文章目录
- 一、基本了解
- 1.1 资源计算
- 1.2 调度机制
- 1.3 服务质量等级
- 二、资源配额 ResourceQuota
- 2.1 支持的限制资源
- 2.2 配额作用域
- 2.3 资源配额选型
- 2.3.1 计算资源配额
- 2.3.2 存储资源配额
- 2.3.3 对象数量配额
- 三、资源限制 LimitRange
- 3.1 限制资源大小值
- 3.2 设置限制默认值
- 3.3 限制存储大小值
一、基本了解
为什么会有资源配额管理?
- 可以提高集群稳定性,确保指定的资源对象在任何时候都不会超量占用系统物理资源,避免业务进程在设计或实现上的缺陷导致整个系统运行紊乱甚至意外宕机。
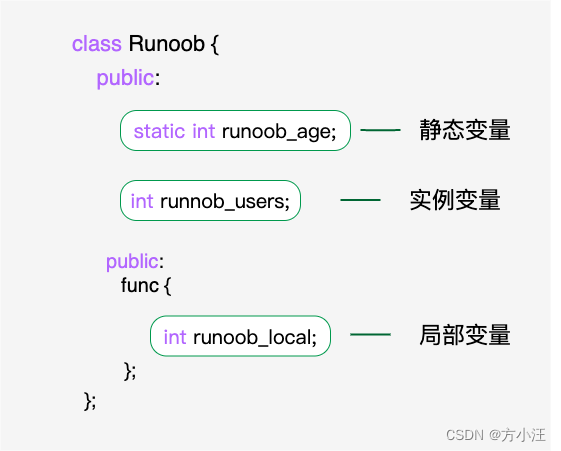
资源配额管理维度:
- 容器级别,定义每个Pod上资源配额相关的参数,比如CPU/Memory、Request/Limit;
- Pod级别,自动为每个没有定义资源配额的Pod添加资源配额模板,比如LimitRanger。
- Namespace级别,从总量上限制一个租户(应用)所能使用的资源配额,比如ResourceQuota,包括资源有:Pod数量、Replication Controller数量、Service数量、ResourceQuota数量、Secret数量和可持有的PV数量。
资源配额参数:
- 程序所使用的CPU与Memory是一个动态的量,跟负载密切相关,当负载增加时,CPU和Memory的使用量也会增加。
- spec.container[].resources.requests.cpu:容器初始要求的CPU数量。
- spec.container[].resources.limits.cpu:容器所能使用的最大CPU数量。
- spec.container[].resources.requests.memory:容器初始要求的内存数量
- spec.container[].resources.limits.memory:容器所能使用的最大内存数量。
1.1 资源计算
- Pod的Requests或Limits指该Pod中所有容器的Requests或Limits的总和,若Pod中没有设置Requests或Limits的容器,则该项的值被当作0或者按照集群配置的默认值来计算。
计算CPU:
- CPU的Requests和Limits是通过CPU数(cpus)来度量的。
- CPU的资源值是绝对值,而不是相对值,比如0.1CPU在单核或多核机器上是一样的,都严格等于0.1 CPU core。
计算Memory:
- 内存的Requests和Limits计量单位是字节数。使用整数或者定点整数加上国际单位制来表示内存值。
- 国际单位制包括十进制的E、P、T、G、M、K、m,或二进制的Ei、Pi、Ti、Gi、Mi、Ki。
- KiB与MiB是以二进制表示的字节单位,常见的KB与MB则是以十进制表示的字节单位,比如:
- 1 KB=1000 Bytes=8000 Bits;
- 1 KiB=2^10 Bytes=1024 Bytes=8192 Bits。
注意事项:
- 计算资源单位大小写敏感,m表示千分之一单位,M表示十进制的1000,二者的含义不同。
1.2 调度机制
基于Requests和Limits的Pod调度机制:
- 调度器在调度时,首先要确保调度后该节点上所有Pod的CPU和内存的Requests总和,不超过该节点能提供给Pod使用的CPU和Memory的最大容量值。
- 例如,某个节点上的CPU资源充足,而内存为4GB,其中3GB可以运行Pod,而某Pod的Memory Requests为1GB、Limits为2GB,那么在这个节点上最多可以运行3个这样的Pod。
