想要借鉴SegViT官方模型源码部署到本地自己代码文件中
1. 环境配置
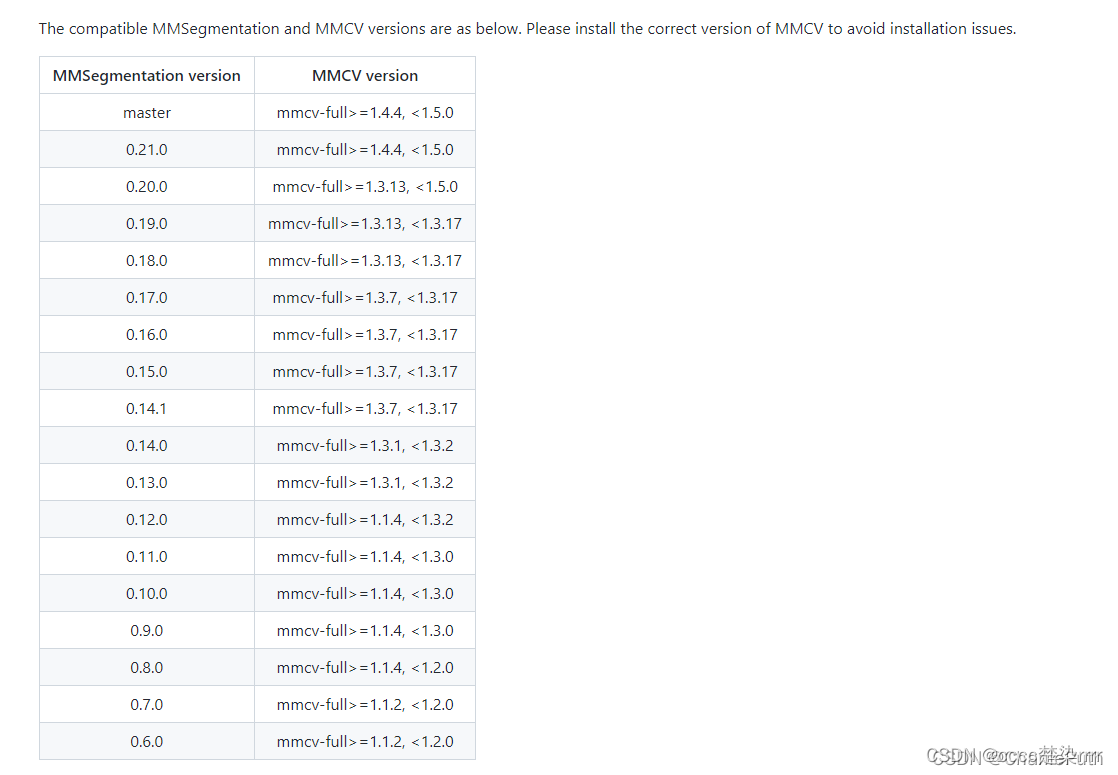
官网要求安装mmcv-full=1.4.4和mmsegmentation=0.24.0
在这之前记得把mmcv和mmsegmentation原来版本卸载
pip uninstall mmcv
pip uninstall mmcv-full
pip uninstall mmsegmentation
安装mmcv
其中,mmcv包含两个版本:一个是完整版mmcv(原来叫mmcv-full),一个是精简版mmcv-lite(原来叫mmcv),2.0.0版本之后更名了,具体的区别可以看mmcv官网手册和博客
安装mmcv-full(也就是mmcv完整版)主要参考mmcv官网手册。
如果你要安装mmcv>=2.0.0直接根据官网手册安装即可,不再赘述。
如果你要安装历史版本,例如我安装mmcv-full==1.4.4,可以参考我的记录。
在安装mmcv前,首先要知道自己的pytorch和cuda对应版本。
查看pytorch版本:
python -c 'import torch;print(torch.__version__)'
如果输出版本信息则已经安装pytorch
查看cuda版本:
注意要查你这个环境下pytorch对应的cuda版本
例如
这是我使用nvidia-smi命令查看的cuda版本:

这是我使用查看pytorch对应cuda版本命令:
