string类
在C语言当中 ,也有字符串,它是以 " \0 " 结尾 的 一些字符的集合,在C的标准库当中还有一些 用于操作 str 类型的库函数,但是,这些函数的功能不是很全面,而且这些操作函数和 str 类型是分开的,不符合 OPP 思想,如果用户对 这些操作函数使用不当的话,可能会有访问越界,或者是 实现不了 想要效果的这些问题。
所以在C++ 当中,对这些 进行了优化,包装,改进,做出了 string类。
string类就是 管理的 字符数组,里面包含了 增删查改 和 一些 功能算法。
string类的文档:
https://cplusplus.com/reference/string/string/?kw=stringhttps://cplusplus.com/reference/string/string/?kw=string
我们可以在官方文档当中使用 ctrl + F 来搜索当前浏览器当中的内容。
string类属于C++ 标准库当中的 内容,所以是包含在 std 命名空间当中的,用的时候,要么展开命名空间,要么使用 std::string 的方式访问这个string的内容:
string s1;
std::string s2;
string name("张三");
name = "张飞";string类的构造函数
string(); | 创建一个空的string对象,也就是创建一个空的字符串 |
string (const char* s); | 以 C 当中 str 的方式 创建这个 string对象,最后以 " \0 " 结尾。 |
string (size_t n, char c); | string类当中有 n 个 c 这个字符。 |
string (const string& str); | 拷贝构造函数 |
string (const string& str, size_t pos, size_t len = npos); | 拷贝构造函数,从某一位置开始(pos),拷贝 len 个字符。 |
string (const char* s, size_t n); | 构造一个string 类 ,在 s 常量字符串 的前n 个字符中拷贝 |
int main()
{
string s1();
string s2("张三");
string s3("hello world");
string s4(10 , '$');
string s5(s2);
string s6(s3, 2, 5);
return 0;
}上述的这个拷贝构造函数当中 string (const string& str, size_t pos, size_t len = npos); npos的值是-1,但是npos 是一个 静态的常量,无符号数,它给的初始值是 -1 ,也是 size_t ,是无符号数,那么-1 就是最大的数。
那么在官方文档中也有说明:

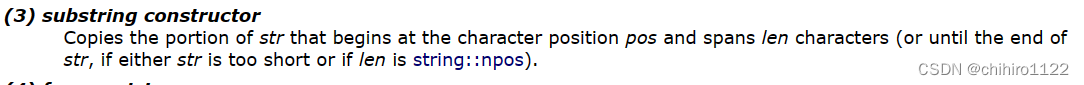
表示,如果 给的 len 大于 字符串长度,或者是 此时的 len = npos ;那么都取到字符串的结尾。
string类对象的访问及遍历操作
当然,在string类当中,还实现了很多的重载符函数,比如 = < <= >= == 等等操作符,基本实现的功能都差不多,但是在Stringe类当中有一个 很厉害的重载符函数(operator[] )。
operator []
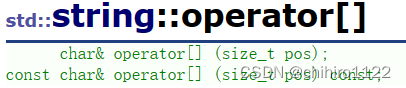
operator[] 在C当中 " [] " 这个操作符相当于是 解引用操作,只有在连续的空间当中才能使用这个 " [] " 这个操作符,比如在栈上开辟的数组和 堆上动态开辟的空间。
那么在自定义类型string 类当中,我们也可以使用 " [] " 来访问这个字符串数组。
使用 下标 + [] 的方式来访问string自定义类型。
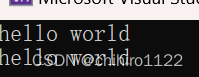
string s3("hello world");
// 直接打s3 当中的内容
cout << s3 << endl;
// 下标 + []
for (int i = 0; i < s3.size(); i++)
{
cout << s3[i];
}
cout << endl;
return 0;输出:
在string 类当中,底层是使用一个 在堆上开辟的数组来存储 字符串的,那么既然是字符串,就是以 " \0 " 结尾的,我们上述的 循环能不能访问到 "\0"呢?
