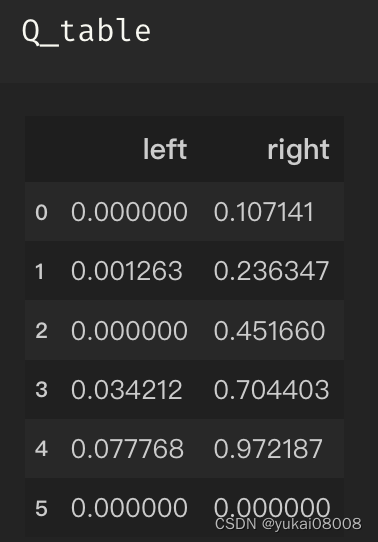
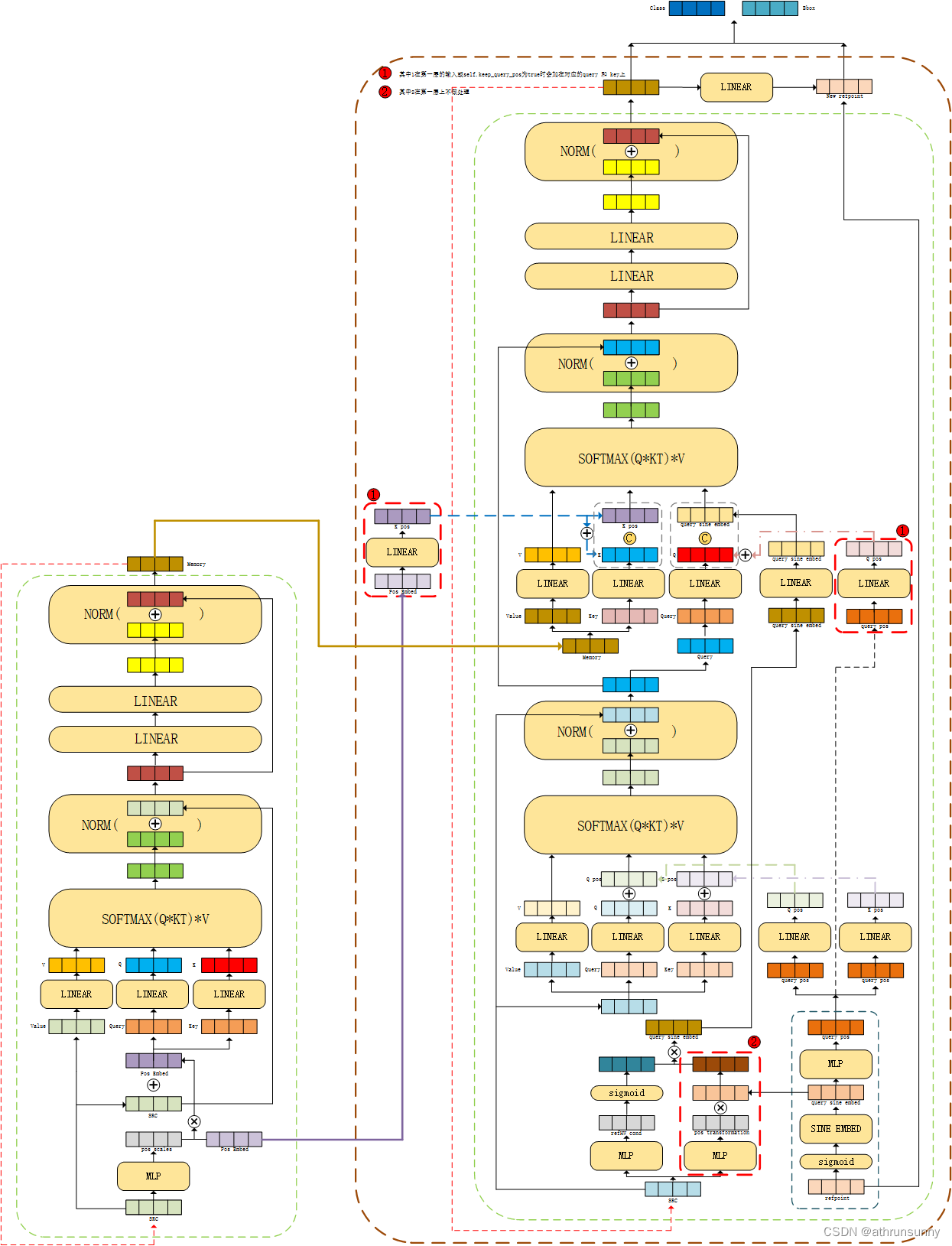
先上一张整体架构图 :

代码地址:GitHub - IDEA-Research/DAB-DETR: [ICLR 2022] DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR
论文地址: https://arxiv.org/pdf/2201.12329.pdf
文章全名《DYNAMIC ANCHOR BOXES ARE BETTER QUERIES FOR DETR》,文中提到使用box坐标不仅有助于使用显式位置先验来提高query-to-feature的相似性,消除DETR中训练收敛缓慢的问题,而且还允许我们使用框宽度和高度信息来调整位置注意力图。
一、backbone
backbone和DETR是一样的,也是仅仅取了最后一层的输出,将该输出作为encoder的输入,具体的可以参看DETR代码学习笔记(一)
二、encoder
先从DAB-DETR的主函数开始:
本文中假设输入的图像尺寸为800*800,输出的feature map大小为800//32=25
class DABDETR(nn.Module):
""" This is the DAB-DETR module that performs object detection """
def __init__(self, backbone, transformer, num_classes, num_queries,
aux_loss=False,
iter_update=True,
query_dim=4,
bbox_embed_diff_each_layer=False,
random_refpoints_xy=False,
):
""" Initializes the model.