Requests和Limits的背后机制:
- kubelet在启动Pod的某个容器时,会将容器的Requests和Limits值转化为相应的容器启动参数传递给容器执行器(Docker或者rkt)。
- 若容器的执行环境是Docker,那么容器的4个参数传递给Docker的过程如下:
- spec.container[].resources.requests.cpu:参数值会被转化为core数(比如配置的100m会转化为0.1),然后乘以1024,再将这个结果作为–cpu-shares参数的值传递给docker run命令。
- spec.container[].resources.limits.cpu:参数值会被转化为millicore数(比如配置的1被转化为1000,配置的100m被转化为100),将此值乘以100000,再除以1000,然后将结果值作为–cpu-quota参数的值传递给docker run命令。
- spec.container[].resources.requests.memory:参数值只提供给Kubernetes调度器作为调度和管理的依据,不会作为任何参数传递给Docker。
- spec.container[].resources.limits.memory:参数值会被转化为单位为Bytes的整数,值作为–memory参数传递给docker run命令。
常见问题分析:
- 若Pod状态为Pending,错误信息为FailedScheduling。若调度器在集群中找不到合适的节点来运行Pod,那么这个Pod会一直处于未调度状态,直到调度器找到合适的节点为止。每次调度器尝试调度失败时,Kubernetes都会产生一个事件。
- 容器被强行终止(Terminated)。如果容器使用的资源超过了它配置的Limits,那么该容器可能被强制终止。我们可以通过kubectl describe pod命令来确认容器是否因为这个原因被终止
1.3 服务质量等级
Pod的三种QoS级别:
- Guaranteed(完全可靠的):如果Pod中的所有容器对所有资源类型都定义了Limits和Requests,并且所有容器的Limits值都和Requests值相等(且都不为0),那么该Pod的QoS级别就是Guaranteed。
- 未定义Requests值,所以其默认等于Limits值。
- 其中定义的Requests与Limits的值完全相同。
- BestEffort(尽力而为、不太可靠的):如果Pod中所有容器都未定义资源配置(Requests和Limits都未定义),那么该Pod的QoS级别就是BestEffort。
- Burstable(弹性波动、较可靠的):当一个Pod既不为Guaranteed级别,也不为BestEffort级别时,该Pod的QoS级别就是Burstable。
- Pod中的一部分容器在一种或多种资源类型的资源配置中定义了Requests值和Limits值(都不为0),且Requests值小于Limits值。
- Pod中的一部分容器未定义资源配置(Requests和Limits都未定义)。
工作特点:
- BestEffort Pod的优先级最低,在这类Pod中运行的进程会在系统内存紧缺时被第一优先“杀掉”。当然,从另一个角度来看,BestEffortPod由于没有设置资源Limits,所以在资源充足时,它们可以充分使用所有闲置资源。
- Burstable Pod的优先级居中,这类Pod在初始时会被分配较少的可靠资源,但可以按需申请更多的资源。当然,如果整个系统内存紧缺,又没有BestEffort容器可以被杀掉以释放资源,那么这类Pod中的进程可能被“杀掉”。