我们先来看看 size()函数计算出的大小是多少:
cout << s3.size() << endl;输出:

我们发现输出的是 11 ,而上述的 "hello world" 的字符串个数就是11 个 ,不加 "\0" 。
因为 "\0" 不是有效字符,他是表示字符串结束的特殊字符。
当我们故意打印出 "\0" 实际上是可以访问到的,但是有些编译器不会显示这个 "\0" ,但是实际上是会访问到的。
那么我们同样可以像使用 " [] " 修改数组一样,对 string 当中的字符串进行修改,因为这个 " operator [] " 函数返回的是 当前 传入的 pos 位置的引用:

当我们传入的是 普通对象的时候,就是 POS 位置的引用,如果传入的这个对象都是 const 的,那么这个函数的返回值就是 const char& ,常量引用。

string s3("hello world");
char s1[] = "hello world";
s1[1]++; // 等价于 *(s1 + 1);
s3[1]++; // 等价于 s3.operator[](1); 上述代码的反汇编如下: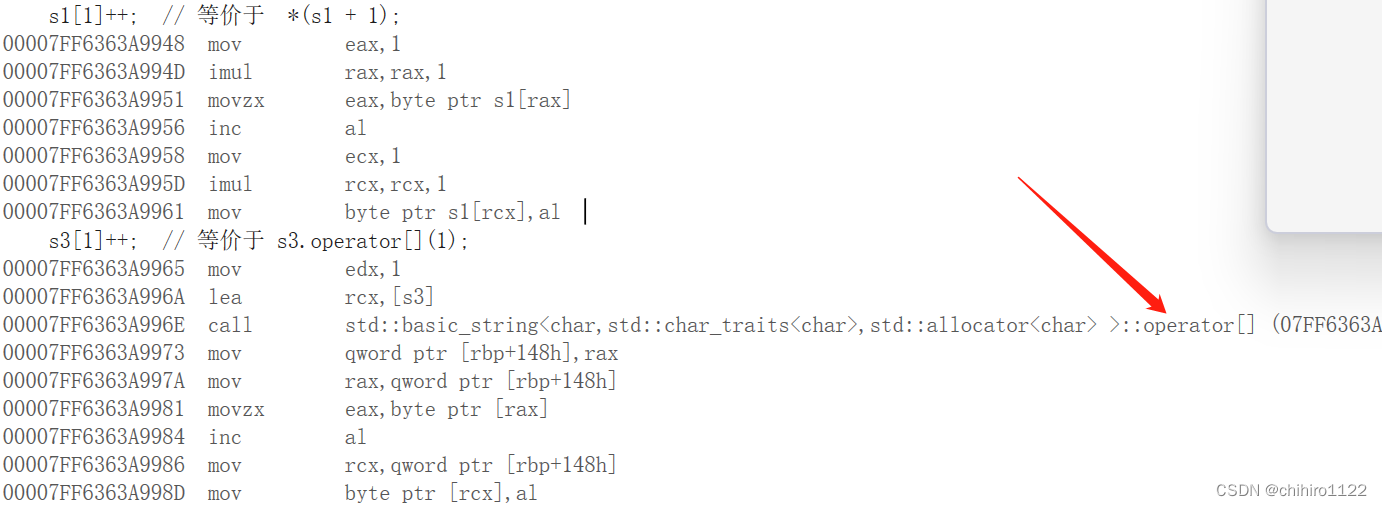
我们发现,在s3 这个对象当中使用 s3[1]++; 这样的实现,在底层其实就是 调用的 operator[] 这个重载运算符函数。
关于 string 当中的容量的函数
| 函数名称 | 功能说明 |
| size(重点) | 返回字符串有效字符长度 |
| length | 返回字符串有效字符长度 |
| capacity | 返回空间总大小 |
| empty (重点) | 检测字符串释放为空串,是返回true,否则返回false |
| clear (重点) | 清空有效字符 |
| reserve (重点) | 为字符串预留空间** |
| resize (重点) | 将有效字符的个数该成n个,多出的空间用字符c填充 |
max_size() 计算这个字符串最大可以达到多大的空间:

但是,max_size ( )计算的值在不同的编译器下的结果是不同的,比如上述结果是在 VS2022 环境下所 输出的结果。
但是如果实在 VS2013 环境下输出如下:

所以 max_size ()函数在实际当中没有多大是使用意义。
capacity()返回这个空间的容量:
string s3("hello world");
cout << s3.capacity() << endl; // 15当然,在数据结构当中我们知道,比如在栈当中,当这个栈满的时候,我们插入元素,那么就会就扩容,而一般我们是扩到原来大小的两倍,但是这个扩容大小在不同的版本的C++之下,有所不同。
在 VS2019 下:

注意:
- 上述的 size( )和 length()这两个函数在底层的实现逻辑是一样的,出现 size( )的目的就是与其他的容器的实现保持一致。
