K最近邻算法
- 算法概述
- 分类
- 什么是分类?
- 分类需要什么?
- k近邻(KNN)分类
- KNN算法关键问题
- k近邻模型的两个关键问题
- 相似性度量——欧氏距离
- K值的选取
- KNN算法流程
- 算法原理
- 算法步骤
- 数据标准化
- 离差标准化数据
- 标准差标准化数据
- 小数定标标准化数据
- 小结
- 特征缩放
- sklearn转换器的三个方法
- 特征缩放的不同方法
- 特征缩放的语法
- 算法实例
- sklearn中的K近邻分类器
- k近邻分类器的使用
- 算法应用
算法概述
分类
什么是分类?
- 用于分类任务的机器学习模型称为分类模型或分类器。
- 分类任务的目标是通过训练样本构建合适的分类器C(X),完成对目标的分类。
- 分类类别只有两类的分类任务称为二值分类或者二分类,这两个类别分别称为正类和负类,通常用+1和-1分别指代。
- 分类类别多于两类的分类任务通常称之为多值分类。
分类需要什么?
- 数据:
1)将对象表示为量化的一组特征。
2)给定类别标签。- 对象间相似性的度量。
k近邻(KNN)分类
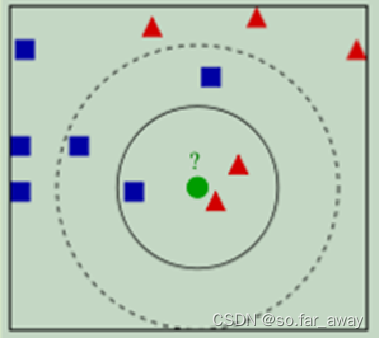
- k-近邻算法,顾名思义,即由某样本k个邻居的类别来推断出该样本的类别。
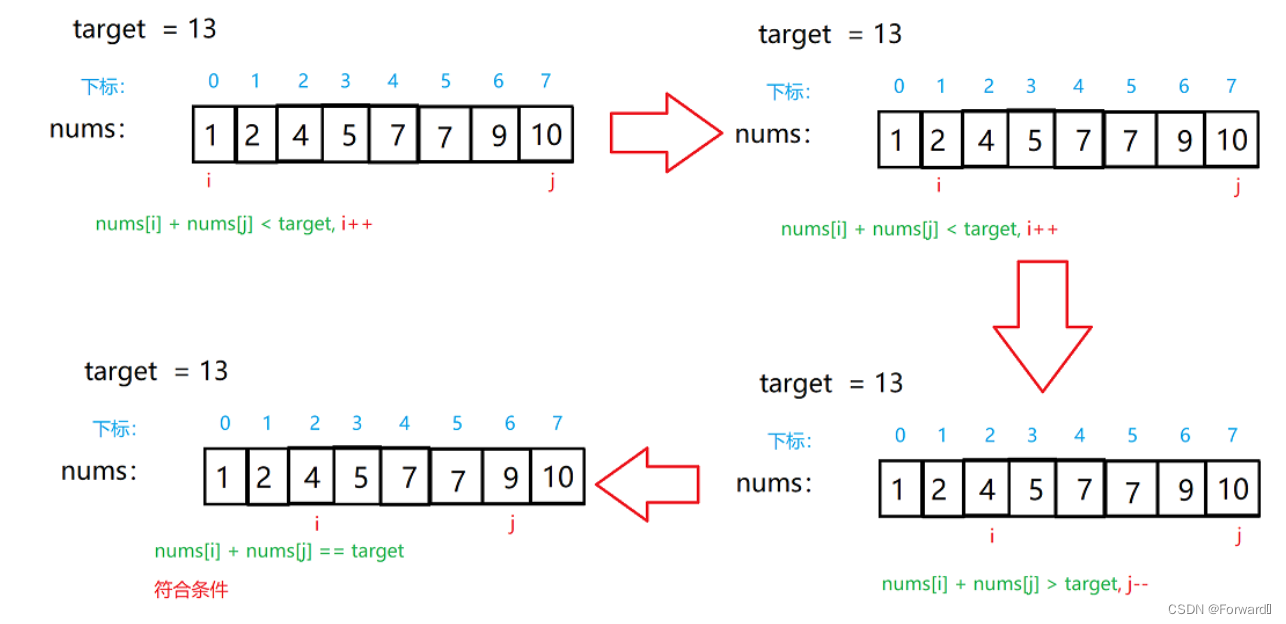
- 给定测试样本,基于特定的某种距离度量找到与训练集中最接近的k个样本,然后基于这k个样本的类别进行预测。
KNN算法关键问题
k近邻模型的两个关键问题
- 正确的"K"值,即K值的选取。
- 如何度量相邻两点之间的相似性/距离?即相似性度量方式的选取。
相似性度量——欧氏距离
欧氏距离也称为欧几里得距离。
其他距离衡量:余弦值距离(cos)、相关度(correlation)、曼哈顿距离(Manhattan distance)。
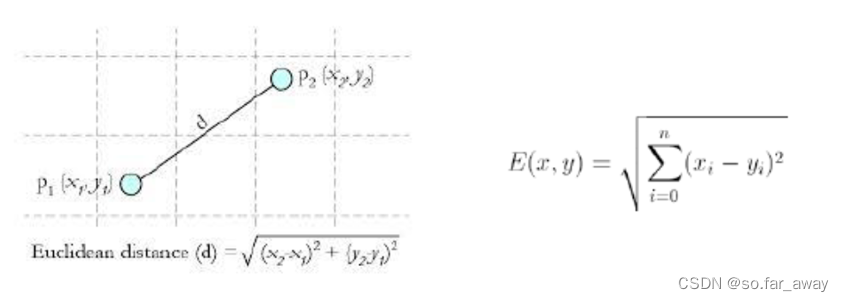
相似性度量实例:
使用如下的训练集,其中包含4个样例,每个样例有三个数值属性,以此判断物体x=[2,4,2]的类别。
通过计算x与所有训练样例之间的欧式距离,我们发现x的最近邻是 e x 2 ex_2 ex2。因为它的类标是pos,因此最近邻分类器返回正类的类标。

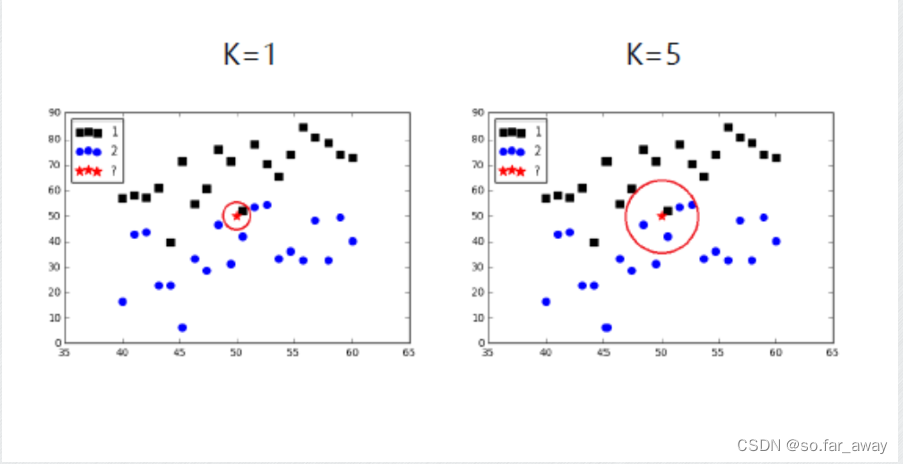
K值的选取
k值大小的影响:
- 较小的k值:
