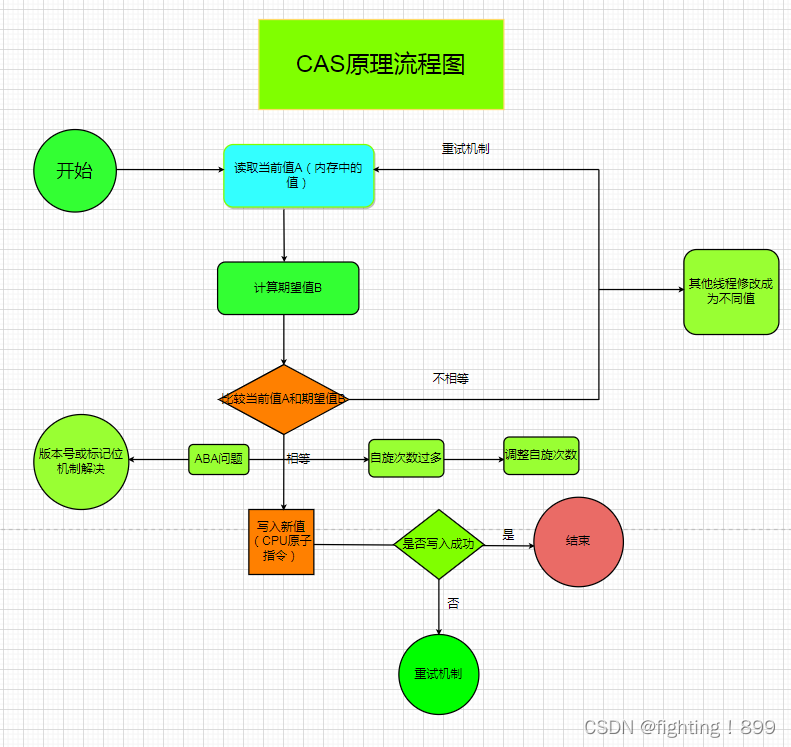
本章节内容节自《python 编程从入门到实践》第十六章,我们将从网络上下载数据,并对数据进行可视化。就可以对其进行分析甚至观察其规律和关联。
学习目标
我们将访问并可视化以下两种常见格式存储的数据:
-
CSV
使用 Python 模块 CSV 来处理以 CSV格式存储的天气数据,找出两个不同地区在同一个时间段内的最高气温和最低温度。然后 使用 matplotlib 根据下载的数据创建一个图表,展示两个不同地区的气温变化
-
JSON
使用 Python 模块 json来访问 JSON格式存储的交易收盘价格数据,并使用Pygal 绘制图形以探索价格变化的周期性
1. CSV 文件格式
要在文本文件中存储数据,最简单的方式:
将数据作为一系列以逗号分隔的值(CSV)写入文件。这样的文件称为 CSV 文件。
例如:
2023-5-14,19,99,12,12,1,2,3,4,5,6,7,8,9,1.0,1.1,1.2,,,,,2.3
虽然 CSV 文件对人来说阅读起来比较麻烦,但程序可以轻松地提取并处理其中的值,这有助于加快数据分析过程。
我们首先处理少量 CSV 格式的天气数据:
这些数据存储在: sitka_weather_07-2014.csv 中,需要将其复制到程序所在的文件夹中。


如果你没有练习资料,也没关系,我已经将其上传到个人资源中,可以到我的个人主页中下载。
我发布的所有内容,即便对你无益,却都是我学到的,无需任何浏览条件。
我分享的所有文件,即便对你无用,却都是无任何下载条件的。


准备阶段的内容已经彻底完成了,下面我们开始正式进入到学习状态:
1.1 分析 CSV 文件头
csv 模块包含在 python 标准库中,可用于分析 CSV 文件中的数据行。
下面我们来查看这个文件的第一行,其中包含一系列有关数据的描述:
highs_lows.py:
import csv
filename = 'sitka_weather_07-2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
print(header_row)
代码片段说明:
我们先导入了 csv模块。
然后将要是有的文件 存储到一个名为 filename 的变量当中。接下来去打开这个文件,并将其结果对象存储在 f 中,然后在调用 svc.reader(),将前面存储的文件作为实参传递给它,从而创建一个与该文件相关联的阅读器。
我们将这个阅读器存储对象存储在 reader 中。
调用的 next() 函数,包含自 : reader 类。
调用 reader 内置的 next 方法并将reader 作为参数传递给它时,会返回文件中的下一行。
我们先执行程序看一下运行效果:

的确如实读出来文件的第一行内容了。
因为我们只调用了一次 next() 函数,所以只读出来了一行内容。
reader 处理文件中以逗号分隔的每一行数据,并将每项数据都作为一个元素存储到列表中。
1.2 打印文件头及其位置
为了让文件头数据更容易理解,将列表中的每个文件头及其位置打印出来:
fighs_lows.py:
这里我们需要使用一下 enumerate() 函数,用其获取每个元素的索引及其值。
import csv
filename = 'sitka_weather_07-2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
#print(header_row)
for index,column_header in enumerate(header_row):
print(index,column_header)
程序执行完成后是这样的:

这里删除了第一个用于打印reader.next读取文件内容信息的print语句。
然后对列表调用 enumerate() 函数,这个函数的作用:获取每个元素的索引及其值。最后 print 一下 存储文件下一行内容的 header_row 变量。
1.3 提取并读取数据
现在,我们能将数据读取出来了。现在要做的就是可以将读取数据中提取出来自己需要的。
filename = 'sitka_weather_07-2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
print(header_row)
highs = []
for row in reader:
highs.append(row[1])
print(highs)
在这里我们创建了一个名为 highs的空列表。然后遍历文件中余下的各行。阅读器对象从其停留的地方继续向下读取。且每次都会返回当前所处位置的下一行。
由于我们之前读取了文件头行,所以这里会从第二行开始读取。每次执行循环时都会将索引1处也就是第二列的数据附加到highs的末尾处。
执行效果:

下面我们使用 int() 将这些数字提取为数字,让 matplotlib 能够提取他们:
highs = []
for row in reader:
high = int(row[1])
highs.apped(high)
print(highs)

然后是将其可视化:
1.4 绘制气温图表
使用 matplotlib 绘制一个显示每日最高气温的图像:
highs_lows_mp:
import csv
from matplotlib import pyplot as plt
#从文件中获取最高气温
filename = 'sitka_weather_07-2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
print(header_row)
highs = []
for row in reader:
high = int(row[1])
highs.append(high)
print(highs)
#根据数据绘制图形
fig = plt.figure(dpi=128,figsize=(10,6))
plt.plot(highs,c='red')
#设置图形格式
plt.title("Daily high temperatures, July 2014",fontsize = 24)
plt.xlabel('',fontsize=16)
plt.xlabel("Temperature(F)",fontsize =16)
plt.tick_params(axis='both',which='major',labelsize =16)
plt.show()

1.5 模块 datetime
我们的 sitka_weather_01-2014.csv 文件内容是这样的:

在这个文件中,第一行数据相当于所有数据的标题。
从第二行开始,才是具体的时间数据。
下面开始在图表中添加日期,使其更有用。
想读取时间数据时,获得的是一个字符串,因为我们需要想办法将字符串’2017-7-1’转换为一个表示相应日期的对象。为创建一个表示2014年7月1日的对象,可以使用 模块datetime 中的方法 strptime()。
使用示例:
from datetime import datetime as dt
first_time = dt.strptime('2014-7-1','%Y-%m-%d')
print(first_time)
其效果是这样的:

这里:我们首先创建了一个 datetime中的 datetime 类,然后调用它的 strptime() 方法,并且将包含所需日期的字符串作为第一个参数。第二个实参告诉 python 如何设置日期的格式。
.
‘%Y-’ 表示将字符串中的第一个连字符前面的部分视为四位的年份。
‘%m-’ 表示见字符串中的第二个连字符前面的部分视为月份的数字。
‘%d’ 让python 将字符串中的最后一个连字符部分视为月份中的第一天。
strptime() 可接受的参数:
| 实参 | 含义 |
|---|---|
| %A | 星期的名称。如Monday |
| %B | 月份名。 如January |
| %m | 用数字表示的月份(01~12) |
| %d | 用数字表示月份中的一天(01~31) |
| %Y | 四位的年份。如2023 |
| %y | 两位的年份。如23 |
| %H | 24小时制的小时数 |
| %I | 12小时制的小时数 |
| %p | am 或 pm |
| %M | 分钟数。(00~59) |
| %S | 秒数。(00~60) |
1.6 在图标中添加日期
现在知道了如何处理 CSV文件中的日期后。就可以对气温图形进行改进了。
即提取日期和最高气温,并将它们传递给plot()。
highs_lows_mp.py:
import csv
from matplotlib import pyplot as plt
from datetime import datetime as dt
#从文件中获取最高气温
filename = 'sitka_weather_07-2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
print(header_row)
dates,highs = [],[]
for row in reader:
current_date = dt.strptime(row[0],"%Y-%m-%d")
dates.append(current_date)
high = int(row[1])
highs.append(high)
print(highs)
#根据数据绘制图形
fig = plt.figure(dpi=128,figsize=(10,6))
plt.plot(dates,highs,c='red')
#设置图形格式
plt.title("Daily high temperatures, July 2014",fontsize = 24)
plt.xlabel('',fontsize=16)
fig.autofmt_xdate()
plt.xlabel("Temperature(F)",fontsize =16)
plt.tick_params(axis='both',which='major',labelsize =16)
plt.show()

