目录
学生课程类型选择影响因素分析
一、研究目的
二、数据来源和相关说明
三、描述性分析
3.1 样本描述
3.2 样本可视化
3.2.1 直方图
3.2.2 列联表
3.2.3 箱线图与折线图
3.2.4 相关性热力图
四、数学建模
4.1 无序多分类logistic回归模型
4.1.1 无序多分类logistic回归模型A
4.1.2 无序多分类logistic回归模型A优化
4.1.3 逐步回归模型C
4.1.4 逐步回归模型C预测
4.2 有序多分类logistics回归模型
4.2.1 模型建立
4.2.2 模型预测效果
五、结论
六、代码
学生课程类型选择影响因素分析
摘要:被调研学生中,一半以上学生高中时期选择了academic类型的课程,女学生略多于男学生,白人居多,社会地位中等人数占比约一半左右,大部分学生来自于公立学校。列联表检验结果得出,性别在所选课程类型上无显著性差异,而社会经济地位有显著性差异,其中社会地位高的学生更倾向于选择academic类型课程。由箱线图和折线图分析可知, academic、general和vocation类课程的数学和阅读成绩平均水平越来越低。由相关性热力图得出,五门课程成绩之间存在较显著的正相关关系。若认为三中课程类型无高低之分,建立的无序多分类回归模型经过变量选择,得出社会经济地位、学校类型、数学分数和社会学分数对高中生课程的选择具有显著性影响。以五门课程平均成绩代替五门课程成绩的模型效果比原模型效果差。根据建立的模型对ID为80的学生选择的课程类型进行预测时,得出此学生选择的课程类型为academic,预测结果正确。若认为三中课程类型有高低之分,建立的有序多分类回归模型经过变量选择,得出社会经济地位、学校类型、数学分数和社会学分数对高中生课程的选择具有显著性影响,与无序多分类回归模型结果一致。根据建立的模型对测试集进行预测,得到混淆矩阵,模型分类正确率为68.33%,模型预测效果良好。
一、研究目的
国家教育统计中心(NCES)的国家教育曾展开过一个纵向研究项目,收集了“高中及以后”研究的一个子集数据。数据包含了了高中生选择的课程类型(分为academic、vocation和general)和可能影响到课程选择的因素。本文欲基于此数据,探究哪些因素会影响到学生在高中学习的课程类型的选择。
二、数据来源和相关说明
数据来源于R语言faraway包中的hsb数据集,此数据集的调查变量包括学生ID,性别,民族,社会经济地位,学校类型,选择的高中课程类型,学生阅读、写作、数学、科学和社会学成绩等十一个变量,维度为200*11,变量具体含义与符号如表2-1所示。由于多分类变量纳入回归模型时需要拆成多个二分类变量,因而本文在表2-1中也列举了多分类变量拆成的二分类变量。
表2-1 变量说明
| 变量 | 含义 | 解释 | 符号 |
| prog | 选择的高中课程类型 | academic-1;general-2;vocation-3 | Y |
| gender | 性别 | 0-男;1-女 | X1 |
| race | 民族 | african-amer-1;asian-2;hispanic-3;white-4 | X2 |
| race1 | 是否是亚洲人 | 0-否;1-是 | X21 |
| race2 | 是否是西班牙人 | 0-否;1-是 | X22 |
| race3 | 是否是白人 | 0-否;1-是 | X23 |
| ses | 社会经济地位 | high-3;middle-2;low-1 | X3 |
| ses1 | 社会地位是否低下 | 0-1否;1-是 | X31 |
| ses2 | 社会地位是否中等 | 0-否;1-是 | X32 |
| schtyp | 学校类型 | private-0;public-1 | X4 |
| read | 阅读分数 | 连续变量 | X5 |
| write | 写作分数 | 连续变量 | X6 |
| math | 数学分数 | 连续变量 | X7 |
| science | 科学分数 | 连续变量 | X8 |
| socst | 社会学分数 | 连续变量 | X9 |
| id | 学生号码 | 学生身份证明 | —— |
三、描述性分析
为了获得对数据的整体了解,本文先对数据进行了描述性统计分析。
3.1 样本描述
10个变量中,5个变量是分类型变量,5个变量时连续性变量。对于分类型变量,统计各个类别出现的百分比,结果如表3-1所示;对于连续型变量,统计其最值、平均值和中位数,结果如表3-2所示。
表3-1 分类型变量样本描述
| 变量 | 因子 | 数值 | 百分比 |
| prog | academic | 105 | 52.50% |
| general | 45 | 22.50% | |
| vocation | 50 | 25.00% | |
| gender | female | 109 | 54.50% |
