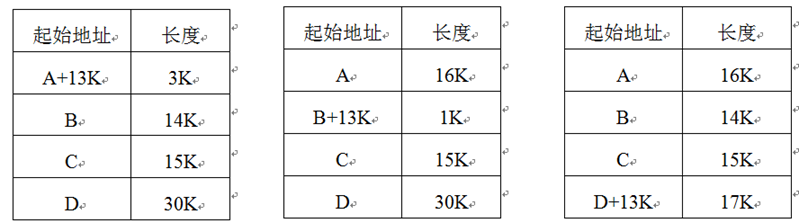
- 区别介绍
(1)lxml
lxml是Python的一个XML解析库,它基于libxml2和libxslt库构建,可以读取、操作和输出XML文档。lxml具有很强的性能和稳定性,在处理较大的XML文件时表现尤佳,并且支持XPath、CSS选择器等高级的选择器语法,可以提高开发效率。
(2)BeautifulSoup
BeautifulSoup是一个HTML和XML的解析器,可以解析HTML和XML文档,并提供了很多有用的方法,让开发者可以轻松地遍历和搜索DOM树。通过BeautifulSoup,我们可以以更加简单、优雅的方式处理HTML文档中的数据。
(3)html.parser
html.parser是Python标准库中的HTML解析库,它是Python 3.x默认的解析库。和lxml、BeautifulSoup相比,它的性能较差,但是它的优点就在于简单易用,不需要额外的安装和配置。
- 应用场景介绍
(1)lxml
lxml适用于处理较大的XML文件,如果你需要解析和操作大型的XML文件,那么lxml是一个不错的选择,因为lxml提供了高效的内存管理机制和先进的XPath选择器语法。常见的应用场景包括爬取RSS、Atom、RDF等XML格式的数据,处理复杂的配置文件和数据文件等。
(2)BeautifulSoup
BeautifulSoup适用于解析HTML文档中的数据,如果你需要提取HTML文档中的数据,那么BeautifulSoup是一个不错的选择。常见的应用场景包括爬取网页数据、解析HTML配置文件、解析XML格式数据等。
(3)html.parser
html.parser适用于简单的HTML文档解析,如果你需要快速地解析一个HTML文档,那么可以选择html.parser。常见的应用场景包括解析HTML配置文件、解析XML格式数据、解析简单的网页数据等。
- 参考资料和优秀实践
(1)参考资料
lxml官方文档:http://lxml.de/
BeautifulSoup官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/
html.parser官方文档:https://docs.python.org/3/library/html.parser.html
(2)优秀实践
①lxml实战:使用lxml处理XML格式数据
通过lxml可以轻松地读取、操作和输出XML文档,本实践介绍了如何使用lxml处理XML格式数据,包括读取XML文件、添加和删除节点、修改和写入XML文件等操作。
链接:https://www.cnblogs.com/yangzhenyu/p/13313457.html
②BeautifulSoup实战:爬取网页数据
通过BeautifulSoup可以轻松地爬取网页数据,本实践介绍了如何使用BeautifulSoup爬取京东商城的商品信息,并存储到MySQL数据库中。
链接:https://zhuanlan.zhihu.com/p/64330403
③html.parser实战:解析HTML文档中的数据
通过html.parser可以轻松地解析HTML文档中的数据,本实践介绍了如何使用html.parser解析HTML格式的网页数据,并提取出所需的数据。
链接:https://www.jianshu.com/p/c25c49130304
- 总结
lxml、BeautifulSoup和html.parser都是Python中常用的解析库,各自具有不同的优点和适用场景。在选择解析库时,需要根据实际情况进行选择,选择最适合自己需求的解析库。同时,可以通过不断实践和学习,不断提高自己的技能水平。