python -c 'import torch;print(torch.version.cuda)'
也可以写成:
参考博客:https://blog.csdn.net/qq_49821869/article/details/127700187
python
>>>import torch
>>>torch.version.cuda

在这里我的pytorch版本应该是1.11.0,对应cuda版本是11.3
参考博客:https://blog.csdn.net/qq_41661809/article/details/125345690
于是,我输入命令:
pip install mmcv-full==1.4.4 -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.11.0/index.html
不成功,于是我访问了这个网址查看,发现我能用的最低版本也就是1.4.7
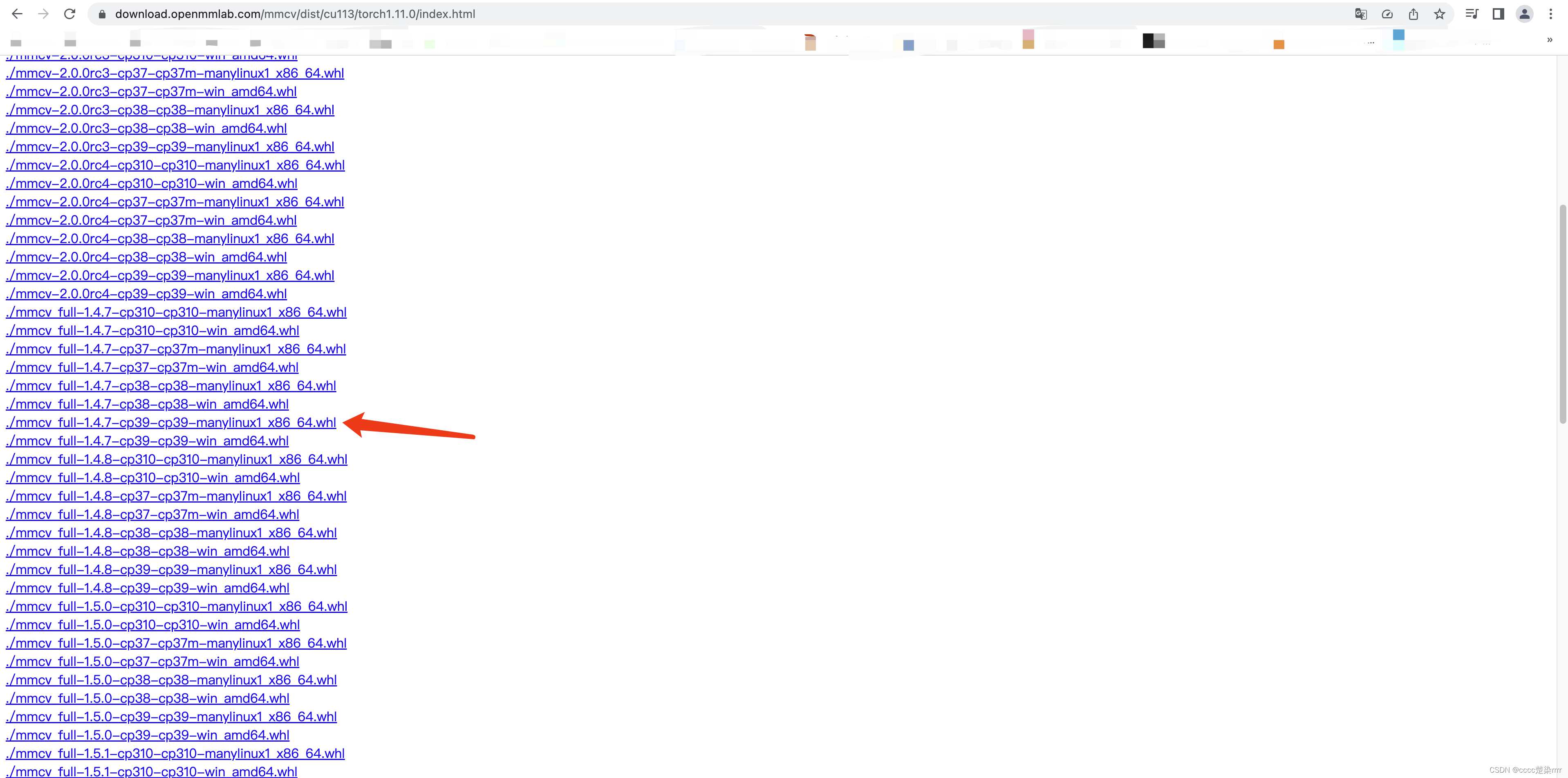
于是我把命令换成了:
pip install mmcv-full==1.4.7 -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.11.0/index.html
mmcv-full安装结束
安装mmsegmentation
mmsegmentation原本我是按照官网指导安装的,