- 用较少训练实例预测,非常相似的实例才起作用,学习的近似误差会减小。
- 预测结果与少量实例有关,对近邻数据非常敏感,学习的估计误差会增大。
- 噪声敏感。
- K值的减小意味着模型变复杂,容易过拟合。(我个人对这一点的理解:当k值很小时,模型会更加关注局部信息,而忽略全局信息,这意味着,如果训练数据中存在一些随机噪声或异常值,它们可能会对模型产生不良影响,并导致模型对数据的过度拟合。)
2.较大的k值- 用较多训练实例进行预测,学习的估计误差会减小。
- 与输入数据距离较远的实例也会起作用,学习的近似误差会增大。
- K值的增大意味着模型变简单,容易欠拟合。
KNN算法流程
算法原理
- 为了判断未知实例的类别,以所有已知类别的实例作为参照选择参数K。
- 计算未知实例与所有已知实例的距离。
- 选择最近K个已知实例。
- 根据少数服从多数的投票法则,让未知实例归类为K个最邻近样本中最多数的类别。
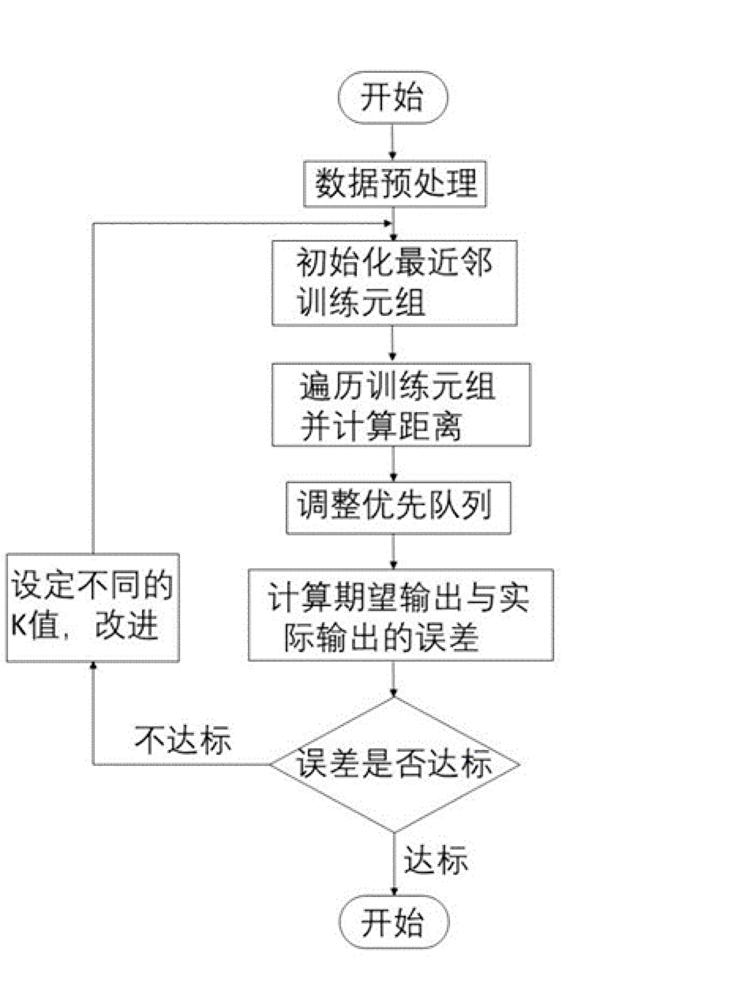
算法步骤
- 选用合适的测试元组和合适的数据存储结构训练数据。
- 维护一个大小为k,按距离由大到小的优先级队列,用于存储最近邻训练元组。随机从训练元组中选取k个元组作为初始的最近邻元组,分别计算测试元组到这k个元组的距离,将训练元组标号和距离存入优先级队列。
- 遍历训练元组集,计算当前训练元组与测试元组的距离。(通常使用欧氏距离)
- 之后将所得距离L与优先级队列中的最大距离L_max进行比较。若L≥ L m a x L_max Lmax,则舍弃该元组,将当前训练元组存入优先级队列。
- 遍历完毕后,计算优先级队列中k 个元组的多数类,并将其作为测试元组的类别。
- 测试元组集测试完毕后计算误差率,继续设定不同的k值重新进行训练,最后取误差率最小的k值。
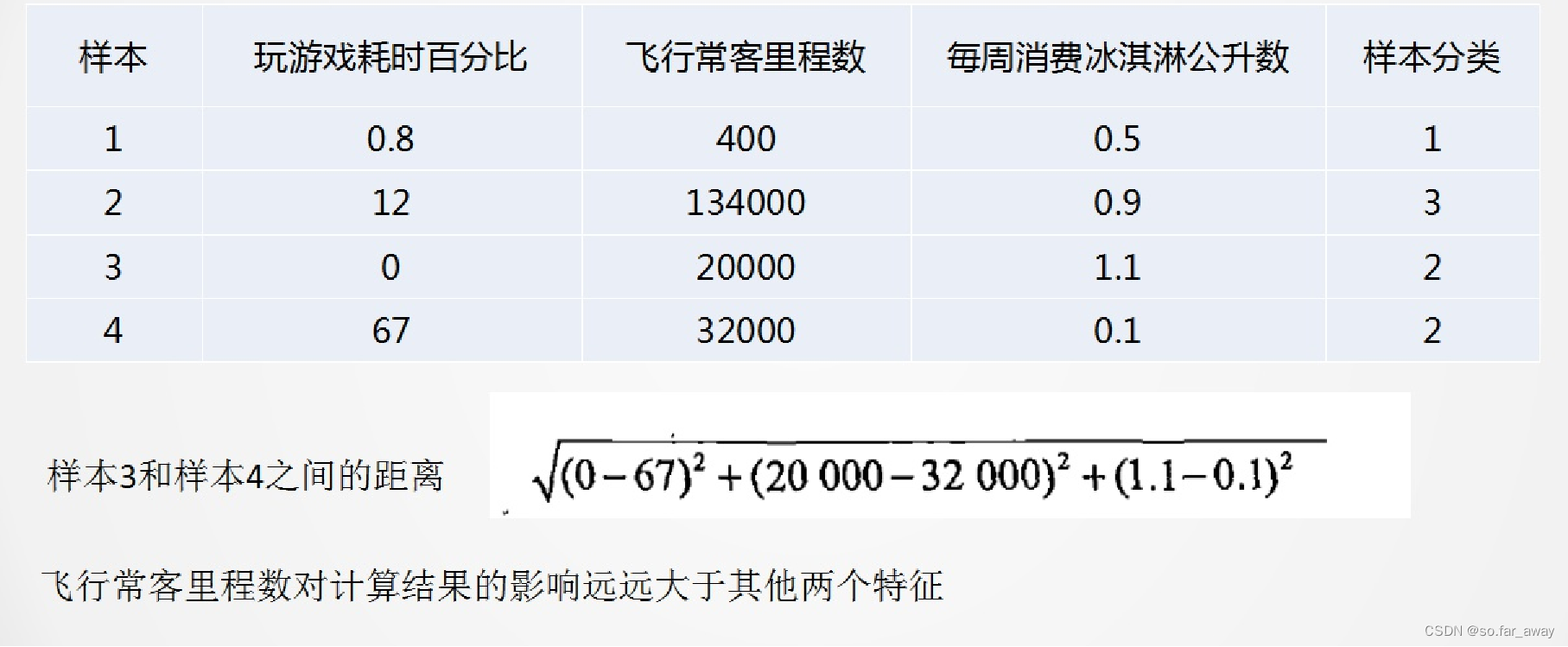
数据标准化
数据的所有特征都要做可比较的量化。
离差标准化数据
离差标准化是对原始数据的一种线性变换,结果是将原始数据的数值映射到[0,1]区间之间,转换公式为:
X ∗ = X − m i n m a x − m i n X^*=\frac{X-min}{max-min} X∗=max−minX−min
其中max为样本数据的最大值,min为样本数据的最小值,max-min为极差。离差标准化保留了原始数据值之间的联系,是消除量纲和数据取值范围影响最简单的方法。
- 数据的整体分布情况并不会随离差标准化而发生改变,原先取值较大的数据,在做完离差标准化后的值依旧较大。