| male | 91 | 45.50% | |
| race | african-amer | 20 | 10.00% |
| asian | 11 | 5.50% | |
| hispanic | 24 | 12.00% | |
| white | 145 | 72.50% | |
| ses | high | 58 | 29.00% |
| low | 47 | 23.50% | |
| middle | 95 | 47.50% | |
| schtyp | private | 32 | 16.00% |
| public | 168 | 84.00% |
由表3-1可以得出:200个学生中,有52.50%个选择了学术型课程,22.50%个选择了通用型课程,25.00%个学生选择了职业型课程;性别中,男性占比45.50%,女性占比54.50%,女性略多于男性;种族中,白人人多最多,占比72.50%,其次为西班牙人、非洲裔美国人和亚洲人,分别占比12.00%、10.00%和5.50%;社会地位中,中等人群人数最多,占比47.50%,其次为高等人群和低等人群,分别占比29.00%和23.50%;学校类型中,公立学校人数最多,占比84.00%,私立学校占比相对较少,仅占16.00%。
表3-2 连续性变量样本描述
| 变量 | Min | Max | Median | Mean |
| read | 1.20 | 76.00 | 50.00 | 52.23 |
| write | 3.00 | 67.00 | 54.00 | 52.77 |
| math | 1.00 | 75.00 | 52.00 | 52.65 |
| science | 2.15 | 74.00 | 53.00 | 51.85 |
| socst | 10.80 | 71.00 | 52.00 | 52.41 |
由表3-2可以得出:阅读成绩介于1.20-76.00之间,其平均水平为52.23(平均值)和50.00(中位数);写作成绩介于3.00-67.00之间,其平均水平为52.77(平均值)和54.00(中位数);数学成绩介于1.00-75.00之间,其平均水平为52.65(平均值)和52.00(中位数);科学成绩介于2.15-74.00之间,其平均水平为51.85(平均值)和53.00(中位数);社会学成绩介于10.80-71.00之间,其平均水平为52.41(平均值)和52.00(中位数)。从均值意义上看,写作成绩最好,其次是数学成绩,科学成绩最差。
3.2 样本可视化
3.2.1 直方图
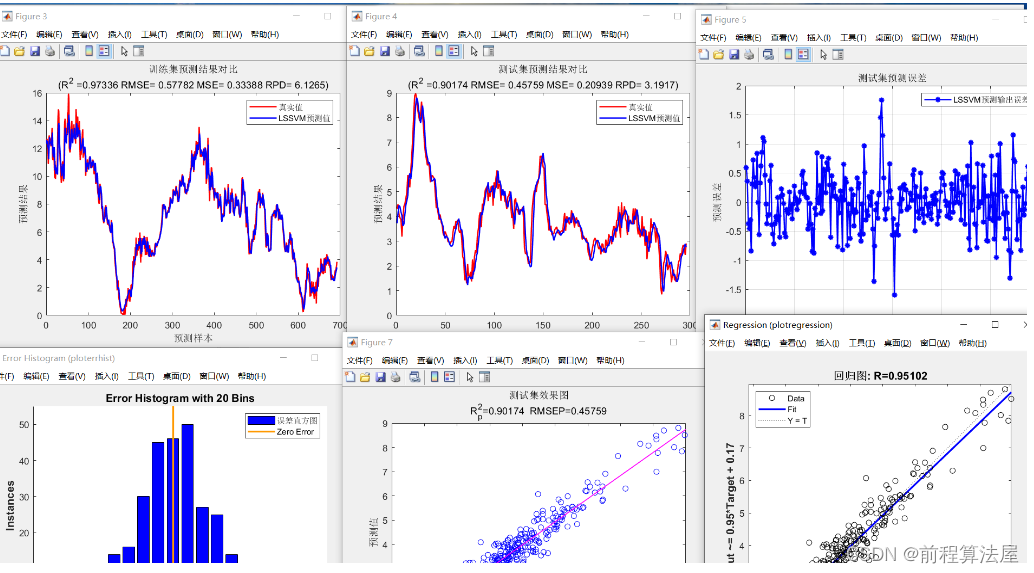
为了得到连续型变量的整体分布状况,本文绘制了直方图,结果如图3-1所示。
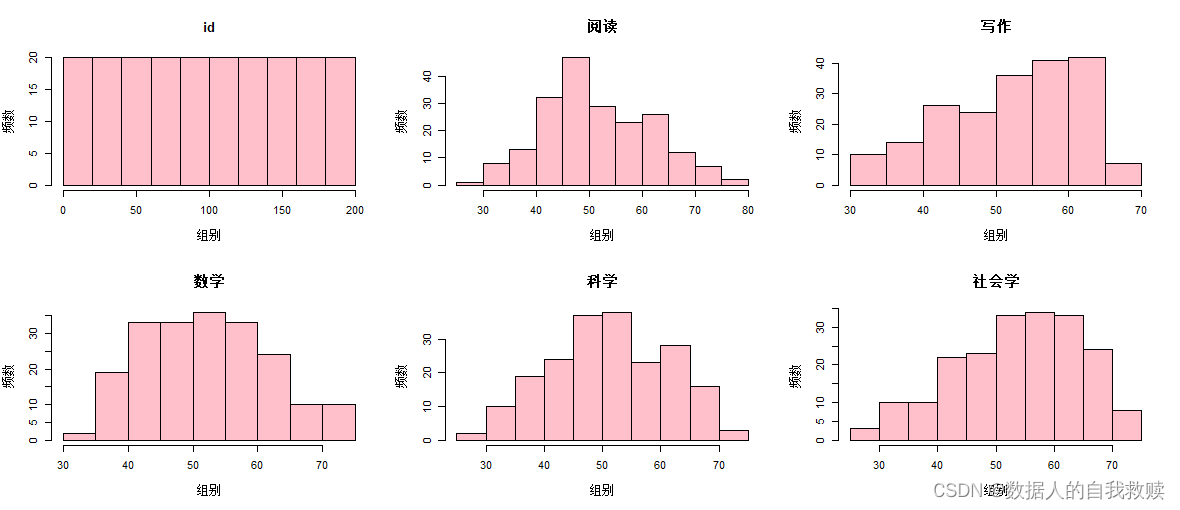
图3-1 连续型变量直方图
由图3-1可以得出:阅读成绩整体上呈现正态分布,成绩主要集中在40-65之间,其中45-50之间频数最高;写作成绩整体上呈现左偏分布,成绩也主要集中在40-65之间,其中60-65之间频数最高;数学成绩整体上呈现均匀分布,成绩主要集中在35-65之间,其中50-55之间频数最高;科学成绩整体上呈现正态分布,成绩主要集中在35-70之间,其中50-55之间频数最高;社会学成绩整体上呈现左偏分布,成绩主要集中在40-70之间,其中55-60之间频数最高。
3.2.2 列联表
为了探究性别和社会经济地位是否会对学生课程类型的选择产生影响,考虑到变量均为分类型变量,因而本文采用了列联表分析法,结果分别如表3-3和表3-4所示。
表3-3 性别-课程类型列联表1
| gender\prog | academic | general | vocation |
| female | 58 | 24 | 27 |
| male | 47 | 21 | 23 |
| chisq.test | p-value=0.9739 | ||
由表3-3可以得出:女性中,选择academic类课程人数最多,其次是vocation,最后是general,人数分别为58、27和24;男性中,选择academic类课程人数最多,其次是vocation,最后是general,人数分别为47、21和23。从选择课程类型分布上看,男性与女性差别不大,这从卡方检验P值也可以得出,P值>0.05,即无法拒绝原假设,认为男性与女性所选课程类型分布无显著差异。
表3-4 社会经济地位-课程类型列联表2
| ses\prog | academic | general | vocation |
| high | 42 | 9 | 7 |
| low | 19 | 16 | 12 |
| middle | 44 | 20 | 31 |
| kruskal.test | p-value=0.009 | ||