Parameters:
backbone: torch module of the backbone to be used. See backbone.py
transformer: torch module of the transformer architecture. See transformer.py
num_classes: number of object classes
num_queries: number of object queries, ie detection slot. This is the maximal number of objects
Conditional DETR can detect in a single image. For COCO, we recommend 100 queries.
aux_loss: True if auxiliary decoding losses (loss at each decoder layer) are to be used.
iter_update: iterative update of boxes
query_dim: query dimension. 2 for point and 4 for box.
bbox_embed_diff_each_layer: dont share weights of prediction heads. Default for False. (shared weights.)
random_refpoints_xy: random init the x,y of anchor boxes and freeze them. (It sometimes helps to improve the performance)
"""
super().__init__()
self.num_queries = num_queries
self.transformer = transformer
hidden_dim = transformer.d_model
self.class_embed = nn.Linear(hidden_dim, num_classes)
self.bbox_embed_diff_each_layer = bbox_embed_diff_each_layer
if bbox_embed_diff_each_layer:
self.bbox_embed = nn.ModuleList([MLP(hidden_dim, hidden_dim, 4, 3) for i in range(6)])
else:
self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3)
# setting query dim
self.query_dim = query_dim
assert query_dim in [2, 4]
self.refpoint_embed = nn.Embedding(num_queries, query_dim) # [300,4]
self.random_refpoints_xy = random_refpoints_xy
if random_refpoints_xy:
# import ipdb; ipdb.set_trace()
self.refpoint_embed.weight.data[:, :2].uniform_(0, 1)
self.refpoint_embed.weight.data[:, :2] = inverse_sigmoid(self.refpoint_embed.weight.data[:, :2])
self.refpoint_embed.weight.data[:, :2].requires_grad = False
self.input_proj = nn.Conv2d(backbone.num_channels, hidden_dim, kernel_size=1)
self.backbone = backbone
self.aux_loss = aux_loss
self.iter_update = iter_update
if self.iter_update:
self.transformer.decoder.bbox_embed = self.bbox_embed
# init prior_prob setting for focal loss
prior_prob = 0.01
bias_value = -math.log((1 - prior_prob) / prior_prob)
self.class_embed.bias.data = torch.ones(num_classes) * bias_value
# import ipdb; ipdb.set_trace()
# init bbox_embed
if bbox_embed_diff_each_layer:
for bbox_embed in self.bbox_embed:
nn.init.constant_(bbox_embed.layers[-1].weight.data, 0)
nn.init.constant_(bbox_embed.layers[-1].bias.data, 0)
else:
nn.init.constant_(self.bbox_embed.layers[-1].weight.data, 0)
nn.init.constant_(self.bbox_embed.layers[-1].bias.data, 0)
def forward(self, samples: NestedTensor):
""" The forward expects a NestedTensor, which consists of:
- samples.tensor: batched images, of shape [batch_size x 3 x H x W]
- samples.mask: a binary mask of shape [batch_size x H x W], containing 1 on padded pixels
It returns a dict with the following elements:
- "pred_logits": the classification logits (including no-object) for all queries.
