目录
一:域名
1.域名概述
2.域名空间结构
3. 域名注册
二: 网页访问(HTTP/HTTPS)
1.网页的基本概念
2.网站
3.主页
4.域名
5.HTTP
6.URL
7.网页基本标签
(1)网页摘要信息的作用
(2)标题标签类型
三:HTML
1.HTML 概述
2.HTML 基本标签
(1)HTML 语法规则
(2)HTML 文件结构
(3)网页的“源码”【在网页空白页按F12会展示源码】
3.HTML 文件结构
(1)头标签中常用标签
(2)内容标签中常用标签
四:web
1.Web概述
2.Web1.0 vs Web2.0
(1)Web1.0
(2)web 2.0
3. 静态页面
(1)静态页面定义
(2)静态页面特点
4.动态页面
(1) 动态页面定义
(2)动态页面特点
(3)目前常用的动态网页编程语言
五:HTTP协议
1.HTTP协议简介
2.HTTP 版本
(1)HTTP/0.9
(2)HTTP/1.0
(3)HTTP/1.1
(4)HTTP/2.0
(5)HTTP3.0
3.HTTP 方法
4.GET 和 POST
(1)GET
(2)POST
(3) GET 与POST 区别
5.HTTP状态码
6.生产环境常见的HTTP状态码
7. HTTP 请求流程分析
(1) 请求报文
(2)常用的请求头
(3)响应报文
(4)常见响应头
总结:常见的状态码及原因
一:域名
1.域名概述
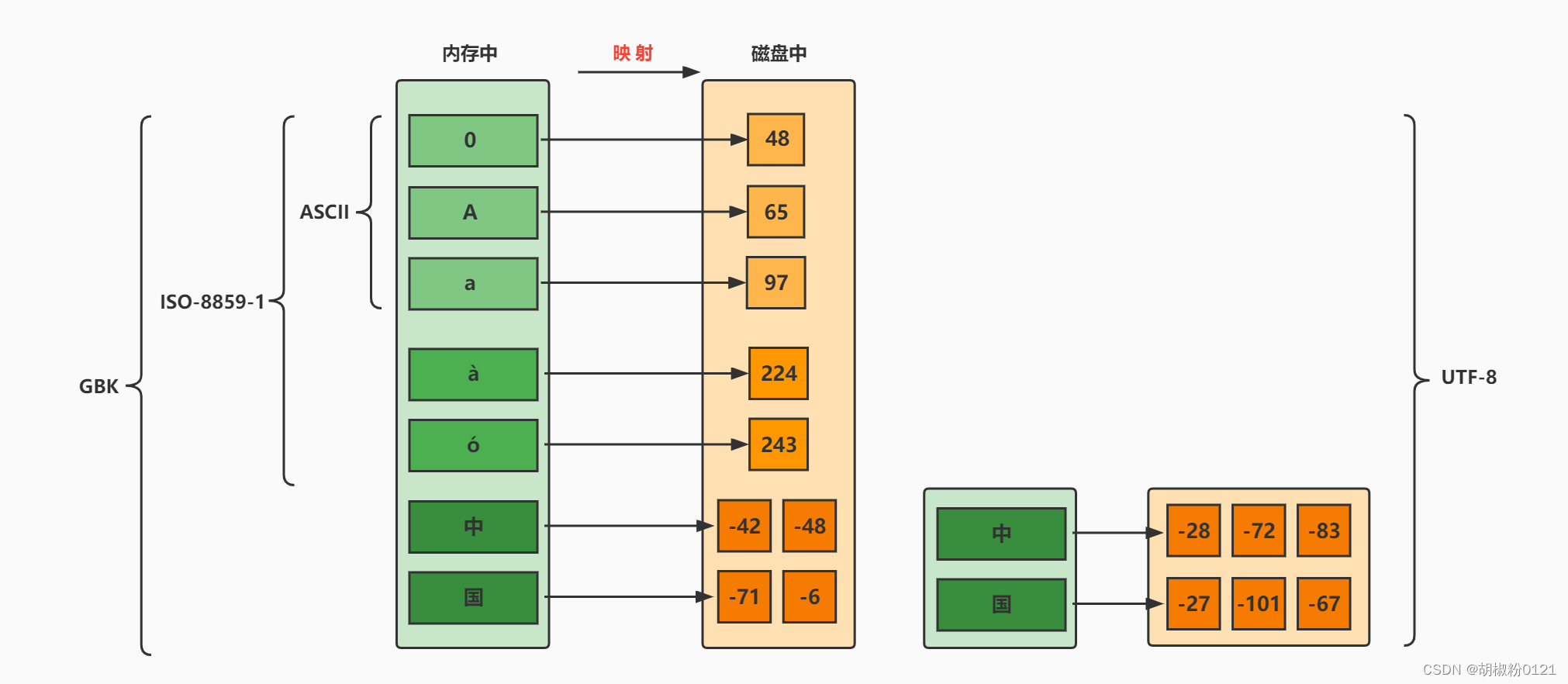
标识一组主机并提供它们的有关信息的树形结构(主要确定了根在哪,就可以确定每个分支)
www.baidu.com
域名服务器(分布式,每台主机维护一个部分):
① 保持和维护域名空间的程序
② 响应解析器的请求
解析端(客户端)
向DNS服务器发出请求的设备
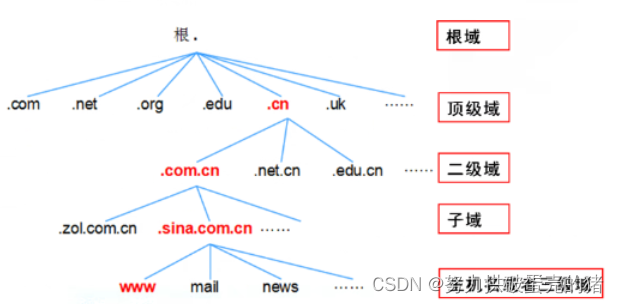
2.域名空间结构
① 根域 位于域名空间最顶层,一般用一个 “.” 表示
基础单位,除了根域 其他都只有一个上级域,有0或多个子域,同层域不可重复的子域或域名
② 顶级域
一般代表一种类型的组织机构或国家地区(主要有此两种类型构成),如 net(网络公司)、com(商业)、org(民间团体组织)、edu(教育)、gov(政府)、mil(军事)、cn(中国)、jp(日本)、hk(中国香港)
③ 二级域
用来标明顶级域内的一个特定的组织,国家顶级域下面的二级域名由国家网络部门统一管理,如 .cn 顶级域名下面设置的二级域名:.com.cn、.net.cn、.edu.cn …
④ 子域
用来标明顶级域内的一个特定的组织,国家顶级域下面的二级域名由国家网络部门统一管理,如 .cn 顶级域名下面设置的二级域名:.com.cn、.net.cn、.edu.cn …
主机
