摘要
本文提出Deep Voice,一种完全由深度神经网络构建的生产质量文本到语音系统。Deep Voice为真正的端到端神经语音合成奠定了基础。该系统由五个主要的构建模块组成:用于定位音素边界的分割模型、字素到音素的转换模型、音素时长预测模型、基频预测模型和音频合成模型。对于分割模型,我们提出了一种使用连接时序分类(CTC)损失的深度神经网络执行音素边界检测的新方法。对于音频合成模型,我们实现了WaveNet的一个变体,比原始模型需要更少的参数,训练速度更快。通过为每个组件使用神经网络,我们的系统比传统的文本到语音系统更简单和更灵活,在传统系统中,每个组件都需要费力的特征工程和广泛的领域专业知识。最后,我们展示了使用我们的系统进行推理可以比实时执行得更快,并描述了CPU和GPU上优化的WaveNet推理内核,与现有实现相比,可实现高达400倍的加速。
介绍
从文本中合成人工人类语音,通常称为文本到语音(TTS),是许多应用程序中的重要组成部分,如语音支持设备、导航系统和视障人士的无障碍环境。从根本上说,它允许人与技术的交互,而不需要视觉界面。现代的TTS系统是基于复杂的、多阶段的处理管道,每一个都可能依赖于手工设计的特征和启发式。由于这种复杂性,开发新的TTS系统可能是非常劳动密集和困难的。
Deep Voice受到传统文本到语音管道的启发,采用相同的结构,同时用神经网络替换所有组件并使用更简单的特征:首先我们将文本转换为音素,然后使用音频合成模型将语言特征转换为语音(Taylor, 2009)。与之前的工作(使用手工设计的特征,如谱包络、谱参数、非周期参数等)不同,我们唯一的特征是带有重音注释的音素、音素持续时间和基频(F0)。这种特征的选择使我们的系统更容易适用于新的数据集、语音和域,而无需任何手动数据注释或额外的特征工程。通过在一个完全包含音频和非对齐文本转录并生成相对高质量语音的全新数据集上重新训练整个管道,而不改变任何超参数,来证明这一说法。在传统的TTS系统中,这种适应需要数天到数周的调整,而深度语音允许您在仅几个小时的人工工作和模型训练所需的时间内完成。
实时推理是生产质量TTS系统的要求;没有它,系统对于大多数TTS应用来说是不可用的。之前的工作已经证明,WaveNet (van den Oord et al., 2016)可以生成接近人类水平的语音。然而,由于模型的高频、自回归性质,WaveNet推理提出了一个令人生畏的计算问题,迄今为止,人们还不知道这样的模型是否可以用于生产系统。我们肯定地回答了这个问题,并展示了高效的、比实时更快的WaveNet推理内核,产生高质量的16khz音频,并实现了比之前WaveNet推理实现的400倍加速(Paine et al., 2016)。
相关工作