由表3-4可以得出:社会地位高人群中,绝大多数人选择了academic类课程,只有少部分人选择了general和vocation,人数分别为42、9和7;社会地位中等的人群中,选择academic类课程人数最多,其次是vocation,最后是general,人数分别为44、31和20;社会地位低等人群中,选择三类课程人数相差不大,人数从高到低分别为19、16和12。直观上看,三个社会地位人群选择课程人群存在差异。由于社会经济地位是有序分组变量,因而本文采用了秩和检验,又因为是多组,因此采用Kruskal-Wallis H检验。检验P值<0.05,即不同社会经济地位人群选择课程类型确实存在显著性差异。
3.2.3 箱线图与折线图
为了探究学生的数学成绩和阅读成绩在课程选择上是否存在差异性,本文选择了箱线图和折线图进行分析,结果如图3-2和图3-3所示。
图3-2 数学成绩-课程类型箱线图
由图3-2可以得出:从中位数意义上看,三种类型课程在数学成绩上存在较显著的差异性,学术型类型学生数学成绩最高,其次为通用类类型,职业型类型学生数学成绩最低;从最大值看,三种类型由高到低分别是学术性、职业型和通用型。综上所述,三个类型的数学成绩存在一定的差异性,其中学术型类型的学生数学成绩最好。
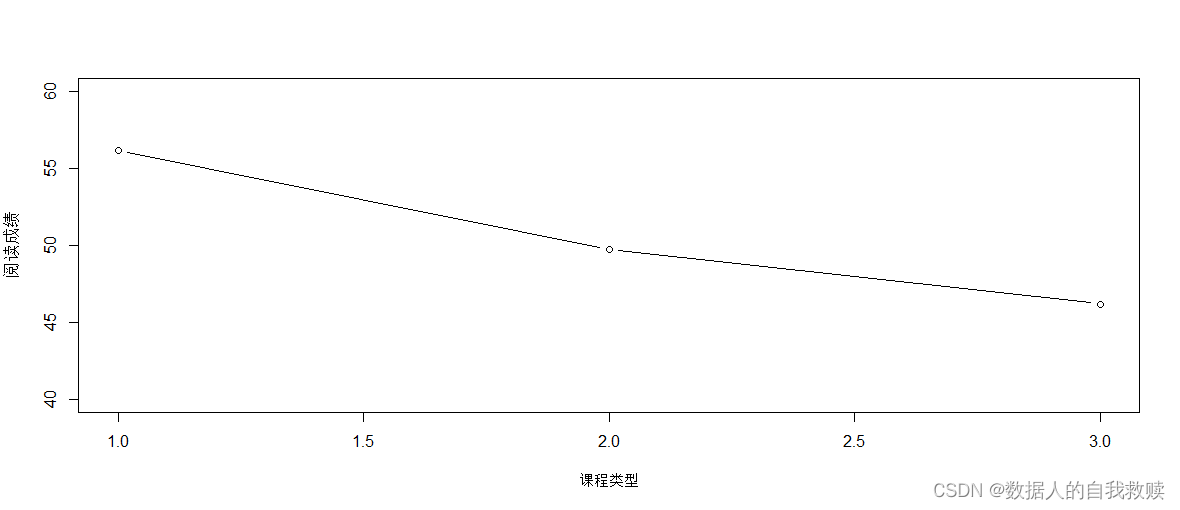
图3-3 阅读成绩-课程类型折线图
由图3-3可以得出:1代表学术型课程,2代表通用型课程,3代表职业型课程;从折线走势上看,呈现递减趋势,即学术型类型学生阅读成绩均分最高,其次为通用型类型,职业型类型阅读平均成绩最低;其中,学术型类型与其他两个类型差别较大,而通用型与职业型差别较小。
3.2.4 相关性热力图
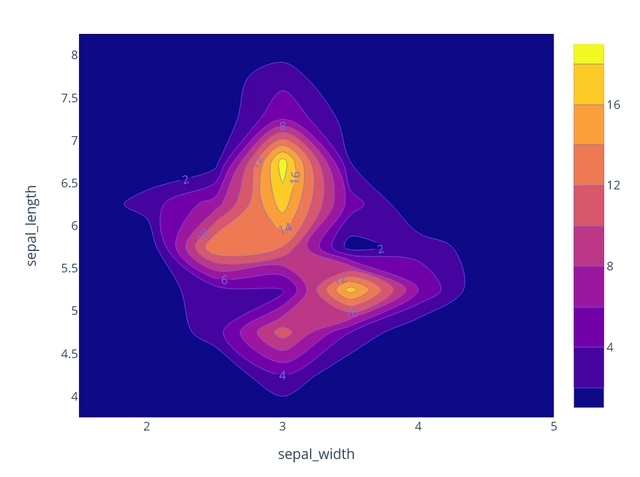
为了探究五门科目成绩之间的线性相关性,本文绘制了相关性热力图,结果如图3-4所示。
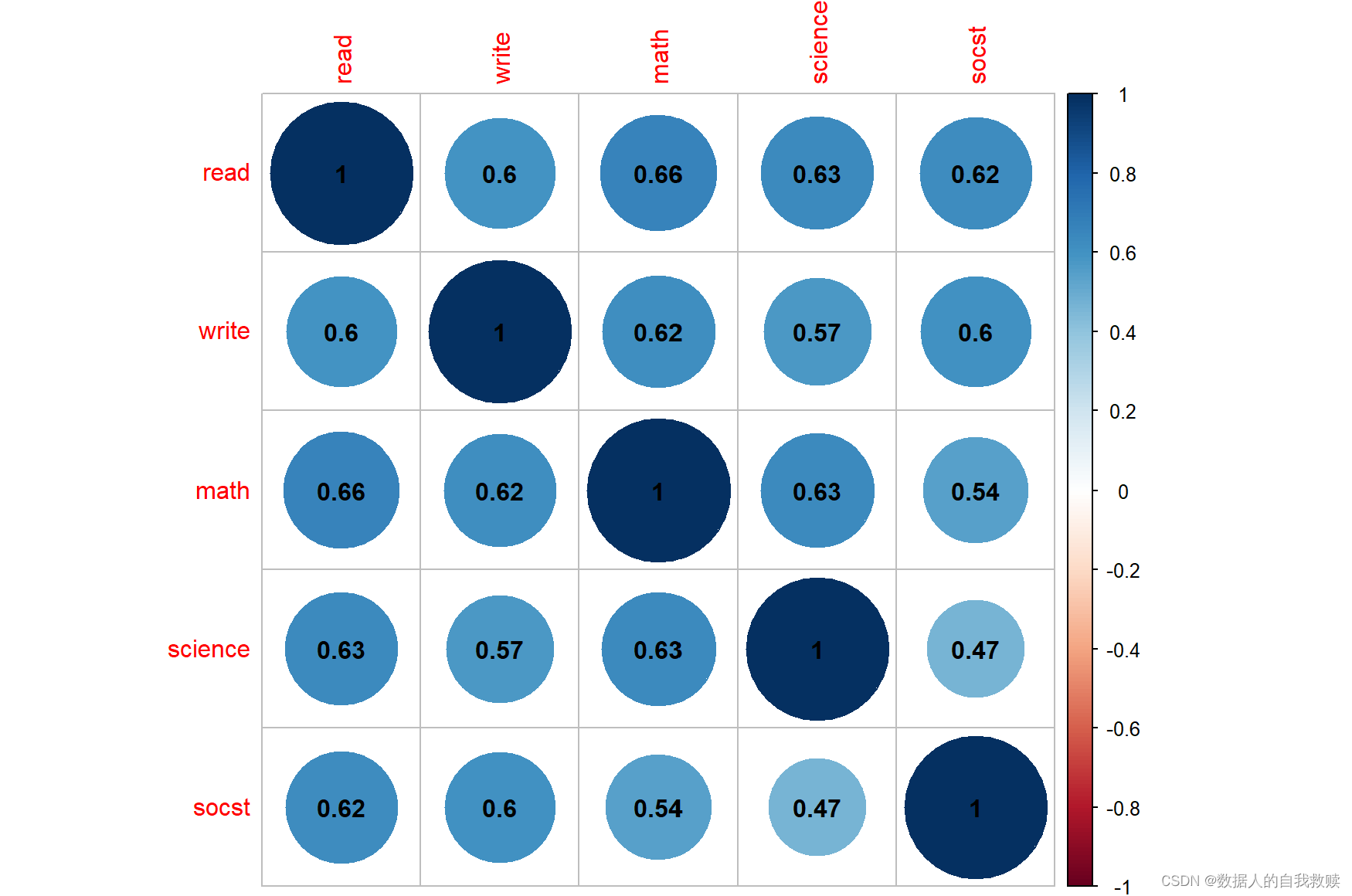
图3-4 五门科目成绩相关性热力图
由图3-4可以得出:大部分科目成绩之间的相关性介于0.5-0.7之间,属于显著正相关关系,因而后续建模分析时可以考虑以五门科目的平均成绩代替五门成绩进行建模分析。
四、数学建模
为了探究高中生选择课程的影响因素,本文建立了多个回归模型。若认为三种课程类型无高低之分,可建立无序多分类logistic回归模型,进而进行变量筛选与预测;若认为三种类型有高低之分时,可建立有序多分类logistic回归模型,进而进行变量筛选与预测。
4.1 无序多分类logistic回归模型
4.1.1 无序多分类logistic回归模型A
以academic作为参照水平,建立无序多分类logistic回归模型A,由于课程类型有三个类别,因而有两个回归模型,回归模型表达式如下。
Y1=logit(P)general/academic=α1+β11X1+β121X21+β122X22+β123X23+β131X31+β132X32+β14X4+β15X5+β16X6+β17X7+β18X8+β19X9
Y2=logit(P)vocation/academic=α2+β21X1+β221X21+β222X22+β223X23+β231X31+β232X32+β24X4+β25X5+β26X6+β27X7+β28X8+β29X9
以极大似然法进行参数估计,同时将模型A与空模型相比较,得到模型整体的显著性,模型A参数估计结果如表4-1所示。
表4-1 无序多分类logistic回归模型A参数估计
|
| general | OR值 | P值 | vocation | OR值 | P值 |
| (Intercept) | 3.6319 | 37.7846 | 0.0464 | 7.4814 | 1774.6899 | 0.0004 |
| X1 | -0.0926 | 0.9115 | 0.8386 | -0.3210 | 0.7254 | 0.5226 |
| X21 | 1.3527 | 3.8680 | 0.2014 | -0.7001 | 0.4966 | 0.6339 |
| X22 | -0.6322 | 0.5314 | 0.4792 | -0.1994 | 0.8193 | 0.8123 |
| X23 | 0.2965 | 1.3452 | 0.6868 | 0.3359 | 1.3992 | 0.6534 |
| X31 | 1.0986 | 3.0001 | 0.0702 | 0.0475 | 1.0486 | 0.9463 |
| X32 | 0.7030 | 2.0197 | 0.1636 | 1.1816 | 3.2595 | 0.0382 |
| X4 | 0.5845 | 1.7942 | 0.3003 | 2.0553 | 7.8094 | 0.0138 |
| X5 | -0.0442 | 0.9568 | 0.1546 | -0.0348 | 0.9658 | 0.3091 |
| X6 | -0.0363 | 0.9644 | 0.2834 | -0.0317 | 0.9688 | 0.3773 |
| X7 | -0.1093 | 0.8965 | 0.0019 | -0.1140 | 0.8923 | 0.0033 |
| X8 | 0.1019 | 1.1073 | 0.0018 | 0.0523 | 1.0537 | 0.1267 |
| X9 | -0.0198 | 0.9804 | 0.4661 | -0.0804 | 0.9227 | 0.0062 |
| P 值 | <0.001 | |||||
由表4-1可以得出:由模型整体检验P值<0.001得出模型A具有统计学意义,可以进行进一步分析。根据系数估计结果,可以得到Y1 、Y2 的表达式,如下所示。
Y1=3.6319-0.0926X1+1.3527X21-0.6322X22+0.2965X23+1.0986X31+0.7030X32+0.5845X4-0.0442X5-0.0363X6-0.1093X7+0.1019X8-0.0198X9
Y2=7.4841-0.3210X1-0.7001X21-0.1994X22+0.3359X23+0.0475X31+1.1816X32+2.0553X4-0.0348X5-0.0317X6-0.1140X7+0.0523X8-0.0804X9
由表4-1和上述表达式可以得出:
(1)在显著性水平α=0.05 下,对回归模型一(Y1 )而言,有如下结论:
- 在general和academic之间进行选择时,只有变量X7 和X8 显著。
- X1 (性别)的回归系数为-0.0926,OR值为0.9115,即性别会对课程选择产生非显著的负向影响关系,说明相对于女同学,男同学更倾向于academic类课程。
- X21 的回归系数为1.3527,OR值为3.8680,即是否是亚洲人会对课程选择产生非显著的正向影响关系,说明相对于非洲裔美国人,亚洲人更倾向于general类课程。
- X22 的回归系数为-0.6322,OR值为0.5314,即是否是西班牙人会对课程选择产生非显著的负向影响关系,说明相对于非洲裔美国人,西班牙人更倾向于academic类课程。
- X23 的回归系数为0.2965,OR值为1.3452,即会对课程选择产生非显著的正向影响关系,说明相对于非洲裔美国人,白人更倾向于general类课程。
- X31 的回归系数为1.0986,OR值为3.0001,即社会地位是否低下会对课程选择产生非显著的正向影响关系,说明相对于社会高等人群,社会地位低等人群更倾向于general类课程。
- X32 的回归系数为0.7030,OR值为2.0197,即社会地位是否中等会对课程选择产生非显著的正向影响关系,说明相对于社会地位高等人群,社会地位中等人群更倾向于general类课程。
- X4 的回归系数为0.5845,OR值为1.7942,即学校类型会对课程选择产生非显著的正向影响关系,说明相对于私立学校,公立学校更倾向于academic类课程。
- X5 的回归系数为-0.0442,OR值为0.9568,即阅读分数会对课程选择产生非显著的负向影响关系,说明其他变量不变时,阅读分数每增加一分,选择general的概率与选择academic概率之比会变为原来的0.9568倍。
- X6 的回归系数为-0.0363,OR值为0.9644,即写作分数会对课程选择产生非显著的负向影响关系,说明其他变量不变时,写作分数每增加一分,选择general的概率与选择academic概率之比会变为原来的0.9644倍。
- X7 的回归系数为-0.1093,OR值为0.8965,即数学分数会对课程选择产生显著的负向影响关系,说明其他变量不变时,数学分数每增加一分,选择general的概率与选择academic概率之比会变为原来的0.8965倍。
- X8 的回归系数为0.1019,OR值为1.1073,即科学分数会对课程选择产生显著的正向影响关系,说明其他变量不变时,科学分数每增加一分,选择general的概率与选择academic概率之比会变为原来的1.1073倍。
- X9 的回归系数为-0.0198,OR值为0.9804,即社会学分数会对课程选择产生非显著的负向影响关系,说明其他变量不变时,社会学分数每增加一分,选择general的概率与选择academic概率之比会变为原来的0.9804倍。
(2)在显著性水平α=0.05 下,对回归模型二(Y2 )而言,有如下结论:
- 在vocation和academic之间进行选择时,变量X3 、X4 、X7 和X9 显著;
- X1 (性别)的回归系数为-0.3210,OR值为0.7254,即性别会对课程选择产生非显著的负向影响关系,说明相对于女同学,男同学更倾向于academic类课程。
- X21 的回归系数为-0.7001,OR值为0.4966,即是否是亚洲人会对课程选择产生非显著的负向影响关系,说明相对于非洲裔美国人,亚洲人更倾向于vocation类课程。