但是要求mmcv>=2.0.0,而且安装的版本是mmsegmentation==1.0.0,这和我的要求冲突了。
注意mmsegmentation要和mmcv版本匹配:
参考博客:https://blog.csdn.net/CharilePuth/article/details/122909620
于是我直接:
pip install mmsegmentation==0.24.0
安装成功。
“pip安装包像喝水一样简单”——曾经一位大佬如是说道。
2. 搞代码!
找模型配置文件
进入官网,在Training中找到模型对应的config文件:
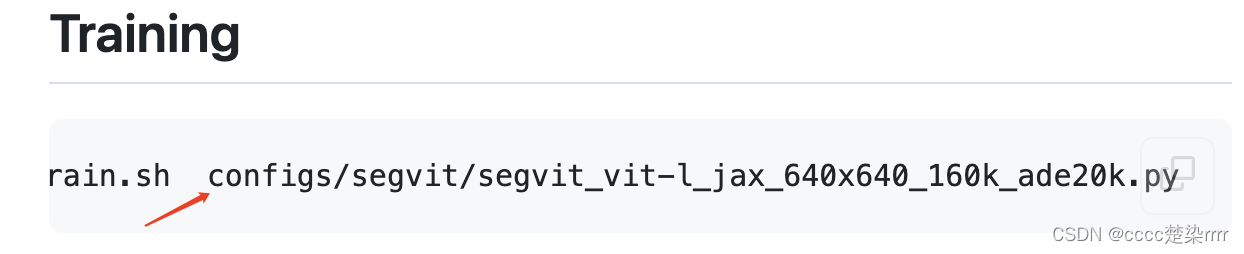
在Highlights中我知道了本文的一大亮点就是收缩结构,可以减小计算成本,因此接下来我会选择收缩结构:

由于我要跑的图片大小为512,因此我在这个代码的Results中找到同样512*512的COCO数据集对应模型:

返回configs文件夹找到这个数据集对应网络模型:
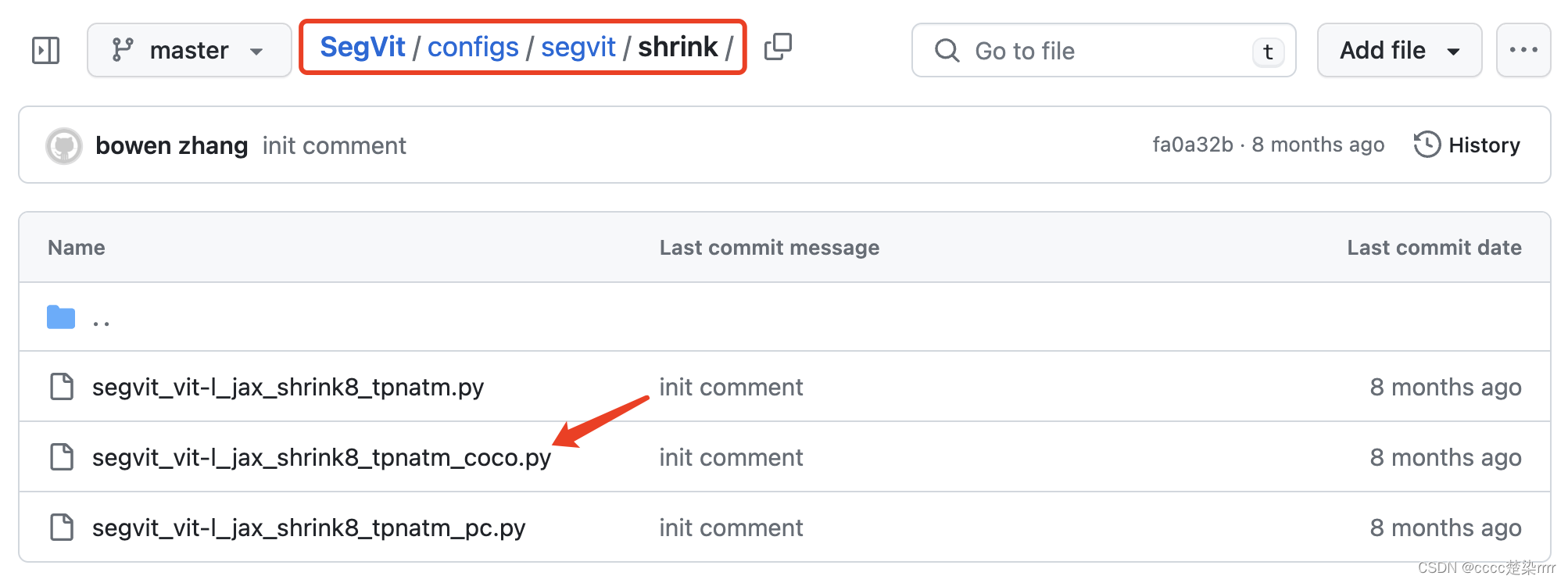
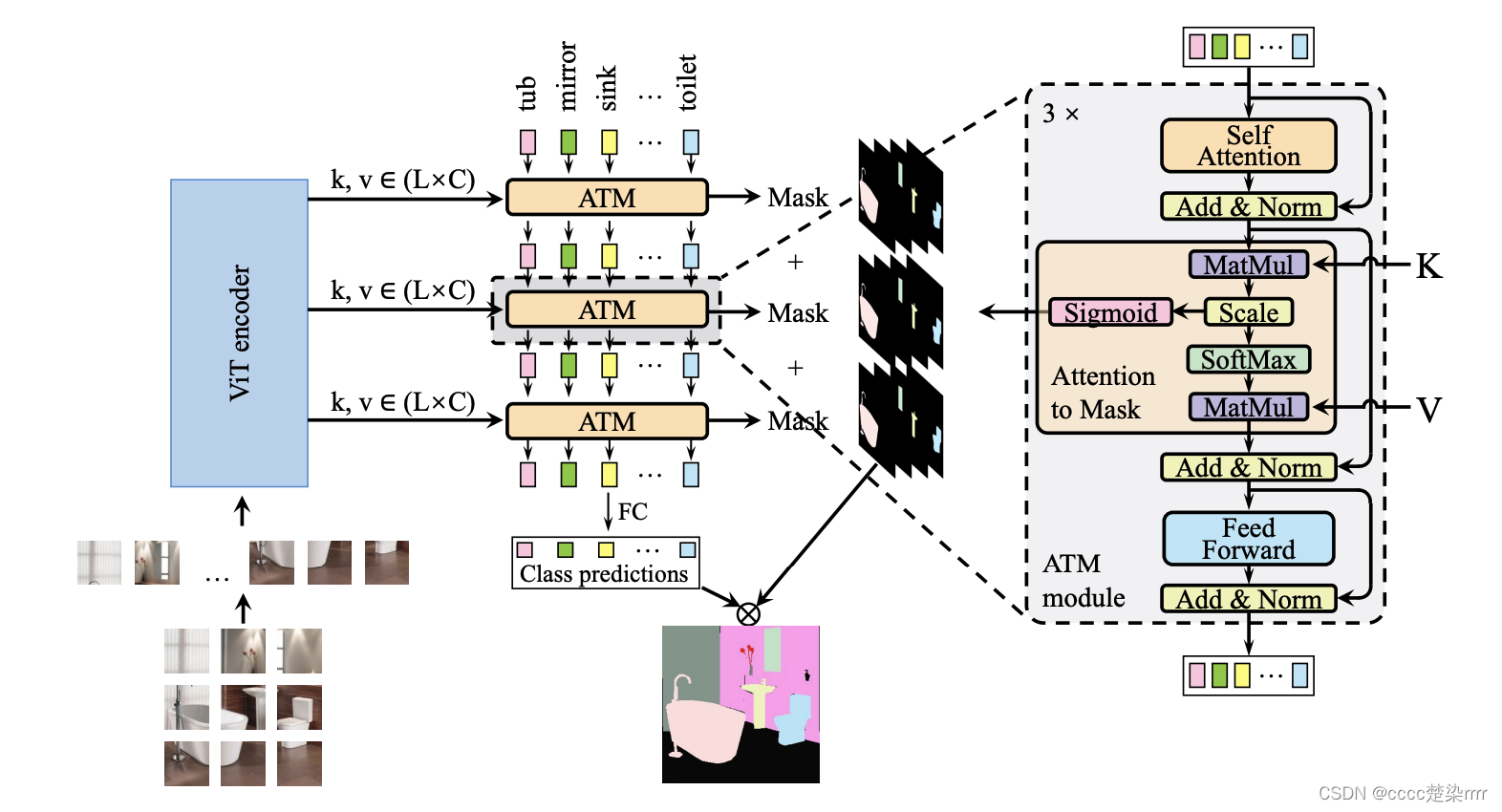
观察其代码得知所用backbone为vit_shrink,解码头为TPNATMHead:
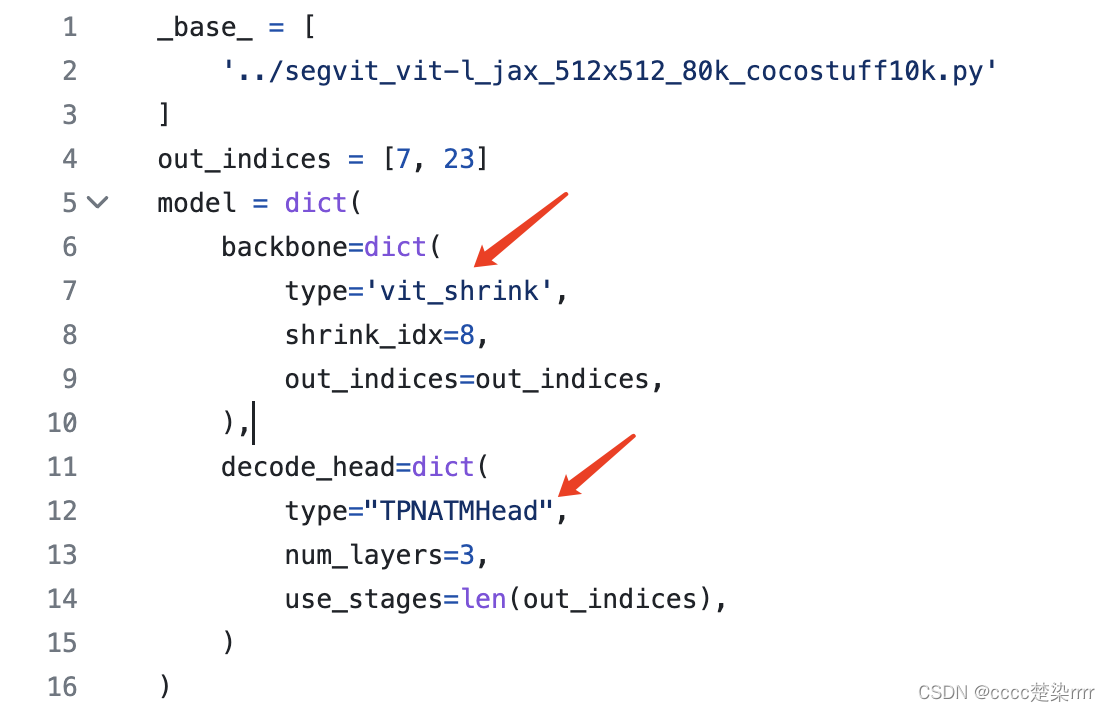
注意其中的参数设置,同时还要关注__base__的配置文件,其中的参数在模型声明的时候要输入进去。