- Guaranteed Pod的优先级最高,而且一般情况下这类Pod只要不超过其资源Limits的限制就不会被“杀掉”。当然,如果整个系统内存紧缺,又没有其他更低优先级的容器可以被“杀掉”以释放资源,那么这类Pod中的进程也可能会被“杀掉”。
二、资源配额 ResourceQuota
为何会有资源配额?
- 当多个团队、多个用户共享使用K8s集群时,会出现不均匀资源使用,默认情况下先到先得,这时可以通过ResourceQuota来对命名空间资源使用总量做限制,从而解决这个问题。
使用流程:
- k8s管理员为每个命名空间创建一个或多个ResourceQuota对象,定义资源使用总量,K8s会跟踪命名空间资源使用情况,当超过定义的资源配额会返回拒绝。
注意事项:
- 如果在集群中新添加了节点,资源配额不会自动更新,该资源配额所对应的命名空间中的对象也不能自动增加资源上限。
2.1 支持的限制资源
资源限制对象:
- 容器资源请求值(requests):命名空间下的所有pod申请资源时设置的requests总和不能超过这个值。
- resources.requests.cpu
- resources.requests.memory
- 容器资源限制值(limits):命名空间下的所有pod申请资源时设置的limits总和不能超过这个值。
- resources.limits.cpu
- resources.limits.memory
注意事项:
- CPU单位:可以写m也可以写浮点数,例如0.5=500m,1=1000m
- requests必须小于limits,建议一个理论值:requests值小于limits的20%-30%,一般是limits的70%。
- limits尽量不要超过所分配宿主机物理配置的80%,否则没有限制意义
- requests只是一个预留性质,并非实际的占用,用于k8s合理的分配资源(每个节点都有可分配的资源,k8s抽象的将这些节点资源统一分配)。比如requests分配1核1G,在满足的节点上创建完容器后实际资源可能只有0.5C1G。
- requests会影响pod调度,k8s只能将pod分配到能满足该requests值的节点上。
- ResourceQuota功能是一个准入控制插件,默认已经启用。
| 支持的资源 | 描述 |
|---|---|
| limits.cpu/memory | 所有Pod上限资源配置总量不超过该值(所有非终止状态的Pod) |
| requests.cpu/memory | 所有Pod请求资源配置总量不超过该值(所有非终止状态的Pod) |
| cpu/memory | 等同于requests.cpu/requests.memory |
| requests.storage | 所有PVC请求容量总和不超过该值 |
| persistentvolumeclaims | 所有PVC数量总和不超过该值 |
| < storage-class-name >. storageclass.storage.k8s.io/requests.storage | 所有与< storage-class-name >相关的PVC请求容量总和不超过该值 |
| < storage-class-name >. storageclass.storage.k8s.io/persistentvolumeclaims | 所有与< storage-class-name >相关的PVC数量总和不超过该值 |
