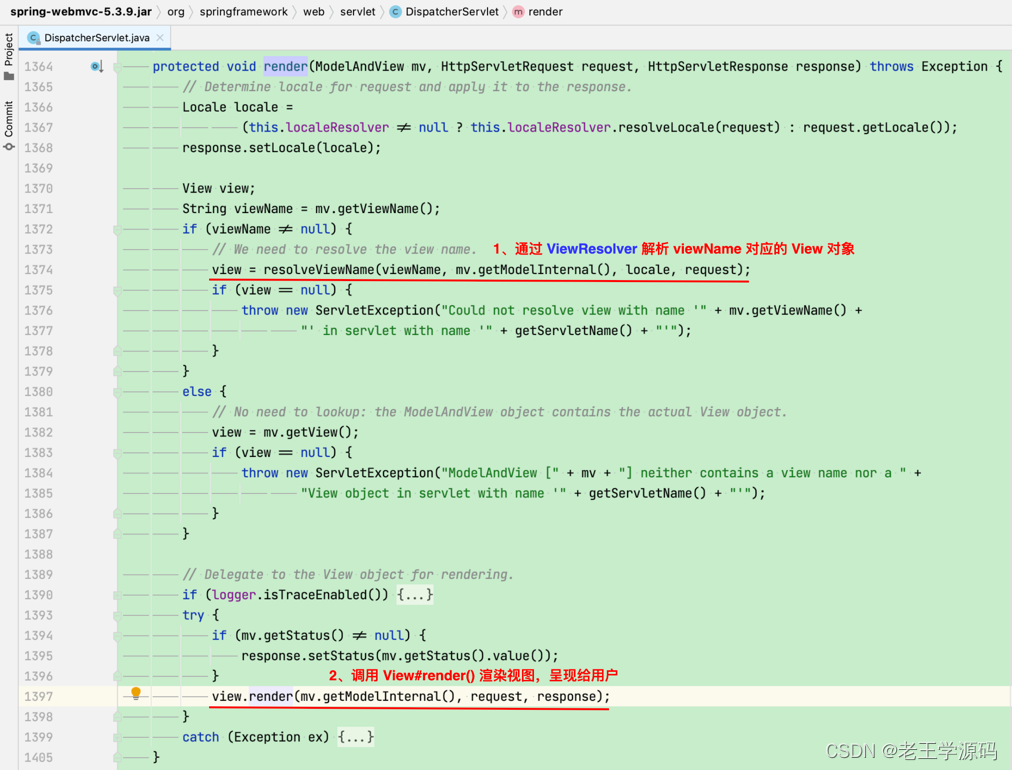
本次分享阿里巴巴达摩院语音实验室、新南威尔士大学与香港科技大学(广州)等在ICASSP2023会议发表的论文《Weighted Sampling for Masked Language Modeling》。该论文主要提出了两种简单有效的加权采样策略,来缓解掩码语言模型(MLM)中的频率偏差问题。
论文作者:
https://arxiv.org/abs/2302.14225Linhan Zhang†, Qian Chen‡, Wen Wang‡, Chong Deng‡, Xin Cao†, Kongzhang Hao†, Yuxin Jiang∗, Wei Wang∗
† University of New South Wales, School of Computer and Engineering
‡ Speech Lab, Alibaba Group, China
∗ Hong Kong University of Science and Technology (Guangzhou), China
论文地址:https://arxiv.org/abs/2302.14225
0 Abstract
掩码语言模型(Masked Language Modeling,MLM)被广泛用于预训练语言模型。标准的随机掩码策略会导致预训练语言模型(PLMs)偏向于高频词。对于罕见词的表示学习效果较差,且PLMs在下游任务中的性能受到限制。为了缓解这种频率偏差问题,我们提出了两种简单而有效的加权采样策略,以基于词频和训练损失进行掩码。我们将这两种策略应用于BERT,并获得了加权采样BERT(WSBERT)。在语义文本相似性基准(Semantic Textual Similarity benchmark,STS)上的实验表明,WSBERT在句子嵌入方面明显优于BERT。将WSBERT与校准方法和提示学习相结合,进一步提高了句子嵌入的性能。我们还研究了在GLUE基准上微调WSBERT,并表明加权采样也提高了骨干PLM的迁移学习能力。同时我们进一步分析并提供了WSBERT如何改善单词嵌入的见解。
1 Introduction
早期的语言模型只是对语境进行从左到右或者从右到左的单向建模。相比之下,掩码语言模型(MLM)用一个特殊的单词[MASK]替换了输入序列中的一个单词子集,并训练模型使用它的双向语境来预测被掩码的单词。MLM已被广泛作为学习双向语境化语言表征的自监督预训练目标,如BERT和RoBERTa。BERT及其扩展的预训练语言模型(PLMs)在各种下游NLP任务中均有优秀表现。