主机位于域名空间最下层,就是一台具体的计算机,如 www、mail、都是具体的计算机名字,可用www.sina.com.cn.、mail.sina.com.cn. 来表示,这种表示方式称为 FQDN (完全合格域名),也是这台主机在域名中的全名
3. 域名注册
域名注册是Internet中用于解决地址对应问题的一种方法 遵循先申请先注册原则 域名注册
步骤:准备申请资料————》寻找域名注册网站————》查询域名————》正式申请————》申请成功

二: 网页访问(HTTP/HTTPS)
1.网页的基本概念
纯文本格式文件,编写语言为HTML,在用户浏览器中被“翻译”成网页形式显示出来。
① 网页
a.纯文本格式文件
b.编写语言为HTML
c.在用户的浏览器中被“翻译”成网页形式显示出来
② 网站
由一个一个页面构成的,是多个网页的结合体
主页
打开网站后出现的第一个网页称为网站主页(或首页)
③ 域名
浏览网页时输入的网址
④ HTTP/HTTPS
用来传输网页的通信协议(是否加密),是一种通讯/交互的标准/规范
⑤ URL
是一种万维网寻址系统
⑥ HTML
用来编写网页的超文本标记语言
⑦ 超链接
超链接是将网站中不同网页链接起来的功能
⑧ 发布
将制作好的网页上传到服务器供用户访问的过程
2.网站
由一个一个页面构成的,是多个网页的结合体
3.主页
打开网站后出现的第一个网页称为网站主页(或首页)
4.域名
浏览网页时输入的网址
5.HTTP
用来传输网页的通信协议
6.URL
是一种万维网寻址系统
7.网页基本标签
(1)网页摘要信息的作用
有利于浏览器解析
有利于搜索引擎搜索
<title>标签 #标题
#举例
<head>
<title>搜狐-中国最大的门户网站
</title>
</head>
<meta>标签 #根据关键信息搜索
#举例
<head>
<meta name="keywords"
content="山东蓝翔,挖掘机培训"/>
</head>(2)标题标签类型
行控制相关标签
范围标签
图像标签
超链接标签
特殊符号
<h1>静夜思</h1>
<p>床前明月光</p>
疑是地上霜<br/>
<span>举头望明月</span>
<img src=""linux.jpg/>
<a href="linux.htm">我是中国人</a>
"©> #空行 双引号 版权符号 大于
三:HTML
1.HTML 概述
HTML叫做超文本标记语言,是一种规范,也是一种标准,它通过标记符号来标记要显示的网页中的各个部分。网页文件本身是一种文本文件,通过在文本文件中添加标记符,可以告诉浏览器如何显示其中的内容。
HTML文件可以使用任何能够生成txt文件的文本编辑器来编辑,生成超文本标记语言文件,只用修改文件名后缀为”.html”或“.htm”即可。
2.HTML 基本标签
(1)HTML 语法规则