| pods、count/deployments.apps、count/statfulsets.apps、count/services (services.loadbalancers、services.nodeports)、count/secrets、count/configmaps、count/job.batch、count/cronjobs.batch | 创建资源数量不超过该值 |
2.2 配额作用域
- 每个配额都有一组相关的 scope(作用域),配额只会对作用域内的资源生效。 配额机制仅统计所列举的作用域的交集中的资源用量。
- 当一个作用域被添加到配额中后,它会对作用域相关的资源数量作限制。 如配额中指定了允许(作用域)集合之外的资源,会导致验证错误。
- scopeSelector 支持在 operator 字段中使用以下值:
- In
- NotIn
- Exists
- DoesNotExist
| 作用域 | 描述 | 限制追踪资源 |
|---|---|---|
| Terminating | 匹配所有 spec.activeDeadlineSeconds 不小于 0 的 Pod。 | pods、cpu、memory、requests.cpu、requests.memory、limits.cpu、limits.memory |
| NotTerminating | 匹配所有 spec.activeDeadlineSeconds 是 nil 的 Pod。 | pods、cpu、memory、requests.cpu、requests.memory、limits.cpu、limits.memory |
| BestEffort | 匹配所有 Qos 是 BestEffort 的 Pod。 | pods |
| NotBestEffort | 匹配所有 Qos 不是 BestEffort 的 Pod。 | pods、cpu、memory、requests.cpu、requests.memory、limits.cpu、limits.memory |
| PriorityClass | 匹配所有引用了所指定的优先级类的 Pods。 | pods、cpu、memory、requests.cpu、requests.memory、limits.cpu、limits.memory |
| CrossNamespacePodAffinity | 匹配那些设置了跨名字空间 (反)亲和性条件的 Pod。 |
注意事项:
- 不能在同一个配额对象中同时设置 Terminating 和 NotTerminating 作用域。
- 不能在同一个配额中同时设置 BestEffort 和 NotBestEffort 作用域。
- 定义 scopeSelector 时,如果使用以下值之一作为 scopeName 的值,则对应的 operator 只能是 Exists:
- Terminating
- NotTerminating
- BestEffort
- NotBestEffort
2.3 资源配额选型
2.3.1 计算资源配额
- 用户可以对给定命名空间下的可被请求的 计算资源 总量进行限制。
| 资源名称 | 描述 |
|---|---|
| limits.cpu | 所有非终止状态的 Pod,其 CPU 限额总量不能超过该值。 |
| limits.memory | 所有非终止状态的 Pod,其内存限额总量不能超过该值。 |
| requests.cpu | 所有非终止状态的 Pod,其 CPU 需求总量不能超过该值。 |
| requests.memory | 所有非终止状态的 Pod,其内存需求总量不能超过该值。 |