然而,最近的研究揭示了MLM的关键问题。一些研究发现BERT和其他PLM的上下文词表征不是各向同性的(isotropic),因为它们在方向上不是均匀分布的;相反,它们是各向异性的,因为词表征占据了一个狭窄的锥体。预训练数据中的标记频率通常遵循一个长尾分布。MLM的传统掩码策略是选择具有均匀分布的单词进行屏蔽。MLM的这种随机掩蔽策略不可避免地会遇到频率偏差的问题,即高频单词会被频繁地掩蔽,而信息量较大的单词,通常频率较低,在预训练中被掩蔽的频率会低很多,这将大大损害预训练的效率,降低罕见词的表征质量,限制PLM的性能。

如图1所示,根据频率选择的单词(粉红色,见公式2)显然比随机选择的单词(蓝色)更有信息量,后者大多是高频词,但对句子的语义并不重要。一些学者研究了MLM训练的PLM的嵌入空间,证实了嵌入更偏向高频词,而罕见词在嵌入空间中分布稀疏。并且证明了频率偏差确实会损害了由MLM训练的PLM生成的句子嵌入的性能。如这些研究所示,缓解频率偏差问题对于提高MLM的有效性和生成的PLM的性能至关重要。
最近的一些研究主要关注提高预训练的效率,包括混合精度训练,不同层的参数提炼,引入注释字典以保存罕见词的信息,设计不同的训练目标,以及在预训练中放弃冗余的单词。然而,这些方法大多集中在修改模型结构或优化预训练上。
我们的工作重点是缓解MLM中的频率偏差问题以及提高PLM的质量。我们提出了两种基于单词频率或训练损失的加权采样(Weighted Sampling)方法来掩蔽单词。后者可以动态调整采样权重,并根据PLM的学习状况在常见词和罕见词的掩码概率之间实现良好的平衡。我们的加权采样方法可以应用于任何MLM-预训练的PLMs。在这项工作中,我们重点研究了将加权采样应用于BERT作为骨干的预训练模型并关注加权采样方法的有效性。我们将BERT初始化,并用加权采样进行预训练。我们将其称为WSBERT。
我们假设加权采样可以缓解频率偏差,同时也可以改善罕见词的表征学习、提高语言表征的整体质量。预训练的语言表征的质量通常是在PLM产生的句子表征、语义文本相似性(STS)基准上进行评估。除此之外也可以在PLM的迁移学习能力上进行评估,通常在GLUE基准上进行微调和测试。最近在句子表征建模方面的研究包括校准方法,提示学习,以及基于句子水平的对比学习(CL)模型,如SimCSE及其变体。尽管SimCSE及其变体在语义文本相似性(STS)上取得了最先进的(SOTA)性能,但由于它们没有以改善单词级表征学习为目标,所以在SQuAD等任务上的迁移学习能力有所下降。我们还观察到,与BERT相比,SimCSE-BERT在GLUE上的性能绝对下降了0.5。
在这项工作中,为了研究所提出的加权采样是否能提高单词嵌入的质量,我们评估了WSBERT在STS上生成的句子表示,以及WSBERT在GLUE上的可转移性。我们还分析了WSBERT和BERT的嵌入空间,以了解加权采样如何提高词嵌入的质量。我们的贡献可以总结为以下几点:
-
我们提出了两种加权采样方法来缓解传统掩码语言建模中的频率偏差问题。
-