- 当数据和最小值相等的时候,通过离差标准化可以发现数据变为0。
- 若数据极差过大就会出现离差标准化后数据之间的差值非常小的情况。
- 同时,还可以看出离差标准化的缺点:若数据集中某个数值很大,则离差标准化的值就会接近于0,并且相互之间差别不大。若将来遇到超过目前属性[min,max]取值范围的时候,会引起系统出错,这时便需要重新确定min和max。
标准差标准化数据
- 标准差标准化也叫零均值标准化或分数标准化,是当前使用最广泛的数据标准化方法。经过该方法处理的数据均值为0,标准差为1,转化公式如下:
X ∗ = X − X ‾ δ X^*=\frac{X-\overline X}{\delta} X∗=δX−X- 其中 X ‾ \overline X X为原始数据的均值, δ \delta δ为原始数据的标准差。标准差标准化后的值区间不局限于[0,1],并且存在负值。同时也不难发现,标准差标准化和离差标准化一样不会改变数据的分布情况。
小数定标标准化数据
通过移动数据的小数位数,将数据映射到区间[-1,1]之间,移动的小数位数取决于数据绝对值的最大值。转化公式如下:
X ∗ = X 1 0 k X^*=\frac{X}{10^k} X∗=10kX
小结
总之,三种标准化方法各有其优势:
- 离差标准化方法简单,便于理解,标准化后的数据限定在[0,1]区间内。
- 标准差标准化受到数据分布的影响较小。
- 小数定标标准化方法的适用范围广,并且受到数据分布的影响较小,相较于前两种方法而言该方法适用程度适中。
特征缩放
sklearn转换器的三个方法
sklearn把相关的功能封装为转换器(transformer)。使用sklearn转换器能够实现对传入的NumPy数组进行标准化处理、归一化处理、二值化处理、PCA降维等操作。转换器主要包括三个方法:
| 方法名称 | 说明 |
|---|---|
| fit | fit方法主要通过分析特征和目标值,提取有价值的信息,这些信息可以是统计量,也可以是权值系数等 |
| transform | transform方法主要用来对特征进行转换。从可利用信息的角度可分为无信息转换和有信息转换。无信息转换是指不利用任何其他信息进行转换,比如指数和对数函数转换等。有信息转换根据是否利用目标值向量又可分为无监督转换和有监督转换。无监督转换指只利用特征的统计信息的转换,比如标准化和PCA降维等。有监督转换指既利用了特征信息又利用了目标值信息的转换,比如通过模型选择特征和LDA降维等 |
