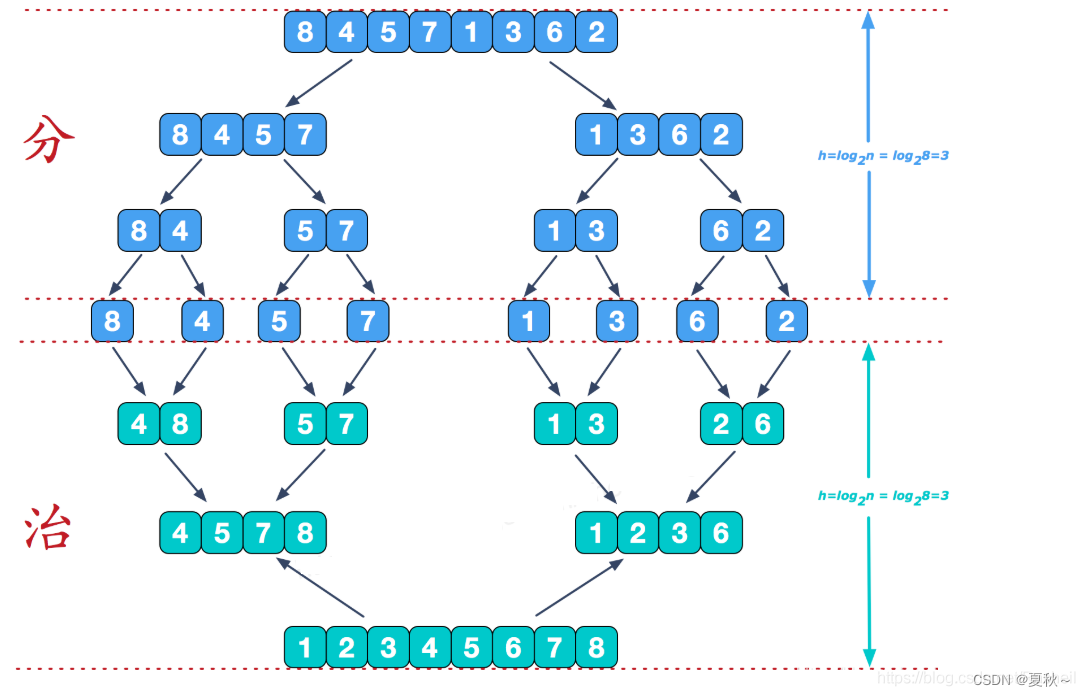
说明
找到了一个合适的例子,然后我对其中的内容进行了拆解分析。我觉得代码表达的内容比伪代码清晰多了。
这次算是补砖了(监督+无监督+强化),过去实际上接触过很多强化体系内的基本工具,但一直没有开始做,部分原因是没时间,但更多的还是因为技术洁癖吧(没ready就不想搞)。
所以我觉得应该可以不考虑姿势,先进行破冰,但同时也不能分散注意力。所以之前我给自己定义的界限是:探索新领域可以,但不能写代码。我觉得这次算是一个微微踩线的动作:没自己写代码,但是稍微改了改代码,总体不到1小时完成整个Case,还行。
内容
这个例子的源是这篇文章, 我从我觉得比较方便的地方把代码拆开来做了分析。
图也来自上文哈。
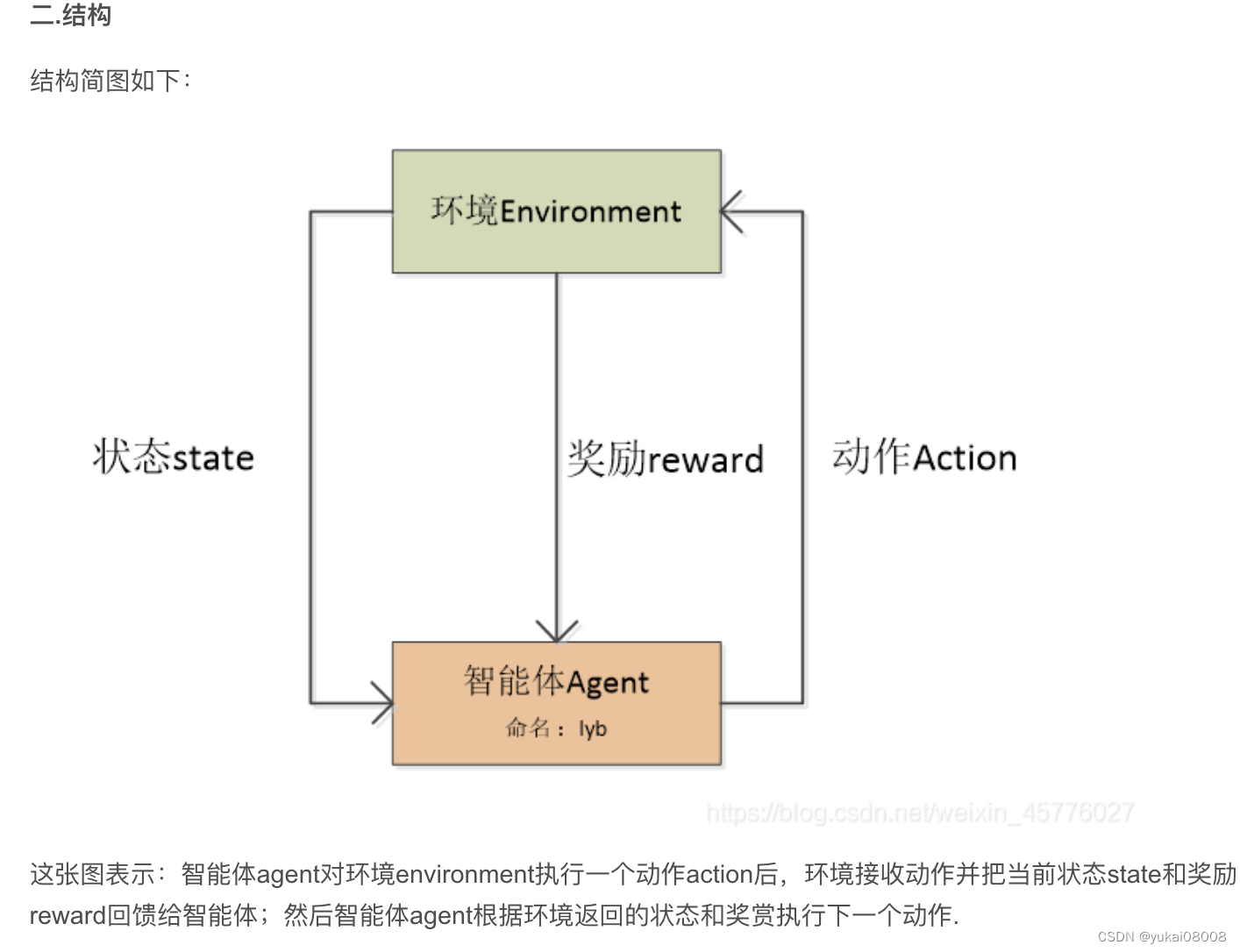
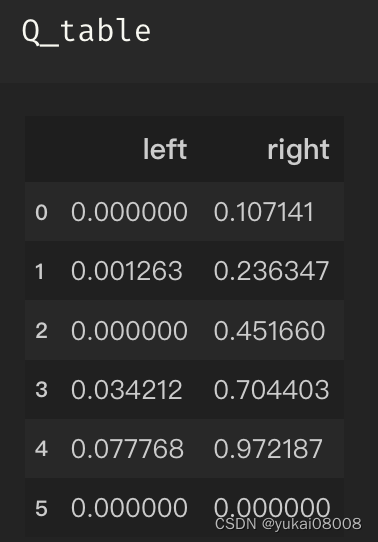
原文也挺有趣的,用DataFrame来表达上面的结构:
- 1 索引是状态
- 2 列名是可采取的行动(Left, Right)
- 3 值是对应的回报(Return)
目标问题是:在一维平面上,有6个点,其中一个是目标点。通过QLearning来找到最优的路径。
这算是无模型的方法,一开始并没有任何的提示,只是在目标点给了1的奖励,其他位置为0。所以算法需要经过一次次的探索来丰富自己的路径数据。
每一次的探索从一个随机点(本例固定为最左边的点)开始游走,到目标点就停下,探索结束。一次也就是一个episode。我想,如果空间大的话,是可以采取有限步达到目标的方式,随机很多点去探索。
以下是我去分解验证的过程:
函数可参考原文,没有改
每次episode从重置状态开始
#设置Q估计表内的状态位置为0
current_state = 0
#与绑定环境相关
updata_environment(current_state)
total_steps = 0
如果不是在目标状态,则执行一次探索
if current_state != states[-1]:
cur_rand = random.uniform(0,1)
#random.uniform(0,1)表示在0-1内随机生成一个随机数
# loc通过行/列标签索引到状态矩阵,(iloc通过行/列号索引矩阵这里没用到),all()表示索引到的状态矩阵与0的比对结果再作一次与运算
is_random_open = cur_rand > want
print('【1】Is random Open',is_random_open)
is_current_state_all_Q_0 = (Q_table.loc[current_state] == 0).all()
print('【2】Is Current State all 0',is_current_state_all_Q_0)
# 是否要随机采取行动(改变位置)
is_random_need_to_change = is_random_open or is_current_state_all_Q_0
print('【3】Is Need To Random Change Action', is_random_need_to_change)
if is_random_need_to_change:
if is_random_open:
print('【4】Change Action Due To Random')
if is_current_state_all_Q_0:
print('【4】Change Action Due To Current State Return 0')
# 基于当前状态选择动作
current_action = random.choice(get_vaild_actions(current_state))
else:
# 根据已知的回报选择动作
print('【4】Choose Known Best Action')
current_action = Q_table.loc[current_state].idxmax()
print('【5】Current Action:', current_action)
# 获取根据当前状态+行动后的新状态
next_state = get_next_state(current_state,current_action)
print('【6】Moving From State %s To State %s by Action %s' %(current_state, next_state, current_action))
# 读取下一个状态下的【行为-奖励】数据
next_state_Q_values = Q_table.loc[next_state,get_vaild_actions(next_state)]
print('【7】Next State Action Returns', next_state_Q_values)
# 从下一步值从获得的影响
part1_next_reward = rewards[next_state]
print('【8.1】part1_next reward', part1_next_reward)
part2_decrease_max = reward_decrease*next_state_Q_values.max()
print('【8.2】part2_decrease_max reward', part2_decrease_max)
part3_current_reward = Q_table.loc[current_state,current_action]
print('【8.3】part3_current reward', part3_current_reward)
# 本状态、本动作的奖励增益
delta_reward = efficiency *(part1_next_reward + part2_decrease_max - part3_current_reward)
print('【9】Current State & Action 【Delta】 Reward' ,delta_reward)