之前的工作使用神经网络作为几种TTS系统组件的替代品,包括字素到音素转换模型(Rao等人,2015;Yao & Zweig, 2015),音素持续时间预测模型(Zen & Sak, 2015),基频预测模型(Pascual & Bonafonte, 2016;Ronanki et al., 2016)、音频合成模型(van den Oord et al., 2016;Mehri et al., 2016)。然而,与Deep Voice不同的是,这些系统都没有解决TTS的全部问题,其中许多系统使用专门为其领域开发的专门手工设计的功能。
最近,在参数化音频合成方面有很多工作,特别是WaveNet, SampleRNN和Char2Wav (van den Oord等人,2016;Mehri等人,2016;Sotelo等人,2017)。WaveNet既可以用于条件音频生成,也可以用于无条件音频生成,而Sam- pleRNN仅用于无条件音频生成。Char2Wav通过基于注意力的音素持续时间模型和相当于F0预测模型的方法扩展了SampleRNN,有效地为基于SampleRNN的声码器提供了局部条件反射信息。
Deep Voice与这些系统在几个关键方面有所不同,这些方面显著地增加了问题的范围。首先,Deep Voice是完全独立的;训练一个新的Deep Voice系统不需要预先存在的TTS系统,可以使用短音频片段和相应的文本转录本数据集从头开始。相比之下,再现上述任何一个系统都需要访问和理解现有的TTS系统,因为它们在训练或推理时都使用了来自另一个TTS系统的特征。
其次,低沉的声音最大限度地减少了手工设计的功能的使用;它使用one-hot编码字符进行字素到音素的转换,one-hot编码音素和重音,以毫秒为单位的音素持续时间,以及可以从中计算的归一化对数基频
使用任何F0估计算法的波形。所有这些都可以很容易地从音频和转录本以最小的努力获得。相比之下,之前的工作使用了更复杂的特征表示,这有效地使再现系统在没有预先存在的TTS系统的情况下是不可能的。WaveNet使用了来自TTS系统的几个特征(Zen et al., 2013),这些特征包括单词中音节的数量、短语中音节的位置、当前帧在音素中的位置等值,以及语音频谱的动态特征(如频谱和激励参数),以及它们的时间导数。Char2Wav依赖于世界TTS系统的声码器特征(Morise et al., 2016)对其对齐模块进行预训练,其中包括F0、谱包络和非周期参数。
最后,我们专注于创建一个可用于生产的系统,这要求我们的模型实时运行以进行推理。Deep Voice可以在几分之一秒内合成音频,并在合成速度和音频质量之间提供可调的权衡。相比之下,之前与WaveNet的结果需要几分钟的运行时间才能合成1秒的音频。我们不知道SampleRNN的类似基准,但原始出版物中描述的3层架构在推理期间所需的计算量大约是我们最大的WaveNet模型的4-5倍,因此实时运行模型可能会被证明具有挑战性。
TTS系统组件
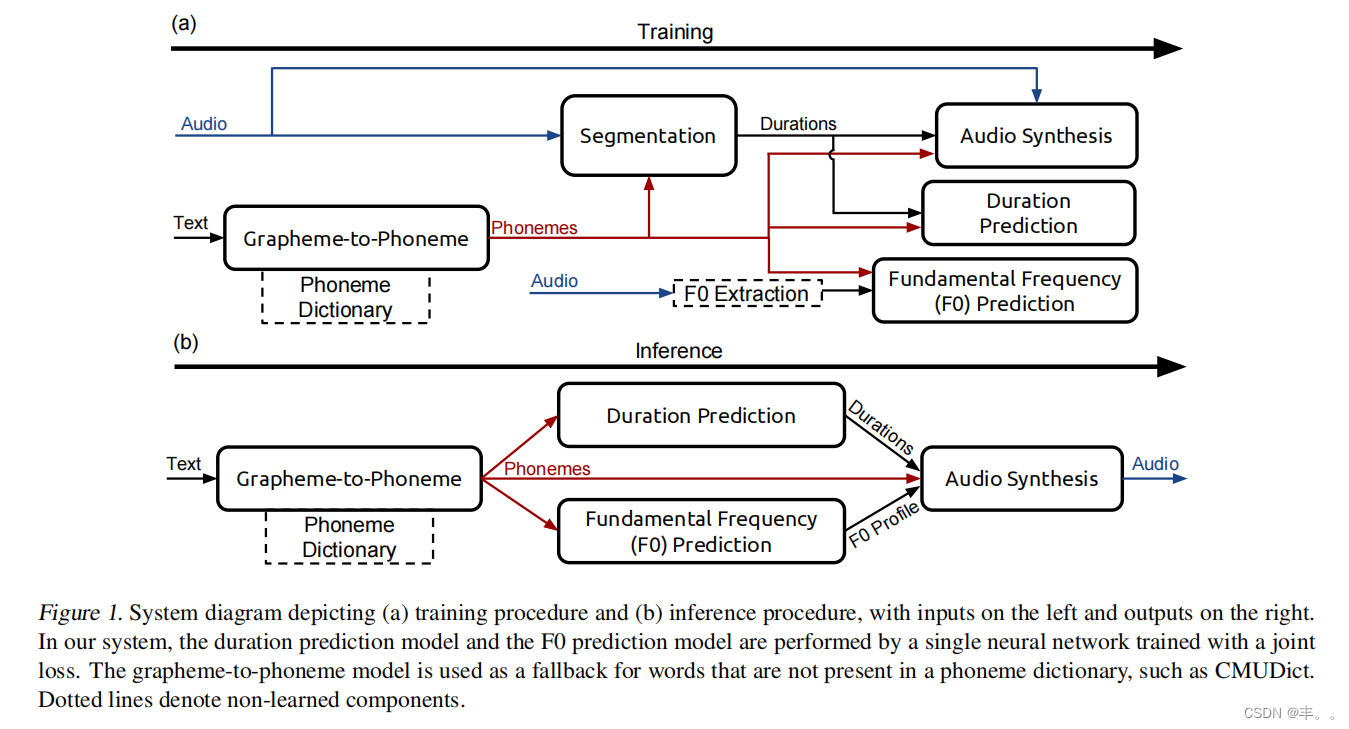
如图1所示,TTS系统由五个主要的构建模块组成:
•字形到音素模型将书面文本(英语字符)转换为音素(使用音素字母表(如ARPABET)进行编码)。
•分割模型在语音数据集中定位音素边界。给定一个音频文件和音频的一个一个音素的转录,分割模型确定音频中每个音素的开始和结束位置。
音素持续时间模型预测音素序列(一个话语)中每个音素的时间持续时间。
•基频模型预测音素是否为浊音。如果是,该模型预测整个音素持续时间的基频(F0)。
•音频合成模型结合了字素到音素、音素时长和基频预测模型的输出,并以高采样率合成音频,对应在推理过程中,文本通过字素到音素模型或音素词典来生成音素。接下来,音素作为输入提供给音素持续时间模型和F0预测模型,为每个音素分配持续时间并生成F0轮廓。最后,音素、音素持续时间和F0被用作音频合成模型的局部调节输入特征,生成最终的发音。
与其他模型不同的是,在推理过程中不使用分割模型。相反,它用于标注训练语音数据的音素边界。音素边界暗示了时长,可以用来训练音素时长模型。标注了音素和音素时长以及基频的音频,被用来训练音频合成模型。
在接下来的几节中,我们将详细描述所有的构建模块。
Grapheme-to-Phoneme模型
我们的字素到音素模型是基于由(Yao & Zweig, 2015)开发的编码器-解码器架构。然而,我们使用了一个具有门控循环单元(GRU)非线性的多层双向编码器和一个同等深度的单向GRU解码器(Chung et al., 2014)。每个解码器层的初始状态被初始化为最终状态
对应的编码器前向层的隐藏状态。该架构使用教师强迫进行训练,并使用波束搜索进行解码。我们在编码器中使用3个双向层,每个1024个单元,在解码器中使用3个大小相同的单向层,并使用宽度为5个候选的波束搜索。在训练过程中,我们在每个循环层之后使用概率为0.95的dropout。对于训练,我们使用β= 0.9,2 β= 0.999, ε = 10−8的Adam优化算法1 ,每1000次迭代应用的批量大小为64,学习率为10−3,退火率为0.85 (Kingma & Ba,2014)。
细分模式
我们的分割模型经过训练,可以输出给定语句和目标音素序列之间的对齐。这个任务类似于语音识别中将语音与书面输出对齐的问题。在该领域,连接时序分类(CTC)损失函数已被证明专注于字符对齐,以学习声音和文本之间的映射(Graves等人,2006年)。我们从最先进的语音识别系统(Amodei et al., 2015)中改编卷积循环神经网络架构用于音素边界检测。
用CTC训练生成音素序列的网络将为每个输出音素产生短暂的峰值。虽然这足以粗略地将音素与音频对齐,但要精确地检测还不够
音素的界限。为了克服这个问题,我们训练预测音素对的序列,而不是单个音素。然后,网络将倾向于在时间步长接近一对中两个音素之间的边界时输出音素对。
为了说明我们的标签编码,考虑字符串“Hello!”。要将其转换为音素对标签序列,需要将发音转换为音素(使用发音词典如CMUDict或字素到音素模型),并将两端的音素序列用静音音素填充,得到“sil HH EH L OW sil”。最后,构建连续的音素对,得到“(sil, HH), (HH, EH), (EH, L), (L, OW), (OW, sil)”。