- clear()这个函数只是将 string类中底层的 数组当中的有效字符清空,并不会改变这个数组的 空间大小。
- .resize(size_t n) 与 resize(size_t n, char c)都是将字符串中有效字符个数改变到n个,不同的是当字符个数增多时:resize(n)用0来填充多出的元素空间,resize(size_t n, char c)用字符c来填充多出的元素空间。注意:resize在改变元素个数时,如果是将元素个数增多,可能会改变底层容量的大
- 小,如果是将元素个数减少,底层空间总大小不变。
- eserve(size_t res_arg=0):为string预留空间,不改变有效元素个数,当reserve的参数小于string的底层空间总大小时,reserver不会改变容量大小
迭代器
我们可以使用begin和 end 来获取这个string 类当中的字符串的 首位字符串的迭代器,和 最后一个有效字符的后一位置的字符的迭代器。
| begin+ end | begin获取一个有效字符的迭代器 + end获取最后一个有效字符下一个位置的迭 代器 |
| rbegin + rend | rbegin获取最后一个有效字符的迭代器 + rend获取第一个有效字符前一个位置的迭 代器 |
string s3("hello world");
string::iterator it = s3.begin();
while (it != s3.end())
{
cout << *it << " ";
it++;
}
cout << endl;输出:
像上述使用 迭代器访问的方式,我们可以把这里的 it 迭代器理解为一个指针,但是迭代器不完全是指针。
而像上述当中的 begin( )和 end(),两个函数返回的是对应位置的迭代器,向上述例子当中可以理解为指针,但是这个函数不是都返回的指针。
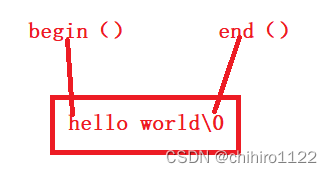
像上述当中的 *it 就是这个it位置的字符。
++it , 就是让 it 这个迭代器往下走,当 it == "\0" 就结束循环。
iterator是一个像指针一样的类型,可能是指针,可能是封装的自定义类型。
*it 可以理解是指针的解引用,那么就可以使用 解引用来修改字符:
cout << s3 << endl;
string::iterator it = s3.begin();
while (it != s3.end())
{
(*it)--;
++it;
}
cout << endl;
it = s3.begin();
while (it != s3.end())
{
cout << *it << " ";
it++;
}
cout << endl;输出:

不仅仅是在 string类 当中支持迭代器,任何容器都是支持迭代器的,而且用法都类似。
vector<int>v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