Shape= [batch_size x num_queries x num_classes]
- "pred_boxes": The normalized boxes coordinates for all queries, represented as
(center_x, center_y, width, height). These values are normalized in [0, 1],
relative to the size of each individual image (disregarding possible padding).
See PostProcess for information on how to retrieve the unnormalized bounding box.
- "aux_outputs": Optional, only returned when auxilary losses are activated. It is a list of
dictionnaries containing the two above keys for each decoder layer.
"""
if isinstance(samples, (list, torch.Tensor)):
samples = nested_tensor_from_tensor_list(samples)
features, pos = self.backbone(samples) # pos [N,256,25,25]
src, mask = features[-1].decompose() # src [N,2048,25,25] ,mask [N,25,25]
assert mask is not None
# default pipeline
embedweight = self.refpoint_embed.weight # [300,4]
hs, reference = self.transformer(self.input_proj(src), mask, embedweight, pos[-1]) # 1*1卷积降维 src [N,2048,25,25] -> src [N,256,25,25]
if not self.bbox_embed_diff_each_layer:
reference_before_sigmoid = inverse_sigmoid(reference)
tmp = self.bbox_embed(hs) # Linear(256,256) Linear(256,256) Linear(256,4) [6,N,300,256]-> [6,N,300,4]
tmp[..., :self.query_dim] += reference_before_sigmoid
outputs_coord = tmp.sigmoid()
else:
reference_before_sigmoid = inverse_sigmoid(reference)
outputs_coords = []
for lvl in range(hs.shape[0]):
tmp = self.bbox_embed[lvl](hs[lvl])
tmp[..., :self.query_dim] += reference_before_sigmoid[lvl]
outputs_coord = tmp.sigmoid()
outputs_coords.append(outputs_coord)
outputs_coord = torch.stack(outputs_coords)
outputs_class = self.class_embed(hs) # Linear(256,91) [6,N,300,256]->[6,N,300,91]
out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}
if self.aux_loss:
out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord)
return out
@torch.jit.unused
def _set_aux_loss(self, outputs_class, outputs_coord):
# this is a workaround to make torchscript happy, as torchscript
# doesn't support dictionary with non-homogeneous values, such
# as a dict having both a Tensor and a list.
return [{'pred_logits': a, 'pred_boxes': b}
for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]经过backbone的src的维度为[N,2048,25,25], pos经过PositionEmbeddingSineHW维度为[N,256,25,25],PositionEmbeddingSineHW和DETR中的PositionEmbeddingSine不同之处在于,PositionEmbeddingSine中使用一个temperature同时控制W和H,而PositionEmbeddingSineHW可在W和H上使用不同的temperature,整体上的功能基本相同。mask在上述中的博文中有详细解释,维度为[N,25,25]。
refpoint_embed由nn.Embedding(num_queries, query_dim)得到,其中num_queries为300,query_dim为4.
src在输入encoder之前会经过一个1*1的卷积进行降维[N,2048,25,25]->[N,256,25,25].
class Transformer(nn.Module):
def __init__(self, d_model=512, nhead=8, num_queries=300, num_encoder_layers=6,
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False,
return_intermediate_dec=False, query_dim=4,
keep_query_pos=False, query_scale_type='cond_elewise',
num_patterns=0,
modulate_hw_attn=True,
bbox_embed_diff_each_layer=False,
):
super().__init__()
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
encoder_norm = nn.LayerNorm(d_model) if normalize_before else None
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before, keep_query_pos=keep_query_pos)
decoder_norm = nn.LayerNorm(d_model)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
return_intermediate=return_intermediate_dec,
d_model=d_model, query_dim=query_dim, keep_query_pos=keep_query_pos, query_scale_type=query_scale_type,
modulate_hw_attn=modulate_hw_attn,
bbox_embed_diff_each_layer=bbox_embed_diff_each_layer)
self._reset_parameters()
assert query_scale_type in ['cond_elewise', 'cond_scalar', 'fix_elewise']
self.d_model = d_model
self.nhead = nhead
self.dec_layers = num_decoder_layers
self.num_queries = num_queries
self.num_patterns = num_patterns
if not isinstance(num_patterns, int):
Warning("num_patterns should be int but {}".format(type(num_patterns)))
self.num_patterns = 0
if self.num_patterns > 0:
self.patterns = nn.Embedding(self.num_patterns, d_model)
def _reset_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def forward(self, src, mask, refpoint_embed, pos_embed):
# flatten NxCxHxW to HWxNxC
bs, c, h, w = src.shape
src = src.flatten(2).permute(2, 0, 1) # src [N,256,25,25]->[625,N,256]
pos_embed = pos_embed.flatten(2).permute(2, 0, 1) # pos_embed [N,256,25,25]->[625,N,256]
refpoint_embed = refpoint_embed.unsqueeze(1).repeat(1, bs, 1) # refpoint_embed [300,4] -> [300,N,4]
mask = mask.flatten(1) # [N,25,25] -> [N,625]
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)
# query_embed = gen_sineembed_for_position(refpoint_embed)
num_queries = refpoint_embed.shape[0]
if self.num_patterns == 0:
tgt = torch.zeros(num_queries, bs, self.d_model, device=refpoint_embed.device) # tgt [300,N,256]全零tensor
else:
tgt = self.patterns.weight[:, None, None, :].repeat(1, self.num_queries, bs, 1).flatten(0, 1) # n_q*n_pat, bs, d_model
refpoint_embed = refpoint_embed.repeat(self.num_patterns, 1, 1) # n_q*n_pat, bs, d_model
# import ipdb; ipdb.set_trace()
hs, references = self.decoder(tgt, memory, memory_key_padding_mask=mask,
pos=pos_embed, refpoints_unsigmoid=refpoint_embed)
return hs, references # [6,N,300,256] [6,N,300,4]在输入encoder之前还会对src,mask,refpoint_embed等做一些维度转换的预处理,之后将feature map 对应的src以及其对应的mask,以及mask经过PositionEmbeddingSineHW后得到的pos_embed传入encoder(后面有图解)。
class TransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers, norm=None, d_model=256):
super().__init__()
self.layers = _get_clones(encoder_layer, num_layers)
self.num_layers = num_layers
self.query_scale = MLP(d_model, d_model, d_model, 2)
self.norm = norm
def forward(self, src,
mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
output = src
for layer_id, layer in enumerate(self.layers):
# rescale the content and pos sim
pos_scales = self.query_scale(output) # 两个Linear(256,256) [625,N,256]->[625,N,256]
output = layer(output, src_mask=mask,
src_key_padding_mask=src_key_padding_mask, pos=pos*pos_scales) # mask==None, src_key_padding_mask [N,625], pos = mask经过编码后乘output经过两个Linear的结果
if self.norm is not None:
output = self.norm(output)
return output在encoder中pos_embed会乘上每一层encoder输出的output经过两个Linear层得到的结果,作为新的pos_embed输入到下一层encoder。encoder的代码如下,和DETR一样,就不展开说了(能看到这里的应该都是知道DETR的)
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(src, pos)
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return srcencoder的图解:
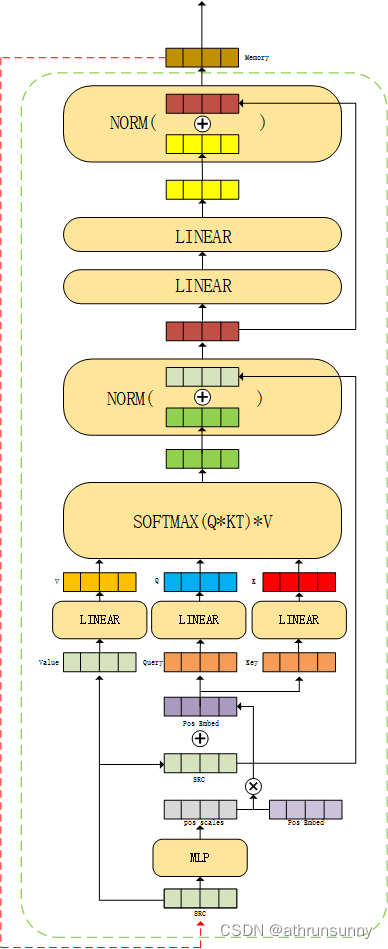
三、decoder
输入decoder之前,先初始化了一个[300,N,256]的全零tgt,我用的默认设置,代码走的是if中的条件。
num_queries = refpoint_embed.shape[0]
if self.num_patterns == 0:
tgt = torch.zeros(num_queries, bs, self.d_model, device=refpoint_embed.device) # tgt [300,N,256]全零tensor
else:
tgt = self.patterns.weight[:, None, None, :].repeat(1, self.num_queries, bs, 1).flatten(0, 1) # n_q*n_pat, bs, d_model
refpoint_embed = refpoint_embed.repeat(self.num_patterns, 1, 1) # n_q*n_pat, bs, d_model将tgt,encoder输出的memory,memory的mask,mask经过PE得到的pos_embed,refpoint_embed,输入到decoder中。其中refpoint_embed在第二维上根据batch size进行了复制[300,4] -> [300,N,4]。
N个batch上300个4维的位置信息,分别代表x,y,w,h,通过gen_sineembed_for_position()分别对他们进行位置编码,query_sine_embed的维度由obj_center[300,N,4]变为[300,N,512]。