HTML标签采用双标记符的形式,前后标记符对应,分别表示标记开始和结束,标记符中间的内容被标签描述。前标记符由“<XXX>”表示,结尾标记符多了一个“/”,由“</XXX>”表示。
(2)HTML 文件结构
HTML文件最外层由<html></html>,说明该文件是用HTML语言描述的。在它里面是并列的头标签(<head>)和内容标签(<body>)
(3)网页的“源码”【在网页空白页按F12会展示源码】
3.HTML 文件结构
HTML网页
头部部分
标题部分
主体部分
网页内容,包括文本、图像等
示例:
<html>
<head>
<title>我的第一个网页 </title>
</head>
<body >
Hello World!
</body>
</html>
(1)头标签中常用标签
头标签中常用标签:
标签 描述
<title> 定义了文档的标题
<base> 定义了页面链接标签的默认链接地址
<link> 定义了一个文档和外部资源之间的关系
<meta> 定义了 HTML 文档中的元数据
<script> 定义了客户端的脚本文件
<style> 定义了 HTML 文档的样式文件
内容标签中常用标签
(2)内容标签中常用标签
标签 描述
<table> 定义一个表格
<tr> 定义了表格中的一行
<td> 定义了表格中某一行的一列
<img> 定义了一个图像
<a> 定义了一个超链接
<p> 定义了一行
<br> 定义了换行
<font> 定义了字体
<h1> 定义字体大小四:web
1.Web概述
Web(Would Wide Web)即全球广域网,也称为万维网 。一种分布式图形信息系统 建立在Internet上的一种网络服务。
2.Web1.0 vs Web2.0
(1)Web1.0
1.以编辑为特征,网站提供给用户的内容是编辑处理后的,然后用户阅读网站提供的内容
2.这个过程是网站到用户的单向行为
(2)web 2.0
1.更注重用户的交互作用,用户既是网站内容的消费者(浏览者),也是网站内容的制造者
2.加强了网站与用户之间的互动,网站内容基于用户提供,网站的诸多功能也由用户参与建设,实现了网站与用户双向的交流与参与
3.Web2.0特征:用户分享、以兴趣为聚合点的社群、开放的平台,活跃的用户。
3. 静态页面
(1)静态页面定义
① 静态网页是标准的HTML文件
② 扩展名是.htm、.html
例如文本、图像、声音、Flash动画、客户端脚本和ActiveX控件及Java小程序等
③ 是网站建设的基础,早期网站一般都由静态网页制作
④ 没有后台数据库、不含程序和不可交互的网页
⑤ 相对更新起来比较麻烦,适用于一般更新较少的展示型网站
(2)静态页面特点
① 每个静态网页都有一个固定的URL,且URL以.htm、.html、.shtml等常见形式为后缀,而不含有“?”