找模型代码
进入backbone文件夹下找到vit_shrink网络:
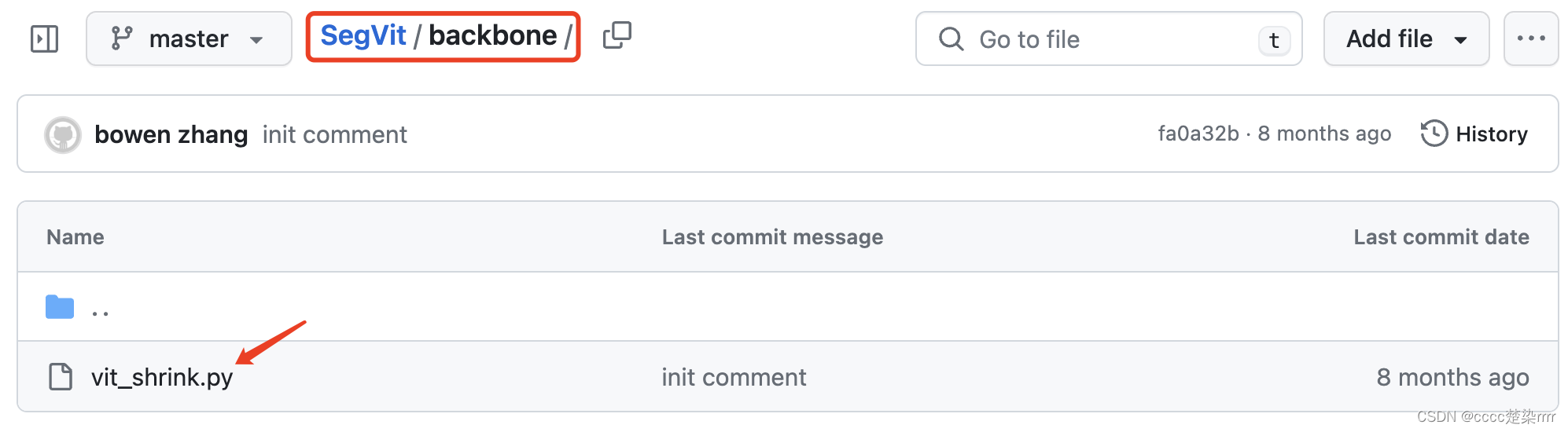
复制粘贴到自己的py文件中
在decode_heads文件夹下找到解码头代码:
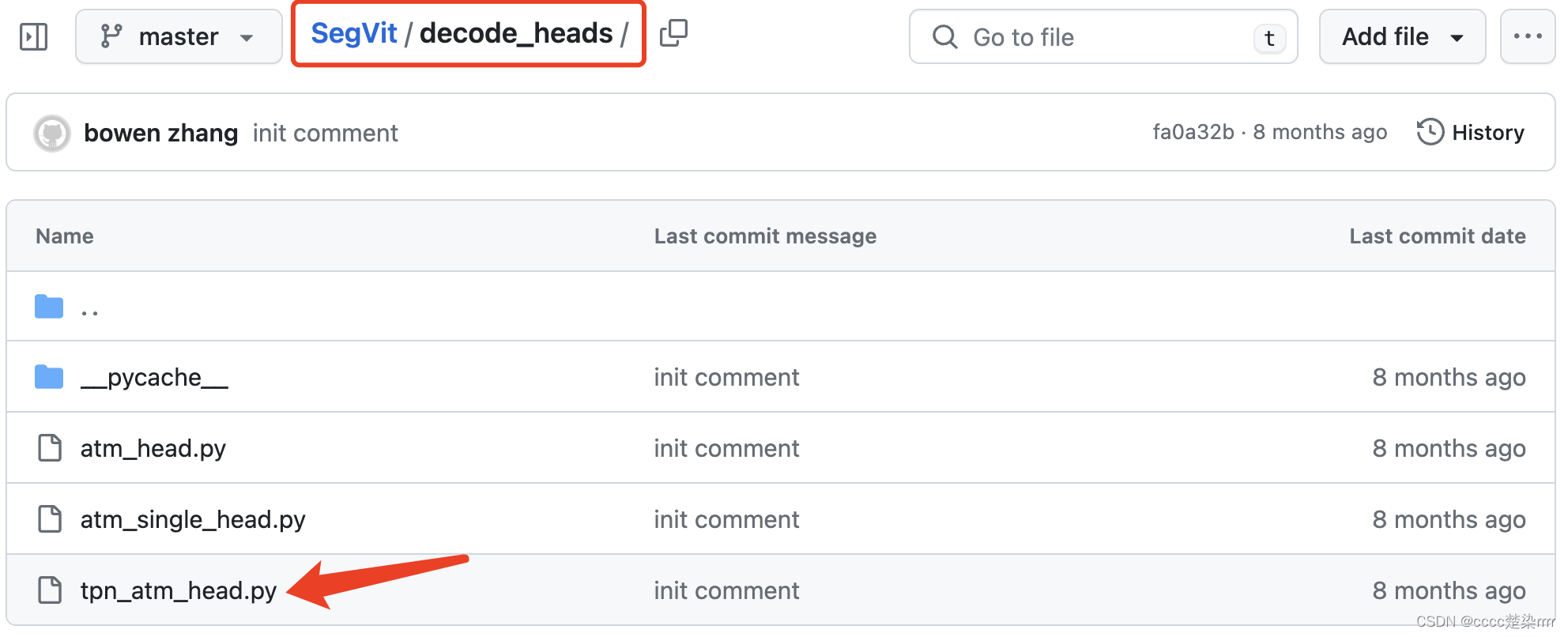
复制粘贴到自己的py文件中
对代码缝缝补补
- 补充库文件
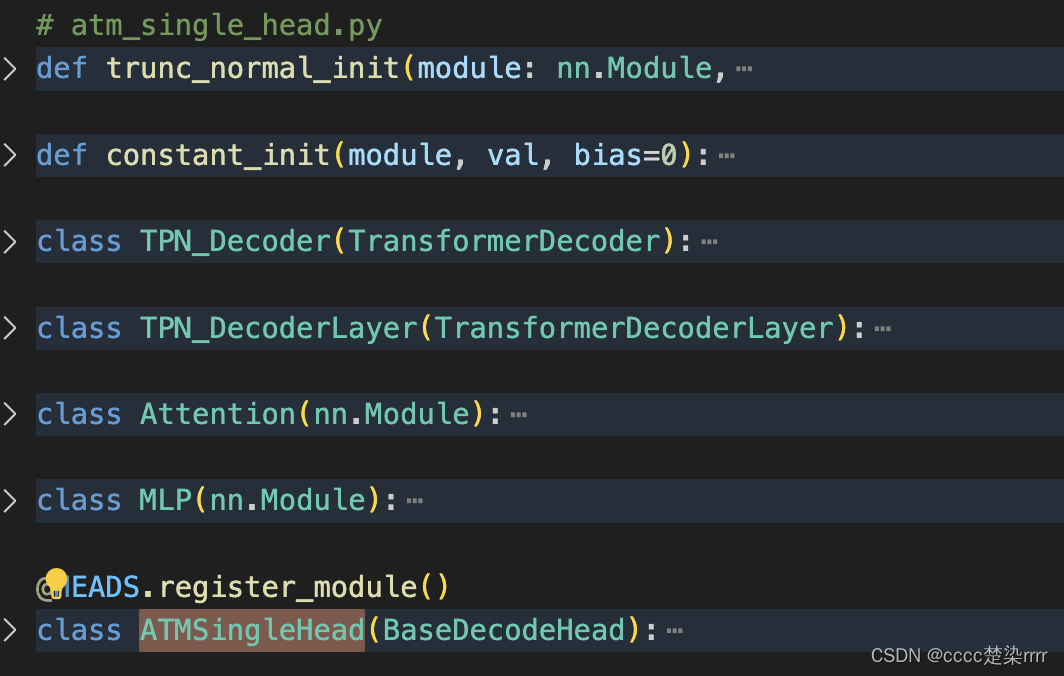
库文件缺什么补什么,例如在tpn_atm_head解码器代码中需要引用另外两个解码器代码中的内容,直接把另外两个解码器的代码ctrl C+V进来,将需要使用的模块留下来即可:
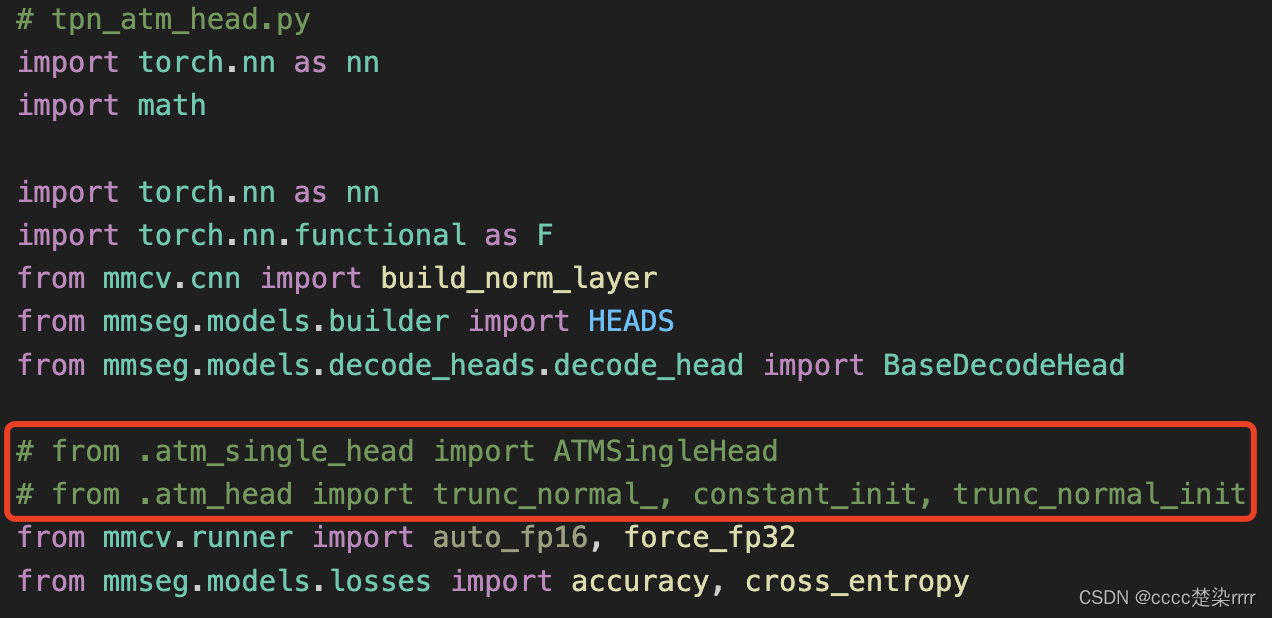
- 检查输入输出
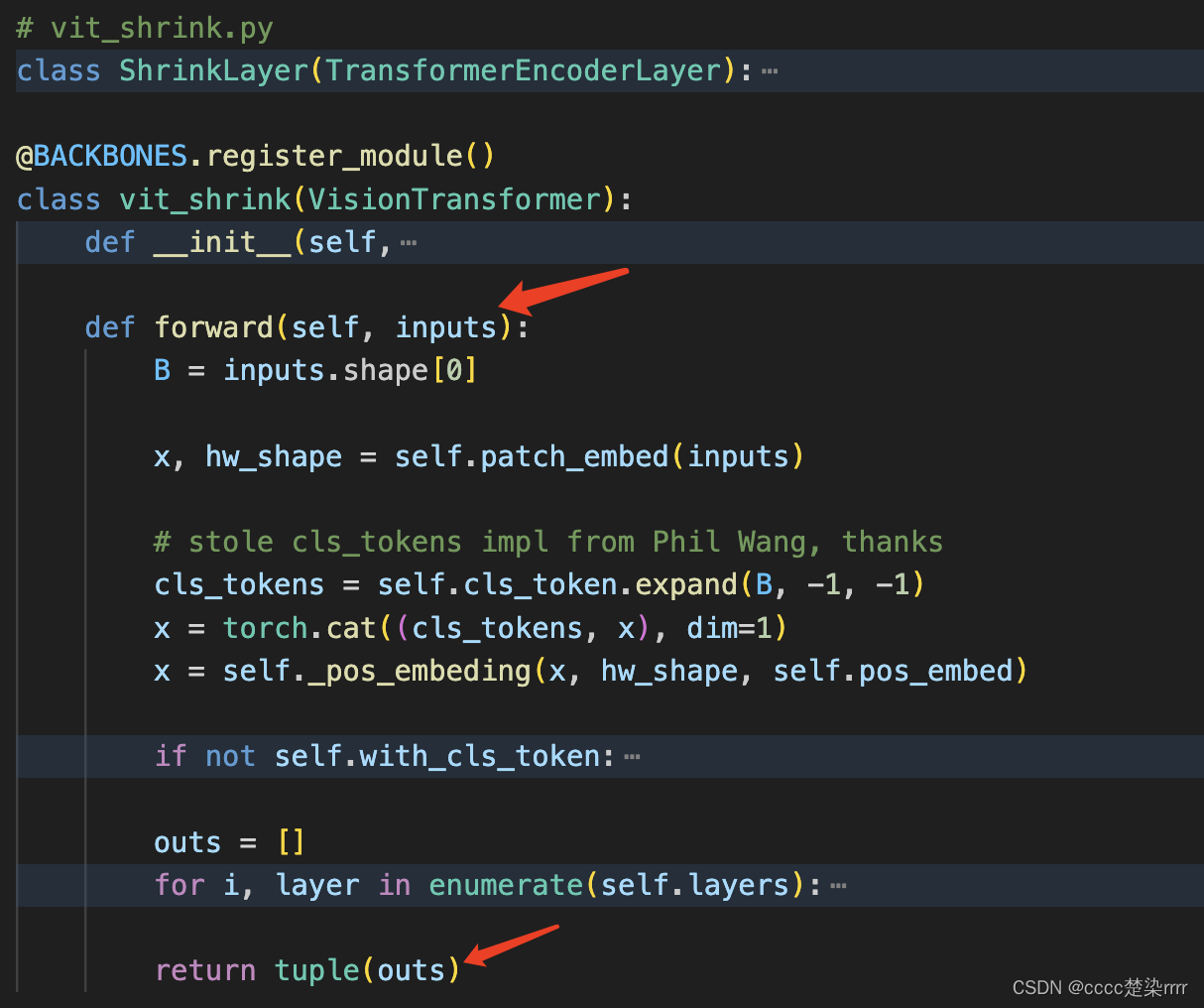
backbone的输入和输出:
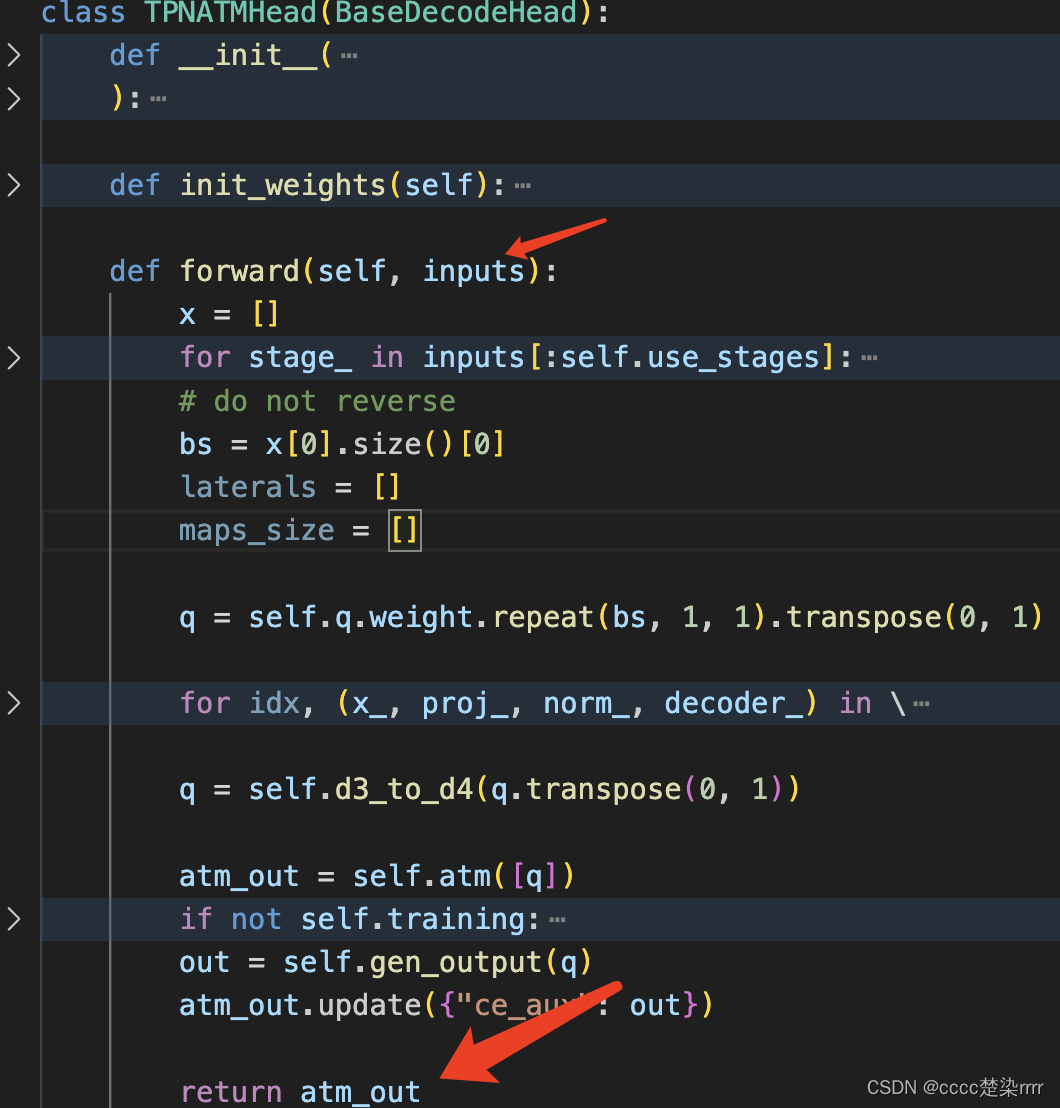
解码器部分的输入输出如图:
写一个SegViT来测试输入输出,注意参考配置文件将对应配置提前声明好:
class SegViT(nn.Module):
def __init__(self, num_class):
super(SegViT, self).__init__()
out_indices = [7,23]
in_channels = 1024
img_size = 512
