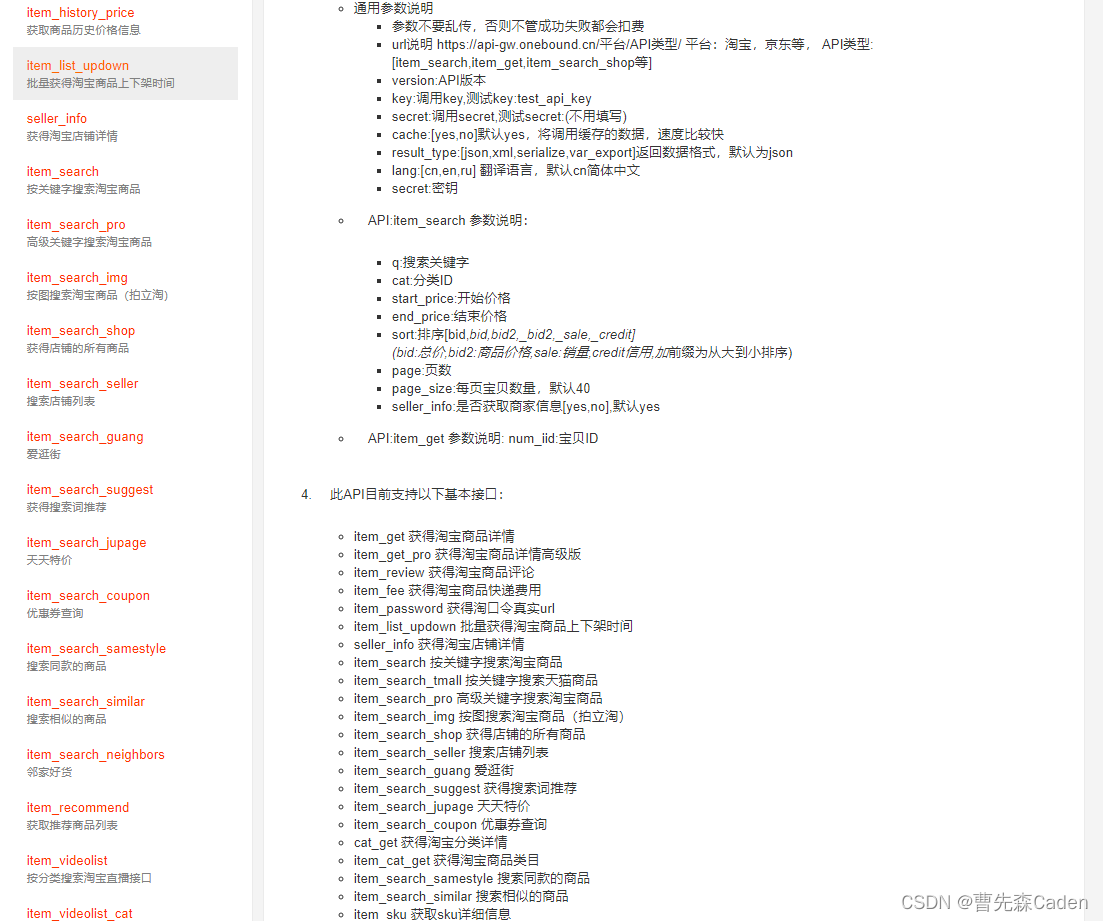
一、说明
在使用Pandas的DataFrame进行数据挖掘的时候,需要形形色色的条件查询,但是这些查询的基本语法是啥,查询的灵活性如何,本文将对他们进行详细列出,便于以后查阅。
二、Pandas条件查询方法
2.1 简单条件查询
1、使用“ [] ”符号进行简单条件查询
- 基本语法:
![]()
- 例如:
import pandas as pd
df = pd.read_csv('data.csv')
df[df['col1'] > 10] # 查询col1列中大于10的行表达式特点:是将由>,==,<, 等比较运算符构成表达式。
2、用“&”连起来的多条件查询
- 基本语法
![]()
使用多个条件进行复合条件查询,是"[ ]"表达式用“&”连起来,
- 例如:
df[(df['col1'] > 5) & (df['col2'] < 10)] # 查询col1列中大于5且col2列中小于10的行
3、str.contains()字符串条件查询
- 语法

使用str.contains()方法进行字符串条件查询,是查出字符串的子串有“apple”的行。
- 例如:
df[df['col1'].str.contains('apple')] # 查询col1列中包含'apple'字符串的行
4、多个字符串内容用isin条件查询
- 语法
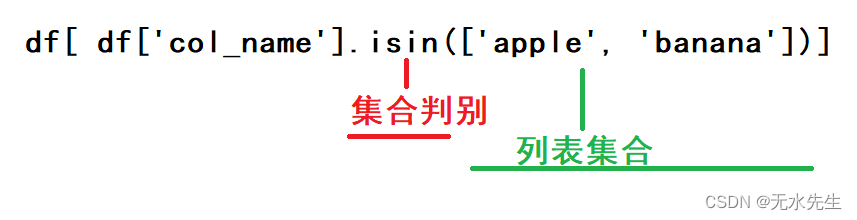
使用isin()方法进行包含查询,
- 例如:
df[df['col1'].isin(['apple', 'banana'])] # 查询col1列中包含'apple'或'banana'的行
5、between条件查询
使用between()方法进行范围查询,例如:
df[df['col1'].between(5, 10)] # 查询col1列中在5到10之间的行
6、查询空值
使用isna()或isnull()方法进行查询空值,例如:
df[df['col1'].isna()] # 查询col1列中为空值的行
2.2、高级查询
2.2.1 内嵌语句查询
- 例1: 比如我想找到所有姓张的人的信息:
df[[x.startswith('张') for x in df['姓名']]] 月份 姓名 性别 应发工资 实发工资 职位
0 1 张三 男 2000 1500 主犯
1 2 张三 男 2000 1000 主犯
2 3 张三 女 2000 15000 主犯
3 4 张三 女 2000 1500 主犯
4 5 张三 女 2000 1500 主犯
这里stratswith方法是Python自带的字符串方法,点这里查看详细说明。
- 还有一种方法:
criterion = df['姓名'].map(lambda x: x.startswith('张'))df[criterion]
月份 姓名 性别 应发工资 实发工资 职位
0 1 张三 男 2000 1500 主犯
1 2 张三 男 2000 1000 主犯
2 3 张三 女 2000 15000 主犯
3 4 张三 女 2000 1500 主犯
4 5 张三 女 2000 1500 主犯
- 速度比较:
# 第一种方法
%timeit df[[x.startswith('张') for x in df['姓名']]]
203 µs ± 8.92 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
# 第二种方法
%timeit criterion = df['姓名'].map(lambda x: x.startswith('张'))