② 网页内容一经发布到网站服务器上,无论是否有用户访问,每个静态网页都是保存在网站服务器上的
③ 静态网页的内容相对稳定,容易被搜索引擎检索
④静态网页没有数据库的支持,在网站制作和维护方面工作量较大,因此当网站信息量很大时完全依靠静态网页制作方式比较困难
⑤静态网页的交互性较差,在功能方面有较大的限制
⑥ 页面浏览速度迅速,过程无需连接数据库,开启页面速度快于动态页面
4.动态页面
(1) 动态页面定义
① 网页 URL不固定,能通过后台与用户交互
② 在动态网页网址中有一个标志性的符号——“?”
③常用的语言有PHP、JSP、Python、Ruby等
(2)动态页面特点
① 交互性 网页会根据用户的要求和选择而动态改变和响应,将浏览器作为客户端界面,这将是今后WEB发展的大势所趋
② 自动更新无须手动地更新HTML文档,便会自动生成新的页面,可以大大节省工作量
③ 因时因人而变 当不同的时间,不同的人访问同一网址时会产生不同的页面
(3)目前常用的动态网页编程语言
●PHP
即 Hypertext Preprocessor(超文本预处理器),它是当今 Internet 上最为火热的脚本语言,其语法借鉴了 C、Java、PERL 等语言,但只需要很少的编程知识你就能使用 PHP 建立一个真正交互的 Web 站点。
●JSP
即 Java Server Pages(Java 服务器页面),它是由 Sun Microsystem 公司于 1999 年 6 月推出的新技术,是基于 Java Servlet 以及整个 Java 体系的 Web 开发技术。
●Python
是一种面向对象、跨平台的动态类计算机程序设计语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越来越多被用于独立的大型项目开发。
●Ruby
是一种简单快捷的面向对象(面向对象程序设计)脚本语言,在 20 世纪 90年代由日本人松本行弘(Yukihiro Matsumoto) 开发,遵守GPL 协议和Ruby License。它的灵感与特性来自于 Perl、Smalltalk、Eiffel、Ada 以及 Lisp 语言。
五:HTTP协议
1.HTTP协议简介
- HTTP(超文本传输协议HyperText Transfer Protocol)协议是互联网上应用最为广泛的一种网络协议,它是基于TCP协议的应用层传输协议,简单来说就是客户端和服务端进行数据传输的一种规则。
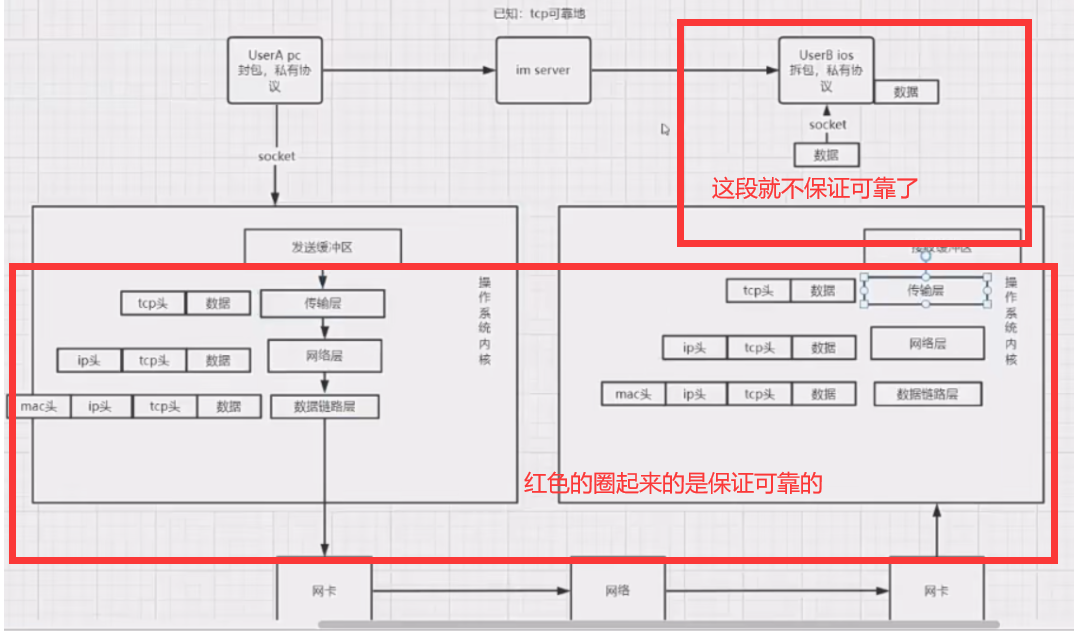
- HTTP/HTTPS是应用层上的协议,建立在传输层TCP之上,客户端通过与服务端进行TCP连接(三次握手),之后发送HTTP请求与接收HTTP响应都是通过访问Socket接口来调用TCP协议实现。
- HTTP 是一种无状态 (stateless) 协议, HTTP协议本身不会对发送过的请求和相应的通信状态进行持久化处理(存储,保存)。这样做的目的是为了保持HTTP协议的简单性,从而能够快速处理大量的事务, 提高效率。
- 然而,在许多应用场景中,我们需要保持用户登录的状态或记录用户购物车中的商品。由于HTTP是无状态协议,所以必须引入一些技术来记录管理状态,例如Cookie。
- cookie和session都为了实现的是http的短期的持久化(内存/缓存方式,查询快、效率比较高)cookie是缓存在用户端(client)浏览器中的(默认缓存一天),当下次客户端通过同一个浏览器访问客户端的时候,会优先读取cookie中的缓存信息,向服务端进行请求,同时服务端收到客户端请求的时候,读取到cookie文件,知道客户端之前找的是服务器A处理的任务,为了省事儿,省资源,干脆直接讲请求直接再交给服务器A处理
注:cookie 省服务器性能,session 更安全。
2.HTTP 版本
(1)HTTP/0.9
已过时。只接受 GET 一种请求方法,没有在通讯中指定版本号,且不支持请求头。由于该版本不支持 POST 方法,所以客户端无法向服务器传递太多信息。
(2)HTTP/1.0
这是第一个在通讯中指定版本号的 HTTP 协议版本,至今仍被广泛采用,特别是在代理服务器中。
(3)HTTP/1.1
引入了持久连接,即TCP连接默认不关闭,可以被多个请求复用,能很好地配合代理服务器工作。还支持管道方式机制,即在同一个TCP连接里面,客户端可以同时发送多个请求,以便降低线路负载,提高传输速度。
(4)HTTP/2.0
完全多路复用,在一个连接里,客户端和浏览器都可以同时发送多个请求或回应,而且不用按照顺序一一对应。引入了头信息压缩机制,使用gzip或compress压缩后再发送。支持服务端推送,允许服务器未经请求,主动向客户端发送资源。
(5)HTTP3.0
HTTP3.0是协议的第一个完全依赖于QUIC协议而非TCP的版本。 HTTP3.0基于QUIC设计,旨在提高Web性能和安全性。它使用流复用,允许在单个连接上发送多个请求和响应,并默认提供加密。HTTP3.0还具有0-RTT(零往返时间)恢复等功能,可提高重新访问网站时的连接速度,并包括一种请求优先级机制,可以进一步提高Web性能。
3.HTTP 方法
HTTP 支持几种不同的请求命令,这些命令被称为 HTTP 方法(HTTP method)。每条 HTTP 请求报文都包含一个方法, 告诉服务器要执行什么动作,包括:获取一个页面,运行一个网关程序,删除一个文件等。最常用的获取资源的方法是 GET、POST、PUT。
| HTTP方法 | 描述 |
|---|---|
| GET | 对服务器资源获取的简单请求 |
| PUT | 向服务器提交数据,以修改数据 |
| DELETE | 删除服务器上的某些资源 |
| POST | 用于发送包含用户提交数据的请求 |
| HEAD | 请求页面的首部,获取资源的元信息 |
(1)GET请求会向数据库发索取数据的请求,从而来获取信息,该请求就像数据库的select操作一样,只是用来查询一下数据,不会修改、增加数据,不会影响资源的内容,即该请求不会产生副作用。无论进行多少次操作,结果都是一样的。
(2)与GET不同的是,PUT请求是向服务器端发送数据的,从而改变信息,该请求就像数据库的update操作一样,用来修改数据的内容,但是不会增加数据的种类等,也就是说无论进行多少次PUT操作,其结果并没有不同。
(3)POST请求同PUT请求类似,都是向服务器端发送数据的,但是该请求会改变数据的种类等资源,就像数据库的insert操作一样,会创建新的内容。几乎目前所有的提交操作都是用POST请求的。
(4)DELETE请求顾名思义,就是用来删除某一个资源的,该请求就像数据库的delete操作
4.GET 和 POST
(1)GET
Accept:客户端可以接受的数据类型