query_sine_embed再经过两个Linear层得到query_pos维度由[300,N,512]->[300,N,256]。
class TransformerDecoder(nn.Module):
def __init__(self, decoder_layer, num_layers, norm=None, return_intermediate=False,
d_model=256, query_dim=2, keep_query_pos=False, query_scale_type='cond_elewise',
modulate_hw_attn=False,
bbox_embed_diff_each_layer=False,
):
super().__init__()
self.layers = _get_clones(decoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
self.return_intermediate = return_intermediate
assert return_intermediate
self.query_dim = query_dim
assert query_scale_type in ['cond_elewise', 'cond_scalar', 'fix_elewise']
self.query_scale_type = query_scale_type
if query_scale_type == 'cond_elewise':
self.query_scale = MLP(d_model, d_model, d_model, 2)
elif query_scale_type == 'cond_scalar':
self.query_scale = MLP(d_model, d_model, 1, 2)
elif query_scale_type == 'fix_elewise':
self.query_scale = nn.Embedding(num_layers, d_model)
else:
raise NotImplementedError("Unknown query_scale_type: {}".format(query_scale_type))
self.ref_point_head = MLP(query_dim // 2 * d_model, d_model, d_model, 2)
self.bbox_embed = None
self.d_model = d_model
self.modulate_hw_attn = modulate_hw_attn
self.bbox_embed_diff_each_layer = bbox_embed_diff_each_layer
if modulate_hw_attn:
self.ref_anchor_head = MLP(d_model, d_model, 2, 2)
if not keep_query_pos:
for layer_id in range(num_layers - 1):
self.layers[layer_id + 1].ca_qpos_proj = None
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
refpoints_unsigmoid: Optional[Tensor] = None, # num_queries, bs, 2
):
output = tgt # 最开始tgt [300,N,256]全零tensor
intermediate = []
reference_points = refpoints_unsigmoid.sigmoid() # [300,N,4]
ref_points = [reference_points]
# import ipdb; ipdb.set_trace()
for layer_id, layer in enumerate(self.layers):
obj_center = reference_points[..., :self.query_dim] # [num_queries, batch_size, 2] # [300,N,4]
# get sine embedding for the query vector
query_sine_embed = gen_sineembed_for_position(obj_center, self.d_model) # 对obj_center[300,N,4] 中的x,y,w,h分别做位置编码->[300,N,512]
query_pos = self.ref_point_head(query_sine_embed) # Linear(512,256) Linear(256,256) [300,N,512]->[300,N,256]
# For the first decoder layer, we do not apply transformation over p_s
if self.query_scale_type != 'fix_elewise':
if layer_id == 0:
pos_transformation = 1
else:
pos_transformation = self.query_scale(output) # Linear(256,256) Linear(256,256) [300,N,256]
else:
pos_transformation = self.query_scale.weight[layer_id]
# apply transformation
query_sine_embed = query_sine_embed[...,:self.d_model] * pos_transformation
# modulated HW attentions
if self.modulate_hw_attn:
refHW_cond = self.ref_anchor_head(output).sigmoid() # nq, bs, 2 Linear(256,256) Linear(256,2) [300,N,2]
query_sine_embed[..., self.d_model // 2:] *= (refHW_cond[..., 0] / obj_center[..., 2]).unsqueeze(-1)
query_sine_embed[..., :self.d_model // 2] *= (refHW_cond[..., 1] / obj_center[..., 3]).unsqueeze(-1)
output = layer(output, memory, tgt_mask=tgt_mask, # None
memory_mask=memory_mask, # None
tgt_key_padding_mask=tgt_key_padding_mask, # None
memory_key_padding_mask=memory_key_padding_mask,
pos=pos, query_pos=query_pos, query_sine_embed=query_sine_embed,
is_first=(layer_id == 0)) # output [300,N,256]
# iter update
if self.bbox_embed is not None:
if self.bbox_embed_diff_each_layer:
tmp = self.bbox_embed[layer_id](output)
else:
tmp = self.bbox_embed(output) # Linear(256,256) Linear(256,256) Linear(256,4) [300,N,4]