我们通过将加权采样应用于BERT,开发了一种新的PLM,即WSBERT。与SOTA句子表征模型不同,我们发现WSBERT在句子表征质量和迁移学习能力方面都优于BERT。我们还在WSBERT中集成了校准方法和提示,从而进一步改善了句子的表征。
-
我们设计了消融方法来分析WSBERT和BERT的嵌入空间。我们发现,在加权抽采样法下,罕见词与常见词更加集中,常见词在嵌入空间中比BERT更加集中。我们还发现,与BERT相比,WSBERT中的常见和罕见词都更接近原点,而且WSBERT的词嵌入比BERT的稀疏程度更低。
2 Method
在这一节,我们主要介绍了传统的掩码语言模型(MLM),然后我们提出了 MLM 的加权采样来缓解频率偏差问题。
2.1 Masked Language Modeling
对于一个句子 S = {t1, t2, . . . , tn},其中 n 是单词的数量,ti 是一个单词,BERT中的标准屏蔽策略随机选择 15% 的单词进行屏蔽。语言模型学习预测具有双向语境的被掩码的单词。为了使模型与微调兼容,对于一个被选中的标记,10%的时间被语料库中的随机标记取代,10%的时间保持不变,80%的时间被一个特殊的单词[MASK]取代。
2.2 Weighted Sampling
为了解决频率偏差问题,我们提出了两种加权采样策略,即频率加权采样和动态加权采样,分别基于统计信号和模型的信号来计算每个标记的掩码概率。
2.2.1 Frequency Weighted Sampling
一个符号w的信息性的自然统计信号是它在预训练语料库中的频率freq(w)。我们首先应用下面的转换来消除极其罕见单词的过度影响,这些标记通常是噪音。

然后我们计算采样权重wt(w),如下所示。

在我们的实验中,我们根据对开发集的性能优化,设置了超参数θ=10和α=0.5。
对于一个句子S={t1, t2, ......, tn}中的每个单词ti,其中n是单词的数量。我们通过归一化wt(ti)来计算屏蔽ti的采样概率p(ti)。

2.2.2 Dynamic Weighted Sampling
频率加权采样法对单词产生恒定的采样概率,而且并不考虑它所适用的掩码语言模型的学习状态。我们假设,一个单词w的信息信号也可能与掩码语言模型对它的预测效果相关。因此,我们提出了图2所示的动态加权取样策略。

我们使用内存中的权重字典来存储每个迭代中的每个批次后的每个单词的采样权重,而不是在一个迭代中处理所有批次的更新,其中采样只进行一次。首先,我们为权重字典中的每个单词 ti∈T 设置一个初始采样权重wt(ti)=1,其中T表示预训练数据集中的所有单词。然后,我们使用基于公式3的权重字典中的采样权重来计算采样概率,并训练一个掩码的语言模型。在每个小批次中,掩码的单词被当前模型预测,我们计算出单词ti的总交叉熵损失为:
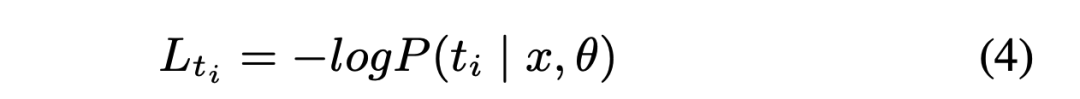
其中x表示输入掩码序列,θ表示当前掩码语言模型的参数。然后,我们使用$L_{t_i}$计算基于下面公式的采样权重wt(ti)。