| hugepages-< size> | 对于所有非终止状态的 Pod,针对指定尺寸的巨页请求总数不能超过此值。 |
| cpu | 与 requests.cpu 相同。 |
| memory | 与 requests.memory 相同 |
示例:
apiVersion: v1 kind: ResourceQuota metadata: name: compute-resources namespace: test ##作用在哪个命名空间,对该命名空间的pod资源进行限制。 spec: hard: requests.cpu: "4" ##test命名空间下的所有pod的cpu资源最小请求值不能超过4核。 requests.memory: 10Gi ##test命名空间下的所有pod的内存资源最小请求值不能超过10G。 limits.cpu: "6" ##test命名空间下的所有pod内的应用cpu资源最大限制值不能超过6核。 limits.memory: 12Gi ##test命名空间下的所有pod内的应用内存资源最大限制值不能超过12G。
1.创建一个计算资源配额qingjun,限制test命名空间的pod,最小请求cpu为2核,最小请求内存大小为2G;容器最大使用资源不能超过cpu 6核、内存10G。
[root@k8s-master1 ResourceQuota]# cat rq1.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: qingjun
namespace: test
spec:
hard:
requests.cpu: 2
requests.memory: 2Gi
limits.cpu: 6
limits.memory: 10Gi
[root@k8s-master1 ResourceQuota]# kubectl apply -f rq1.yaml
2.查看创建的resourcequota。

3.创建pod资源,查看效果。此时所创建的3个pod要求资源是满足的,所以创建成功。
[root@k8s-master1 ResourceQuota]# cat deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
namespace: test
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
resources:
requests:
cpu: 0.2
memory: 200Mi
limits:
cpu: 1
memory: 1Gi
[root@k8s-master1 ResourceQuota]# kubectl apply -f deploy.yaml

4.给这组pod扩容到10个,发现最终只能扩容到6个,因为每个pod上限配置为cpu 1核、内存 1G,而限制的资源计数配额上限配置为6核,超过的部分不会被创建。
[root@k8s-master1 ResourceQuota]# kubectl scale deploy nginx --replicas=10 -n test
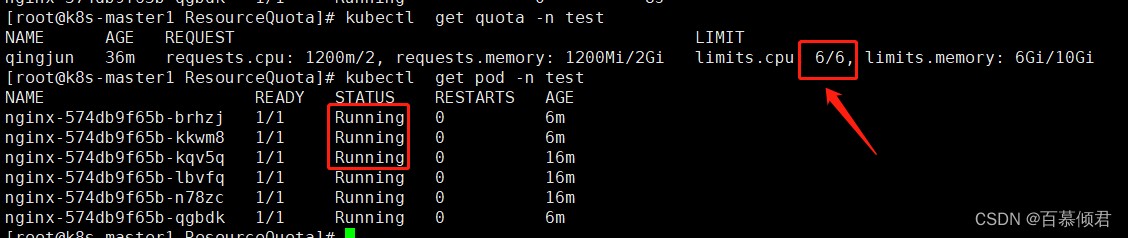
5.查看创建失败原因。
[root@k8s-master1 ResourceQuota]# kubectl describe rs -n test


2.3.2 存储资源配额
- 用户可以对给定命名空间下的存储资源 总量进行限制。
| 资源名称 | 说明 |
|---|---|
| requests.storage | 所有 PVC,存储资源的需求总量不能超过该值。 |