93.2 µs ± 6.21 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
%timeit df[criterion]
201 µs ± 2.44 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
可以看到,第二种方法实际上并没有明显快多少。并且如果加上添加检索规则的时间反而更慢。
2.2.2 可用于修改内容的where方法
- 先看用法:
df.where(df['性别'] == '男')
月份 姓名 性别 应发工资 实发工资 职位
0 1.0 张三 男 2000.0 1500.0 主犯
1 2.0 张三 男 2000.0 1000.0 主犯
2 NaN NaN NaN NaN NaN NaN
3 NaN NaN NaN NaN NaN NaN
4 NaN NaN NaN NaN NaN NaN
5 2.0 李四 男 1800.0 1300.0 从犯
6 3.0 李四 男 1800.0 1300.0 从犯
7 4.0 李四 男 1800.0 1300.0 从犯
8 5.0 李四 男 1800.0 1300.0 从犯
9 NaN NaN NaN NaN NaN NaN
10 NaN NaN NaN NaN NaN NaN
11 NaN NaN NaN NaN NaN NaN
12 NaN NaN NaN NaN NaN NaN
这里where的使用和直接访问标签的方式就有所不同了,这是将所有满足条件的项保持原状,而其它项全部设为NaN。如果要替换数据的话,需要比较复杂的表达式,这里只看一个简单的例子:
dates = pd.date_range('1/1/2000', periods=8)
df = pd.DataFrame(np.random.randn(8, 4),index=dates, columns=['A', 'B', 'C', 'D'])
df.where(df < 0, -df)
A B C D
2000-01-01 -2.843891 -0.140803 -1.816075 -0.248443
2000-01-02 -0.195239 -1.014760 -0.621017 -0.308201
2000-01-03 -0.773316 -0.411646 -1.091336 -0.486160
2000-01-04 -1.753884 -0.596536 -0.273482 -0.685287
2000-01-05 -1.125159 -0.549449 -0.275434 -0.861960
2000-01-06 -1.059645 -1.600819 -0.085352 -0.406073
2000-01-07 -1.692449 -1.767384 -0.266578 -0.593165
2000-01-08 -0.163517 -1.645777 -1.509307 -0.637490
这里插一句:实际上numpy也有where方法,用法类似,可参考:Python Numpy中返回下标操作函数-节约时间的利器
2.2.3 快速的查询方法query
df.query('姓名>性别')
月份 姓名 性别 应发工资 实发工资 职位
2 3 张三 女 2000 15000 主犯
3 4 张三 女 2000 1500 主犯
4 5 张三 女 2000 1500 主犯
9 1 王五 女 1800 1300 龙套
10 2 王五 女 1800 1300 龙套
11 3 王五 女 1800 1300 龙套