其中 τ 是温度参数,默认值为0.2。最后,对于下一个小批量,我们在对 wt(ti) 进行归一化来计算单词 ti 的采样概率 p(ti)。
由上式计算的采样权重,对于具有较高交叉熵预测损失的单词更大,即在当前掩码语言模型中学习不佳且通常是罕见词;对于具有较低交叉熵损失的标记,即相对更好学习的单词,采样权重较小。我们将采样权重函数 wt(ti) 设计上式,目的是扩大不同单词之间采样权重的方差,进一步提高罕见词的采样概率。在预训练的每次迭代中,权重字典都会使用每个单词 ti 的最新采样权重 wt(ti) 进行更新。对于下一次迭代,对于序列 s = t1, t2, ..., tn, s ∈ S,选择掩码每个单词的采样概率是使用等式更新的权重字典计算的。
3 Experiments
我们进行了两组实验。首先,我们通过评估常用的 STS 任务,调查使用 WSBERT 的无监督句子表征的质量。之后,我们通过在 GLUE 基准上进行微调并且评估 WSBERT,研究加权采样对 BERT 迁移学习能力的影响。我们还设计了消融研究来分析 WSBERT 对罕见词和常见词的词嵌入的影响。
3.1 Datasets and Implementation Details
对于 WSBERT,我们在 bert-base-uncased (BERT) 上进行预训练,在 WikiText 数据集(+100M 单词)上进行加权采样。我们将学习率设置为 5e-5 并训练 10 个epoch。我们使用 4 个 NVIDIA V100 GPU 来训练 WSBERT,每个设备的批量大小为 8,梯度累积为 8。我们使用 WordPiece 标记器,单词频率基于标记化的维基文本。STS 任务包含 STS 2012-2016、STS 基准和 SICK-Relatedness 数据集。GLUE 包括八个数据集:MNLI、QQP、QNLI、SST、STS、Cola、MRPC、RTE。为了分析在没有加权采样的情况下持续预训练的效果,我们继续对 BERT 进行预训练,使用与 BERT 相同的随机采样,在相同的 WikiText 数据上使用与 WSBERT 相同的预训练设置,我们将其称为 BERT-CP。我们比较了 bert-base-uncased (BERT)、BERT-CP 和 WSBERT 在 GLUE 上的微调性能。对于每个 GLUE 任务的每个模型,我们使用不同的随机种子运行三个运行;对于每次运行,我们在 2e−5、3e−5、5e−5 学习率和 5、10 个epoch之间对 GLUE 验证集的超参数进行网格搜索。三个模型的其他超参数相同:我们使用 1 个 V100进行训练,每个设备的批量大小为 32,warm-up率为0.06,权重衰减为 0.01。表2报告了三个运行的最佳结果的平均值和标准差。
3.2 Main Results