- X22 的回归系数为-0.1994,OR值为0.8193,即是否是西班牙人会对课程选择产生非显著的负向影响关系,说明相对于非洲裔美国人,西班牙人更倾向于academic类课程。
- X23 的回归系数为0.3359,OR值为1.3992,即会对课程选择产生非显著的正向影响关系,说明相对于非洲裔美国人,白人更倾向于vocation类课程。
- X31 的回归系数为0.0475,OR值为1.0486,即社会地位是否低下会对课程选择产生非显著的正向影响关系,说明相对于社会高等人群,社会地位低等人群更倾向于vocation类课程。
- X32 的回归系数为1.1816,OR值为3.2595,即社会地位是否中等会对课程选择产生显著的正向影响关系,说明相对于社会地位高等人群,社会地位中等人群更倾向于vocation类课程。
- X4 的回归系数为2.0553,OR值为7.8094,即学校类型会对课程选择产生显著的正向影响关系,说明相对于私立学校,公立学校更倾向于academic类课程。
- X5 的回归系数为-0.0348,OR值为0.9658,即阅读分数会对课程选择产生非显著的负向影响关系,说明其他变量不变时,阅读分数每增加一分,选择vocation的概率与选择academic概率之比会变为原来的0.9568倍。
- X6 的回归系数为-0.0317,OR值为0.9688,即写作分数会对课程选择产生非显著的负向影响关系,说明其他变量不变时,写作分数每增加一分,选择vocation的概率与选择academic概率之比会变为原来的0.9644倍。
- X7 的回归系数为-0.1140,OR值为0.8923,即数学分数会对课程选择产生显著的负向影响关系,说明其他变量不变时,数学分数每增加一分,选择vocation的概率与选择academic概率之比会变为原来的0.8965倍。
- X8 的回归系数为0.0523,OR值为1.0537,即科学分数会对课程选择产生非显著的正向影响关系,说明其他变量不变时,科学分数每增加一分,选择vocation的概率与选择academic概率之比会变为原来的1.1073倍。
- X9 的回归系数为-0.0804,OR值为0.9227,即社会学分数会对课程选择产生显著的负向影响关系,说明其他变量不变时,社会学分数每增加一分,选择vocation的概率与选择academic概率之比会变为原来的0.9804倍。
4.1.2 无序多分类logistic回归模型A优化
由于五门科目之间存在较显著的线性相关性,因而考虑用五门科目的均值替代五门科目成绩进行建模,得到模型B,比较两个模型之间的AIC值,结果如表4-2所示。
表4-2 模型A与模型B的AIC值比较
|
| 模型A | 模型B |
| AIC | 357.8705 | 364.6081 |
由表4-2可以得出,AIC值越小,表明模型拟合效果越好,因而模型A效果更好,本文基于模型A进行后续分析。
4.1.3 逐步回归模型C
在无序多分类logistic回归模型中,很多变量对高中生课程选择不存在显著影响,因而考虑根据AIC准则建立逐步回归模型C,对变量进行选择,逐步回归模型C参数估计结果如表4-3所示。
表4-3 逐步回归模型C参数估计
|
| general | OR值 | P值 | vocation | OR值 | P值 |
| (Intercept) | 2.5870 | 13.2902 | 0.1250 | 6.6873 | 802.1308 | 0.0006 |
| X31 | 0.8761 | 2.4015 | 0.1282 | -0.0157 | 0.9844 | 0.9813 |
| X32 | 0.6979 | 2.0095 | 0.1569 | 1.2065 | 3.3418 | 0.0303 |
| X4 | 0.6469 | 1.9096 | 0.2358 | 1.9956 | 7.3563 | 0.0141 |
| X7 | -0.1212 | 0.8858 | 0.0002 | -0.1370 | 0.8720 | 0.0001 |
| X8 | 0.0821 | 1.0856 | 0.0032 | 0.0394 | 1.0402 | 0.1689 |
| X9 | -0.0444 | 0.9566 | 0.0582 | -0.0936 | 0.9106 | 0.0003 |
| P 值 | <0.001 | |||||
由表4-3可以得出:逐步回归模型C整体P值<0.001,因而模型存在统计学意义;根据模型参数估计结果,可以得到模型表达式,如下所示;逐步回归模型保留了变量X31 、X32 、X4 、X7 、X8 和X9 ,其中只有变量X31 和X8 不显著,其他变量均显著,即社会经济地位、学校类型、数学分数和社会学分数对高中生课程的选择有显著影响。
Y1=2.5870+0.8761X31+0.6979X32+0.6469X4-0.1212X7+0.0821X8-0.0444X9