输入音频的特点是以10毫秒的步幅计算20个梅尔频率倒谱系数(mfcc)。在输入层的顶部,有两个卷积层(时间和频率上的2D卷积),三个双向循环的GRU层,最后一个softmax输出层。卷积层使用单位步幅的核,高度9(在频率bin中),宽度5(在时间),循环层使用512个GRU单元(每个方向)。概率为0.95的Dropout在最后的卷积层和循环层之后应用。为了计算音素对错误率(PPER),我们使用波束搜索进行解码。为了解码音素边界,我们在相邻音素对至少有一个音素重叠的约束下,执行宽度为50的波束搜索,并跟踪每个音素对在发音中的位置。
在训练中,我们使用Adam优化算法1 ,β= 0.9,2 β= 0.999, ε = 10−8,每500次迭代应用一次批量大小为128,学习率为10−4,退火率为0.95 (Kingma & Ba,2014)。
音素时长和基频模型
我们使用单一架构来联合预测音素时长和随时间变化的基频。模型的输入是一个带有重音的音素序列,每个音素和重音都被编码为一个one-hot向量。该架构包括两个全连接层,每个层有256个单元,然后是两个单向循环层,每个层有128个GRU单元,最后是一个全连接的输出层。在初始的全连接层和最后的循环层之后应用概率为0.8的Dropout。
最后一层对每个输入音素产生三个估计:音素持续时间,音素是浊音的概率(即具有基频),以及20个随时间变化的F0值,这些值在预测的持续时间内进行均匀采样。该模型通过最小化联合损失来优化,该联合损失结合了音素持续时间误差、基频误差、音素为浊音概率的负对数似然,以及与F0相对于时间的绝对变化成比例的惩罚项来施加平滑性。损失函数的具体功能形式在附录B中描述。
在训练时,我们使用β= 0.9,2 β= 0.999, ε = 10−8的Adam优化算法1 ,每400次迭代应用的批量大小为128,学习率为3 × 10−4,退火率为0.9886 (Kingma & Ba,2014)。
音频合成模型
我们的音频合成模型是WaveNet的变体。WaveNet由一个条件网络和一个自回归网络组成,前者将语言特征向上采样到所需的频率,后者在离散化的音频样本y∈{0,1,…上生成概率分布P(y)。255}。我们改变层数’,残差通道数r(每层隐藏状态的维度),和跳过通道数s(层输出在输出层之前被投影到的维度)。
WaveNet由一个上采样和调节网络组成,其次是 2×1具有r个残差输出通道和门控tanh非线性的卷积层。我们用Wprev和Wcur将卷积分解为每个时间步长的两个矩阵乘法。这些层通过残差连接连接。每一层的隐藏状态被连接到一个r向量,并与Wskip投影到s跳过通道,随后是两层具有relu非线性的1 × 1卷积(具有权重Wrelu和Wout)。
WaveNet使用转置卷积进行上采样和调节。我们发现,如果我们首先用双向准rnn (QRNN)层的堆栈对输入进行编码(Bradbury et al., 2016),然后通过重复到所需的频率进行上采样,我们的模型表现得更好,训练速度更快,需要的参数更少。
我们最高质量的最终模型使用’ = 40层,r = 64个残差通道,s = 256个跳过通道。对于训练,我们使用带有1 β=的Adam优化算法
0.9, β2 = 0.999, ε = 10−8,批大小为8,学习率为10−3,退火率为0.9886应用每
1000次迭代(Kingma & Ba, 2014)。
请参阅附录A,了解我们WaveNet架构和我们使用的QRNN层的完整详细信息。
结果
在一个内部英语语音数据库上训练模型,该数据库包含大约20小时的语音数据,被分割为13,079个语句。此外,本文展示了在暴雪2013数据子集上训练的模型的音频合成结果(Prahallad et al., 2013)。这两个数据集都由专业女性演讲者发言。
我们所有的模型都是使用TensorFlow框架实现的(Abadi等人,2015)。
分割结果
我们在8个TitanX Maxwell gpu上进行训练,在gpu之间平均分配每个批次,并使用一个ring all-reduce来在不同的gpu上计算平均梯度,每次迭代耗时约1300毫秒。在大约14000次迭代后,该模型收敛到音素对错误率为7%。我们还发现音素边界不必精确,随机移动音素边界10-30毫秒不会对音频质量产生影响,因此怀疑音频质量对超过一定程度的音素对错误率不敏感。
Grapheme-to-Phoneme结果
我们在从CMUDict (Weide, 2008)获得的数据上训练一个字母到音素模型。我们剔除了所有不以字母开头、包含数字或具有多个发音的单词,从而从原始的133,854个字母-音素序列对中留下了124,978个单词。
我们在单个TitanX Maxwell GPU上进行训练,每次迭代耗时约150毫秒。经过大约20000次迭代后,该模型收敛到音素错误率为5.8%,单词错误率为28.7%,与之前报道的结果相当(Yao & Zweig, 2015)。与之前的工作不同,我们在解码过程中没有使用语言模型,也没有将具有多种发音的单词包含在我们的数据集中。
音素持续时间和基频结果
我们在单个TitanX Maxwell GPU上进行训练,每次迭代耗时约120毫秒。在大约20000次迭代后,模型收敛到38毫秒(对于音素持续时间)和29.4 Hz(对于基频)的平均绝对误差。
音频合成结果
我们将音频数据集中的话语划分为一秒钟的块,每个块有四分之一秒的上下文,用四分之一秒的si-填充每个话语
Lence在开头。我们过滤掉了主要是沉默的块,最终总共有74,348块。
我们训练了不同深度的模型,包括残差层堆栈中的10层、20层、30层和40层。我们发现,低于20层的模型会导致音频质量较差。20层、30层和40层模型都能产生高质量的可识别语音,但40层模型比20层模型的噪声更小,可以用高质量的戴耳式耳机检测到。
之前的工作强调了感受野大小在确定模型质量方面的重要性。的确,20层模型的感受野大小只有40层模型的一半。然而,当以48khz运行时,40层的模型只有83毫秒的感受野,但仍然可以生成高质量的音频。这表明20层模型的感受野是足够的,我们推测音频质量的差异是由于感受野大小之外的一些其他因素造成的。
我们在8个TitanX Maxwell GPU上进行训练,每个GPU有一个块,使用环allreduce来计算不同GPU上的平均梯度。每次迭代耗时约450毫秒。我们的模型在大约30万次迭代后收敛。我们发现一个1.25s的块就足以饱和GPU上的计算,而批处理并没有提高训练效率。
与高维生成模型常见的情况一样(Theis et al., 2015),模型损失与单个样本的感知质量在某种程度上是不相关的。虽然具有异常高损失的模型听起来明显有噪声,但在一定阈值以下优化的模型并不具有指示其质量的损失。此外,模型架构的变化(如深度和输出频率)可以对模型损失产生显著影响,而对音频质量的影响很小。
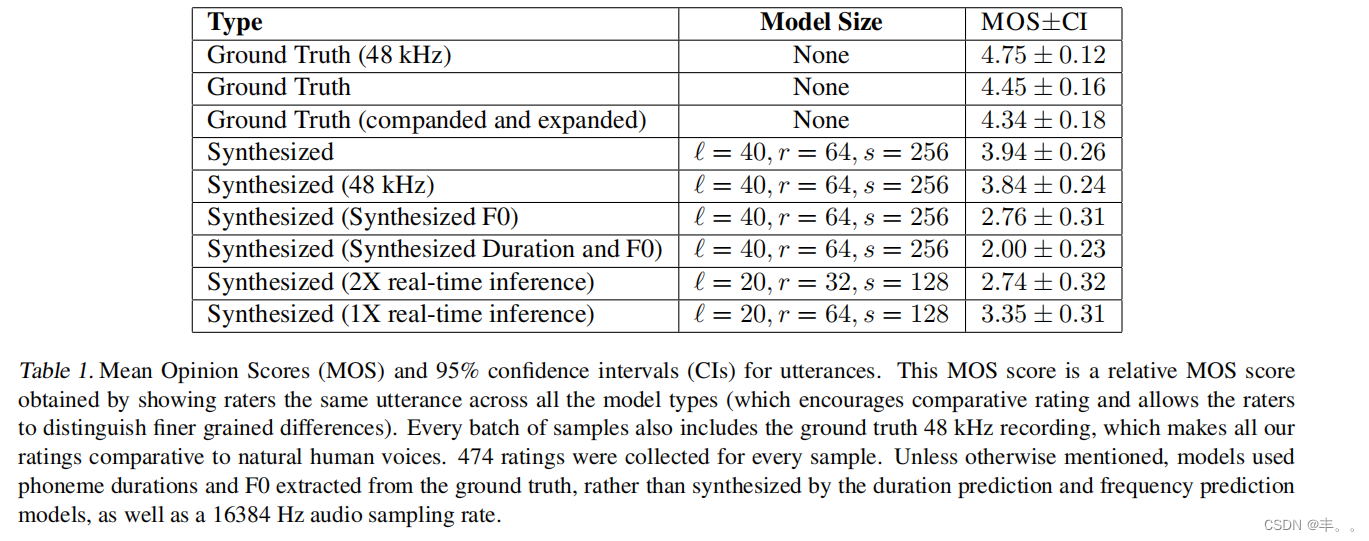
为了估计我们的TTS管道各个阶段的感知质量,我们使用CrowdMOS工具包和方法论(Ribeiro et al., 2011)众包了Mechanical Turk的平均意见分数(MOS)评级(评级在1到5之间,值越高越好)。为了分离音频预处理的效果、WaveNet模型质量以及音素持续时间和基频模型质量,我们为各种语音类型提供了MOS分数,包括从真实音频中提取WaveNet输入(持续时间和F0)而不是由其他模型合成的合成结果。结果如表1所示。我们有意在评分者评估的每一批样本中包括ground truth样本,以突出来自人类语音的delta,并允许评分者区分模型之间更细粒度的差异;这种方法的缺点是,得到的MOS分数将明显低于if评分者
仅与合成音频样本一起呈现。
首先,当简单地将音频流从48 kHz降采样到16 kHz时,发现MOS显著下降,特别是与μ kHz扩谱和量化相结合时,这可能是因为48 kHz样本作为5分的基线呈现给评分者,而低质量的噪声合成结果呈现为1。当与基准真值持续时间和F0一起使用时,我们的模型得分很高,我们模型的95%置信区间与基准真值样本的置信区间相交。然而,使用合成频率降低了MOS,进一步包括合成持续时间大大降低了它。我们得出的结论是,向自然TTS发展的主要障碍在于持续时间和基频预测,我们的系统在这方面没有实质性的进展,超过了最先进的水平。最后,我们最好的模型运行速度比实时稍慢(见表2),因此我们证明了通过获得比实时运行速度快1倍和2倍的模型的分数来调整模型大小,可以用合成质量换取推理速度。
我们还测试了在原始WaveNet出版物的全套特征上训练的WaveNet模型,但没有发现这些模型与在我们的简化特征集上训练的模型之间存在知觉上的差异。
暴雪的结果