| persistentvolumeclaims | 在该命名空间中所允许的 PVC 总量。 |
| < storage-class-name>.storageclass.storage.k8s.io/requests.storage | 在所有与 < storage-class-name> 相关的持久卷申领中,存储请求的总和不能超过该值。 |
| < storage-class-name>.storageclass.storage.k8s.io/persistentvolumeclaims | 在与 storage-class-name 相关的所有持久卷申领中,命名空间中可以存在的持久卷申领总数。 |
示例:
apiVersion: v1 kind: ResourceQuota metadata: name: storage-resources namespace: test spec: hard: requests.storage: "10G" ##限制pvc能使用的最大内存。 managed-nfs-storage.storageclass.storage.k8s.io/requests.storage: "5G"
1.创建资源配额baimu。
[root@k8s-master1 ResourceQuota]# cat rq2.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: baimu
namespace: test
spec:
hard:
requests.storage: "10G"
[root@k8s-master1 ResourceQuota]# kubectl apply -f rq2.yaml

2.创建pvc测试效果,先创建指定内存为8G,小于限制大小,可以创建成功。
[root@k8s-master1 ResourceQuota]# cat pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: myclaim
namespace: test
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi
[root@k8s-master1 ResourceQuota]# kubectl apply -f pvc.yaml

3.再创建第二个pvc,同样申请8G,此时会创建失败,原因是先前创建的pvc已经占用了8G,而这次创建要求的8G已经超过了限制大小的10G。

2.3.3 对象数量配额
- 你可以使用以下语法对所有标准的、命名空间域的资源类型进行配额设置。
- count/< resource >.< group >:用于非核心(core)组的资源。
- count/< resource >:用于核心组的资源
| 资源名称 | 描述 |
|---|---|
| configmaps | 在该命名空间中允许存在的 ConfigMap 总数上限。 |
| persistentvolumeclaims | 在该命名空间中允许存在的 PVC 的总数上限。 |
| pods | 在该命名空间中允许存在的非终止状态的 Pod 总数上限。Pod 终止状态等价于 Pod 的 .status.phase in (Failed, Succeeded) 为真。 |
| replicationcontrollers | 在该命名空间中允许存在的 ReplicationController 总数上限。 |
| resourcequotas | 在该命名空间中允许存在的 ResourceQuota 总数上限。 |
| services | 在该命名空间中允许存在的 Service 总数上限。 |