Y2=6.6873-0.0157X31+1.2065X32+1.9956X4-0.1370X7+0.0394X8-0.0936X9
4.1.4 逐步回归模型C预测
为了得到逐步回归模型C的预测效果,本文对ID为80的学生高中选择的课程类型进行预测,预测结果如表4-4所示。
表4-4 ID为80的学生预测结果
| Y1 | Y2 | exp(Y1) | exp(Y2) | academic | general | vocation | |
| 预测值 | -2.5195 | -0.0672 | 0.0805 | 0.9350 | 0.4962 | 0.0399 | 0.4639 |
由表4-4可以得出:ID为80的学生选择academic、general和vocation类型的概率分别为0.4963、0.0399和0.4639,因而最终将ID为80的学生判为选择academic类型课程,预测结果正确。
4.2 有序多分类logistics回归模型
4.2.1 模型建立
若认为三种课程类型有高低之分,即academic>general>vocation,则可以建立有序多分类回归模型。为了对模型预测效果进行评估,本文将hsb数据集随机打乱,并以前70%作为训练集训练模型,以后30%作为测试集对模型预测结果进行评估。为了对自变量进行筛选,本文基于AIC准备建立了逐步回归模型,模型预测结果如表4-5所示。
表4-5 有序多分类回归logistic模型D与逐步回归模型E参数估计
|
| 有序多分类回归模型D | 逐步回归模型E | ||||
| 变量 | estimate | P值 | OR值 | estimate | P值 | OR值 |
| X1 | -0.0427 | 0.9164 | 0.9582 | —— | —— | —— |
| X21 | -0.3402 | 0.7224 | 0.7117 | —— | —— | —— |
| X22 | 0.4200 | 0.5624 | 1.5220 | —— | —— | —— |
| X23 | 0.4340 | 0.4764 | 1.5434 | —— | —— | —— |
| X31 | 0.2636 | 0.6191 | 1.3015 | 0.1672 | 0.7448 | 1.1820 |
| X32 | 1.0926 | 0.0205 | 2.9820 | 1.0612 | 0.0218 | 2.8898 |
| X4 | 1.2321 | 0.0368 | 3.4284 | 1.1860 | 0.0356 | 3.2739 |
| X5 | -0.0343 | 0.2010 | 0.9663 | —— | —— | —— |
| X6 | -0.0121 | 0.6852 | 0.9880 | —— | —— | —— |
| X7 | -0.0807 | 0.0046 | 0.9225 | -0.0870 | 0.0003 | 0.9167 |
| X8 | 0.0223 | 0.4380 | 1.0225 | —— | —— | —— |
| X9 | -0.0500 | 0.0490 | 0.9512 | -0.0598 | 0.0035 | 0.9419 |
| academic|general | -6.2560 | 0.0001 | 0.0019 | -6.2511 | 0.0000 | 0.0019 |
| general|vocation | -4.5932 | 0.0041 | 0.0101 | -4.6234 | 0.0015 | 0.0098 |
| P值 | <0.001 | <0.001 | ||||
由表4-5可以得出:有序多分类回归模型D和逐步回归模型E的整体P值均<0.001,因而两个模型均具有统计学意义。由于模型D很多变量在统计学意义上不显著,因而考虑对逐步回归模型E进行解读,并进行后续分析。逐步回归模型E参数估计结果解读如下:
- 逐步回归模型E保留了变量X31 、X32 、X4 、X7 和X9 ,其中只有变量X31 不显著,其他变量均显著。
- X31 的回归系数为0.1672,OR值为1.1820,即社会地位是否低下会对课程选择产生非显著的正向影响关系,说明相对于社会高等人群,社会地位低等人群更倾向于高等类型课程。
- X32 的回归系数为1.0612,OR值为2.8898,即社会地位是否中等会对课程选择产生显著的正向影响关系,说明相对于社会地位高等人群,社会地位中等人群更倾向于高等类课程。
- X4 的回归系数为1.1860,OR值为3.2739,即学校类型会对课程选择产生显著的正向影响关系,说明相对于私立学校,公立学校更倾向于高等类课程。
- X7 的回归系数为-0.0870,OR值为0.9167,即数学分数会对课程选择产生显著的负向影响关系,说明其他自变量不变时,数学分数每增加一分,选择课程类型增加一个及一个等级以上的优势增加到原来的0.9167倍。