这次我们创建了两个空列表,用于存储从文件中提取的日期和最高气温。然后,我们将包含日期信息的数据(row[0])转换为datetime对象,并将其附加到列表dates末尾。
然后将日期和最高气温值传递给 plot()。在调用 fig.autofmt_xdate()来绘制斜的日期标签,以免它们被重叠。
1.7 涵盖更长的时间
现在我们要在图表上添加更多的数据。 以 一座城市的天气图为例。
先将 sitka_weather_2014.csv 文件放到本程序所在的文件夹当中,该文件包含 某城市的一整年天气数据。


放好之后,我们该开始思考怎么用代码将这些数据绘制成图了:
import csv
from matplotlib import pyplot as plt
from datetime import datetime as dt
#从文件中获取最高气温
filename = 'sitka_weather_2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
print(header_row)
dates,highs = [],[]
for row in reader:
current_date = dt.strptime(row[0],"%Y-%m-%d")
dates.append(current_date)
high = int(row[1])
highs.append(high)
print(highs)
#根据数据绘制图形
fig = plt.figure(dpi=128,figsize=(10,6))
plt.plot(dates,highs,c='red')
#设置图形格式
plt.title("Daily high temperatures - 2014",fontsize = 24)
plt.xlabel('',fontsize=16)
fig.autofmt_xdate()
plt.xlabel("Temperature(F)",fontsize =16)
plt.tick_params(axis='both',which='major',labelsize =16)
plt.show()
其实这段代码和前面的示例别无区别。只是更改了所要读取的目标文件。其次就是还修改了绘制图表的标题。
1.8 再绘制一个数据系列
现在需要从数据文件中提取最低气温,并将它们添加到图表中。
import csv
from matplotlib import pyplot as plt
from datetime import datetime as dt
#从文件中获取最高气温
filename = 'sitka_weather_2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
print(header_row)
dates,highs,lows = [],[],[]
for row in reader:
current_date = dt.strptime(row[0],"%Y-%m-%d")
dates.append(current_date)
high = int(row[1])
highs.append(high)
low = int(row[3])
lows.append(low)
print(highs)
#根据数据绘制图形
fig = plt.figure(dpi=128,figsize=(10,6))
plt.plot(dates,highs,c='red')
#设置图形格式
plt.title("Daily high temperatures - 2014",fontsize = 24)
plt.xlabel('',fontsize=16)
fig.autofmt_xdate()
plt.xlabel("Temperature(F)",fontsize =16)
plt.tick_params(axis='both',which='major',labelsize =16)
plt.show()

1.9 给图表区域着色
通过添加两个数据系列后,可以了解每天的气温范围。
下面来给这个图表最后的修饰,通过着色来呈现每天的天气范围。
fill_between()
它接受一个x值系列和两个值系列,并填充两个y值系列之间的空间:
plt.plot(dates,highs,c='red',alpha =0.5)
plt.plot(dates,lows,c='red',alpha =0.5)
plt.fill_between(dates,highs,lows,facecolor ='blue',alpha =0.1)

alpha 指定颜色的透明度。0表示完全透明,1表示完全不透明。
设置为0.5,可让红色和蓝色都看起来更浅。
.
fill_between() 说明:
这里我们传递的x值系列为 列表 dates,传递的两个y值分别为:highs,lows。实参facecolor指定了填充区域的颜色。
1.10 错误检查
这是关于 处理CSV格式的最后一小节内容。
现在程序的状态为: 我们使用 highs_lows.py中写好的逻辑来读取文件:sitka_weather_2014.csv 中的数据。
但如果,我们不想读取这个文件中的数据了。
首先要做的就是更改程序中定义好的文件的名字:
将 titak_weather_2014.csv 更改为 death_valley_2014.csv
然后运行程序,开始读取数据:
运行结果报错了,其信息显示如下

出现这个bug的原因源于:
python 无法处理其中一天的最高气温,因为它无法将空字符串(’ ') 转换为整数。
现在,我们知道了原因,但是为了确凿事实,在去看一下所读取文件的内容:

为了解决这个问题,我们可以在代码程序中加入异常处理:
import csv
from matplotlib import pyplot as plt
from datetime import datetime as dt
#从文件中获取最高气温
filename = 'death_valley_2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
#print(header_row)
dates,highs,lows = [],[],[]
for row in reader:
try:
current_date = dt.strptime(row[0],"%Y-%m-%d")
high = int(row[1])
low = int(row[3])
except ValueError:
print(current_date,'missing date')
else:
dates.append(current_date)
highs.append(high)
lows.append(low)
#print(highs)
#根据数据绘制图形
fig = plt.figure(dpi=128,figsize=(10,6))
plt.plot(dates,highs,c='red',alpha =0.5)
plt.plot(dates,lows,c='red',alpha =0.5)
plt.fill_between(dates,highs,lows,facecolor ='blue',alpha =0.1)
#设置图形格式
plt.title("Daily high temperatures - 2014",fontsize = 24)
plt.xlabel('',fontsize=16)
fig.autofmt_xdate()
plt.xlabel("Temperature(F)",fontsize =16)
plt.tick_params(axis='both',which='major',labelsize =16)
plt.show()
添加了异常处理之后,我们的程序又能正常运行了: