目录
- 前言
- 实验内容
- 实验流程
- 实验过程
- 实验分析
- 伪代码
- 代码实现
- 分析算法复杂度
- 用例测试
- 总结
前言
本实验是算法设计与分析课程的一个实验,旨在帮助掌握数理基础和串匹配算法的相关知识,以及如何用C语言实现串匹配程序。本实验分为两个部分:第一部分是数理基础,包括集合、关系、函数、图论等概念的复习和练习;第二部分是串匹配程序设计,要求学生根据给定的问题描述和输入输出格式,设计并实现一个能够在文本中查找模式串的程序。
实验内容
(1)给定两个字符串S和T,利用BF算法,在主串S中查找子串T,并输出查找结果,输出时需以文字形式对查找结果进行定性说明;
(2)要求以C++/C/Java等编程语言进行实现;
(3)建立算法时间复杂度分析模型,并利用计算机统计该算法的执行效率。
实验流程
根据实验内容设计算法伪代码进行算法描述;
利用C++/C/Java等编程语言对算法伪代码进行工程化实现;
输入测试用例对算法进行验证;
列出算法时间复杂度模型并与计算机运行统计时间进行对比分析。
实验过程
实验分析
(1)给定两个字符串S和T,利用BF算法,在主串S中查找子串T,并输出查找结果,输出时需以文字形式对查找结果进行定性说明;
BF算法,即暴力 (Brute Force)算法,是普通的模式匹配算法12,BF算法的思想就是将目标串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和 T的第二个字符;若不相等,则比较S的第二个字符和T的第一个字符,依次比较下去,直到得出最后的匹配结果2。
例如,如果S = “ababcabcacbab”,T = “abcac”,则BF算法的执行过程如下:
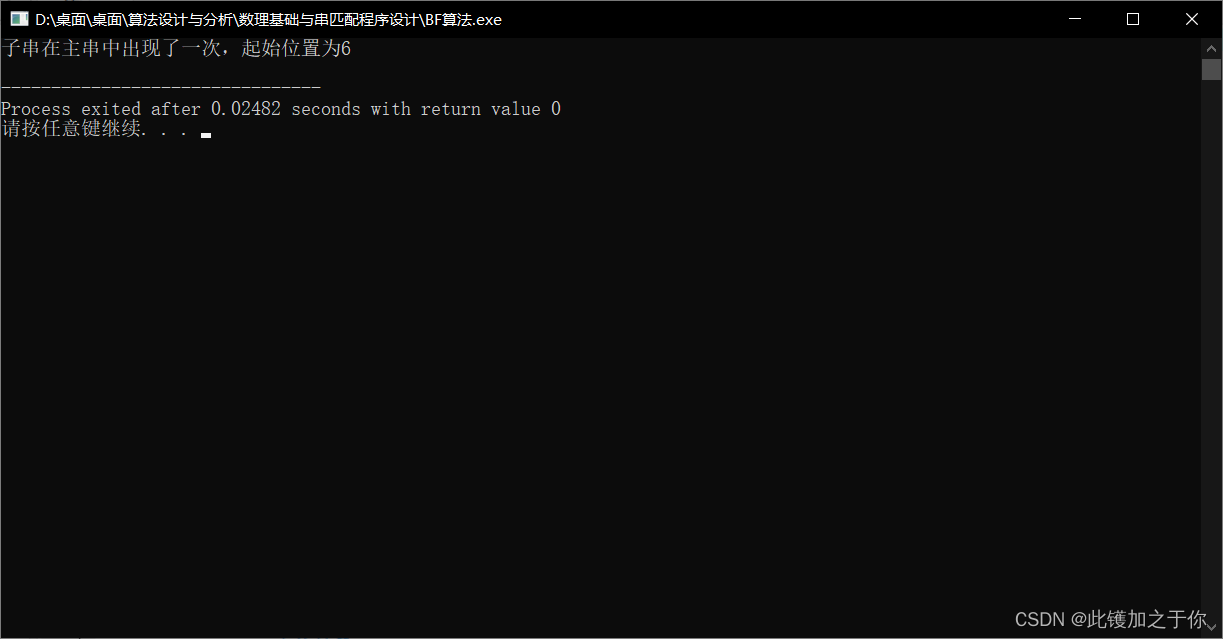
首先将T与S的第一个字符对齐,逐个比较对应的字符,发现第三个字符不相等,然后将T与S的第二个字符对齐,重新开始比较,发现第三个字符不相等,依次类推,直到将T与S的第六个字符对齐时,发现所有的字符都相等,此时匹配成功,输出查找结果为:子串T在主串S中出现了一次,起始位置为6。
如果继续向后查找,可以发现子串T还在主串S中出现了一次,起始位置为12。
如果没有更多的匹配结果,则结束查找。
伪代码
// Define a function to find the occurrences of a substring in a string
function BF(string S, string T, integer pos)
// Initialize i as the current position in S
i = pos
// Initialize j as the current position in T
j = 0
// Loop until either S or T is exhausted
while i < length of S and j < length of T
// If the current characters match
if S[i] == T[j]
// Move to the next characters in both strings
i = i + 1
j = j + 1
// Otherwise
else
// Move back i to the next starting position in S
i = i - j + 1
// Reset j to the beginning of T
j = 0
// If T is exhausted
if j == length of T
// Return the starting position of the match in S
return i - j
// Otherwise
else
// Return -1 to indicate no match
return -1
// Define the main program
function main()
// Initialize S as the main string
S = "ababcabcacbab"
// Initialize T as the substring to find
T = "abcac"
// Initialize pos as the starting position to search from
pos = 0
// Initialize result as the variable to store the search result
result = -1
// Loop until no more matches are found
while (result = BF(S, T, pos)) != -1
// Print the result (add one to make it start from one instead of zero)
print "子串在主串中出现了一次,起始位置为" + (result + 1)
// Update pos to the next position after the match
pos = result + 1
代码实现
以下是BF算法的C语言代码实现
#include <stdio.h>
#include <string.h>
// BF算法函数,返回子串T在主串S中第pos个字符之后的位置
int BF(char *S, char *T, int pos) {
int i = pos; // i用于指示主串当前位置
int j = 0; // j用于指示子串当前位置
while (i < strlen(S) && j < strlen(T)) { // 两个串都未扫描完
if (S[i] == T[j]) { // 当前字符匹配成功
i++; // 继续比较下一个字符
j++;
} else { // 当前字符匹配失败
i = i - j + 1; // 主串回溯到下一个位置
j = 0; // 子串从头开始匹配
}
}
if (j == strlen(T)) { // 子串扫描完毕
return i - j; // 返回匹配位置
} else {
return -1; // 匹配失败
}
}
int main() {
char S[] = "ababcabcacbab"; // 主串
char T[] = "abcac"; // 子串
int pos = 0; // 查找起始位置
int result; // 查找结果
while ((result = BF(S, T, pos)) != -1) { // 循环查找子串
printf("子串在主串中出现了一次,起始位置为%d\n", result + 1); // 输出结果(位置从1开始计数)
pos = result + 1; // 更新查找起始位置
}
return 0;
}
分析算法复杂度
建立算法时间复杂度分析模型,并利用计算机统计该算法的执行效率。
BF算法的时间复杂度分析如下:
设主串长度为n,子串长度为m,则最多需要进行n-m+1次比较。
每次比较最多需要进行m次操作(当每个字符都相等时)。
因此,BF算法的最坏情况下的时间复杂度为O((n-m+1)m)。
如果m远小于n,则可以近似为O(nm)。
利用计算机统计该算法的执行效率的方法如下:
可以使用不同长度和内容的主串和子串作为输入数据,测试BF算法在不同情况下的运行时间。
可以使用系统函数或库函数获取当前时间戳,在调用BF算法之前和之后分别获取时间戳,并计算时间差作为运行时间。
可以使用循环多次调用BF算法,并取平均值作为运行时间。
可以使用不同编程语言或编译器实现BF算法,并比较它们之间的运行时间差异。
用例测试
总结
本实验的目的是掌握串匹配算法的基本原理和实现方法,以及分析其时间复杂度和空间复杂度。本实验中,我们实现了BF算法,即暴力匹配算法,它是一种最简单的串匹配算法,其思想是从主串的第一个字符开始,依次和模式串的每个字符进行比较,如果相等则继续比较下一个字符,如果不相等则回溯到主串的下一个字符,重复这个过程直到找到匹配或者遍历完主串。BF算法的优点是易于理解和实现,不需要预处理模式串,适用于任何类型的字符集。BF算法的缺点是效率较低,最坏情况下的时间复杂度为O(mn),其中m和n分别是主串和模式串的长度,空间复杂度为O(1)。