# import ipdb; ipdb.set_trace()
tmp[..., :self.query_dim] += inverse_sigmoid(reference_points)
new_reference_points = tmp[..., :self.query_dim].sigmoid()
if layer_id != self.num_layers - 1:
ref_points.append(new_reference_points)
reference_points = new_reference_points.detach()
if self.return_intermediate:
intermediate.append(self.norm(output))
if self.norm is not None:
output = self.norm(output)
if self.return_intermediate:
intermediate.pop()
intermediate.append(output)
if self.return_intermediate:
if self.bbox_embed is not None:
return [
torch.stack(intermediate).transpose(1, 2),
torch.stack(ref_points).transpose(1, 2),
]
else:
return [
torch.stack(intermediate).transpose(1, 2),
reference_points.unsqueeze(0).transpose(1, 2)
]
return output.unsqueeze(0)
# For the first decoder layer, we do not apply transformation over p_s
if self.query_scale_type != 'fix_elewise':
if layer_id == 0:
pos_transformation = 1
else:
pos_transformation = self.query_scale(output) # Linear(256,256) Linear(256,256) [300,N,256]
else:
pos_transformation = self.query_scale.weight[layer_id]
代码默认的模式是‘cond_elewise’,第一层的pos_transformation是不会对output使用Linear进行处理,除了第一层decoder外,其他的层都会对output使用Linear进行处理。
# modulated HW attentions
if self.modulate_hw_attn:
refHW_cond = self.ref_anchor_head(output).sigmoid() # nq, bs, 2 Linear(256,256) Linear(256,2) [300,N,2]
query_sine_embed[..., self.d_model // 2:] *= (refHW_cond[..., 0] / obj_center[..., 2]).unsqueeze(-1)
query_sine_embed[..., :self.d_model // 2] *= (refHW_cond[..., 1] / obj_center[..., 3]).unsqueeze(-1)
对应的公式:
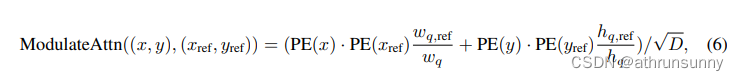
将output(tgt),encoder输出的memory,memory对应的mask,mask经过PE得到的pos_embed,refpoint的得到的query_sine_embed以及由query_sine_embed得到的query_pos传入decoder。
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False, keep_query_pos=False,
rm_self_attn_decoder=False):
super().__init__()
# Decoder Self-Attention
if not rm_self_attn_decoder:
self.sa_qcontent_proj = nn.Linear(d_model, d_model)
self.sa_qpos_proj = nn.Linear(d_model, d_model)
self.sa_kcontent_proj = nn.Linear(d_model, d_model)
self.sa_kpos_proj = nn.Linear(d_model, d_model)
self.sa_v_proj = nn.Linear(d_model, d_model)
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout, vdim=d_model)
self.norm1 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
# Decoder Cross-Attention
self.ca_qcontent_proj = nn.Linear(d_model, d_model)
self.ca_qpos_proj = nn.Linear(d_model, d_model)
self.ca_kcontent_proj = nn.Linear(d_model, d_model)
self.ca_kpos_proj = nn.Linear(d_model, d_model)
self.ca_v_proj = nn.Linear(d_model, d_model)
self.ca_qpos_sine_proj = nn.Linear(d_model, d_model)
self.cross_attn = MultiheadAttention(d_model*2, nhead, dropout=dropout, vdim=d_model)
self.nhead = nhead
self.rm_self_attn_decoder = rm_self_attn_decoder
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
self.keep_query_pos = keep_query_pos
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None, # None
memory_mask: Optional[Tensor] = None, # None
tgt_key_padding_mask: Optional[Tensor] = None, # None
memory_key_padding_mask: Optional[Tensor] = None, # [N,625]
pos: Optional[Tensor] = None, # [625,N,256]
query_pos: Optional[Tensor] = None, # [300,N,256]
query_sine_embed = None, # [300,N,256]
is_first = False):
# ========== Begin of Self-Attention =============
if not self.rm_self_attn_decoder:
# Apply projections here
# shape: num_queries x batch_size x 256
q_content = self.sa_qcontent_proj(tgt) # Linear(256,256) [300,N,256] # target is the input of the first decoder layer. zero by default.