表1显示了语义文本相似度的主要STS结果。我们报告了具有频率加权掩码和动态加权掩码的WSBERT结果,分别称为WSBERT Freq和WSBERT Dynamic。表1中第一组结果显示WSBERT Dynamic比BERT和BERT-CP结果高提升了6.54 和 5.59,显著提高了 PLM 句子嵌入的质量。WSBERT Dynamic结果相比于WSBERT Freq提升4.06,表明动态加权采样比仅基于单词频率的采样更有效。BERT Whitening 作为一种校准方法,与WSBERT 兼容。
表1中的第二组结果显示,尽管WSBERT Dynamic在STS 上的平均得分低于BERT Whitening,但WSBERT Dynamic可以与Whitening有效结合,并将WSBERT Dynamic的性能进一步提高到 70.45。我们还研究了如何使用提示增强BERT和WSBERT。与以前在中使用单个 [MASK]的方法不同,我们使用具有多个[MASK]的手动提示模板来转换句子。此外,我们不是将掩码单词的提取和平均表征作为最终的句子嵌入,而是对整个转换后的句子进行编码,并通过平均池化句子的所有词嵌入来计算句子嵌入。
表1中的第三组显示,提示增强的WSBERT性能达到70.08。这些结果表明,加权采样改进了PLM生成的句子表征,并将WSBERT与Whitening和提示相结合进一步改进了句子嵌入。我们没有将WSBERT与STS上的SOTA模型进行比较,即基于句子级对比学习 (CL) 的模型,例如 SimCSE,因为之前的工作和我们的研究表明基于句子级CL的模型会损害迁移学习能力。与 BERT 相比,我们观察到 SimCSE-BERT的GLUE AVG分数下降了 0.5。然而,正如下面的GLUE实验所示,WSBERT既增强了BERT的句子表示,又提高了迁移学习能力。

GLUE 评估如表 2 所示,与 BERT 和 BERT-CP 相比,WSBERT 获得了最好的平均 GLUE 分数,绝对优于 BERT 0.52。WSBERT 在 MNLI 和 QQP 上保持着不错的竞争力,并在其他所有任务上均优于 BERT。与 SimCSE 等模型相比,动态加权采样在增强句子表示的同时提高了迁移学习能力。与 BERT 相比,BERT-CP 在 GLUE AVG 上降低了0.35。而 WSBERT 比 BERTCP 绝对值提高了0.87。这些结果证明 WSBERT 相比于 BERT 的提高增益来自动态加权采样的持续预训练,而不是仅使用随机采样在 WikiText 数据集上对 BERT 预训练更多步骤。与 BERT 相比,BERT-CP 在 GLUE 的性能降低,这可能是因为用于连续预训练的 WikiText(373.28M 数据大小)比标准 BERT 预训练数据集(Wikipedia 和 Bookscorpus,16GB 数据大小)小得多且多样化程度较低,这可能会伤害PLM 的通用性。