Accept-Language:客户端可以接受的语言类型
User-Agent:浏览器的信息
Accpect-Encoding:客户端可以接受的编码格式
Host:表示请求的ip和端口号
Connection:告诉服务器请求连接如何处理 Keep-Alive:通知服务器回传数据不要马上关闭,保持一小段的连接
Closed:马上关闭
(2)POST
① 请求行
请求的方式
请求的资源路径
请求的协议的版本号
② 请求头
Accept:客户端可以接受的数据类型
Accept-Language:客户端可以接受的语言类型
Referer:表示请求发起时,浏览器地址栏中的地址
User-Agent:浏览器的信息
Content-Type:发送的数据类型
Content-Length:发送的数据长度
③ 请求体:就是发送给服务器的数据
(3) GET 与POST 区别
●GET 方法:从指定的服务器上获得数据
GET请求能被缓存
GET请求会保存在浏览器的浏览纪录里
GET请求有长度的限制
主要用于获取数据
查询的字符串会显示在URL后缀中,不安全,比如 http://www.test.com/a.php?Id=123
●POST 方法:提交数据给指定服务器处理
POST请求不能被缓存
POST请求不会保存在浏览器的浏览纪录里
POST请求没有长度限制
查询的字符串不会显示在URL中,比较安全5.HTTP状态码
当使用浏览器访问某一个URL,会根据处理情况返回相应的处理状态
通常正常的状态码为2xx,3xx(如200)
如果出现异常会返回4xx,5xx(如404)
| 状态码首位 | 已定义范围 | 分类 |
|---|---|---|
| 1xx | 100-101 | 信息提示 |
| 2xx | 200-206 | 成功 |
| 3xx | 300-305 | 重定向 |
| 4xx | 400-415 | 客户端错误 |
| 5xx | 500-505 | 服务器错误 |
6.生产环境常见的HTTP状态码
| 消息 | 描述 |
|---|---|
| 200 OK | 请求成功(其后是对GET和POST请求的应答文档) |
| 301 Moved Permanently | 请求的永久页面跳转 |
| 403 Forbidden | 禁止访问该页面 |
| 404 Not Found | 服务器无法找到被请求的页面 |
| 500 Internal Server Error | 内部服务器错误 |
| 403 Forbidden | 禁止访问该页面 |
| 404 Not Found | 服务器无法找到被请求的页面 |
| 500 Internal Server Error | 内部服务器错误 |
7. HTTP 请求流程分析
用户在浏览器输入URL访问时,发起HTTP请求报文,请求中包括请求行、请求头、请求体,服务器收到请求后返回响应报文,包括状态行、响应头、响应体。
- 客户端通过域名进行访问,先进行DNS域名解析
- 之后客户端请求与web服务器建立TCP连接(三次握手)
- 建立连接后,客户端向web服务器发送一个HTTP请求
- 服务器响应HTTP请求,客户端的浏览器得到HTML代码
- 浏览器解析HTML代码,并请求HTML代码中的资源。(浏览器拿到HTML文件后,开始解析HTML代码,遇到静态资源时,就向服务器去请求下载。)