q_pos = self.sa_qpos_proj(query_pos) # Linear(256,256) [300,N,256]
k_content = self.sa_kcontent_proj(tgt) # Linear(256,256) [300,N,256]
k_pos = self.sa_kpos_proj(query_pos) # Linear(256,256) [300,N,256]
v = self.sa_v_proj(tgt) # Linear(256,256) [300,N,256]
num_queries, bs, n_model = q_content.shape
hw, _, _ = k_content.shape
q = q_content + q_pos
k = k_content + k_pos
tgt2 = self.self_attn(q, k, value=v, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
# ========== End of Self-Attention =============
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
# ========== Begin of Cross-Attention =============
# Apply projections here
# shape: num_queries x batch_size x 256
q_content = self.ca_qcontent_proj(tgt) # Linear(256,256) [300,N,256]
k_content = self.ca_kcontent_proj(memory) # Linear(256,256) [625,N,256]
v = self.ca_v_proj(memory) # Linear(256,256) [625,N,256]
num_queries, bs, n_model = q_content.shape
hw, _, _ = k_content.shape
k_pos = self.ca_kpos_proj(pos) # Linear(256,256) [625,N,256]
# For the first decoder layer, we concatenate the positional embedding predicted from
# the object query (the positional embedding) into the original query (key) in DETR.
if is_first or self.keep_query_pos:
q_pos = self.ca_qpos_proj(query_pos) # Linear(256,256) [300,N,256]
q = q_content + q_pos # [300,N,256]
k = k_content + k_pos # [625,N,256]
else:
q = q_content
k = k_content
q = q.view(num_queries, bs, self.nhead, n_model//self.nhead) # [300,N,8,32]
query_sine_embed = self.ca_qpos_sine_proj(query_sine_embed) # Linear(256,256) [300,N,256]
query_sine_embed = query_sine_embed.view(num_queries, bs, self.nhead, n_model//self.nhead) # [300,N,8,32]
q = torch.cat([q, query_sine_embed], dim=3).view(num_queries, bs, n_model * 2) # [300,N,512]
k = k.view(hw, bs, self.nhead, n_model//self.nhead) # [625,N,8,32]
k_pos = k_pos.view(hw, bs, self.nhead, n_model//self.nhead) # [625,N,8,32]