vector<int>::iterator vit = v.begin();
while (vit != v.end())
{
cout << *vit << endl;
++vit;
}迭代器的好处就在于,我们之前访问数组这些连续空间当中访问的时候,就可以使用 "[]" 的方式来访问这个其中的数据,但是 "[]" 这样方式访问的前提是 ,这空间是连续的,如果是向链表,树,这样的结构就不能使用 "[]" 的方式访问,但是像上述的这些类型,有些可以实现迭代器,那么就可以使用迭代器的方式来访问其中的数据了。
迭代器提供了一种统一的方式去访问 简单的数组,复杂一点 链表,更复杂的 树,哈希表这些结构。
而迭代器的用法就是 和算法来一起使用的 ,我们在库当中查看一些算法的时候,发现很多的函数都实现的所有的类型,比如如下的 reverse()逆置函数,他支持的是所有的类型,在这里就是使用的是迭代器来进行传参,而用模板来实现各种迭代器的匹配问题:
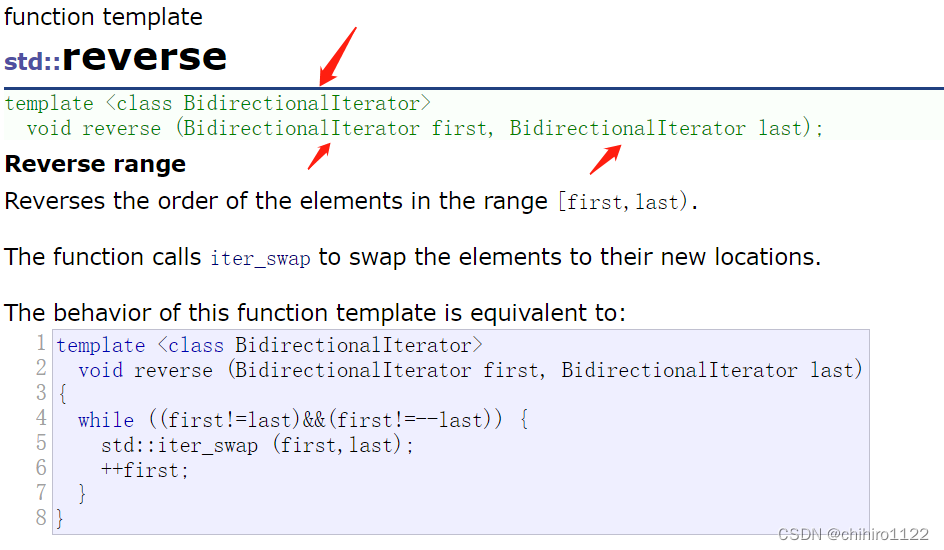
利用函数模板,来实现不同类型的迭代器的传参,实现函数的重载,这样不管是什么类型的迭代器传进来,都可以使用这个算法。
那么如上述的过程,算法就可以通过容器去修改容器当中的数据,使用迭代器和模板之后,我们就可以不用在去关系实现的数据是什么类型的了,只需要传入这个类型的迭代器即可。
对于上述的当中的 begin()和 end()函数是顺序访问的取其中的迭代器的函数,那么如果我们想要逆向访问的话,也是可以的。
使用 rbegin()和 rend()函数都是可以进行操作的,所对应获取的位置的迭代器如下所示:

上两个函数对应的迭代器就是 reverse_iterator 迭代器,所以我们在使用迭代器的时候,应该使用的迭代器应该是 reverse_iterator。
例子:
string s3("hello world");
string::reverse_iterator vit = s3.rbegin();
while (vit != s3.rend())
{
cout << *vit << " ";
vit++;
}
cout << endl; 输出:
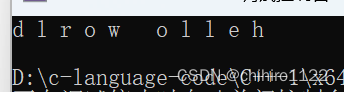
对于上述当中的迭代器,在写起来的时候已经有些麻烦了,我们可以使用auto来自动推导这个迭代器的类型:
auto vit = s3.rbegin();一些问题:
我们在实现函数的传参的时候,比如现在我想把 一个 string类的对象传入到函数当中去,那么这里就会取调用这个string类的拷贝构造函数,去创建一个空间,这里是一个深拷贝,这样不仅仅会浪费空间,而且会有损效率,我们在这里的优化解决方案是传入这个 string类对象的 引用,这样就不会发生深拷贝了。如果我们不想修改这个对象,那么我们还会用 const 修饰这个形参。
但是如果我们在传入引用之后,函数中使用了这个对象的迭代器,不会报错;但是如果用const 修饰之后就会报错!!!
如这个例子:
void func(const string& s)
{
string::reverse_iterator vit = s.rbegin();
while (vit != s.rend())
{
cout << *vit << " ";
vit++;
}
cout << endl;
}
int main()
{
string s3("hello world");
func(s3);
return 0;
} 报错:
我们发现,报的错是模板的错,而且报的错很复杂,因为模板的实现很复杂。
这里其实发生的权限的放大,而且对于const 对象的传参,有对应的const 迭代器来使用:

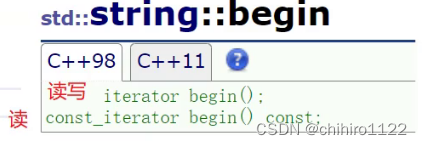
在官方文档当中,有 const char& operator[] (size_t pos_ const; 这个const的成员函数,当我们函数中传入的是 const 的对象的时候,在其中使用的迭代器应该是 const 的 迭代器:
void func(const string& s)
{
string::const_reverse_iterator vit = s.rbegin();
while (vit != s.rend())
{
cout << *vit << " ";
vit++;
}
cout << endl;
}输出:
对于 普通的迭代器,可以读写,但是对于const 的迭代器,就只能进行读的操作。其中的写功能也就是能不能对string类当中给定字符串中的字符进行修改。
也就是说 如果 it 是我们定义的迭代器的话,如果不能进行 写的操作,那么是 *it 不能改变,而 it 是可以修改的。
针对上述的 const 的问题,我们使用 auto就非常的好用,他同样会自动推导这个 const 的迭代器!!
void func(const string& s)
{
/*string::const_reverse_iterator vit = s.rbegin();*/
auto vit = s.rbegin();
while (vit != s.rend())
{
cout << *vit << " ";
vit++;
}
cout << endl;
}输出:
范围for
在string类当中的访问,其实最方便的就是使用 返回for 的方式来访问这个 string类当中的字符串。
范围for是在C++11 支持的更简洁的新的遍历方式。