12 4 王五 女 1800 1300 龙套
这里,字符串的比较可以查看Python的字符串比较。当然,这里可以看到,query方法主要还是用于列的比较。
2.3 pandas中的shift()函数
- 语法:
shift(periods, freq, axis)- 参数注释:
| 参数 | 参数意义 | |
|---|---|---|
| period | 表示移动的幅度,可以是正数,也可以是负数,默认值是1,1就表示移动一次,注意这里移动的都是数据,而索引是不移动的,移动之后没有对应值的,就赋值为NaN。 | |
| freq | DateOffset, timedelta, or time rule string,可选参数,默认值为None,只适用于时间序列,如果这个参数存在,那么会按照参数值移动时间索引,而数据值没有发生变化。 | |
| axis | 0为垂,1为水平 |
- 实例代码
# 表格数据生成
import pandas as pd
import numpy as np
import datetime
df = pd.DataFrame(np.arange(16).reshape(4,4),columns=['A','B','C','D'],index=pd.date_range('20130101', periods=4))
>>>df
A B C D
2013-01-01 0 1 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 10 11
2013-01-04 12 13 14 15
#默认是axis = 0轴的设定,当period为正时向下移动
# 表示表格从原始数据第二行开始有效
df.shift(2)
A B C D
2013-01-01 NaN NaN NaN NaN
2013-01-02 NaN NaN NaN NaN
2013-01-03 0.0 1.0 2.0 3.0
2013-01-04 4.0 5.0 6.0 7.0
#默认是axis = 0轴的设定,当period为负时向下移动
df.shift(-2)
A B C D
2013-01-01 8.0 9.0 10.0 11.0
2013-01-02 12.0 13.0 14.0 15.0
2013-01-03 NaN NaN NaN NaN
2013-01-04 NaN NaN NaN NaN
#axis = 1,当period为正向右,为负向左移动
df.shift(2,axis=1)
A B C D
2013-01-01 NaN NaN 0.0 1.0
2013-01-02 NaN NaN 4.0 5.0
2013-01-03 NaN NaN 8.0 9.0
2013-01-04 NaN NaN 12.0 13.0
# frep参数决定索引为日期,正加负减
df.shift(freq=datetime.timedelta(1))
A B C D
2013-01-02 0 1 2 3
2013-01-03 4 5 6 7
2013-01-04 8 9 10 11
2013-01-05 12 13 14 15
df.shift(freq=datetime.timedelta(-1))
A B C D
2012-12-31 0 1 2 3
2013-01-01 4 5 6 7
2013-01-02 8 9 10 11
2013-01-03 12 13 14 15
除了上述方法之外,还有:query方法的条件处理、MultiIndex情况下的处理、get方法、lookup方法等等
三、更多内容
(更新中..)