- X9 的回归系数为-0.0598,OR值为0.9419,即社会学分数会对课程选择产生显著的负向影响关系,说明其他变量不变时,社会学分数每增加一分,选择程类型增加一个及一个等级以上的优势增加到原来的0.9419倍。
4.2.2 模型预测效果
以数据集后30%数据作为测试集,对逐步回归模型E预测结果进行评估,得到混淆矩阵如表4-7所示。
表4-7 混淆矩阵
| 真实类别\预测类别 | academic | general | vocation |
| academic | 33 | 4 | 3 |
| general | 5 | 0 | 2 |
| vocation | 3 | 2 | 8 |
| 正确率 | 68.33% | ||
| 错误率 | 31.67% | ||
由表4-7可以得出:选择academic类型的学生中,有33个学生课程类型判断正确,7个学生的课程类型判断错误;选择general类型的学生中,全部判断错误;选择general类型的学生中,有8个学生课程类型判断正确,5个学生课程类型判断错误;整体正确率为68.33%,错误率为31.67%,预测效果良好。
五、结论
根据上述描述性统计分析和数学建模,本文得出如下结论:
- 被调研学生中,一半以上学生高中时期选择了academic类型的课程,女学生略多于男学生,白人居多,社会地位中等人数占比约一半左右,大部分学生来自于公立学校。
- 列联表检验结果得出,性别在所选课程类型上无显著性差异,社会经济地位在所选课程上有显著性差异,其中社会地位高的学生更倾向于选择academic类型课程。
- 由箱线图和折线图分析可知,数学成绩和阅读成绩均在课程等级上呈现递减趋势,即academic、general和vocation课程类型的两门成绩平均水平越来越低。
- 由相关性热力图可以看出,五门课程成绩之间存在较显著的正相关关系。
- 若认为三中课程类型无高低之分,建立的无序多分类回归模型经过基于AIC准则的变量选择,得出社会经济地位、学校类型、数学分数和社会学分数对高中生课程的选择具有显著性影响。以五门课程平均成绩代替五门课程成绩的模型效果比原模型效果差。根据建立的模型对ID为80的学生选择的课程类型进行预测时,得出此学生选择的课程类型为academic,预测结果正确。
- 若认为三中课程类型有高低之分,建立的有序多分类回归模型经过基于AIC准则的变量选择,得出社会经济地位、学校类型、数学分数和社会学分数对高中生课程的选择具有显著性影响,与无序多分类回归模型结果一致。根据建立的模型对测试集进行预测,得到混淆矩阵,模型分类正确率为68.33%,模型预测效果良好。
六、代码
library(faraway)
attach(hsb)
hsb[c(1:5),]
??hsb
View(hsb)
#描述性统计分析
summary(hsb)
#绘制各科分数直方图
par(mfrow=c(2,3))
hist(read,col='pink',main="阅读",xlab="组别" ,ylab = "频数")
hist(write,col='pink',main="写作",xlab="组别" ,ylab = "频数")
hist(math,col='pink',main="数学",xlab="组别" ,ylab = "频数")
hist(science,col='pink',main="科学",xlab="组别" ,ylab = "频数")
hist(socst,col='pink',main="社会学",xlab="组别" ,ylab = "频数")
hist(id,main="id",col='pink',xlab="组别" ,ylab = "频数")
#制作列联表
table1=table(gender,prog)
table1
table2=table(ses,prog)
table2
chisq.test(table1)
kruskal.test(ses~prog,data=hsb)
#绘制课程类型-数学成绩箱线图
par(mfrow=c(1,1))
boxplot(math~prog,col='pink',ylab="数学成绩",xlab="课程类型",data=hsb)
#绘制课程类型-数学成绩折线图
#"academic","general","vocation"
par(mfrow=c(1,1))
plot(c(1,3),c(40,60),type="n",xlab="课程类型",ylab="阅读成绩")
points(c(1:3),tapply(read,prog,mean),type="b")
#绘制各科分数热力图
library(corrplot)
a=hsb[,c(7:11)]
k=cor(a,use='everything',method='pearson')
par(mfrow=c(1,1))
corrplot(k,addCoef.col = "black")