语法:
for(变量的类型 变量名(s1) : 需要迭代的变量名(s2))
{
// 其中就可以使用新创建的 s1 这个变量来迭代 s2
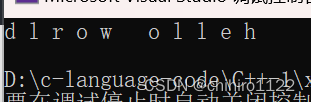
} string s3("hello world");
for (auto str : s3)
{
cout << str;
}输出:
在此处我们使用了 auto 来自动的推出这个这个str 的类型,然后他会自动的 迭代,自动判断结束。
如上述例子,就是依次从 s3 当中取数据,然后赋值给 str ,通过这样的方式来进行迭代。
所以像上述的 方式,如果我们直接修改 str 的内容,s3 当中的字符串是不会改变的:
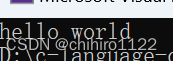
string s3("hello world");
for (auto str : s3)
{
str++;
}
cout << s3 << endl;输出:
如果我们使用类型是 这个目标变量的引用就可以修改了:
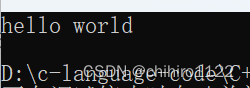
string s3("hello world");
for (auto& str : s3)
{
str++;
}
cout << s3 << endl;输出:
这时候,每一次传入的就是依次传入 这个 字符串当中字符的引用,所以我们就可以进行修改。
范围for 其实 在底层的实现就是用的迭代器来实现的,他其实就是使用类似于我们上述在迭代器当中实现的遍历一样来实现,而上述的依次拷贝其实就是把 *it 拷贝给了 str,从而使实现自动迭代。
我们查看反汇编也能看到一些我们之前在 迭代器当中的一些影子:
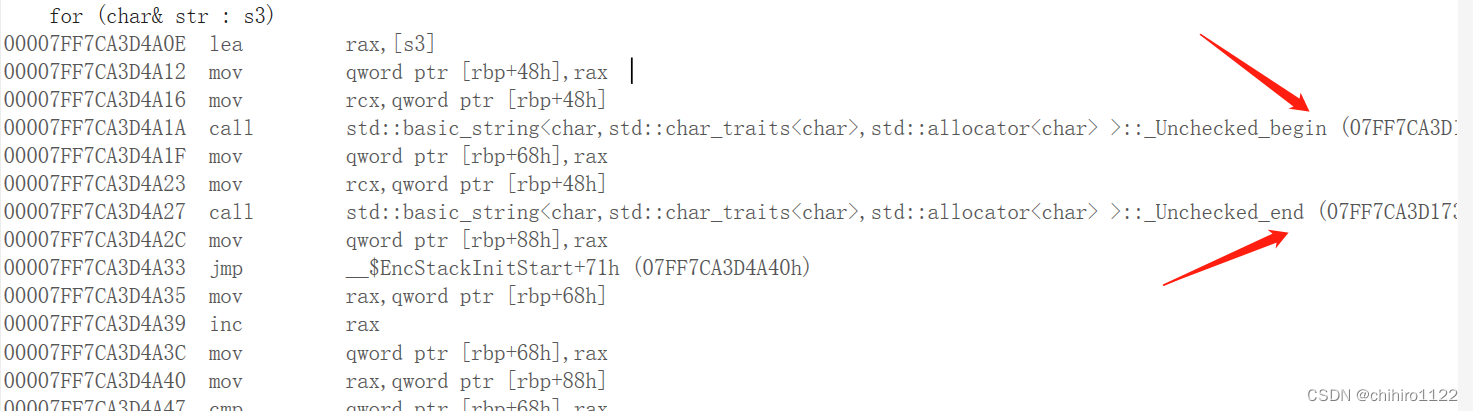
在 返回for 当中也 调用了 begin()和 end()函数来判断 开始和结束。
也就是说,我们使用得很香的 范围for 其实就是使用的 迭代器 来实现的,没有迭代器就没有 范围for,那么有些类型是不支持 迭代器的,那么它就不支持 范围for,例如:
在 Stack 当中就不支持 范围 for:
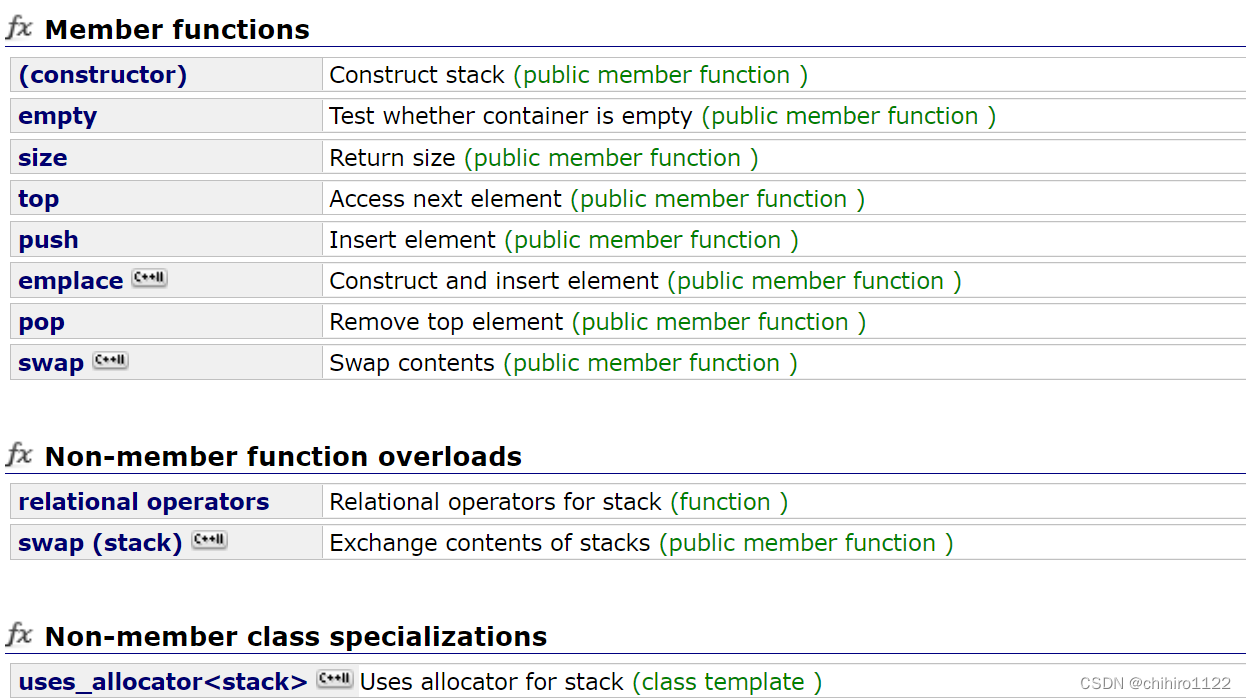
范围for 也是有局限性的,因为范围for 只能正向的遍历,不能像之前的迭代器一样,还有返乡遍历的 迭代器,范围for只是一个傻瓜式用 正向遍历的 迭代器做成的。