# checkpoint = './pretrained/vit_large_p16_384_20220308-d4efb41d.pth'
checkpoint = 'https://download.openmmlab.com/mmsegmentation/v0.5/pretrain/segmenter/vit_large_p16_384_20220308-d4efb41d.pth'
# self.backbone = get_vit_shrink()
self.backbone = vit_shrink(
img_size=(img_size,img_size),embed_dims=in_channels,num_layers=24,drop_path_rate=0.3,num_heads=16,out_indices=out_indices)
self.decoder = TPNATMHead(
img_size=img_size,in_channels=in_channels,channels=in_channels,embed_dims=in_channels//2,num_heads=16,num_classes=num_class,num_layers=3, use_stages=len(out_indices))
def forward(self, _x):
x = self.backbone(_x)
out = self.decoder(x)
# if self.training:
# return out['pred'], out['ce_aux']
# else:
# return out
return out
运行检查out的类型
if __name__ == "__main__":
x = torch.randn(4, 3, 512, 512)
net = SegViT(6)
# flops, params = profile(net, (x,))
# print('flops: %.2f G, params: %.2f M' % (flops / 1000000000.0, params / 1000000.0))
# res, aux = net(x)
res = net(x)
print(res)
然后发现输出是一个字典类型,prediction是其中键名为pred对应的值,该值为tensor类型,shape大小为(4,6,512,512),输出正确。
接下来要找辅助分支的输出。
在解码器头的forward中发现:

将注释去掉,得到辅助分支的输出(会将辅助分支的输出结果以字典元素形式加入到atm_out中,可以调试看看),记得要把对应的初始化函数的注释也去掉:
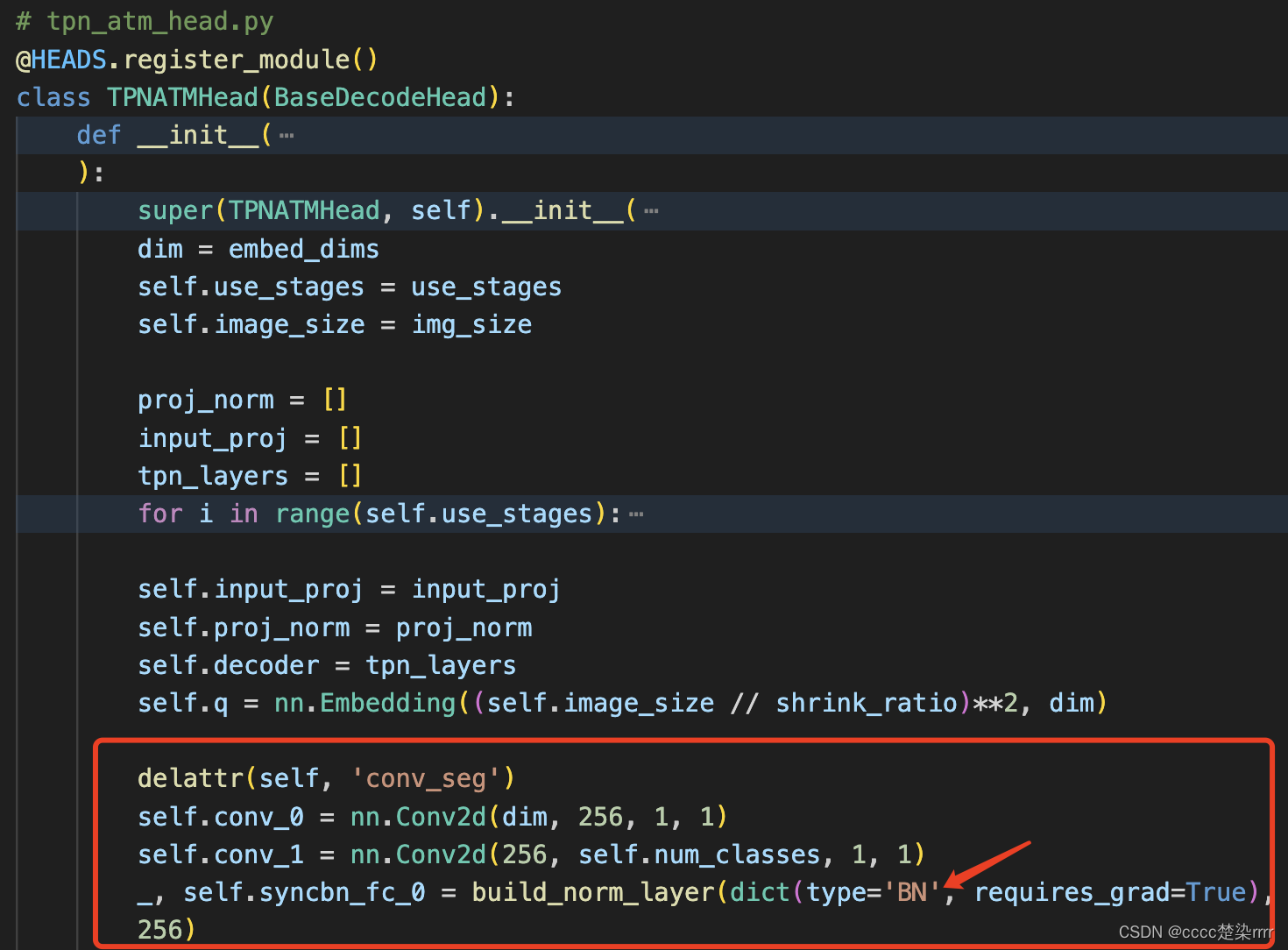
其中,由于我是单卡运行,于是把SyncBN改成了BN,否则报错。
另外,训练阶段和测试阶段的输出是不一样的,可以调试检查:
def forward(self, _x):
x = self.backbone(_x)