| services.loadbalancers | 在该命名空间中允许存在的 LoadBalancer 类型的 Service 总数上限。 |
| services.nodeports | 在该命名空间中允许存在的 NodePort 类型的 Service 总数上限。 |
| secrets | 在该命名空间中允许存在的 Secret 总数上限。 |
示例:
apiVersion: v1 kind: ResourceQuota metadata: name: object-counts namespace: test spec: hard: pods: "10" ##最多可以创建pod数量。 count/deployments.apps: "3" ##最多可以创建deploy数量。 count/services: "3" ##最多可以创建svc数量。
1.创建资源配额wuhan1。
[root@k8s-master1 ResourceQuota]# cat rq3.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: wuhan
namespace: test
spec:
hard:
pods: "10" ##最多可以创建pod数量。
count/deployments.apps: "3" ##最多可以创建deploy数量。
count/services: "3" ##最多可以创建svc数量。
[root@k8s-master1 ResourceQuota]# kubectl apply -f rq3.yaml

2.创建一个deploy,其pod副本有3个,满足限制要求,创建成功。

3.创建第二个、第三个deploy资源都可以,创建第四个deploy失败,原因时超过了限制要求。

三、资源限制 LimitRange
基本了解:
- 默认情况下,K8s集群上的容器对计算资源没有任何限制,可能会导致个别容器资源过大导致影响其他容器正常工
作,这时可以使用LimitRange定义容器默认CPU和内存请求值或者最大上限。- 也存在员工在设置ResourceQuota时,过大或过小,甚至忘记设置。那么limirange就可以设置个默认值,即时忘记没有设置限制值时,也可给你设置个默认限制值;也可以限制员工在设置限制值时要合理,不能超过limitrange的最小值,也不能低于limitrange的最小值。
LimitRange限制维度:
- 限制容器配置requests.cpu/memory,limits.cpu/memory的最小、最大值。
- 限制容器配置requests.cpu/memory,limits.cpu/memory的默认值。
- 限制PVC配置requests.storage的最小、最大值。
注意事项:

3.1 限制资源大小值
1.创建一个LimitRange。
[root@k8s-master1 ResourceQuota]# cat lr1.yaml
apiVersion: v1
kind: LimitRange
metadata:
name: qingjun
namespace: test ##策略作用哪个命名空间。
spec:
limits:
- max: ##容器能设置limit的最大值。
cpu: 1
memory: 1Gi
min: ##容器能设置request的最小值。
cpu: 200m
memory: 200Mi
type: Container ##限制对象。
[root@k8s-master1 ResourceQuota]# kubectl apply -f lr1.yaml