3.3 Analysis
MLM 预训练 PLM 的词嵌入可能会因单词频率而产生偏差,导致高频单词的嵌入非常集中,而罕见词分散稀疏。受以往这些工作的启发,为了分析加权采样是否确实可以缓解频率偏差问题,我们提出了两种方法来分析表示空间中 BERT、BERT-CP 和 WSBERT 的分布。我们还分析了使用和不使用加权采样训练模型的训练时间。
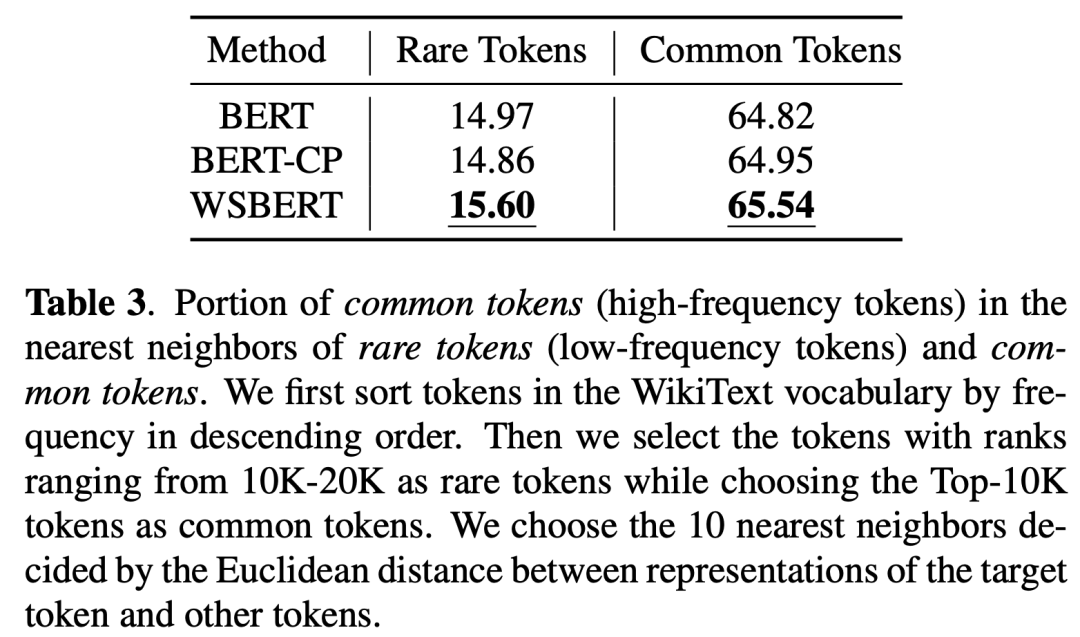
Nearest Neighbors: 我们研究了罕见词的最近邻 (NN) 中的常见词部分,将其定义为Prare,以及常见词在常见词的最近邻中的部分,表示为Pcommon(罕见词和常见词在表3解释中定义)。罕见和常见词的最近邻中较大部分的常见词分布更加集中,因此词嵌入中的频率偏差更小。在表 3 中,WSBERT 的 Prare/Pcommon 比 BERT 增加了 0.63/0.72,比 BERT-CP 增加了 0.74/0.59,这表明与 BERT 和 BERTCP 相比,WSBERT 在词嵌入中具有更集中的单词分布和更小的频率偏差,与 BERT 和 BERT-CP 相比,常见词也更集中于 WSBERT。
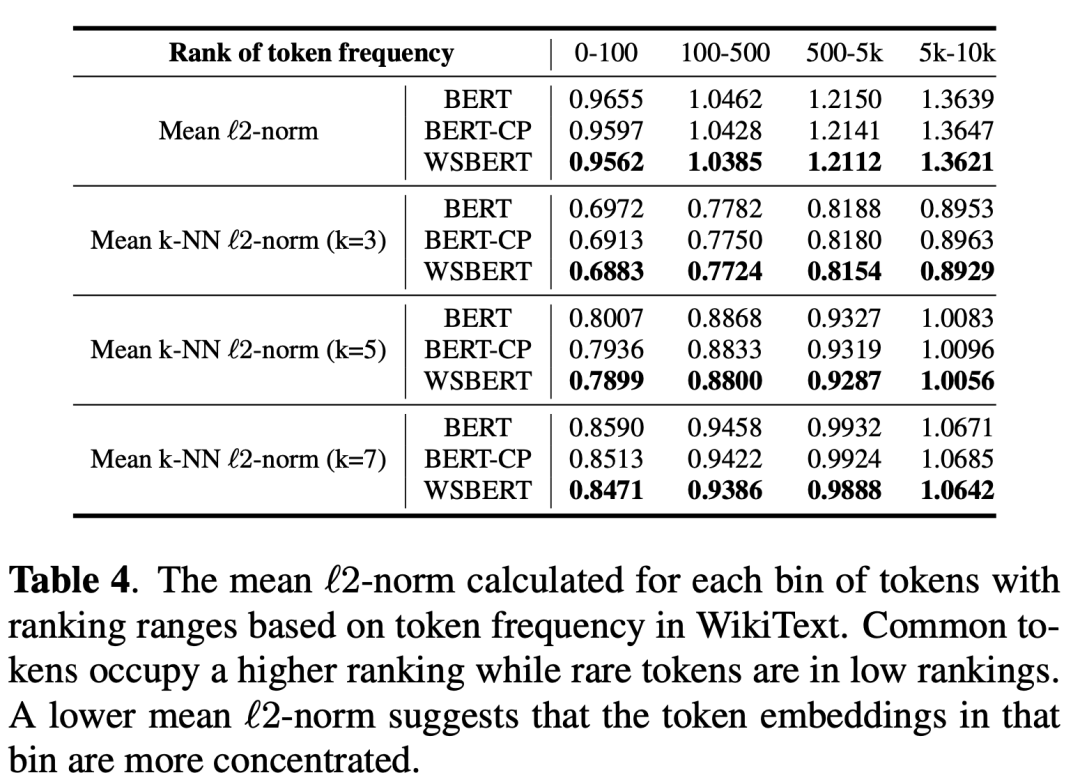
Token Distribution:收到其他工作的启发,我们计算了三个模型词嵌入和原点之间的均值L2-范数,以分析单词分布。如表 4 第一行所示,虽然常见的词靠近原点而罕见词分布在远离原点的地方,但较小的均值 L2-范数 表明 WSBERT 的词嵌入 比 BERT 和 BERT- CP更加集中。WSBERT 的 L2-范数在所有区间上都小于 BERT,这表明常见词和罕见词都比 BERT 更接近 WSBERT 的原点。此外,如表4中每个k的较小平均k-NNL2-范数所示,每个区间中的WSBERT单词比BERT和BERT-CP更紧凑,这表明WSBERT的嵌入空间比BERT和BERT-CP更加紧凑。嵌入空间中的稀疏性可能会导致语义定义不清,因此WSBERT在句子嵌入和迁移学习能力方面的优势也可能归因于嵌入空间中WSBERT的稀疏性降低。
Training Time: 在训练期间计算每个单词的采样权重需要一些额外的时间。因此,我们比较了10个epoch有加权采样和没有加权采样的MLM训练时间。不进行加权采样的训练需要11个小时,而进行加权采样训练需要20个小时。这种效率和性能之间的折衷是可以接受的。
4 Conclusion
我们提出了两种加权采样方法来缓解预训练语言模型的掩蔽语言模型中的频率偏差问题。大量实验表明,加权采样提高了句子表征和预训练模型的迁移能力。我们还分析了词嵌入,目的是解释加权采样是如何工作的。我们未来的工作包括研究其他动态采样方法,并研究对频率偏差具有惩罚的训练目标。
(论文翻译:内蒙古大学计算机学院22级硕士研究生 马泽宁)