-E模型的工作原理。
三、模型工作原理
Shap-E 还是用到了潜空间扩散模型(Latent Diffusion)。
熟悉 Stable Diffusion 的小伙伴应该对于这个概念并不陌生,其实就是将一些高维信息,降维表示到一个特定的特征空间,然后再根据这些特征,做生成。

Shap-E 整体结构也是类似的 Encoder - Decoder 结构。
不过输入和输出变了,比如 Shap-E 的 Encoder 结构是这样的:
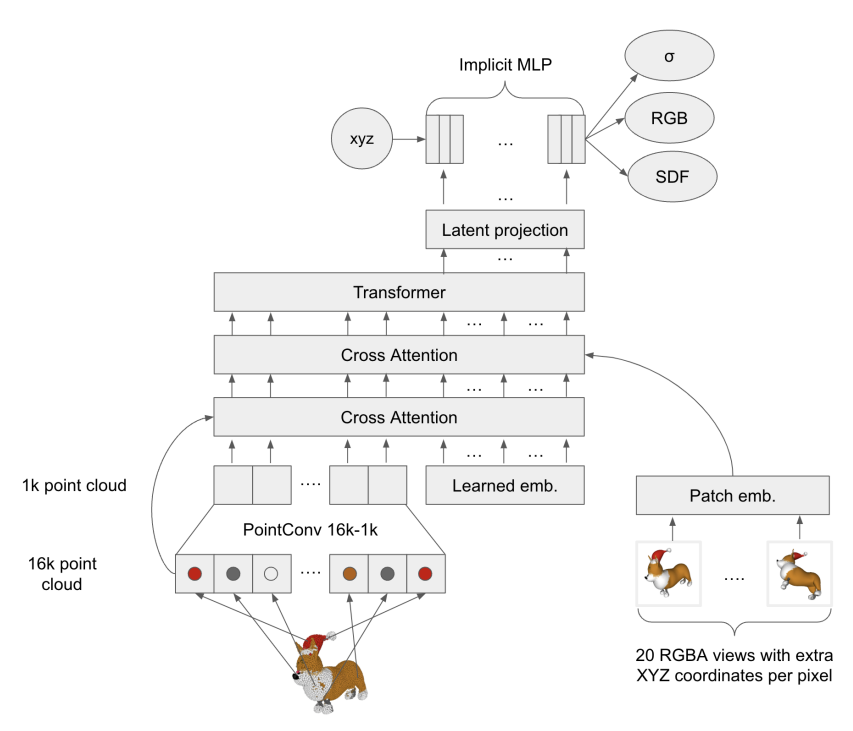
输入是点云模型,经过降维、交叉注意力层、Transformer等结构,最终获得一个 implicit MLP。
至于 Decoder 则采用 STF Rendering 进行渲染,同时加入了 CLIP 的 text embedding。
Shap-E 支持多模态,输入既可以是文字,也可以图片。
四、模型算法应用
项目地址:
https://github.com/openai/shap-e
算法部署并不复杂,Shap-E 只依赖于 CLIP。
(1)可以单独创建一个名为 shape 的虚拟环境
conda create -n shape python=3
(2)激活conda环境
conda activate shape
(3)然后安装好 CLIP 的一些依赖
conda install --yes -c pytorch pytorch=1.7.1 torchvision cudatoolkit=11.0
pip install ftfy regex tqdm
(4)进入 Shap-E 项目的根目录,pip 安装剩余依赖包
pip install -e .
shap_e/examples/sample_text_to_3d.ipynb 是文本描述生成三维模型的脚本代码。
shap_e/examples/sample_image_to_3d.ipynb 是二维平面图片生成三维模型的脚本代码。
五、千寻总结
写完这篇技术文,千寻的第一个想法就是,害,文章刚刚开始时候,有点贩卖焦虑了,就这!
就这生成效果,想要完全取代人家3D建模师,我觉得还是有很长的路要走的。
目前的生成算法存在的问题:
1.模型的推理时间较长,平均生成一次三维模型图片,耗时大约30S左右。
2.生成的三维模型,细节度不够,只能算是有一个大体的外部轮廓,动物的面部细节特征几乎是全部没有。
所以根本不用焦虑,但是还是要继续努力啊!
我是千与千寻,一个只讲干货的码农,我们下期见~