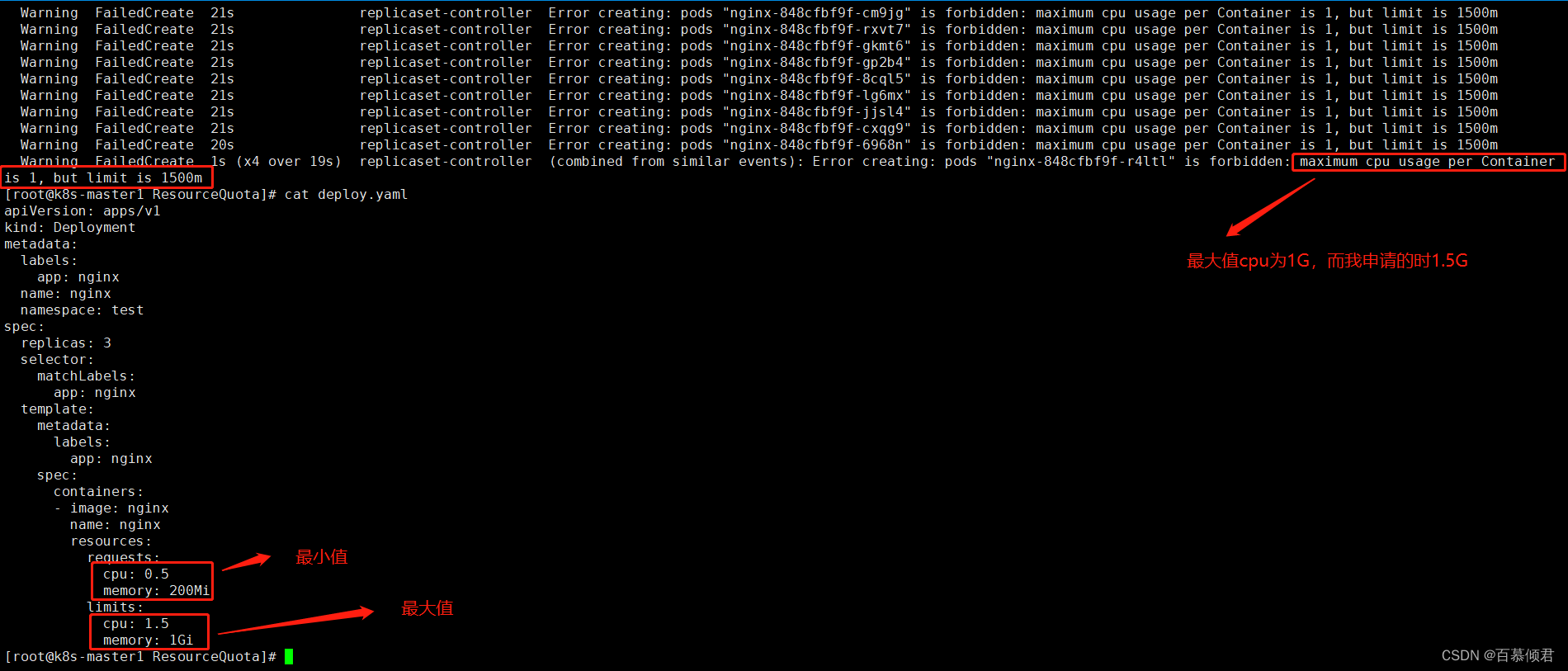
2.创建资源测试。创建的pod申请最大cpu资源超过设置值,会创建失败,限制成功。
[root@k8s-master1 ResourceQuota]# kubectl describe rs -n test
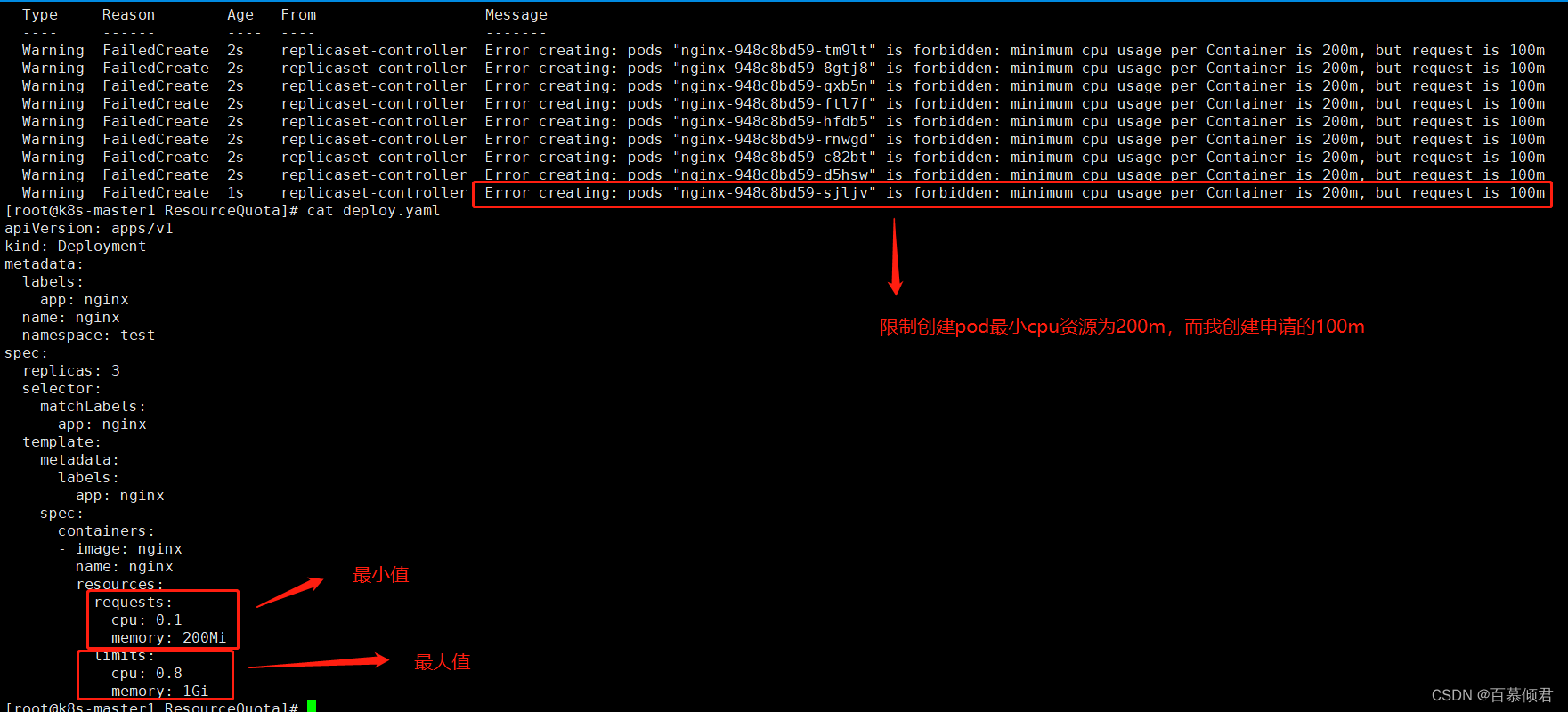
3.创建的pod申请最小cpu资源低于设置值,会创建失败,限制成功。
3.2 设置限制默认值
基本了解:
- 这个资源默认值,是在限制资源大小值时就会默认创建,根据max最大值创建。
- 当默认值不合理时,需要我们手动去设置。
- Containers可以设置限制默认值,Pod不能设置Default Request和Default Limit参数。

1.可以直接在限制大小的基础上设置限制默认值。
[root@k8s-master1 ResourceQuota]# cat lr1.yaml
apiVersion: v1
kind: LimitRange
metadata:
name: qingjun
namespace: test
spec:
limits:
- max: ##限制最大值。
cpu: 2
memory: 5Gi
min: ##限制最小值。
cpu: 0.5
memory: 1Gi
type: Container
default: ##限制默认最大值。
cpu: 1
memory: 3Gi
defaultRequest: ##限制默认最小值。
cpu: 0.5
memory: 1Gi
[root@k8s-master1 ResourceQuota]# kubectl apply -f lr1.yaml
2.查看。

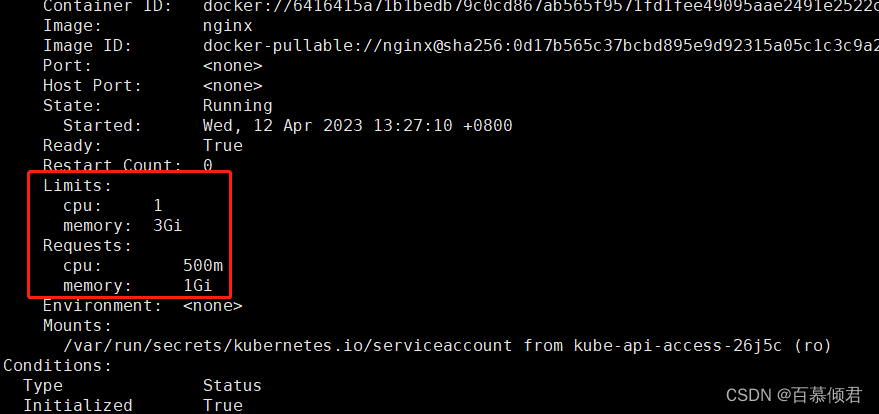
3.创建pod时不设置资源申请大小时,可以看到会默认设置成默认值。
##创建。
[root@k8s-master1 ResourceQuota]# kubectl run nginx1 --image=nginx -n test
##查看。
[root@k8s-master1 ResourceQuota]# kubectl describe pod nginx1 -n test
3.3 限制存储大小值
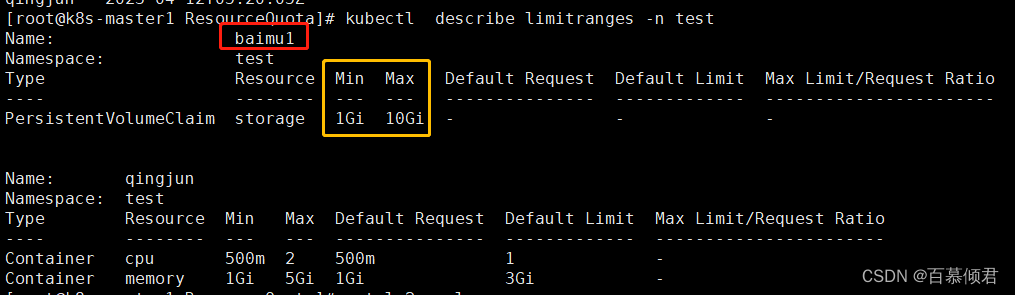
1.创建限制策略。
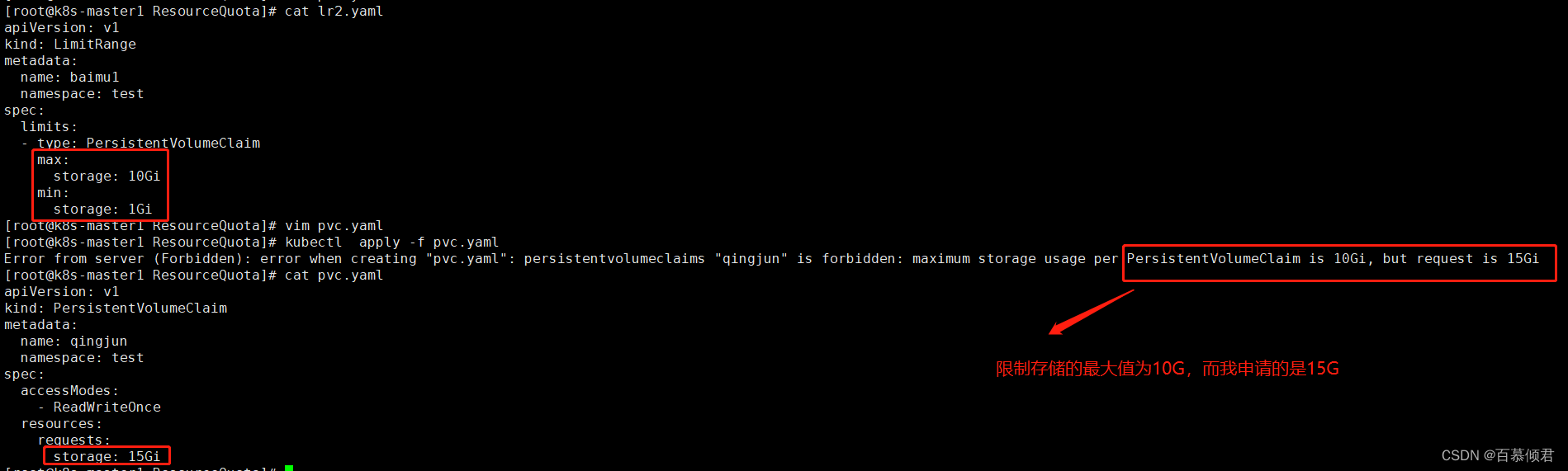
[root@k8s-master1 ResourceQuota]# cat lr2.yaml
apiVersion: v1
kind: LimitRange
metadata:
name: baimu1
namespace: test
spec:
limits:
- type: PersistentVolumeClaim
max:
storage: 10Gi
min:
storage: 1Gi
[root@k8s-master1 ResourceQuota]# kubectl apply -f lr2.yaml
2.测试效果。生成一个pvc,申请资源为15G,超过了设置的限制最大值,创建失败,测试成功。
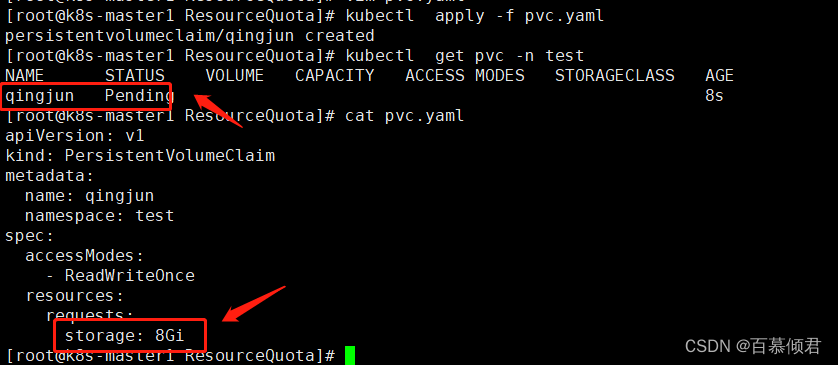
3.创建pvc的申请资源改成8G后,符合设置的限制区间值,创建成功,测试通过。
![buu [NPUCTF2020]共 模 攻 击 1](https://img-blog.csdnimg.cn/d6ef911fb87b4cb0b89770dd8cf6e561.png)