为了证明我们系统的灵活性,我们在暴雪2013数据集(Prahallad et al., 2013)上用相同的超参数重新训练了我们所有的模型。对于我们的实验,我们使用了一个20.5小时的数据集子集,它被分割成9,741个语句。我们使用第4.4节中描述的程序来评估模型,该程序鼓励评分者直接将合成音频与真实值进行比较。在坚持的设置上,16 kHz compated和expanded audio收到MOS分数为4.65±0.13,而我们的合成音频收到MOS分数为2.67±0.37。
优化推理
尽管WaveNet在生成高质量合成语音方面显示出了希望,但最初的实验报告称,短语音的生成时间为几分钟或几小时。由于模型的高频、自回归性质,WaveNet推理提出了一个极具挑战性的计算问题,这比传统的循环神经网络需要更多的时间步长。当生成音频时,单个样本必须在大约60 μ s(用于16khz音频)或20 μ s(用于48khz音频)内生成。对于我们的40层模型,这意味着单个层(由几个矩阵相乘和非线性组成)必须在大约1.5 μ s内完成。为了比较,访问驻留的值
在CPU的主内存中可以使用0.1 μ s。为了实时执行推理,我们必须非常小心,永远不要重新计算任何结果,将整个模型存储在处理器缓存中(与主内存相反),并优化利用可用的计算单元。这些相同的技术可以用来用PixelCNN (Oord et al., 2016)将图像合成加速到每幅图像几分之一秒。
用我们的40层WaveNet模型合成1秒的音频大约需要55×109 floating点操作(FLOPs)。任何给定层中的激活依赖于前一层和前一个时间步的激活,因此推理必须一次完成一个时间步和一层。单层只需要42 × 103次FLOPs,这使得实现有意义的并行变得困难。除了计算需求,该模型有大约1.6 × 106个参数,如果以单精度表示,这相当于大约6.4 MB。(完整的性能模型见附录E。)
在CPU上,单个Haswell或Broadwell核的峰值单精度吞吐量约为77 × 109 FLOPs, L2-to-L1缓存带宽约为140 GB/s1。模型必须每个时间步从cache加载一次,这需要100 GB/s的带宽。即使模型适合L2 cache,实现也需要利用70%的最大带宽和70%的峰值FLOPS,才能在单核上进行实时推理。跨多个核心拆分计算降低了问题的难度,但尽管如此,它仍然具有挑战性,因为推理必须在最大内存带宽和峰值FLOPs的显著比例下运行,同时保持线程同步。
GPU具有比CPU更高的内存带宽和峰值FLOPs,但提供了更专业的,因此具有限制性的计算模型。一个为每一层或时间步启动一个单一内核的简单实现是站不住脚的,但基于持久RNN技术(Diamos et al., 2016)的实现可能能够利用gpu提供的吞吐量。
为CPU和GPU实现了高速优化的推理内核,并证明了WaveNet推理的速度可以超过实时。表2列出了不同模型的CPU和GPU推理速度。在这两种情况下,基准只包括自回归、高频音频的生成,而不包括语言条件反射特征的生成(可以对整个话语进行并行处理)。我们的CPU内核以实时或高于实时的速度运行于