k = torch.cat([k, k_pos], dim=3).view(hw, bs, n_model * 2) # [625,N,512]
tgt2 = self.cross_attn(query=q,
key=k,
value=v, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
# ========== End of Cross-Attention =============
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt # [300,N,256]
# For the first decoder layer, we concatenate the positional embedding predicted from
# the object query (the positional embedding) into the original query (key) in DETR.
if is_first or self.keep_query_pos:
q_pos = self.ca_qpos_proj(query_pos) # Linear(256,256) [300,N,256]
q = q_content + q_pos # [300,N,256]
k = k_content + k_pos # [625,N,256]
else:
q = q_content
k = k_content
这里要注意的是第一层的decoder,第一层会比较特殊,比如上面这里,其中:
1、k_pos:来自mask经过PE编码后得到的pos_embed,再将pos_embed经过Linear后得到最后的k_pos
2、q_pos:由query_sine_embed得到的query_pos,再将query_pos经过Linear后得到最后的q_pos
3、第一层decoder中,会将这两个值加在k,q上,之后会将k和k_pos cat在一起(每一层都会cat k_pos,只是在第一层或self.keep_query_pos为True时会在k上加k_pos,在q上加q_pos)
4、而q还会与query_sine_embed经过Linear后的结果cat在一起
可以看如下图解:
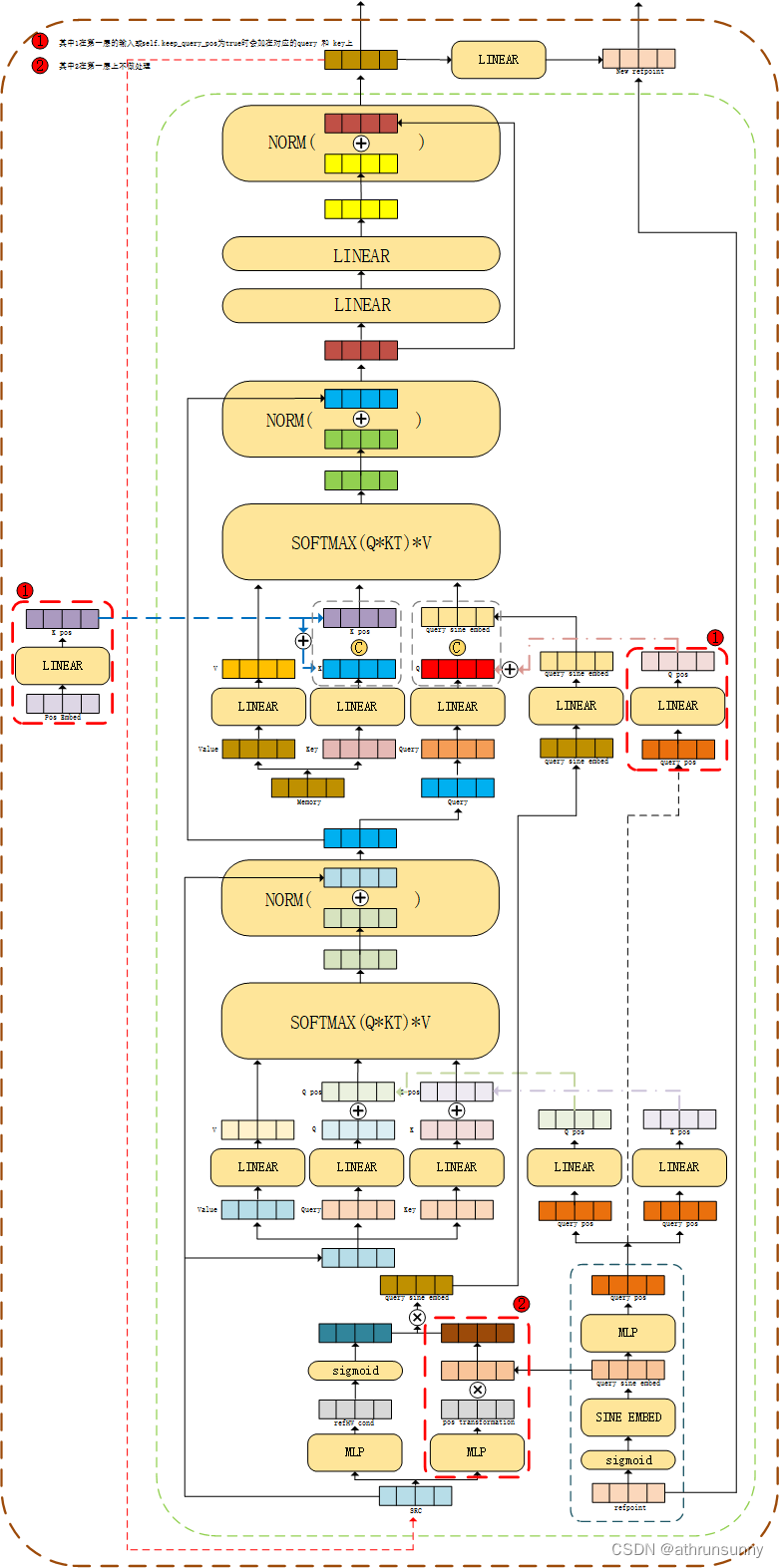
和论文中的图解比起来多了些细节
论文的图解:

if not self.bbox_embed_diff_each_layer:
reference_before_sigmoid = inverse_sigmoid(reference)
tmp = self.bbox_embed(hs) # Linear(256,256) Linear(256,256) Linear(256,4) [6,N,300,256]-> [6,N,300,4]
tmp[..., :self.query_dim] += reference_before_sigmoid
outputs_coord = tmp.sigmoid()
else:
reference_before_sigmoid = inverse_sigmoid(reference)
outputs_coords = []
for lvl in range(hs.shape[0]):
tmp = self.bbox_embed[lvl](hs[lvl])
tmp[..., :self.query_dim] += reference_before_sigmoid[lvl]
outputs_coord = tmp.sigmoid()
outputs_coords.append(outputs_coord)
outputs_coord = torch.stack(outputs_coords)
outputs_class = self.class_embed(hs) # Linear(256,91) [6,N,300,256]->[6,N,300,91]
out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}
最后的输出还会对边界框和类别做处理
完整的图解:
最后就是loss,loss部分和DETR基本相同,可以参看DETR代码学习笔记(三)