print('【10】Current State & Action Reward ' , Q_table.loc[current_state, current_action])
Q_table.loc[current_state, current_action]+=delta_reward
print('【11】Current State & Action Reward Changed By 【Delta Reward】 ' , Q_table.loc[current_state, current_action])
print('【12】Moving To New State & Update')
current_state = next_state
updata_environment(current_state) #更新环境
print('【13】QTable',Q_table)
else:
print('【14】找到目标')
一开始执行时,会看到探索的位置左右移动,一直到找到目标之后。可能会经过十几轮才会找到目标。
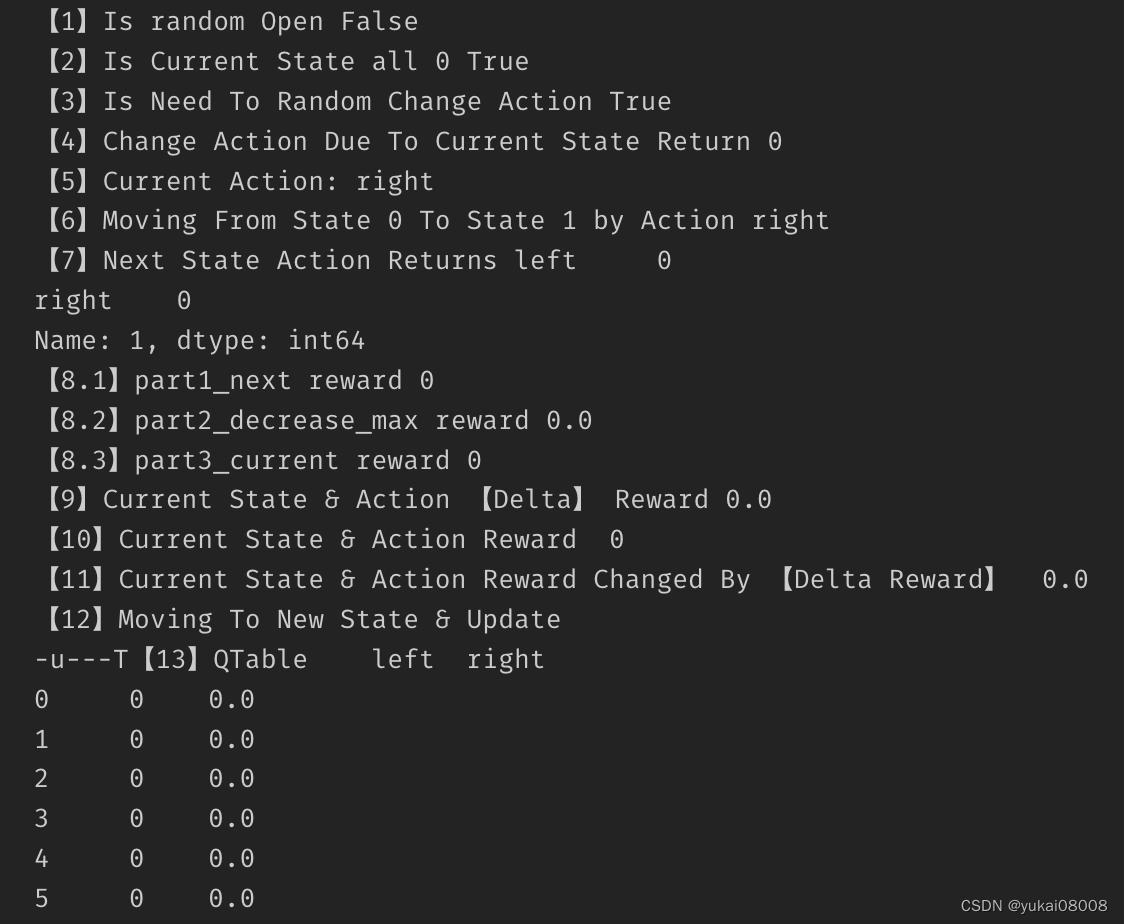
那个u会一直挪来挪去,最终会找到出口。
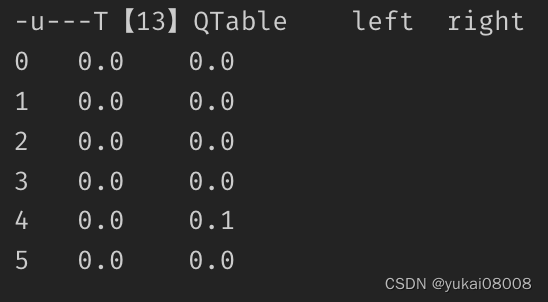
到达目标后,第一次的episode结束,然后进入第二波。此时的QTable不再是全为0,游走的效率会提升(达到状态4之后就会必然走向5,而不会退回3)
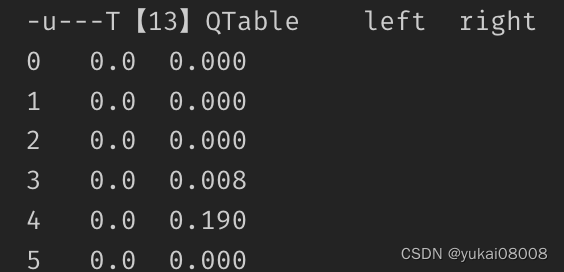
然后再过一轮,这时候状态3的Right也有了大于0的回报,这样随机游走会进一步减少。
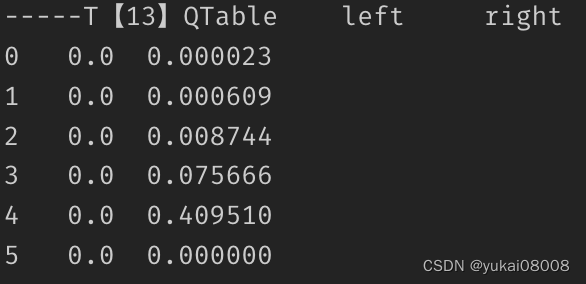
之后的每一次游走,会不断丰富在各个状态下的回报值。这个过程中,随机游走已经确定了,每次都直接往右走。
进入批次运行的状态,看u总是直接从左到右。
大概几十次之后
总结
整体上,我觉得强化学习很好玩,和打游戏简直一毛一样。
这次是一个快速探索的实验,到这里就结束了,原理性验证通过,还是挺满意的。