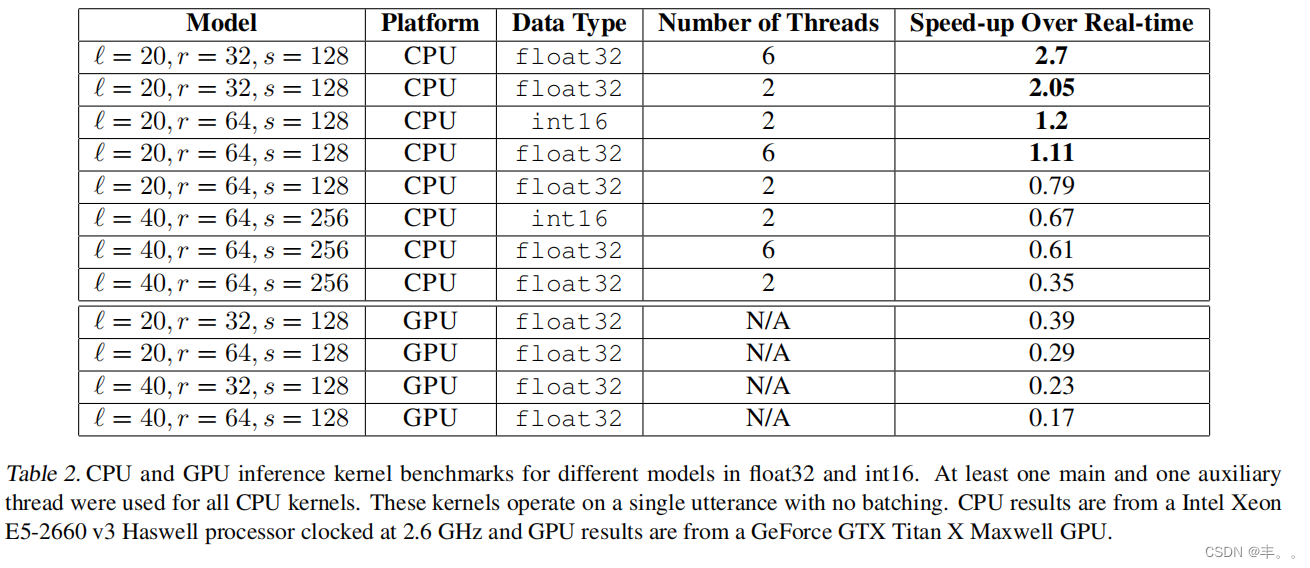
模型子集,而GPU模型还没有达到这一性能。
CPU实现
我们通过避免任何重新计算,进行缓存友好的内存访问,通过高效同步的多线程并行工作,最小化非线性FLOPs,通过线程钉住避免缓存抖动和线程争用,并使用自定义硬件优化的矩阵乘法和卷积例程来实现实时CPU推断。
对于CPU实现,我们将计算划分为以下步骤:
样本嵌入:通过做两个样本嵌入来计算WaveNet输入因果卷积,一个用于当前时间步,一个用于前一个时间步,并将它们与偏差相加。也就是说,
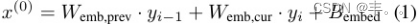


Ther库提供了等效的int16操作。
GPU实现
由于其计算强度,许多神经模型最终部署在gpu上,gpu可以具有比cpu高得多的计算吞吐量。由于我们的模型是内存带宽和FLOP bound,在GPU上运行推理似乎是一个自然的选择,但事实证明,这带来了一系列不同的挑战。
通常,代码在GPU上以内核调用的顺序运行,每个矩阵乘法或向量操作都是它自己的内核。然而,CUDA内核启动的延迟(可能高达50 μ s)与从GPU内存加载整个模型所需的时间相结合,对于这样的方法来说,是非常大的。这种风格的推理内核最终会比实时慢大约1000倍。
为了在GPU上接近实时,我们转而使用持久rnn (Diamos et al., 2016)的技术构建一个内核,该技术在单个内核启动中生成输出音频中的所有样本。模型的权重被加载到寄存器一次,然后在整个推理过程中不卸载它们即可使用。由于CUDA编程模型和这样的持久化内核之间的不匹配,由此产生的内核被专门用于特定的模型尺寸,并且编写起来是令人难以置信的劳动密集型。虽然我们的GPU推理速度不是很实时(表2),但我们相信,通过这些技术和更好的实现,我们可以在GPU和cpu上实现实时WaveNet推理。持久化GPU内核的实现细节可以在附录D中找到。
结论
在这项工作中,我们通过构建一个完全的神经系统,证明了当前的深度学习方法对于高质量的文本到语音引擎的所有组件都是可行的。我们将推理优化到比实时更快的速度,表明这些技术可以应用于以流媒体方式实时生成音频。我们的系统是可训练的,无需任何人工参与,极大地简化了创建TTS系统的过程。
我们的工作为探索开辟了许多新的可能方向。推理性能可以通过仔细的优化,GPU上的模型量化,CPU上的int8量化,以及与其他架构(如Xeon Phi)的实验来进一步提高。另一个自然的方向是消除阶段之间的分离,将分割、时长预测和基频预测模型直接合并到音频合成模型中,从而将问题转化为完整的序列到序列模型,创建一个单端到端可训练的TTS系统,并允许我们在没有中间监督的情况下训练整个系统。代替融合模型,通过更大的训练数据集或生成建模技术来改进持续时间和频率模型可能会对语音自然度产生影响。