#构建无序多分类回归模型
library("nnet")
hsb$prog2=relevel(hsb$prog,ref = "academic")#改变因子水平次序
Model.A=multinom(prog2~gender+race+ses+schtyp+read+write+math+science+socst,data=hsb)
Model.AA=multinom(prog2~1,data=hsb)#空模型
anova(Model.A,Model.AA)
summary(Model.A)#没有给出P值
exp(coef(Model.A))#得到OR值
##计算pvalue,Z统计量
z=summary(Model.A)$coefficients/summary(Model.A)$standard.errors
p=(1 - pnorm(abs(z),0,1))*2#双侧,所以*2
p#越小越好
#用五门科目平均成绩代替五门科目建立无序多分类回归模型
hsb$ave=(read+write+math+science+socst)/5
Model.B=multinom(prog2~gender+race+ses+schtyp+ave,data=hsb)
summary(Model.B)#没有给出P值
AIC(Model.A,Model.B)
#对模型A用逐步回归法筛选变量
Model.C=step(Model.A,trace=F)#根据AIC准则从全模型Model.A中选出最优子模型,逐步回归
summary(Model.C)#没有给出P值
exp(coef(Model.C))#得到OR值
##计算pvalue,Z统计量
z=summary(Model.C)$coefficients/summary(Model.C)$standard.errors
p=(1 - pnorm(abs(z),0,1))*2#双侧,所以*2
p#越小越好
anova(Model.AA,Model.C)
#对ID为80的学生进行预测
ID80=data.frame(ses="high",schtyp="public",math=68,science=66,socst=66)
ID80
a=predict(Model.C,ID80)
summary(a)
#建立有序多分类回归模型
#首先将样本打乱,分出训练集和测试集
len=length(hsb[,1])#样本量
p=0.7#用作训练集的样本概率
ss0=round(len*p)#训练集样本量
hsb1=hsb[order(runif(len)),]
#数据集swiss的前70%作为训练集
A0=hsb1[c(1:ss0),]
#数据集swiss的后30%作为测试集
A1=hsb1[-c(1:ss0),]
library(MASS)
Model.D=polr(prog~gender+race+ses+schtyp+read+write+math+science+socst,data=A0,Hess=TRUE,method="logistic")
Model.DD=polr(prog~1,data=A0,Hess=TRUE,method="logistic")#空模型
anova(Model.D,Model.DD)
summary(Model.D)
ctable=coef(summary(Model.D))
p=pnorm(abs(ctable[,"t value"]),lower.tail = FALSE)*2
(ctable <- cbind(ctable,"p value"=p))
(ci <- confint(Model.D))#95%CI
exp(cbind(OR=coef(Model.D),ci))#ORֵ
#逐步回归进行变量选择
Model.E=step(Model.D,trace=F)
anova(Model.DD,Model.E)
summary(Model.E)
ctable=coef(summary(Model.E))
p=pnorm(abs(ctable[,"t value"]),lower.tail = FALSE)*2
(ctable <- cbind(ctable,"p value"=p))
(ci <- confint(Model.E))#95%CI
exp(cbind(OR=coef(Model.E),ci))#ORֵ
#根据有序多分类回归模型E进行预测,并计算混淆矩阵
p=predict(Model.E,A1,type="p")#利用模型E预测数据取值为各水平的概率(type=p)
A1$pre=predict(Model.E,A1)#利用模型E对数据A1进行预测,将预测结果存入A1的变量pre中
A1[c(1:5),]#显示数据a0的前5行
table(A1[,c(6,14)])#根据预测值和真实值生成列联表,展示预测精度(混淆矩阵)个人见解,还行各位读者批评指正!