out = self.decoder(x)
if self.training:
return out['pred'], out['ce_aux']
else:
return out
- 加载权重文件
权重文件注意可以提前下载好
def get_vit_shrink(pretrained=True, img_size=512, in_channels=1024, out_indices=[7,23]):
model = vit_shrink(
img_size=(img_size,img_size),embed_dims=in_channels,num_layers=24,drop_path_rate=0.3,num_heads=16,out_indices=out_indices)
if pretrained:
checkpoint = '权重文件所在路径'
# if 'state_dict' in checkpoint: state_dict = checkpoint['state_dict']
# else: state_dict = checkpoint
model.load_state_dict(checkpoint, strict=False)
return model
最终的模型是:
class SegViT(nn.Module):
def __init__(self, num_class):
super(SegViT, self).__init__()
out_indices = [7,23]
in_channels = 1024
img_size = 512
# checkpoint = './pretrained/vit_large_p16_384_20220308-d4efb41d.pth'
# checkpoint = 'https://download.openmmlab.com/mmsegmentation/v0.5/pretrain/segmenter/vit_large_p16_384_20220308-d4efb41d.pth'
self.backbone = get_vit_shrink()
self.decoder = TPNATMHead(
img_size=img_size,in_channels=in_channels,channels=in_channels,embed_dims=in_channels//2,num_heads=16,num_classes=num_class,num_layers=3, use_stages=len(out_indices))
def forward(self, _x):
x = self.backbone(_x)
out = self.decoder(x)
if self.training:
return out['pred'], out['ce_aux']
else:
return out
- 检查最终的输入输出
结束。
3. 运行模型
在自己的框架里,配置参数,然后运行即可。
结束。