- 断开TCP连接(四次挥手),浏览器对页面进行渲染呈现给用户

(1) 请求报文
请求行:请求行由请求方法、URL 以及协议版本三部分组成。
请求头:请求头为请求报文添加了一些附加信息,由“名/值”对组成,每行一对,名和值之间使用冒号分隔。
空行:请求头部的最后会有一个空行,表示请求头部结束,接下来为请求体,这一行非常重要,必不可少。
请求体:请求体是请求提交的参数,GET 方法已经在 URL 中指明了参数,所以提交时没有数据。POST 方法提交的参数在请求体中。
 (2)常用的请求头
(2)常用的请求头
| 请求头 | 描述 |
| Host | 接受请求的服务器地址,可以是 IP:端口号 ,也可以是域名 |
| User-Agent | 发送请求的应用程序名称 |
| Connection | 指定与连接相关的属性,如Connection:Keep-Alive |
| Accept-Charset | 通知服务端可以发送的编码格式 |
| Accept-Encoding | 通知服务端可以发送的数据压缩格式 |
| Accept-Language | 通知服务端可以发送的语言 |
(3)响应报文
状态行:状态行由协议版本,状态码,状态码描述三部分组成。
响应头:响应头与请求头部类似,为响应报文添加了一些附加信息。
空行:响应头部的最后会有一个空行,表示响应头部结束。
响应体:服务器返回的相应 HTML 数据,浏览器对其解析后显示页面。

(4)常见响应头
| 响应头 | 描述 |
| Server | 服务器应用程序软件的名称和版本 |
| Content-Type | 响应正文的类型(是图片还是二进制字符串) |
| Content-Length | 响应正文长度 |
| Content-Charset | 响应正文使用的编码 |
| Content-Encoding | 响应正文使用的数据压缩格式 |
| Content-Language | 响应正文使用的语言 |
总结:常见的状态码及原因
1xx:信息性状态码,表示服务器已经接收到请求,正在处理中。
- 100:请求已被服务器接收,继续处理。
- 101:服务器已经理解了客户端的请求,并将通过Upgrade消息头通知客户端采用不同的协议来完成这个请求。例如,将HTTP协议升级为WebSocket协议。
2xx:成功状态码,表示服务器已经成功处理了请求。
- 200:请求已成功,请求所希望的响应头或数据体将随此响应返回。
- 201:请求已经被成功处理,并创建了新的资源。
- 204:请求已成功处理,但是没有返回任何内容。
3xx:重定向状态码,表示请求需要进一步操作以完成请求。
- 301:请求的资源已永久移动到新的位置,客户端应该使用新的URL访问。
- 302:请求的资源已临时移动到新的位置,客户端应该使用新的URL访问。
- 304:客户端发送了一个带条件的请求,服务器告诉客户端资源未被修改,可以直接使用缓存的资源。
4xx:客户端错误状态码,表示客户端发送的请求有错误。
- 400:请求语法错误,服务器无法识别此请求。
- 401:请求未经授权,需要身份验证。
- 403:请求被服务器拒绝,权限不足。
- 404:请求的资源不存在。
5xx:服务器错误状态码,表示服务器处理请求时发生错误。
- 500:服务器内部错误,无法完成请求。
- 503:服务器暂时无法处理请求,通常是因为服务器过载或正在进行维护。