| fit_transform | fit_transform方法就是先调用fit方法,然后调用transform方法 |
特征缩放的不同方法
- Standard Scaler:即标准化,尽量将数据转化为均值为0,方差为1的数据,形如标准正态分布(高斯分布)。
- Minimum-Maximum Scaler:将数据缩放到某一给定范围(通常是[0,1])。
- Maximum Absolute Value Scaler:通过除以最大绝对值,将数据缩放到[-1,1]。
- 使各特征的数值都处于统一数量级上。
| 函数名称 | 说明 |
|---|---|
| MinMaxScaler | 对特征进行离差标准化 |
| StandardScaler | 对特征进行标准差标准化 |
| Normalizer | 对特征进行归一化 |
| Binarizer | 对定量特征进行二值化处理 |
| OneHotEncoder | 对定性特征进行独热编码处理 |
| FunctionTransformer | 对特征进行自定义函数变换 |
特征缩放的语法
导入包含缩放方法的类:
from sklearn.preprocessing import StandardScaler
创建该类的一个对象:
stdsc=StandardScaler()
拟合缩放的参数,然后对数据做转换:
stdsc=stdsc.fit(X_data)
X_scaled=stdsc.transform(X_data)
或者
X_scaled=stdsc.fit_transform(X_data)
算法实例
sklearn中的K近邻分类器
在sklearn库中,可以使用
sklearn.neighbors.KNeighborsClassifier创建一个K近邻分类器,主要参数有:
- n_neighbors:用于指定分类器中K的大小(默认值为5,注意区分与kmeans的区别)
- weights:设置选中的K个点对分类结果影响的权重(默认值为平均权重),可以选择“distance”代表越近的点权重越高,或者传入自己编写的以距离为参数的权重计算函数。
- algorithm:设置用于计算临近点的方法,因为当数据量很大的情况下计算当前点与所有点的距离再选出最近的k各点,这个计算量是很费时的,所以选项中有ball_tree、kd_tree和brute,分别代表不同的寻找邻居的优化算法,默认值为auto,根据训练数据自动选择。
k近邻分类器的使用
#创建一组数据X和它对应的标签y
X=[[0],[1],[2],[3]]
y=[0,0,1,1]
#使用import语句导入K近邻分类器
from sklearn.neighbors import KNeighborsClassifier
#参数n_neighbors设置为3 即使用最近的3个邻居作为分类的依据 其他参数保持默认值 并将创建好的实例赋值给变量neigh
neigh=KNeighborsClassifier(n_neighbors=3)
#调用fit函数 训练
neigh.fit(X,y)
#调用predict函数 对未知分类样本[1.1]分类
print(neigh.predict([[1.1]]))
#预测分类为0
算法应用
案例研究:鸢尾花数据集
- 150个鸢尾花样例load_iris()
- 用4个特征度量:花萼的长度和宽度,花瓣的长度和宽度
- 来自3个不同的属种:Setosa、Versicolor、Virginica,每种50个样例
- 分类问题:给定一株鸢尾花,判定其属种
代码实现
普通版本:

from sklearn import neighbors
from sklearn import datasets
knn=neighbors.KNeighborsClassifier()
iris=datasets.load_iris()
X,y=iris.data,iris.target
knn.fit(X,y)
predictedLabel=knn.predict([[0.1,0.2,0.3,0.4]])
print(iris.target_names[predictedLabel])
K折交叉验证版:
from sklearn import neighbors
from sklearn import datasets
from sklearn.model_selection import cross_val_score
iris=datasets.load_iris()
X,y=iris.data,iris.target
knn=neighbors.KNeighborsClassifier()
knn.fit(X,y)
scores=cross_val_score(knn,X,y,cv=5)
predictedLabel=knn.predict([[0.1,0.2,0.3,0.4]])
print(iris.target_names[predictedLabel])
print(scores.mean())